Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bagian ini memandu Anda melalui laporan XGBoost pelatihan Debugger. Laporan secara otomatis digabungkan tergantung pada regex tensor keluaran, mengenali jenis pekerjaan pelatihan Anda di antara klasifikasi biner, klasifikasi multiclass, dan regresi.
penting
Dalam laporan tersebut, plot dan dan rekomendasi disediakan untuk tujuan informasi dan tidak definitif. Anda bertanggung jawab untuk membuat penilaian independen Anda sendiri atas informasi tersebut.
Topik
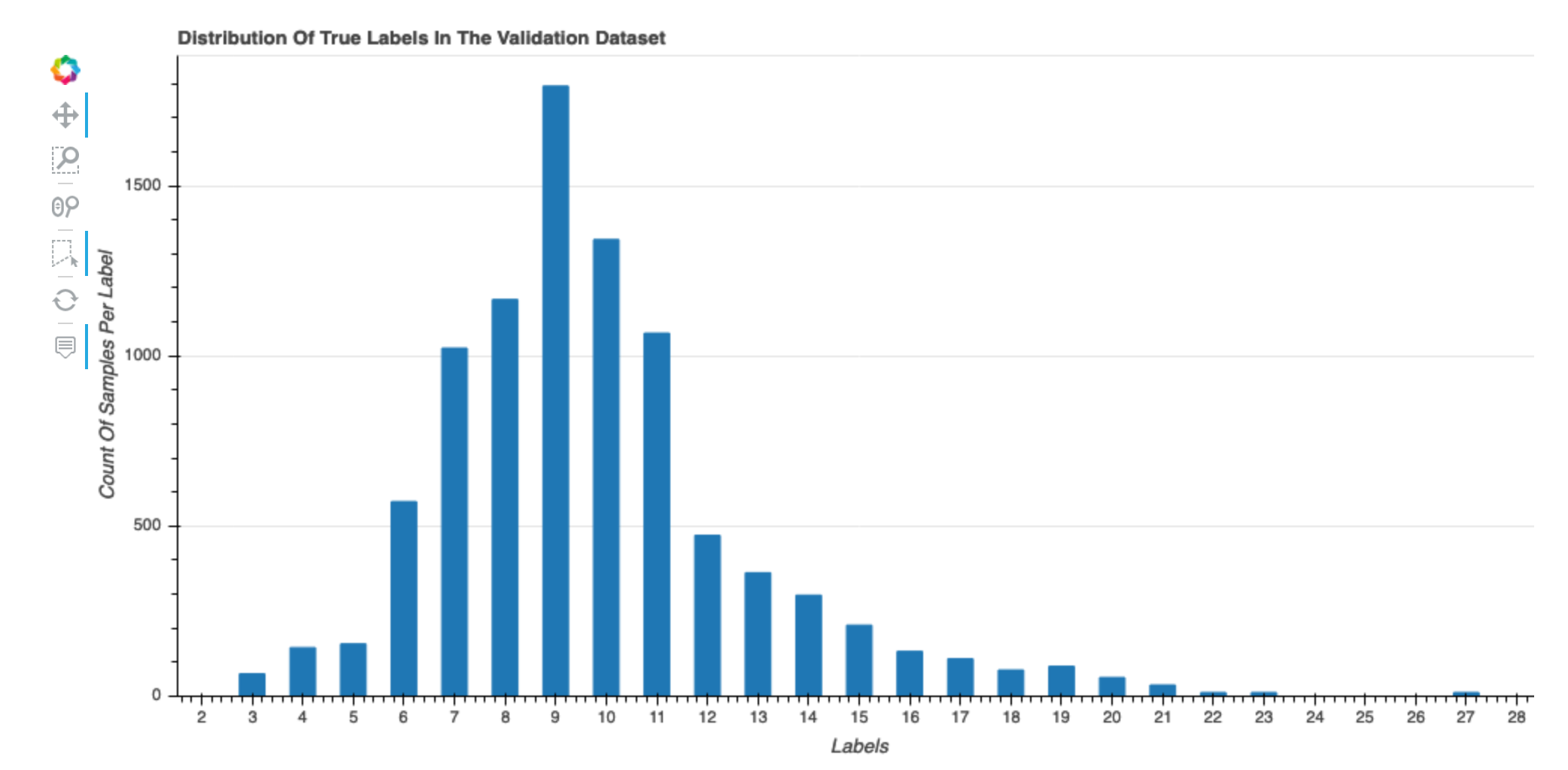
Distribusi label sebenarnya dari kumpulan data
Histogram ini menunjukkan distribusi kelas berlabel (untuk klasifikasi) atau nilai (untuk regresi) dalam kumpulan data asli Anda. Kecondongan dalam kumpulan data Anda dapat berkontribusi pada ketidakakuratan. Visualisasi ini tersedia untuk jenis model berikut: klasifikasi biner, multiklasifikasi, dan regresi.
