Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mempersiapkan model Anda untuk penerapan pada titik akhir SageMaker AI memerlukan beberapa langkah, termasuk memilih gambar model, menyiapkan konfigurasi titik akhir, mengkodekan fungsi serialisasi dan deserialisasi Anda untuk mentransfer data ke dan dari server dan klien, mengidentifikasi dependensi model, dan mengunggahnya ke Amazon S3. ModelBuilderdapat mengurangi kompleksitas penyiapan dan penerapan awal untuk membantu Anda membuat model yang dapat diterapkan dalam satu langkah.
ModelBuildermelakukan tugas-tugas berikut untuk Anda:
Mengonversi model pembelajaran mesin yang dilatih menggunakan berbagai kerangka kerja seperti XGBoost atau PyTorch menjadi model yang dapat diterapkan dalam satu langkah.
Melakukan pemilihan kontainer otomatis berdasarkan kerangka model sehingga Anda tidak perlu menentukan penampung secara manual. Anda masih dapat membawa kontainer Anda sendiri dengan meneruskan URI Anda sendiri ke
ModelBuilder.Menangani serialisasi data di sisi klien sebelum mengirimnya ke server untuk inferensi dan deserialisasi hasil yang dikembalikan oleh server. Data diformat dengan benar tanpa pemrosesan manual.
Memungkinkan pengambilan dependensi secara otomatis dan mengemas model sesuai dengan harapan server model.
ModelBuilderpenangkapan dependensi otomatis adalah pendekatan upaya terbaik untuk memuat dependensi secara dinamis. (Kami menyarankan Anda menguji pengambilan otomatis secara lokal dan memperbarui dependensi untuk memenuhi kebutuhan Anda.)Untuk kasus penggunaan model bahasa besar (LLM), secara opsional melakukan penyetelan parameter lokal dari properti penyajian yang dapat digunakan untuk kinerja yang lebih baik saat menghosting pada titik akhir AI. SageMaker
Mendukung sebagian besar server model populer dan kontainer seperti TorchServe, Triton, DJLServing dan kontainer TGI.
Membangun model Anda dengan ModelBuilder
ModelBuilderadalah kelas Python yang mengambil model kerangka kerja, seperti XGBoost atau PyTorch, atau spesifikasi inferensi yang ditentukan pengguna dan mengubahnya menjadi model deployable. ModelBuildermenyediakan fungsi build yang menghasilkan artefak untuk penerapan. Artefak model yang dihasilkan khusus untuk server model, yang juga dapat Anda tentukan sebagai salah satu input. Untuk detail lebih lanjut tentang ModelBuilder kelas, lihat ModelBuilder
Diagram berikut menggambarkan keseluruhan alur kerja pembuatan model saat Anda menggunakan. ModelBuilder ModelBuildermenerima spesifikasi model atau inferensi bersama dengan skema Anda untuk membuat model yang dapat diterapkan yang dapat Anda uji secara lokal sebelum penerapan.
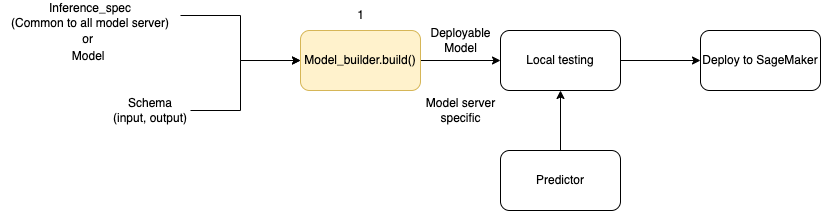
ModelBuilderdapat menangani kustomisasi apa pun yang ingin Anda terapkan. Namun, untuk menerapkan model kerangka kerja, pembuat model mengharapkan setidaknya model, input dan output sampel, dan peran. Dalam contoh kode berikut, ModelBuilder dipanggil dengan model kerangka kerja dan instance SchemaBuilder dengan argumen minimum (untuk menyimpulkan fungsi yang sesuai untuk serialisasi dan deserialisasi input dan output endpoint). Tidak ada kontainer yang ditentukan dan tidak ada dependensi paket yang diteruskan— SageMaker AI secara otomatis menyimpulkan sumber daya ini saat Anda membuat model Anda.
