Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menguji model dengan varian produksi
Dalam alur kerja produksi, ilmuwan dan insinyur data sering mencoba meningkatkan kinerja menggunakan berbagai metode, seperti, pelatihan tentang data tambahan atau yang lebih baruPenyetelan model otomatis dengan AI SageMaker, meningkatkan pemilihan fitur, menggunakan instance yang diperbarui dengan lebih baik, dan wadah penyajian. Anda dapat menggunakan varian produksi untuk membandingkan model, instans, dan kontainer Anda, dan memilih kandidat berkinerja terbaik untuk menanggapi permintaan inferensi.
Dengan titik akhir multi-varian SageMaker AI, Anda dapat mendistribusikan permintaan pemanggilan titik akhir di beberapa varian produksi dengan menyediakan distribusi lalu lintas untuk setiap varian, atau Anda dapat memanggil varian tertentu secara langsung untuk setiap permintaan. Dalam topik ini, kita melihat kedua metode untuk menguji model ML.
Topik
Uji model dengan menentukan distribusi lalu lintas
Untuk menguji beberapa model dengan mendistribusikan lalu lintas di antara mereka, tentukan persentase lalu lintas yang diarahkan ke setiap model dengan menentukan bobot untuk setiap varian produksi dalam konfigurasi titik akhir. Untuk informasi, lihat CreateEndpointConfig. Diagram berikut menunjukkan cara kerjanya secara lebih rinci.
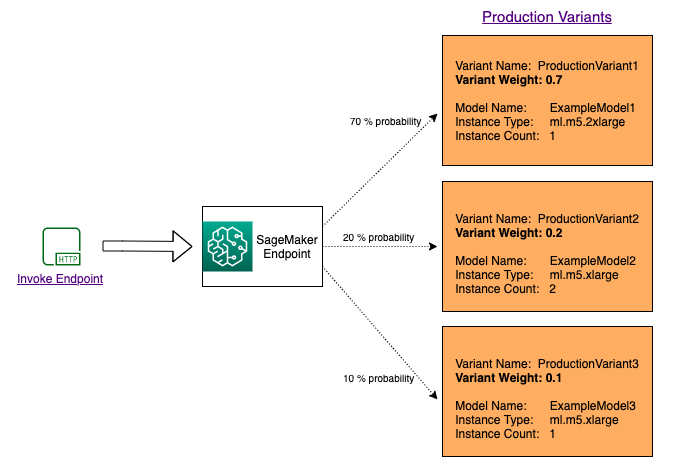
Uji model dengan menggunakan varian tertentu
Untuk menguji beberapa model dengan menjalankan model tertentu untuk setiap permintaan, tentukan versi spesifik model yang ingin Anda panggil dengan memberikan nilai untuk TargetVariant parameter saat Anda memanggil. InvokeEndpoint SageMaker AI memastikan bahwa permintaan diproses oleh varian produksi yang Anda tentukan. Jika Anda telah menyediakan distribusi lalu lintas dan menentukan nilai untuk TargetVariant parameter, perutean yang ditargetkan akan mengesampingkan distribusi lalu lintas acak. Diagram berikut menunjukkan cara kerjanya secara lebih rinci.