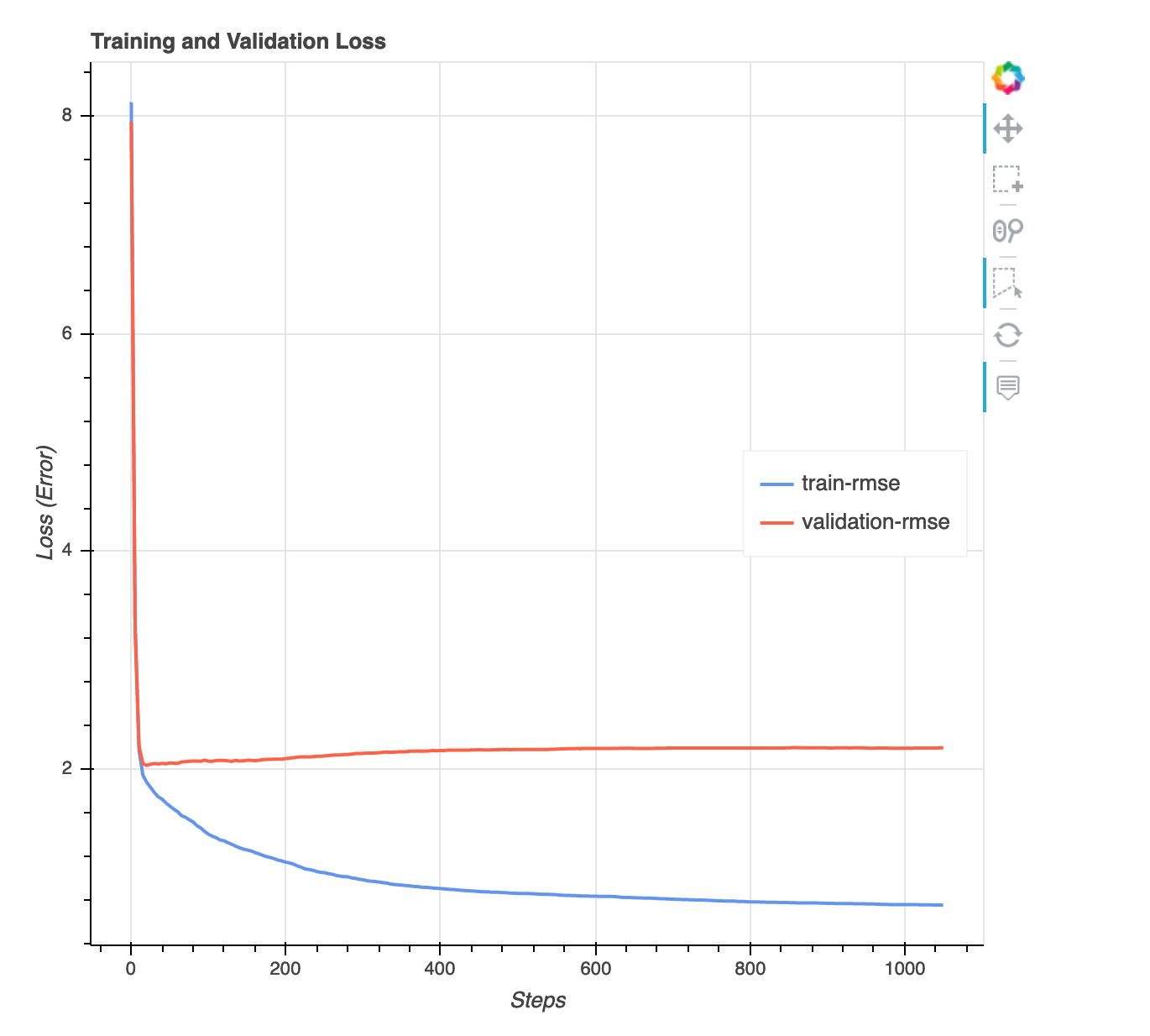
Grafik kerugian versus langkah
Ini adalah bagan garis yang menunjukkan perkembangan kerugian pada data pelatihan dan data validasi di seluruh langkah pelatihan. Kerugian adalah apa yang Anda definisikan dalam fungsi tujuan Anda, seperti kesalahan kuadrat rata-rata. Anda dapat mengukur apakah modelnya overfit atau underfit dari plot ini. Bagian ini juga memberikan wawasan yang dapat Anda gunakan untuk menentukan cara mengatasi masalah overfit dan underfit. Visualisasi ini tersedia untuk jenis model berikut: klasifikasi biner, multiklasifikasi, dan regresi.