from sagemaker.serve.builder.model_builder import ModelBuilder
from sagemaker.serve.builder.schema_builder import SchemaBuilder
model_builder = ModelBuilder(
model=model,
schema_builder=SchemaBuilder(input, output),
role_arn="execution-role",
)Contoh kode berikut dipanggil ModelBuilder dengan spesifikasi inferensi (sebagai InferenceSpec contoh) alih-alih model, dengan penyesuaian tambahan. Dalam hal ini, panggilan ke pembuat model menyertakan jalur untuk menyimpan artefak model dan juga mengaktifkan penangkapan otomatis semua dependensi yang tersedia. Untuk detail tambahan tentangInferenceSpec, lihatSesuaikan pemuatan model dan penanganan permintaan.
model_builder = ModelBuilder(
mode=Mode.LOCAL_CONTAINER,
model_path=model-artifact-directory,
inference_spec=your-inference-spec,
schema_builder=SchemaBuilder(input, output),
role_arn=execution-role,
dependencies={"auto": True}
)Tentukan metode serialisasi dan deserialisasi
Saat menjalankan titik akhir SageMaker AI, data dikirim melalui muatan HTTP dengan tipe MIME yang berbeda. Misalnya, gambar yang dikirim ke titik akhir untuk inferensi perlu dikonversi ke byte di sisi klien dan dikirim melalui payload HTTP ke titik akhir. Ketika titik akhir menerima payload, ia perlu deserialisasi string byte kembali ke tipe data yang diharapkan oleh model (juga dikenal sebagai deserialisasi sisi server). Setelah model menyelesaikan prediksi, hasilnya juga perlu diserialisasikan ke byte yang dapat dikirim kembali melalui payload HTTP ke pengguna atau klien. Setelah klien menerima data byte respons, klien perlu melakukan deserialisasi sisi klien untuk mengonversi data byte kembali ke format data yang diharapkan, seperti JSON. Minimal, Anda perlu mengonversi data untuk tugas-tugas berikut:
Serialisasi permintaan inferensi (ditangani oleh klien)
Deserialisasi permintaan inferensi (ditangani oleh server atau algoritma)
Memanggil model terhadap muatan dan mengirim muatan respons kembali
Serialisasi respons inferensi (ditangani oleh server atau algoritma)
Deserialisasi respons inferensi (ditangani oleh klien)
Diagram berikut menunjukkan proses serialisasi dan deserialisasi yang terjadi saat Anda memanggil titik akhir.
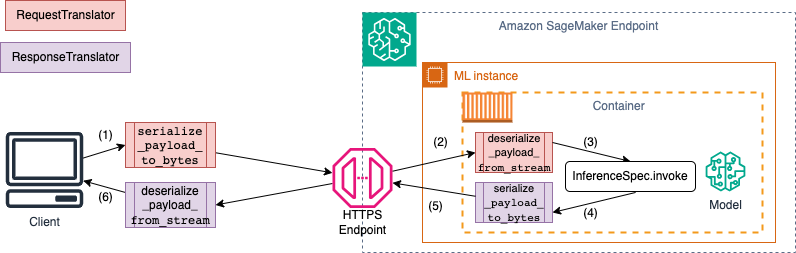
Saat Anda memasok input dan output sampel keSchemaBuilder, pembuat skema menghasilkan fungsi penyusunan yang sesuai untuk membuat serial dan deserialisasi input dan output. Anda dapat lebih lanjut menyesuaikan fungsi serialisasi Anda denganCustomPayloadTranslator. Tetapi untuk kebanyakan kasus, serializer sederhana seperti berikut ini akan berfungsi:
input = "How is the demo going?"
output = "Comment la démo va-t-elle?"
schema = SchemaBuilder(input, output)Untuk detail lebih lanjut tentangSchemaBuilder, lihat SchemaBuilder
Cuplikan kode berikut menguraikan contoh di mana Anda ingin menyesuaikan fungsi serialisasi dan deserialisasi di sisi klien dan server. Anda dapat menentukan penerjemah permintaan dan tanggapan Anda sendiri CustomPayloadTranslator dan meneruskan penerjemah ini ke. SchemaBuilder
Dengan memasukkan input dan output dengan penerjemah, pembuat model dapat mengekstrak format data yang diharapkan model. Misalnya, input sampel adalah gambar mentah, dan penerjemah khusus Anda memotong gambar dan mengirim gambar yang dipotong ke server sebagai tensor. ModelBuildermembutuhkan input mentah dan kode pra-pemrosesan atau pasca-pemrosesan khusus untuk memperoleh metode untuk mengonversi data di sisi klien dan server.
