Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Evaluasi model
Sekarang setelah Anda melatih dan menerapkan model menggunakan Amazon SageMaker AI, evaluasi model tersebut untuk memastikan bahwa model tersebut menghasilkan prediksi yang akurat pada data baru. Untuk evaluasi model, gunakan kumpulan data pengujian yang Anda buat. Siapkan kumpulan data
Evaluasi Model yang Diterapkan ke Layanan Hosting SageMaker AI
Untuk mengevaluasi model dan menggunakannya dalam produksi, panggil titik akhir dengan kumpulan data pengujian dan periksa apakah kesimpulan yang Anda dapatkan mengembalikan akurasi target yang ingin Anda capai.
Untuk mengevaluasi model
-
Siapkan fungsi berikut untuk memprediksi setiap baris set tes. Dalam contoh kode berikut,
rowsargumennya adalah untuk menentukan jumlah baris yang akan diprediksi pada suatu waktu. Anda dapat mengubah nilainya untuk melakukan inferensi batch yang sepenuhnya memanfaatkan sumber daya perangkat keras instans.import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
Jalankan kode berikut untuk membuat prediksi dataset pengujian dan plot histogram. Anda hanya perlu mengambil kolom fitur dari kumpulan data pengujian, tidak termasuk kolom ke-0 untuk nilai aktual.
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()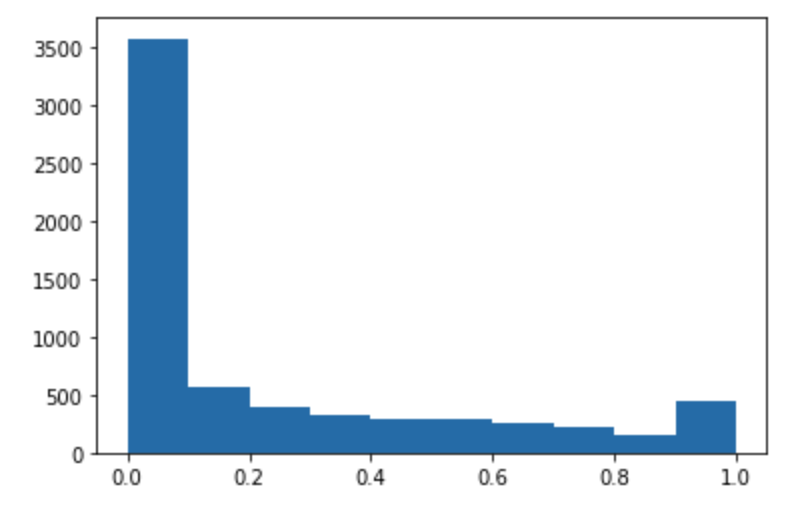
-
Nilai yang diprediksi adalah tipe float. Untuk menentukan
TrueatauFalseberdasarkan nilai float, Anda perlu menetapkan nilai cutoff. Seperti yang ditunjukkan dalam kode contoh berikut, gunakan Scikit-learn pustaka untuk mengembalikan metrik kebingungan keluaran dan laporan klasifikasi dengan cutoff 0,5.import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))Ini akan mengembalikan matriks kebingungan berikut:
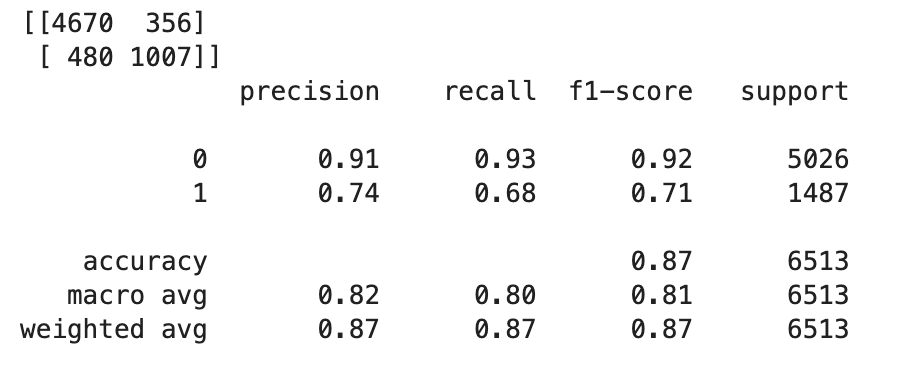
-
Untuk menemukan cutoff terbaik dengan set pengujian yang diberikan, hitung fungsi kehilangan log dari regresi logistik. Fungsi kehilangan log didefinisikan sebagai kemungkinan log negatif dari model logistik yang mengembalikan probabilitas prediksi untuk label kebenaran dasarnya. Contoh kode berikut secara numerik dan iteratif menghitung nilai kehilangan log (
-(y*log(p)+(1-y)log(1-p)), di mana label sebenarnya danypmerupakan perkiraan probabilitas dari sampel uji yang sesuai. Ini mengembalikan log loss versus grafik cutoff.import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()Ini harus mengembalikan kurva kehilangan log berikut.