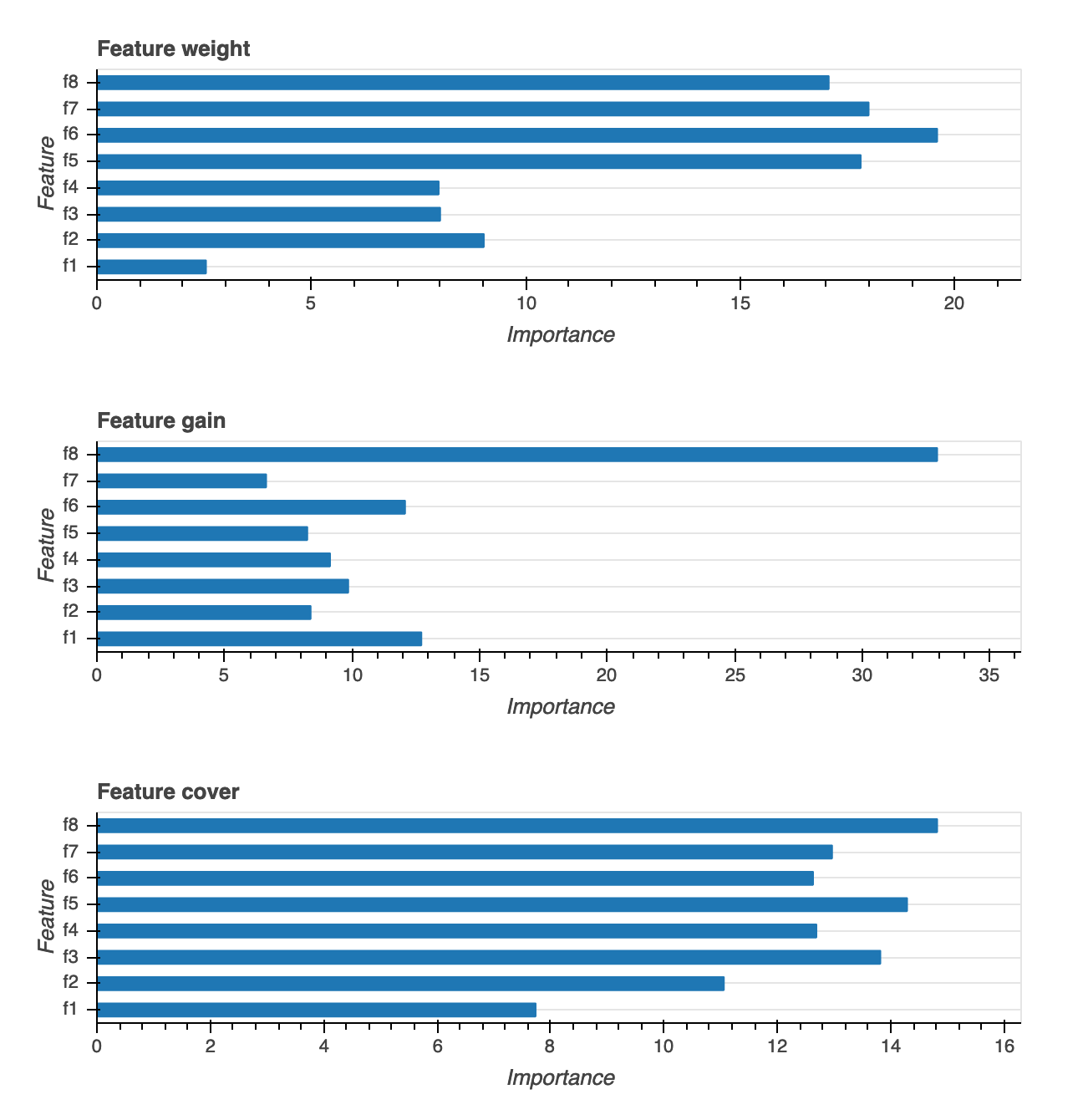
Pentingnya fitur
Ada tiga jenis visualisasi penting fitur yang disediakan: Berat, Kenaikan, dan Cakupan. Kami memberikan definisi rinci untuk masing-masing dari ketiganya dalam laporan. Visualisasi kepentingan fitur membantu Anda mempelajari fitur apa saja dalam kumpulan data pelatihan yang berkontribusi pada prediksi. Visualisasi kepentingan fitur tersedia untuk jenis model berikut: klasifikasi biner, multiklasifikasi, dan regresi.
Matriks kebingungan
Visualisasi ini hanya berlaku untuk model klasifikasi biner dan multiclass. Akurasi saja mungkin tidak cukup untuk mengevaluasi kinerja model. Untuk beberapa kasus penggunaan, seperti perawatan kesehatan dan deteksi penipuan, penting juga untuk mengetahui tingkat positif palsu dan tingkat negatif palsu. Matriks kebingungan memberi Anda dimensi tambahan untuk mengevaluasi kinerja model Anda.

Evaluasi matriks kebingungan
Bagian ini memberi Anda lebih banyak wawasan tentang metrik mikro, makro, dan tertimbang tentang presisi, penarikan, dan skor F1 untuk model Anda.