from sagemaker.serve import CustomPayloadTranslator
# request translator
class MyRequestTranslator(CustomPayloadTranslator):
# This function converts the payload to bytes - happens on client side
def serialize_payload_to_bytes(self, payload: object) -> bytes:
# converts the input payload to bytes
... ...
return //return object as bytes
# This function converts the bytes to payload - happens on server side
def deserialize_payload_from_stream(self, stream) -> object:
# convert bytes to in-memory object
... ...
return //return in-memory object
# response translator
class MyResponseTranslator(CustomPayloadTranslator):
# This function converts the payload to bytes - happens on server side
def serialize_payload_to_bytes(self, payload: object) -> bytes:
# converts the response payload to bytes
... ...
return //return object as bytes
# This function converts the bytes to payload - happens on client side
def deserialize_payload_from_stream(self, stream) -> object:
# convert bytes to in-memory object
... ...
return //return in-memory objectAnda meneruskan input dan output sampel bersama dengan penerjemah kustom yang ditentukan sebelumnya saat Anda membuat SchemaBuilder objek, seperti yang ditunjukkan pada contoh berikut:
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
Kemudian Anda meneruskan input dan output sampel, bersama dengan penerjemah khusus yang ditentukan sebelumnya, ke objek. SchemaBuilder
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
Bagian berikut menjelaskan secara rinci cara membangun model Anda ModelBuilder dan menggunakan kelas pendukungnya untuk menyesuaikan pengalaman untuk kasus penggunaan Anda.
Topik
Sesuaikan pemuatan model dan penanganan permintaan
Memberikan kode inferensi Anda sendiri melalui InferenceSpec menawarkan lapisan penyesuaian tambahan. DenganInferenceSpec, Anda dapat menyesuaikan cara model dimuat dan cara menangani permintaan inferensi yang masuk, melewati pemuatan default dan mekanisme penanganan inferensi. Fleksibilitas ini sangat bermanfaat ketika bekerja dengan model non-standar atau pipa inferensi khusus. Anda dapat menyesuaikan invoke metode untuk mengontrol bagaimana model memproses dan pasca-proses permintaan masuk. invokeMetode ini memastikan bahwa model menangani permintaan inferensi dengan benar. Contoh berikut digunakan InferenceSpec untuk menghasilkan model dengan HuggingFace pipa. Untuk detail lebih lanjut tentangInferenceSpec, lihat InferenceSpec
from sagemaker.serve.spec.inference_spec import InferenceSpec
from transformers import pipeline
class MyInferenceSpec(InferenceSpec):
def load(self, model_dir: str):
return pipeline("translation_en_to_fr", model="t5-small")
def invoke(self, input, model):
return model(input)
inf_spec = MyInferenceSpec()
model_builder = ModelBuilder(
inference_spec=your-inference-spec,
schema_builder=SchemaBuilder(X_test, y_pred)
)Contoh berikut menggambarkan variasi yang lebih disesuaikan dari contoh sebelumnya. Sebuah model didefinisikan dengan spesifikasi inferensi yang memiliki dependensi. Dalam hal ini, kode dalam spesifikasi inferensi tergantung pada paket lang-segment. Argumen untuk dependencies berisi pernyataan yang mengarahkan pembangun untuk menginstal lang-segment menggunakan Git. Karena pembuat model diarahkan oleh pengguna untuk menginstal dependensi secara kustom, auto kuncinya adalah mematikan False penangkapan otomatis dependensi.
model_builder = ModelBuilder(
mode=Mode.LOCAL_CONTAINER,
model_path=model-artifact-directory,
inference_spec=your-inference-spec,
schema_builder=SchemaBuilder(input, output),
role_arn=execution-role,
dependencies={"auto": False, "custom": ["-e git+https://github.com/luca-medeiros/lang-segment-anything.git#egg=lang-sam"],}
)Bangun model Anda dan terapkan
Panggil build fungsi untuk membuat model deployable Anda. Langkah ini membuat kode inferensi (asinference.py) di direktori kerja Anda dengan kode yang diperlukan untuk membuat skema Anda, menjalankan serialisasi dan deserialisasi input dan output, dan menjalankan logika kustom yang ditentukan pengguna lainnya.
