Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Amazon SageMaker AI Random Cut Forest (RCF) adalah algoritma tanpa pengawasan untuk mendeteksi titik data anomali dalam kumpulan data. Ini adalah pengamatan yang menyimpang dari data yang terstruktur atau berpola dengan baik. Anomali dapat bermanifestasi sebagai lonjakan tak terduga dalam data deret waktu, jeda periodisitas, atau titik data yang tidak dapat diklasifikasikan. Mereka mudah dijelaskan dalam hal itu, ketika dilihat dalam plot, mereka sering mudah dibedakan dari data “biasa”. Memasukkan anomali ini dalam kumpulan data dapat secara drastis meningkatkan kompleksitas tugas pembelajaran mesin karena data “reguler” sering dapat dijelaskan dengan model sederhana.
Ide utama di balik algoritma RCF adalah untuk membuat hutan pohon di mana setiap pohon diperoleh dengan menggunakan partisi sampel data pelatihan. Misalnya, sampel acak dari data input ditentukan terlebih dahulu. Sampel acak kemudian dipartisi sesuai dengan jumlah pohon di hutan. Setiap pohon diberi partisi seperti itu dan mengatur subset poin itu menjadi pohon k-d. Skor anomali yang ditetapkan ke titik data oleh pohon didefinisikan sebagai perubahan yang diharapkan dalam kompleksitas pohon sebagai hasil menambahkan titik itu ke pohon; yang, dalam perkiraan, berbanding terbalik dengan kedalaman yang dihasilkan dari titik di pohon. Hutan tebang acak memberikan skor anomali dengan menghitung skor rata-rata dari setiap pohon penyusun dan menskalakan hasilnya sehubungan dengan ukuran sampel. Algoritma RCF didasarkan pada yang dijelaskan dalam referensi [1].
Sampel Data Secara Acak
Langkah pertama dalam algoritma RCF adalah mendapatkan sampel acak dari data pelatihan. Secara khusus, misalkan kita menginginkan sampel ukuran
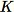 dari
dari
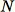 total titik data. Jika data pelatihan cukup kecil, seluruh kumpulan data dapat digunakan, dan kami dapat menggambar
elemen secara acak dari set ini. Namun, seringkali data pelatihan terlalu besar untuk muat sekaligus, dan pendekatan ini tidak layak. Sebagai gantinya, kami menggunakan teknik yang disebut reservoir sampling.
total titik data. Jika data pelatihan cukup kecil, seluruh kumpulan data dapat digunakan, dan kami dapat menggambar
elemen secara acak dari set ini. Namun, seringkali data pelatihan terlalu besar untuk muat sekaligus, dan pendekatan ini tidak layak. Sebagai gantinya, kami menggunakan teknik yang disebut reservoir sampling.
Reservoir sampling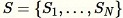 di mana elemen dalam dataset hanya dapat diamati satu per satu atau dalam batch. Faktanya, pengambilan sampel reservoir bekerja bahkan ketika tidak
diketahui apriori. Jika hanya satu sampel yang diminta, seperti kapan
di mana elemen dalam dataset hanya dapat diamati satu per satu atau dalam batch. Faktanya, pengambilan sampel reservoir bekerja bahkan ketika tidak
diketahui apriori. Jika hanya satu sampel yang diminta, seperti kapan
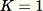 , algoritmanya seperti ini:
, algoritmanya seperti ini:
Algoritma: Pengambilan Sampel Reservoir
-
Masukan: dataset atau aliran data
-
Inisialisasi sampel acak
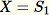
-
Untuk setiap sampel yang diamati
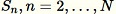 :
:-
Pilih nomor acak yang seragam
![Equation in text-form: \xi \in [0,1]](images/rcf6.jpg)
-
Jika
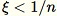
-
Set
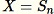
-
-
-
Kembali
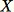
Algoritma ini memilih sampel acak sedemikian rupa sehingga
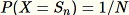 untuk semua
untuk semua
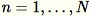 . Ketika
. Ketika
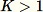 algoritma lebih rumit. Selain itu, perbedaan harus dibuat antara pengambilan sampel acak yang dengan dan tanpa penggantian. RCF melakukan pengambilan sampel reservoir tambahan tanpa penggantian pada data pelatihan berdasarkan algoritma yang dijelaskan dalam [2].
algoritma lebih rumit. Selain itu, perbedaan harus dibuat antara pengambilan sampel acak yang dengan dan tanpa penggantian. RCF melakukan pengambilan sampel reservoir tambahan tanpa penggantian pada data pelatihan berdasarkan algoritma yang dijelaskan dalam [2].
