Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Gunakan Pembelajaran Penguatan dengan Amazon SageMaker AI
Pembelajaran penguatan (RL) menggabungkan bidang-bidang seperti ilmu komputer, ilmu saraf, dan psikologi untuk menentukan bagaimana memetakan situasi ke tindakan untuk memaksimalkan sinyal hadiah numerik. Gagasan tentang sinyal hadiah di RL ini berasal dari penelitian ilmu saraf tentang bagaimana otak manusia membuat keputusan tentang tindakan mana yang memaksimalkan hadiah dan meminimalkan hukuman. Dalam kebanyakan situasi, manusia tidak diberi instruksi eksplisit tentang tindakan mana yang harus diambil, melainkan harus mempelajari tindakan mana yang menghasilkan imbalan paling langsung, dan bagaimana tindakan tersebut memengaruhi situasi dan konsekuensi masa depan.
Masalah RL diformalkan menggunakan proses keputusan Markov (MDPs) yang berasal dari teori sistem dinamis. MDP bertujuan untuk menangkap detail tingkat tinggi dari masalah nyata yang dihadapi agen pembelajaran selama beberapa periode waktu dalam upaya mencapai beberapa tujuan akhir. Agen pembelajaran harus dapat menentukan keadaan lingkungannya saat ini dan mengidentifikasi kemungkinan tindakan yang mempengaruhi keadaan agen pembelajaran saat ini. Selanjutnya, tujuan agen pembelajaran harus berkorelasi kuat dengan keadaan lingkungan. Solusi untuk masalah yang dirumuskan dengan cara ini dikenal sebagai metode pembelajaran penguatan.
Apa perbedaan antara paradigma pembelajaran penguatan, pengawasan, dan tanpa pengawasan?
Pembelajaran mesin dapat dibagi menjadi tiga paradigma pembelajaran yang berbeda: diawasi, tidak diawasi, dan penguatan.
Dalam pembelajaran yang diawasi, supervisor eksternal memberikan serangkaian pelatihan contoh berlabel. Setiap contoh berisi informasi tentang suatu situasi, termasuk dalam kategori, dan memiliki label yang mengidentifikasi kategori yang menjadi miliknya. Tujuan dari pembelajaran yang diawasi adalah untuk menggeneralisasi untuk memprediksi dengan benar dalam situasi yang tidak ada dalam data pelatihan.
Sebaliknya, RL menangani masalah interaktif, sehingga tidak mungkin untuk mengumpulkan semua contoh situasi yang mungkin dengan label yang benar yang mungkin dihadapi agen. Jenis pembelajaran ini paling menjanjikan ketika seorang agen dapat secara akurat belajar dari pengalamannya sendiri dan menyesuaikannya.
Dalam pembelajaran tanpa pengawasan, seorang agen belajar dengan mengungkap struktur dalam data yang tidak berlabel. Sementara agen RL mungkin mendapat manfaat dari mengungkap struktur berdasarkan pengalamannya, satu-satunya tujuan RL adalah untuk memaksimalkan sinyal hadiah.
Topik
Mengapa Pembelajaran Penguatan Penting?
RL sangat cocok untuk memecahkan masalah besar dan kompleks, seperti manajemen rantai pasokan, sistem HVAC, robotika industri, kecerdasan buatan game, sistem dialog, dan kendaraan otonom. Karena model RL belajar dengan proses terus menerus menerima penghargaan dan hukuman untuk setiap tindakan yang diambil oleh agen, adalah mungkin untuk melatih sistem untuk membuat keputusan di bawah ketidakpastian dan dalam lingkungan yang dinamis.
Proses Keputusan Markov (MDP)
RL didasarkan pada model yang disebut Markov Decision Processes (MDPs). MDP terdiri dari serangkaian langkah waktu. Setiap langkah waktu terdiri dari yang berikut:
- Lingkungan
-
Mendefinisikan ruang di mana model RL beroperasi. Ini bisa berupa lingkungan dunia nyata atau simulator. Misalnya, jika Anda melatih kendaraan otonom fisik di jalan fisik, itu akan menjadi lingkungan dunia nyata. Jika Anda melatih program komputer yang memodelkan kendaraan otonom yang mengemudi di jalan, itu akan menjadi simulator.
- Status
-
Menentukan semua informasi tentang lingkungan dan langkah-langkah masa lalu yang relevan dengan masa depan. Misalnya, dalam model RL di mana robot dapat bergerak ke segala arah kapan saja, posisi robot pada langkah waktu saat ini adalah keadaan, karena jika kita tahu di mana robot itu berada, tidak perlu mengetahui langkah-langkah yang diambil untuk sampai ke sana.