Sebagai pemeriksaan integritas, SageMaker AI mengemas dan mengasinkan file yang diperlukan untuk penerapan sebagai bagian dari fungsi ModelBuilder build. Selama proses ini, SageMaker AI juga membuat penandatanganan HMAC untuk file pickle dan menambahkan kunci rahasia di CreateModelAPI sebagai variabel lingkungan selama deploy (ataucreate). Peluncuran endpoint menggunakan variabel lingkungan untuk memvalidasi integritas file pickle.
# Build the model according to the model server specification and save it as files in the working directory
model = model_builder.build()Terapkan model Anda dengan deploy metode model yang ada. Pada langkah ini, SageMaker AI menyiapkan titik akhir untuk meng-host model Anda saat mulai membuat prediksi pada permintaan yang masuk. Meskipun ModelBuilder menyimpulkan sumber daya titik akhir yang diperlukan untuk menerapkan model Anda, Anda dapat mengganti perkiraan tersebut dengan nilai parameter Anda sendiri. Contoh berikut mengarahkan SageMaker AI untuk menyebarkan model pada satu ml.c6i.xlarge instance. Model yang dibuat dari ModelBuilder memungkinkan pencatatan langsung selama penerapan sebagai fitur tambahan.
predictor = model.deploy(
initial_instance_count=1,
instance_type="ml.c6i.xlarge"
)Jika Anda menginginkan kontrol yang lebih halus atas sumber daya titik akhir yang ditetapkan ke model Anda, Anda dapat menggunakan objek. ResourceRequirements Dengan ResourceRequirements objek, Anda dapat meminta jumlah minimum CPUs, akselerator, dan salinan model yang ingin Anda terapkan. Anda juga dapat meminta batas memori minimum dan maksimum (dalam MB). Untuk menggunakan fitur ini, Anda perlu menentukan jenis titik akhir Anda sebagaiEndpointType.INFERENCE_COMPONENT_BASED. Contoh berikut meminta empat akselerator, ukuran memori minimum 1024 MB, dan satu salinan model Anda untuk digunakan ke titik akhir tipe. EndpointType.INFERENCE_COMPONENT_BASED
resource_requirements = ResourceRequirements(
requests={
"num_accelerators": 4,
"memory": 1024,
"copies": 1,
},
limits={},
)
predictor = model.deploy(
mode=Mode.SAGEMAKER_ENDPOINT,
endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED,
resources=resource_requirements,
role="role"
)Bawa wadah Anda sendiri (BYOC)
Jika Anda ingin membawa wadah Anda sendiri (diperpanjang dari wadah SageMaker AI), Anda juga dapat menentukan URI gambar seperti yang ditunjukkan pada contoh berikut. Anda juga perlu mengidentifikasi server model yang sesuai dengan gambar ModelBuilder untuk menghasilkan artefak khusus untuk server model.
model_builder = ModelBuilder(
model=model,
model_server=ModelServer.TORCHSERVE,
schema_builder=SchemaBuilder(X_test, y_pred),
image_uri="123123123123.dkr.ecr.ap-southeast-2.amazonaws.com/byoc-image:xgb-1.7-1")
)Menggunakan ModelBuilder dalam mode lokal
Anda dapat menerapkan model Anda secara lokal dengan menggunakan mode argumen untuk beralih antara pengujian lokal dan penerapan ke titik akhir. Anda perlu menyimpan artefak model di direktori kerja, seperti yang ditunjukkan pada cuplikan berikut:
model = XGBClassifier()
model.fit(X_train, y_train)
model.save_model(model_dir + "/my_model.xgb")Lewati objek model, SchemaBuilder instance, dan atur mode keMode.LOCAL_CONTAINER. Saat Anda memanggil build fungsi, ModelBuilder secara otomatis mengidentifikasi wadah kerangka kerja yang didukung dan memindai dependensi. Contoh berikut menunjukkan pembuatan model dengan XGBoost model dalam mode lokal.