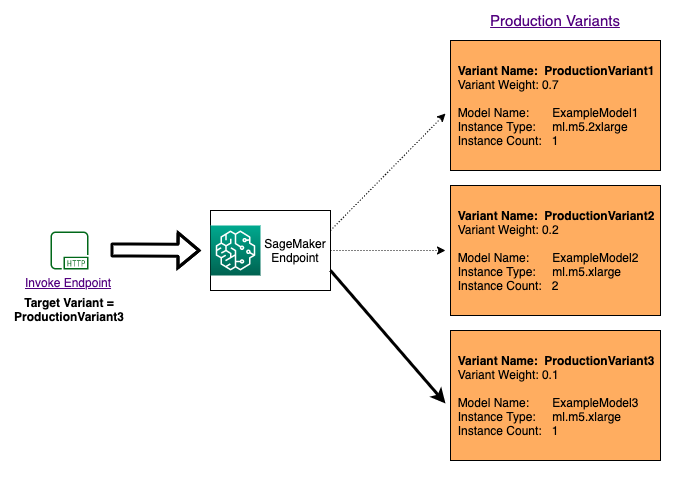
Contoh A/B uji model
Melakukan A/B pengujian antara model baru dan model lama dengan lalu lintas produksi dapat menjadi langkah terakhir yang efektif dalam proses validasi untuk model baru. Dalam A/B pengujian, Anda menguji berbagai varian model Anda dan membandingkan kinerja masing-masing varian. Jika versi model yang lebih baru memberikan kinerja yang lebih baik daripada versi yang ada sebelumnya, ganti versi lama model dengan versi baru dalam produksi.
Contoh berikut menunjukkan bagaimana melakukan pengujian A/B model. Untuk contoh buku catatan yang mengimplementasikan contoh ini, lihat "A/B Menguji model ML dalam produksi
Langkah 1: Buat dan terapkan model
Pertama, kami menentukan di mana model kami berada di Amazon S3. Lokasi-lokasi ini digunakan saat kami menerapkan model kami dalam langkah-langkah selanjutnya:
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
Selanjutnya, kita membuat objek model dengan data gambar dan model. Objek model ini digunakan untuk menyebarkan varian produksi pada titik akhir. Model dikembangkan dengan melatih model ML pada kumpulan data yang berbeda, algoritme atau kerangka kerja ML yang berbeda, dan hiperparameter yang berbeda:
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
Kami sekarang membuat dua varian produksi, masing-masing dengan model dan persyaratan sumber daya yang berbeda (jenis dan jumlah instance). Ini memungkinkan Anda untuk juga menguji model pada jenis instans yang berbeda.
Kami menetapkan initial_weight 1 untuk kedua varian. Ini berarti bahwa 50% dari permintaan pergi keVariant1, dan 50% sisanya dari permintaan keVariant2. Jumlah bobot di kedua varian adalah 2 dan setiap varian memiliki penetapan bobot 1. Ini berarti bahwa setiap varian menerima 1/2, atau 50%, dari total lalu lintas.
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
Akhirnya kami siap untuk menerapkan varian produksi ini pada titik akhir SageMaker AI.
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
Langkah 2: Panggil model yang digunakan
Sekarang kami mengirim permintaan ke titik akhir ini untuk mendapatkan kesimpulan secara real time. Kami menggunakan distribusi lalu lintas dan penargetan langsung.
Pertama, kami menggunakan distribusi lalu lintas yang kami konfigurasikan pada langkah sebelumnya. Setiap respons inferensi berisi nama varian produksi yang memproses permintaan, sehingga kita dapat melihat bahwa lalu lintas ke dua varian produksi kira-kira sama.