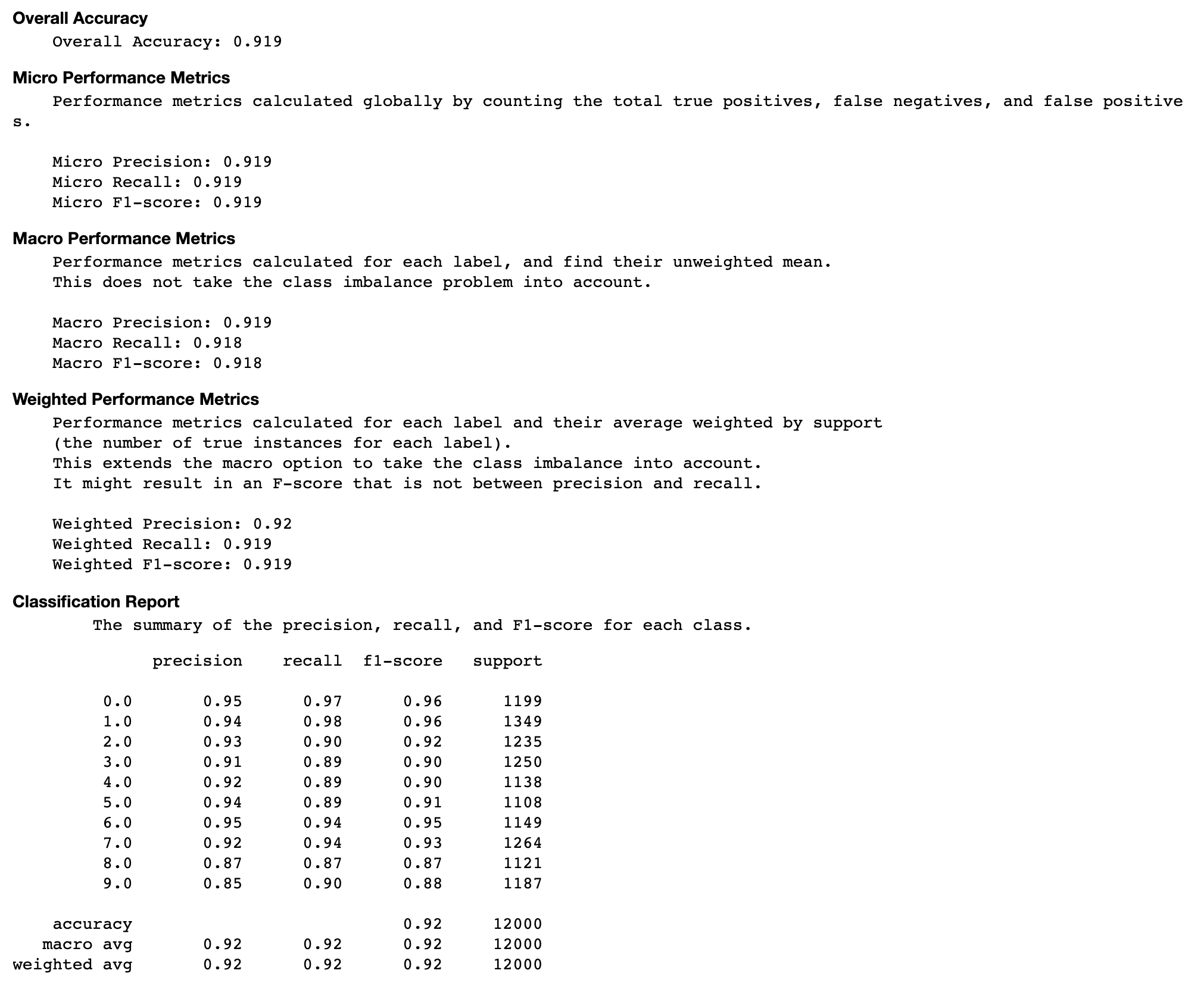
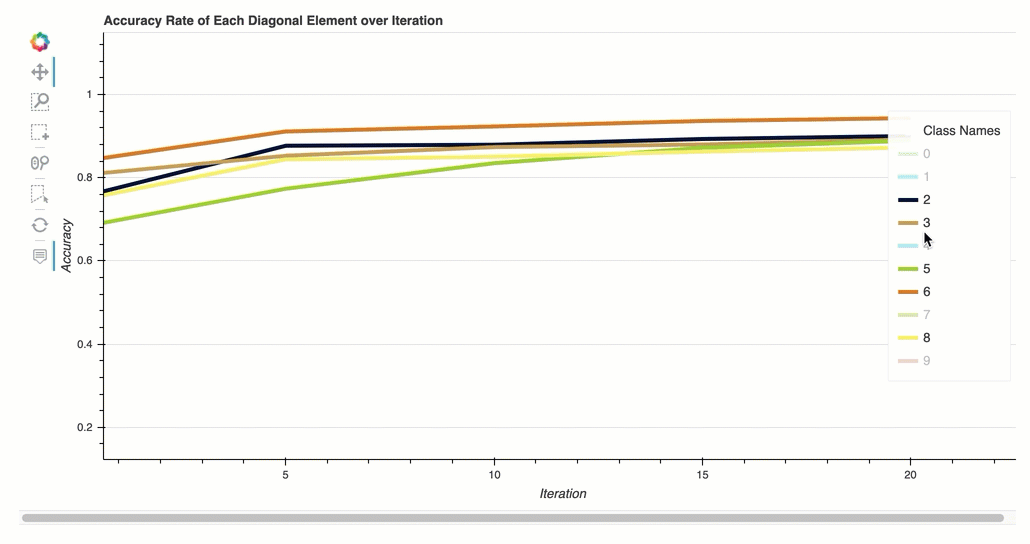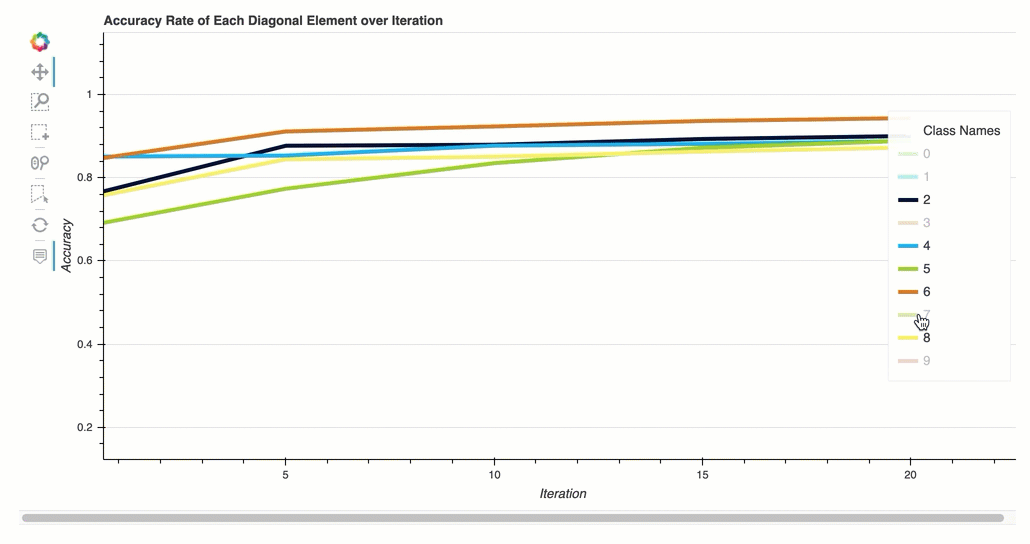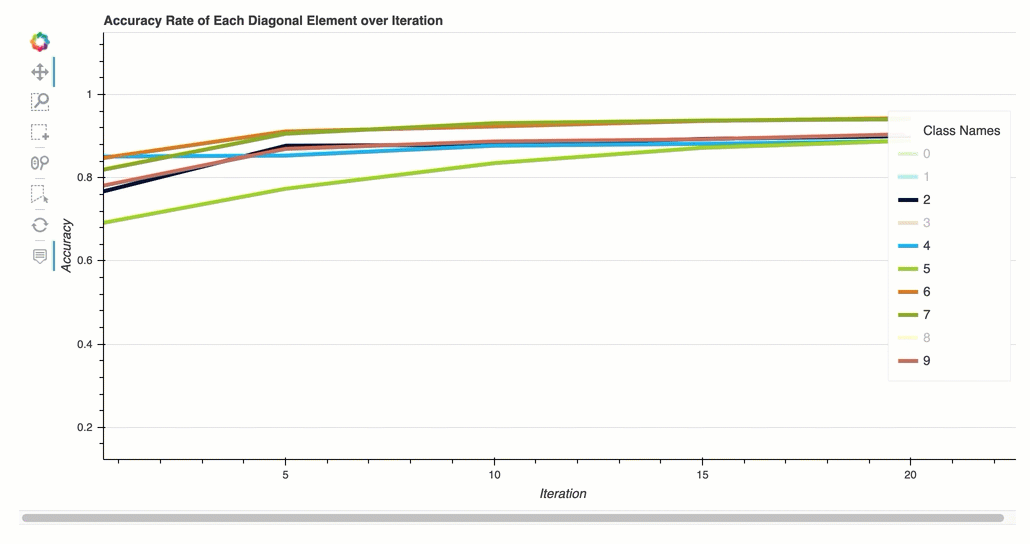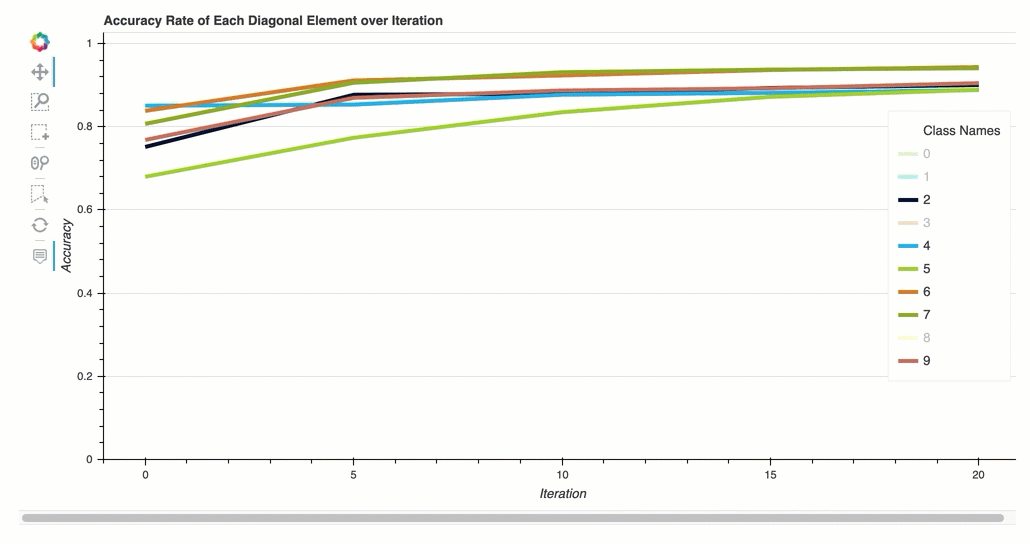
Tingkat akurasi setiap elemen diagonal melalui iterasi
Visualisasi ini hanya berlaku untuk klasifikasi biner dan model klasifikasi multikelas. Ini adalah bagan garis yang memplot nilai diagonal dalam matriks kebingungan di seluruh langkah pelatihan untuk setiap kelas. Plot ini menunjukkan kepada Anda bagaimana keakuratan setiap kelas berlangsung selama langkah-langkah pelatihan. Anda dapat mengidentifikasi kelas yang berkinerja buruk dari plot ini.
