Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bagian ini menjelaskan alur kerja machine learning (ML) yang khas dan menjelaskan cara menyelesaikan tugas-tugas tersebut dengan Amazon SageMaker AI.
Dalam pembelajaran mesin, Anda mengajarkan komputer untuk membuat prediksi atau kesimpulan. Pertama, Anda menggunakan algoritma dan contoh data untuk melatih model. Kemudian, Anda mengintegrasikan model Anda ke dalam aplikasi Anda untuk menghasilkan kesimpulan secara real time dan dalam skala besar.
Diagram berikut menunjukkan alur kerja khas untuk membuat model ML. Ini mencakup tiga tahap dalam aliran melingkar yang kita bahas secara lebih rinci melanjutkan diagram:
-
Hasilkan contoh data
-
Latih model
-
Menyebarkan model
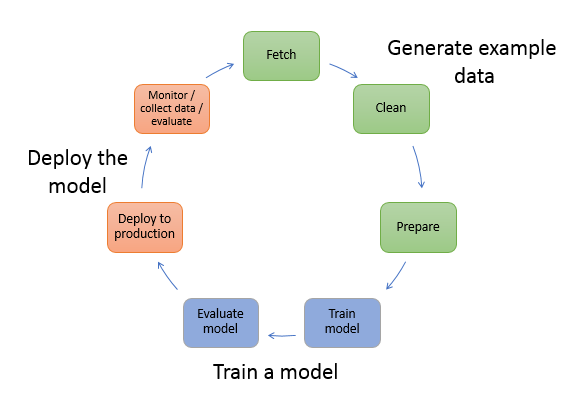
Diagram menunjukkan bagaimana melakukan tugas-tugas berikut dalam skenario yang paling umum:
-
Menghasilkan contoh data — Untuk melatih model, Anda memerlukan contoh data. Jenis data yang Anda butuhkan tergantung pada masalah bisnis yang Anda inginkan untuk dipecahkan oleh model tersebut. Ini berkaitan dengan kesimpulan yang Anda ingin model untuk menghasilkan. Misalnya, jika Anda ingin membuat model yang memprediksi angka dari gambar input digit tulisan tangan. Untuk melatih model ini, Anda memerlukan contoh gambar angka tulisan tangan.
Ilmuwan data sering mencurahkan waktu untuk mengeksplorasi dan memproses data contoh sebelum menggunakannya untuk pelatihan model. Untuk memproses data sebelumnya, Anda biasanya melakukan hal berikut:
-
Ambil data — Anda mungkin memiliki repositori data contoh internal, atau Anda mungkin menggunakan kumpulan data yang tersedia untuk umum. Biasanya, Anda menarik dataset atau dataset ke dalam satu repositori.
-
Bersihkan data — Untuk meningkatkan pelatihan model, periksa data dan bersihkan, sesuai kebutuhan. Misalnya, jika data Anda memiliki
country nameatribut dengan nilaiUnited StatesdanUS, Anda dapat mengedit data agar konsisten. -
Mempersiapkan atau mengubah data — Untuk meningkatkan kinerja, Anda dapat melakukan transformasi data tambahan. Misalnya, Anda dapat memilih untuk menggabungkan atribut untuk model yang memprediksi kondisi yang memerlukan de-icing pesawat terbang. Alih-alih menggunakan atribut suhu dan kelembaban secara terpisah, Anda dapat menggabungkan atribut tersebut menjadi atribut baru untuk mendapatkan model yang lebih baik.
Di SageMaker AI, Anda dapat memproses data contoh menggunakan SageMaker APIsSDK SageMaker Python
di lingkungan pengembangan terintegrasi (IDE). Dengan SDK for Python (Boto3), Anda dapat mengambil, menjelajahi, dan menyiapkan data Anda untuk pelatihan model. Untuk informasi tentang persiapan data, pemrosesan, dan transformasi data Anda, lihat Rekomendasi untuk memilih alat persiapan data yang tepat di SageMaker AIBeban kerja transformasi data dengan SageMaker Processing, danBuat, simpan, dan bagikan fitur dengan Feature Store. -
-
Melatih model — Pelatihan model mencakup pelatihan dan evaluasi model, sebagai berikut:
-
Melatih model — Untuk melatih model, Anda memerlukan algoritme atau model dasar yang telah dilatih sebelumnya. Algoritma yang Anda pilih tergantung pada sejumlah faktor. Untuk solusi bawaan, Anda dapat menggunakan salah satu algoritma yang SageMaker menyediakan. Untuk daftar algoritma yang disediakan oleh SageMaker dan pertimbangan terkait, lihat. Algoritma bawaan dan model yang telah dilatih sebelumnya di Amazon SageMaker Untuk solusi pelatihan berbasis UI yang menyediakan algoritme dan model, lihat. SageMaker JumpStart model terlatih
Anda juga membutuhkan sumber daya komputasi untuk pelatihan. Penggunaan sumber daya Anda tergantung pada ukuran kumpulan data pelatihan Anda dan seberapa cepat Anda membutuhkan hasilnya. Anda dapat menggunakan sumber daya mulai dari satu instans tujuan umum hingga kluster instans GPU terdistribusi. Untuk informasi selengkapnya, lihat Latih Model dengan Amazon SageMaker.
-
Mengevaluasi model — Setelah Anda melatih model Anda, Anda mengevaluasinya untuk menentukan apakah keakuratan kesimpulan dapat diterima. Untuk melatih dan mengevaluasi model Anda, gunakan SageMaker Python SDK
untuk mengirim permintaan ke model untuk inferensi melalui salah satu yang tersedia. IDEs Untuk informasi selengkapnya tentang mengevaluasi model Anda, lihatPemantauan kualitas data dan model dengan Amazon SageMaker Model Monitor.
-
-
Menyebarkan model — Anda secara tradisional merekayasa ulang model sebelum Anda mengintegrasikannya dengan aplikasi Anda dan menerapkannya. Dengan layanan hosting SageMaker AI, Anda dapat menerapkan model Anda secara independen, yang memisahkannya dari kode aplikasi Anda. Untuk informasi selengkapnya, lihat Menyebarkan model untuk inferensi.
Pembelajaran mesin adalah siklus yang berkelanjutan. Setelah menerapkan model, Anda memantau kesimpulan, mengumpulkan lebih banyak data berkualitas tinggi, dan mengevaluasi model untuk mengidentifikasi penyimpangan. Anda kemudian meningkatkan akurasi kesimpulan Anda dengan memperbarui data pelatihan Anda untuk memasukkan data berkualitas tinggi yang baru dikumpulkan. Saat lebih banyak contoh data tersedia, Anda terus melatih ulang model Anda untuk meningkatkan akurasi.