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker AI memancarkan metrik seperti Latency dan Invocations untuk setiap varian di Amazon. CloudWatch Untuk daftar lengkap metrik yang dipancarkan SageMaker AI, lihat. Metrik Amazon SageMaker AI di Amazon CloudWatch Mari kueri CloudWatch untuk mendapatkan jumlah pemanggilan per varian, untuk menunjukkan bagaimana pemanggilan dibagi di seluruh varian secara default:
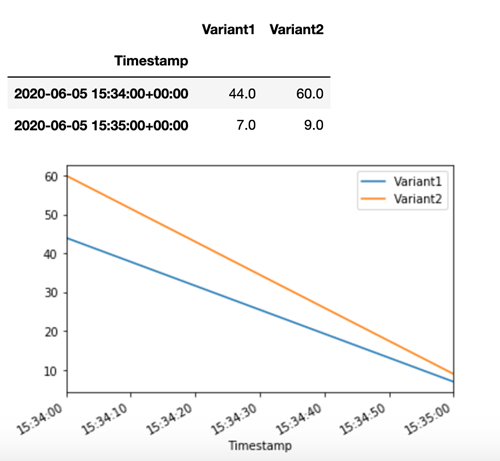
Sekarang mari kita memanggil versi tertentu dari model dengan menentukan Variant1 sebagai TargetVariant dalam panggilan ke. invoke_endpoint
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
Untuk mengonfirmasi bahwa semua pemanggilan baru diproses olehVariant1, kita dapat CloudWatch melakukan kueri untuk mendapatkan jumlah pemanggilan per varian. Kami melihat bahwa untuk pemanggilan terbaru (stempel waktu terbaru), semua permintaan diproses olehVariant1, seperti yang telah kami tentukan. Tidak ada doa yang dibuat untuk. Variant2
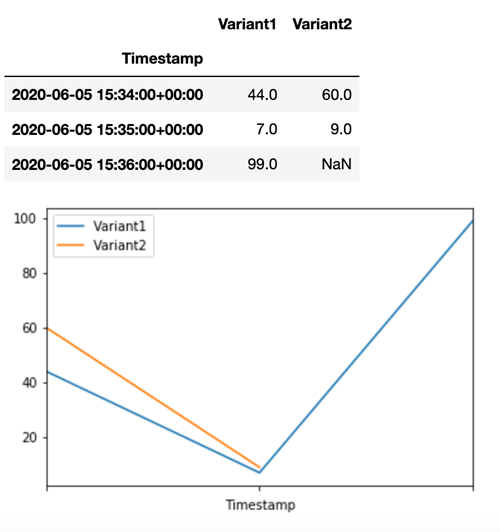
Langkah 3: Evaluasi kinerja model
Untuk melihat versi model mana yang berkinerja lebih baik, mari kita evaluasi akurasi, presisi, penarikan, skor F1, dan Penerima yang beroperasi charactersistic/Area di bawah kurva untuk setiap varian. Pertama, mari kita lihat metrik ini untukVariant1:
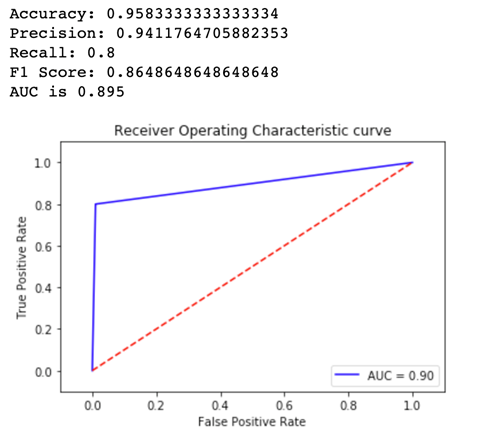
Sekarang mari kita lihat metrik untukVariant2:
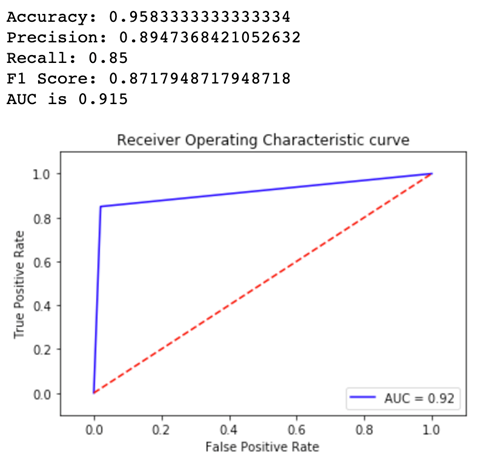
Untuk sebagian besar metrik yang kami tentukan, Variant2 berkinerja lebih baik, jadi inilah yang ingin kami gunakan dalam produksi.