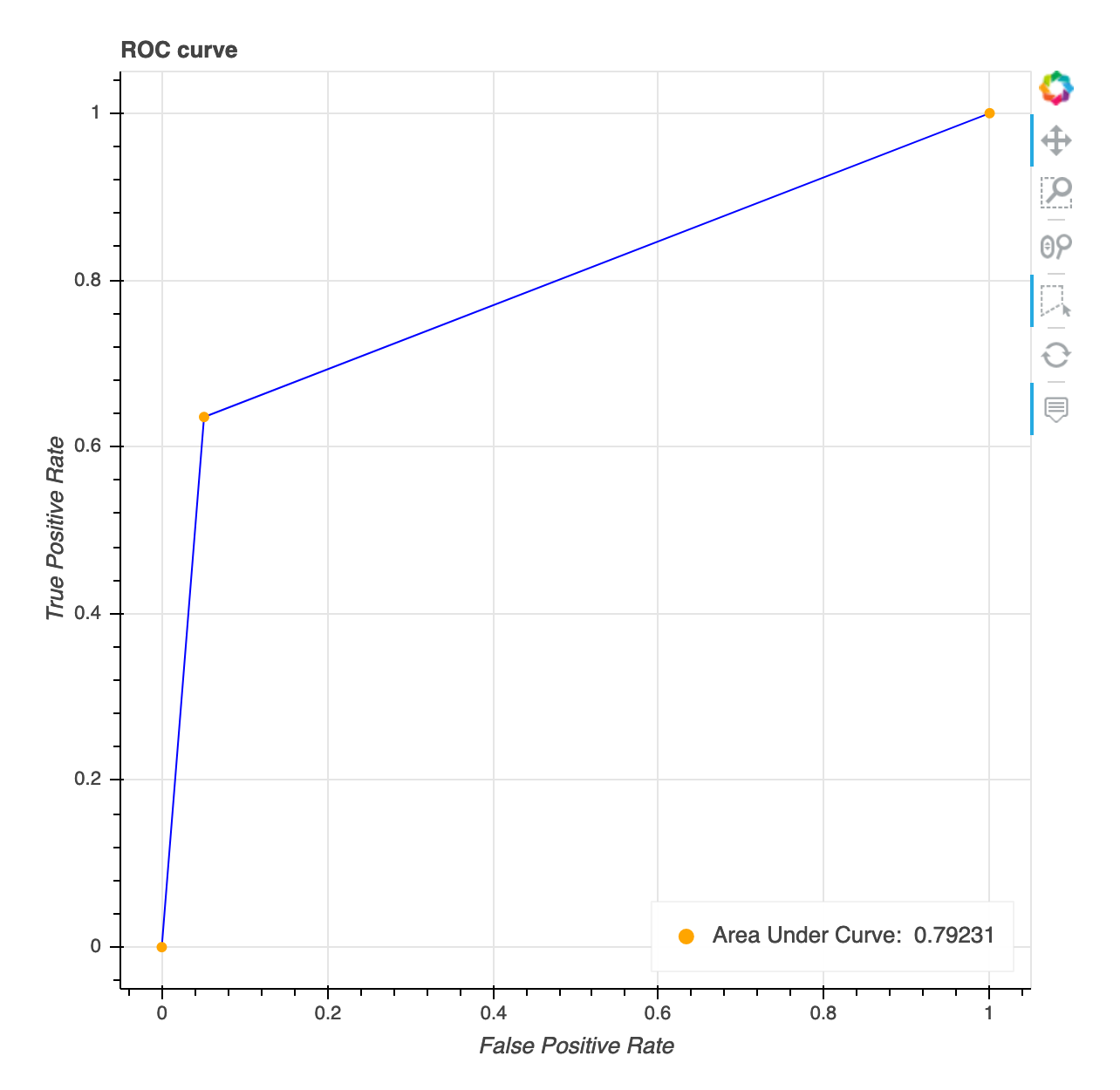
Kurva karakteristik operasi penerima
Visualisasi ini hanya berlaku untuk model klasifikasi biner. Kurva Karakteristik Operasi Penerima biasanya digunakan untuk mengevaluasi kinerja model klasifikasi biner. Sumbu y dari kurva adalah True Positive Rate (TPF) dan sumbu x adalah laju positif palsu (FPR). Plot juga menampilkan nilai untuk area di bawah kurva (AUC). Semakin tinggi nilai AUC, semakin prediktif pengklasifikasi Anda. Anda juga dapat menggunakan kurva ROC untuk memahami trade-off antara TPR dan FPR dan mengidentifikasi ambang klasifikasi optimal untuk kasus penggunaan Anda. Ambang klasifikasi dapat disesuaikan untuk menyesuaikan perilaku model untuk mengurangi lebih dari satu atau beberapa jenis kesalahan (FP/FN).