Melatih Model RCF dan Menghasilkan Inferensi
Langkah selanjutnya dalam RCF adalah membangun hutan potong acak menggunakan sampel data acak. Pertama, sampel dipartisi menjadi sejumlah partisi berukuran sama dengan jumlah pohon di hutan. Kemudian, setiap partisi dikirim ke pohon individu. Pohon secara rekursif mengatur partisinya menjadi pohon biner dengan mempartisi domain data ke dalam kotak pembatas.
Prosedur ini paling baik diilustrasikan dengan sebuah contoh. Misalkan sebuah pohon diberi kumpulan data dua dimensi berikut. Pohon yang sesuai diinisialisasi ke simpul akar:
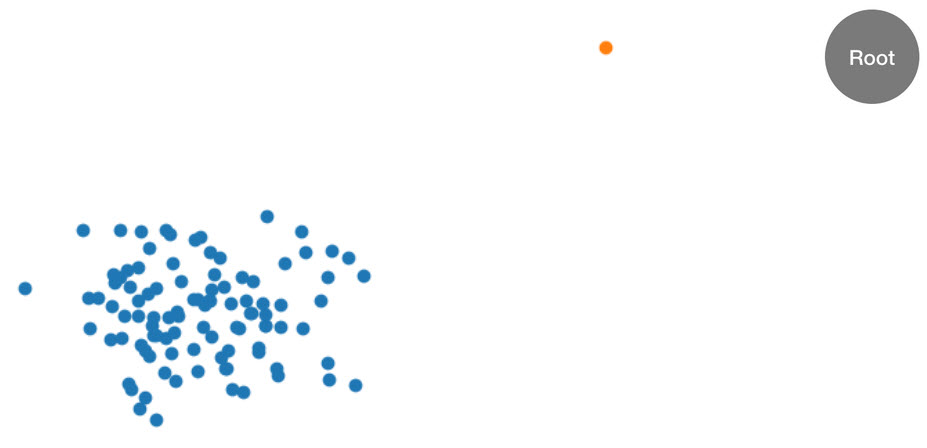
Gambar: Kumpulan data dua dimensi di mana sebagian besar data terletak pada cluster (biru) kecuali satu titik data anomali (oranye). Pohon diinisialisasi dengan simpul akar.
Algoritma RCF mengatur data ini dalam pohon dengan terlebih dahulu menghitung kotak pembatas data, memilih dimensi acak (memberi bobot lebih pada dimensi dengan “varians” yang lebih tinggi), dan kemudian secara acak menentukan posisi “potongan” hyperplane melalui dimensi itu. Dua subruang yang dihasilkan mendefinisikan sub pohon mereka sendiri. Dalam contoh ini, pemotongan terjadi untuk memisahkan titik tunggal dari sisa sampel. Tingkat pertama dari pohon biner yang dihasilkan terdiri dari dua simpul, satu yang akan terdiri dari subpohon titik di sebelah kiri potongan awal dan yang lainnya mewakili titik tunggal di sebelah kanan.