- Tindakan
-
Apa yang dilakukan agen. Misalnya, robot mengambil langkah maju.
- Hadiah
-
Angka yang mewakili nilai negara yang dihasilkan dari tindakan terakhir yang diambil agen. Misalnya, jika tujuannya adalah agar robot menemukan harta karun, hadiah untuk menemukan harta karun mungkin 5, dan hadiah karena tidak menemukan harta karun mungkin 0. Model RL mencoba menemukan strategi yang mengoptimalkan imbalan kumulatif dalam jangka panjang. Strategi ini disebut kebijakan.
- Observasi
-
Informasi tentang keadaan lingkungan yang tersedia untuk agen di setiap langkah. Ini mungkin seluruh negara bagian, atau mungkin hanya bagian dari negara. Misalnya, agen dalam model bermain catur akan dapat mengamati seluruh keadaan papan pada langkah apa pun, tetapi robot dalam labirin mungkin hanya dapat mengamati sebagian kecil labirin yang saat ini ditempati.
Biasanya, pelatihan di RL terdiri dari banyak episode. Episode terdiri dari semua langkah waktu dalam MDP dari keadaan awal hingga lingkungan mencapai status terminal.
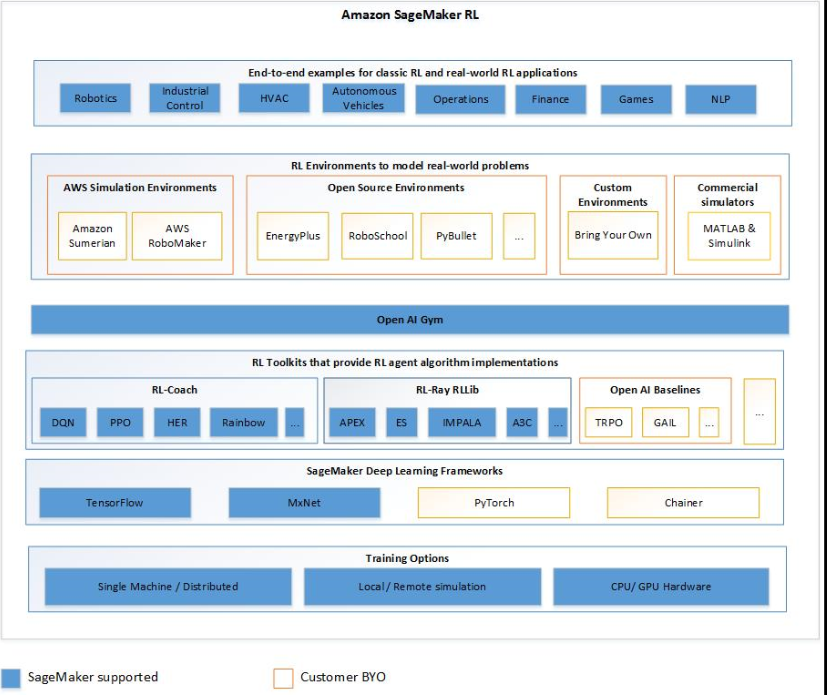
Fitur Utama Amazon SageMaker AI RL
Untuk melatih model RL di SageMaker AI RL, gunakan komponen berikut:
-
Kerangka pembelajaran mendalam (DL). Saat ini, SageMaker AI mendukung RL in TensorFlow dan Apache MXNet.
-
Toolkit RL. Toolkit RL mengelola interaksi antara agen dan lingkungan dan menyediakan berbagai pilihan algoritma RL canggih. SageMaker AI mendukung toolkit Intel Coach dan Ray RLLib. Untuk informasi tentang Intel Coach, lihat https://nervanasystems.github.io/coach/
. Untuk informasi tentang Ray RLLib, lihat. https://ray.readthedocs.io/en/latest/rllib.html -
Lingkungan RL. Anda dapat menggunakan lingkungan khusus, lingkungan sumber terbuka, atau lingkungan komersial. Untuk informasi, lihat Lingkungan RL di Amazon AI SageMaker.
Diagram berikut menunjukkan komponen RL yang didukung dalam SageMaker AI RL.
Notebook Contoh Pembelajaran Penguatan
Untuk contoh kode lengkap, lihat contoh buku catatan pembelajaran penguatan