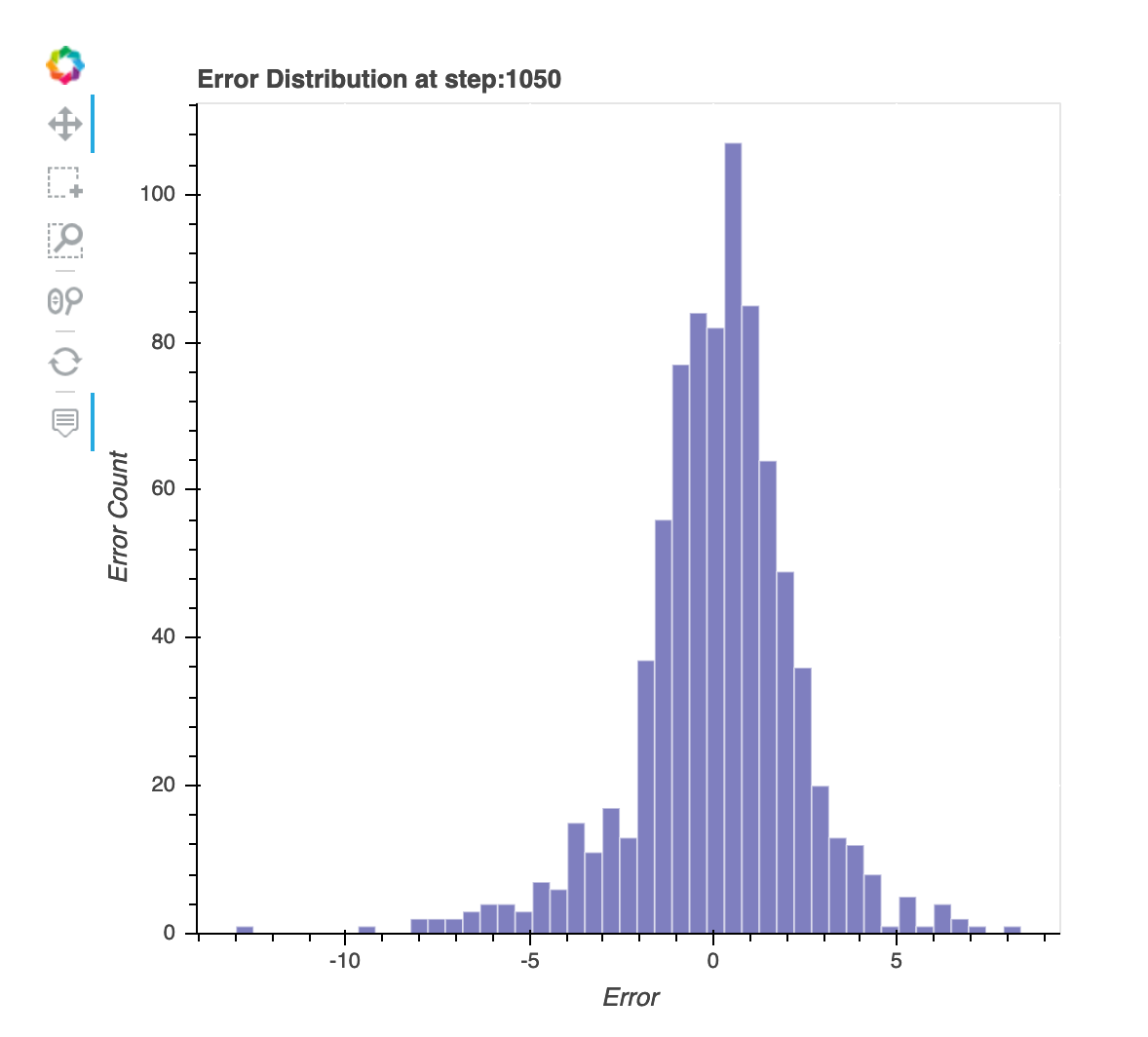
Distribusi residu pada langkah terakhir yang disimpan
Visualisasi ini adalah bagan kolom yang menunjukkan distribusi sisa pada langkah terakhir yang ditangkap Debugger. Dalam visualisasi ini, Anda dapat memeriksa apakah distribusi residu mendekati distribusi normal yang berpusat pada nol. Jika residu miring, fitur Anda mungkin tidak cukup untuk memprediksi label.