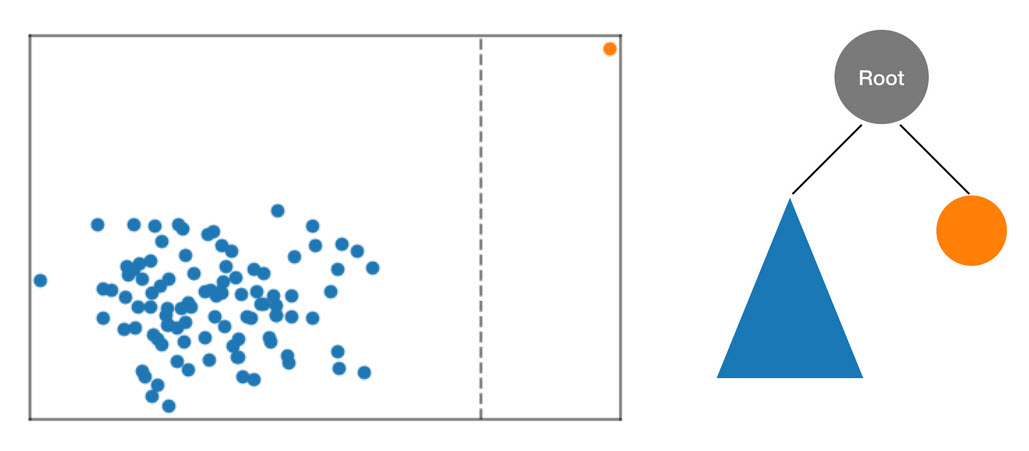
Gambar: Potongan acak yang mempartisi kumpulan data dua dimensi. Titik data anomali lebih mungkin terisolasi dalam kotak pembatas pada kedalaman pohon yang lebih kecil daripada titik lainnya.
Kotak pembatas kemudian dihitung untuk bagian kiri dan kanan data dan proses diulang sampai setiap daun pohon mewakili satu titik data dari sampel. Perhatikan bahwa jika titik tunggal cukup jauh maka kemungkinan besar pemotongan acak akan menghasilkan isolasi titik. Pengamatan ini memberikan intuisi bahwa kedalaman pohon, secara longgar, berbanding terbalik dengan skor anomali.
Saat melakukan inferensi menggunakan model RCF terlatih, skor anomali akhir dilaporkan sebagai rata-rata di seluruh skor yang dilaporkan oleh setiap pohon. Perhatikan bahwa sering terjadi bahwa titik data baru belum berada di pohon. Untuk menentukan skor yang terkait dengan titik baru, titik data dimasukkan ke dalam pohon yang diberikan dan pohon secara efisien (dan sementara) dipasang kembali dengan cara yang setara dengan proses pelatihan yang dijelaskan di atas. Artinya, pohon yang dihasilkan seolah-olah titik data input adalah anggota sampel yang digunakan untuk membangun pohon di tempat pertama. Skor yang dilaporkan berbanding terbalik dengan kedalaman titik input di dalam pohon.
Pilih Hyperparameters
Hyperparameter utama yang digunakan untuk menyetel model RCF adalah dan. num_trees num_samples_per_tree Peningkatan num_trees memiliki efek mengurangi kebisingan yang diamati dalam skor anomali karena skor akhir adalah rata-rata skor yang dilaporkan oleh masing-masing pohon. Meskipun nilai optimal bergantung pada aplikasi, kami merekomendasikan penggunaan 100 pohon untuk memulai sebagai keseimbangan antara noise skor dan kompleksitas model. Perhatikan bahwa waktu inferensi sebanding dengan jumlah pohon. Meskipun waktu pelatihan juga terpengaruh, itu didominasi oleh algoritma pengambilan sampel reservoir yang dijelaskan di atas.
Parameter num_samples_per_tree terkait dengan kepadatan anomali yang diharapkan dalam kumpulan data. Secara khusus, num_samples_per_tree harus dipilih sedemikian rupa sehingga 1/num_samples_per_tree mendekati rasio data anomali dengan data normal. Misalnya, jika 256 sampel digunakan di setiap pohon maka kami mengharapkan data kami mengandung anomali 1/256 atau sekitar 0,4% dari waktu. Sekali lagi, nilai optimal untuk hyperparameter ini tergantung pada aplikasi.
Referensi
-
Sudipto Guha, Nina Mishra, Gourav Roy, dan Okke Schrijvers. “Deteksi anomali berbasis hutan potong acak yang kuat di sungai.” Dalam Konferensi Internasional tentang Machine Learning, hlm. 2712-2721. 2016.
-
Taman Byung-Hoon, George Ostrouchov, Nagiza F. Samatova, dan Al Geist. “Pengambilan sampel acak berbasis reservoir dengan penggantian dari aliran data.” Dalam Prosiding Konferensi Internasional SIAM 2004 tentang Data Mining, hlm. 492-496. Masyarakat untuk Matematika Industri dan Terapan, 2004.