Langkah 4: Tingkatkan lalu lintas ke model terbaik
Sekarang kami telah menentukan bahwa Variant2 kinerjanya lebih baik daripadaVariant1, kami mengalihkan lebih banyak lalu lintas ke sana. Kami dapat terus menggunakan TargetVariant untuk memanggil varian model tertentu, tetapi pendekatan yang lebih sederhana adalah memperbarui bobot yang ditetapkan untuk setiap varian dengan memanggil. UpdateEndpointWeightsAndCapacities Ini mengubah distribusi lalu lintas ke varian produksi Anda tanpa memerlukan pembaruan ke titik akhir Anda. Ingat dari bagian pengaturan bahwa kami menetapkan bobot varian untuk membagi lalu lintas 50/50. CloudWatch Metrik untuk total pemanggilan untuk setiap varian di bawah ini menunjukkan kepada kita pola pemanggilan untuk setiap varian:
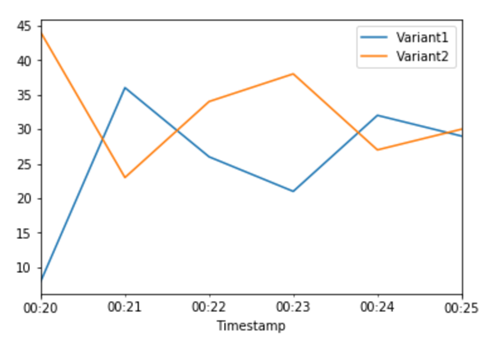
Sekarang kita menggeser 75% dari lalu lintas ke Variant2 dengan menetapkan bobot baru untuk setiap varian menggunakan. UpdateEndpointWeightsAndCapacities SageMaker AI sekarang mengirimkan 75% dari permintaan inferensi ke Variant2 dan sisanya 25% dari permintaan keVariant1.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
CloudWatch Metrik untuk pemanggilan total untuk setiap varian menunjukkan kepada kita pemanggilan yang lebih tinggi daripada untuk: Variant2 Variant1
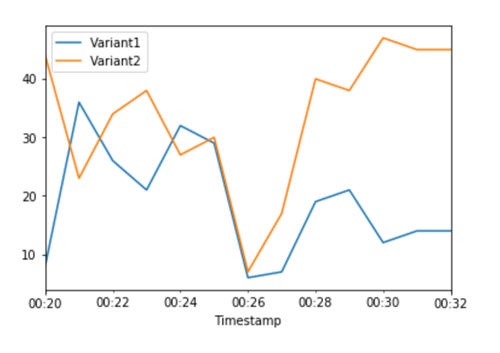
Kami dapat terus memantau metrik kami, dan ketika kami puas dengan kinerja varian, kami dapat merutekan 100% lalu lintas ke varian itu. Kami gunakan UpdateEndpointWeightsAndCapacitiesuntuk memperbarui tugas lalu lintas untuk varian. Berat untuk Variant1 diatur ke 0 dan berat untuk Variant2 diatur ke 1. SageMaker AI sekarang mengirimkan 100% dari semua permintaan inferensi keVariant2.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
CloudWatch Metrik untuk total pemanggilan untuk setiap varian menunjukkan bahwa semua permintaan inferensi sedang diproses oleh Variant2 dan tidak ada permintaan inferensi yang diproses oleh. Variant1
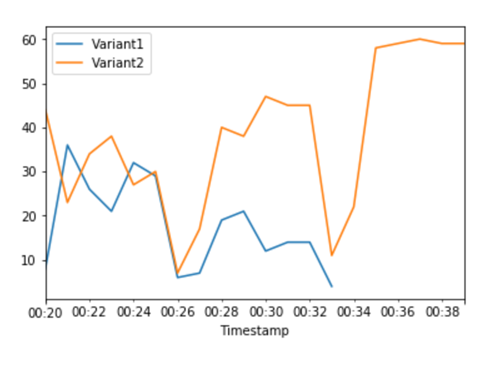
Anda sekarang dapat memperbarui titik akhir dengan aman dan menghapus Variant1 dari titik akhir Anda. Anda juga dapat terus menguji model baru dalam produksi dengan menambahkan varian baru ke titik akhir Anda dan mengikuti langkah 2 - 4.