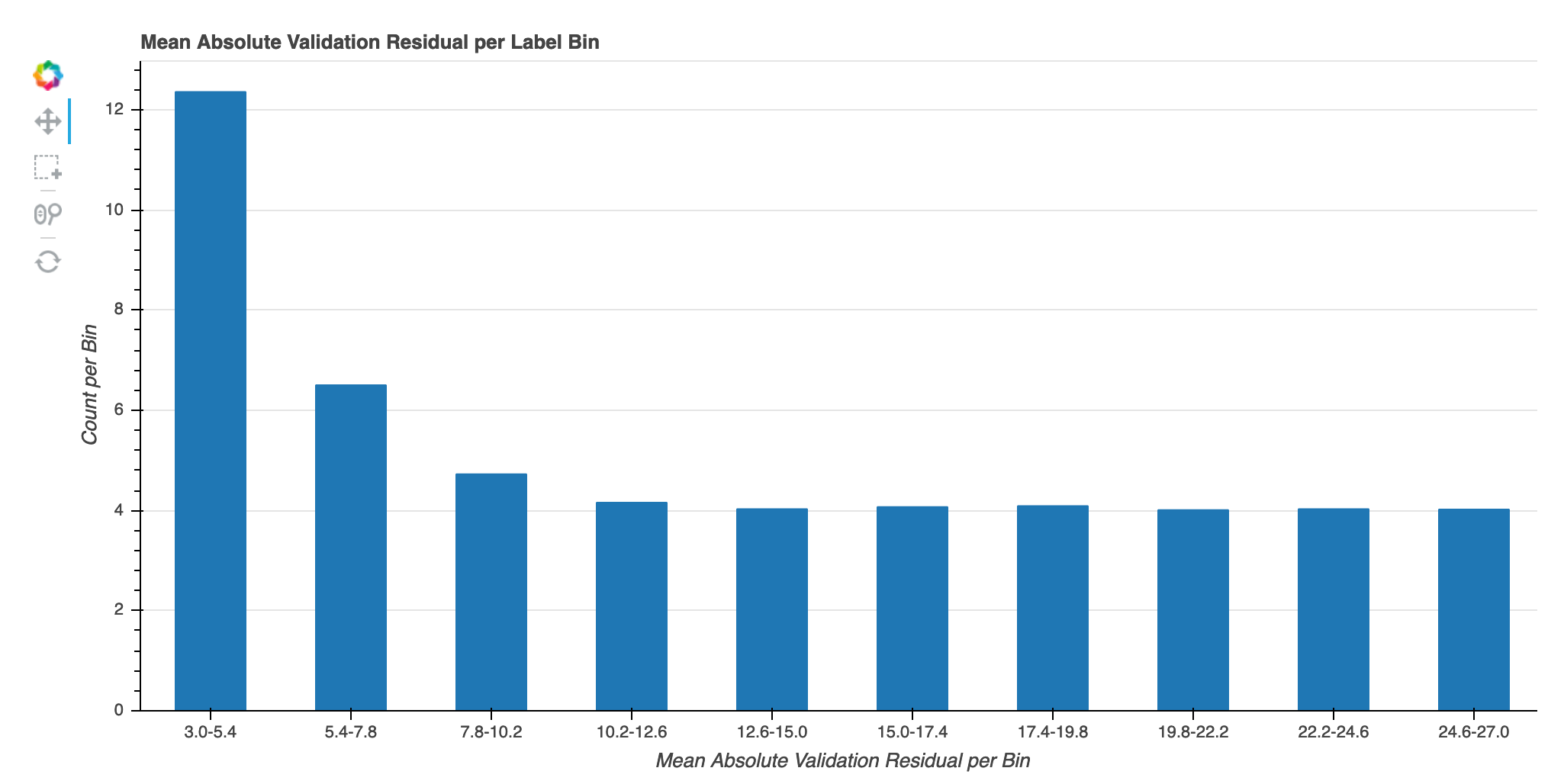
Kesalahan validasi absolut per bin label melalui iterasi
Visualisasi ini hanya berlaku untuk model regresi. Nilai target aktual dibagi menjadi 10 interval. Visualisasi ini menunjukkan bagaimana kesalahan validasi berkembang untuk setiap interval selama langkah-langkah pelatihan dalam plot baris. Kesalahan validasi absolut adalah nilai absolut perbedaan antara prediksi dan aktual selama validasi. Anda dapat mengidentifikasi interval berkinerja buruk dari visualisasi ini.