model_builder_local = ModelBuilder( model=model, schema_builder=SchemaBuilder(X_test, y_pred), role_arn=execution-role, mode=Mode.LOCAL_CONTAINER ) xgb_local_builder = model_builder_local.build()
Panggil deploy fungsi untuk menyebarkan secara lokal, seperti yang ditunjukkan pada cuplikan berikut. Jika Anda menentukan parameter untuk tipe atau hitungan contoh, argumen ini diabaikan.
predictor_local = xgb_local_builder.deploy()
Memecahkan masalah mode lokal
Tergantung pada pengaturan lokal pribadi Anda, Anda mungkin mengalami kesulitan berjalan ModelBuilder dengan lancar di lingkungan Anda. Lihat daftar berikut untuk beberapa masalah yang mungkin Anda hadapi dan cara mengatasinya.
Sudah digunakan: Anda mungkin mengalami
Address already in usekesalahan. Dalam hal ini, ada kemungkinan bahwa kontainer Docker berjalan pada port itu atau proses lain memanfaatkannya. Anda dapat mengikuti pendekatan yang diuraikan dalam dokumentasi Linuxuntuk mengidentifikasi proses dan dengan anggun mengarahkan proses lokal Anda dari port 8080 ke port lain atau membersihkan instance Docker. Masalah Izin IAM: Anda mungkin mengalami masalah izin saat mencoba menarik gambar Amazon ECR atau mengakses Amazon S3. Dalam hal ini, navigasikan ke peran eksekusi notebook atau instans Studio Classic untuk memverifikasi kebijakan
SageMakerFullAccessatau izin API masing-masing.Masalah kapasitas volume EBS: Jika Anda menerapkan model bahasa besar (LLM), Anda mungkin kehabisan ruang saat menjalankan Docker dalam mode lokal atau mengalami batasan ruang untuk cache Docker. Dalam hal ini, Anda dapat mencoba memindahkan volume Docker Anda ke sistem file yang memiliki cukup ruang. Untuk memindahkan volume Docker Anda, selesaikan langkah-langkah berikut:
Buka terminal dan jalankan
dfuntuk menampilkan penggunaan disk, seperti yang ditunjukkan pada output berikut:(python3) sh-4.2$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 195928700 0 195928700 0% /dev tmpfs 195939296 0 195939296 0% /dev/shm tmpfs 195939296 1048 195938248 1% /run tmpfs 195939296 0 195939296 0% /sys/fs/cgroup /dev/nvme0n1p1 141545452 135242112 6303340 96% / tmpfs 39187860 0 39187860 0% /run/user/0 /dev/nvme2n1 264055236 76594068 176644712 31% /home/ec2-user/SageMaker tmpfs 39187860 0 39187860 0% /run/user/1002 tmpfs 39187860 0 39187860 0% /run/user/1001 tmpfs 39187860 0 39187860 0% /run/user/1000Pindahkan direktori Docker default dari
/dev/nvme0n1p1ke/dev/nvme2n1sehingga Anda dapat sepenuhnya memanfaatkan volume SageMaker AI 256 GB. Untuk detail selengkapnya, lihat dokumentasi tentang cara memindahkan direktori Docker Anda. Hentikan Docker dengan perintah berikut:
sudo service docker stopTambahkan
daemon.jsonke/etc/dockeratau tambahkan gumpalan JSON berikut ke yang sudah ada.{ "data-root": "/home/ec2-user/SageMaker/{created_docker_folder}" }Pindahkan direktori Docker
/var/lib/dockerke/home/ec2-user/SageMaker AIdengan perintah berikut:sudo rsync -aP /var/lib/docker/ /home/ec2-user/SageMaker/{created_docker_folder}Mulai Docker dengan perintah berikut:
sudo service docker startBersihkan sampah dengan perintah berikut:
cd /home/ec2-user/SageMaker/.Trash-1000/files/* sudo rm -r *Jika Anda menggunakan instance SageMaker notebook, Anda dapat mengikuti langkah-langkah dalam file persiapan Docker
untuk mempersiapkan Docker untuk mode lokal.
ModelBuilder contoh
Untuk contoh penggunaan lainnya ModelBuilder untuk membuat model Anda, lihat ModelBuildercontoh buku catatan