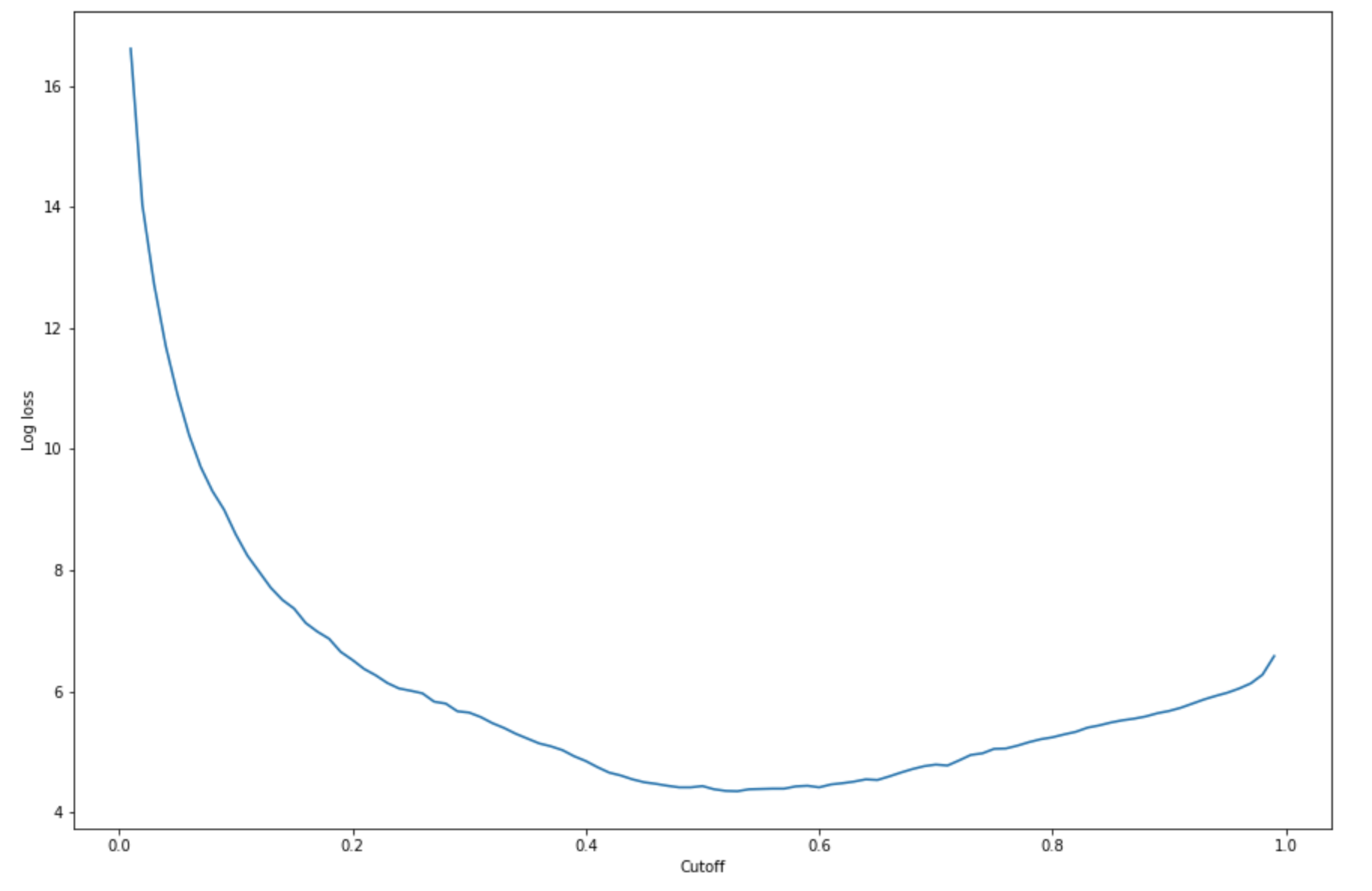
-
Temukan titik minimum kurva kesalahan menggunakan
minfungsi NumPyargmindan:print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )Ini harus kembali:
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897.Alih-alih menghitung dan meminimalkan fungsi kehilangan log, Anda dapat memperkirakan fungsi biaya sebagai alternatif. Misalnya, jika Anda ingin melatih model untuk melakukan klasifikasi biner untuk masalah bisnis seperti masalah prediksi churn pelanggan, Anda dapat mengatur bobot ke elemen matriks kebingungan dan menghitung fungsi biaya yang sesuai.
Anda sekarang telah melatih, menerapkan, dan mengevaluasi model pertama Anda di SageMaker AI.
Tip
Untuk memantau kualitas model, kualitas data, dan penyimpangan bias, gunakan Amazon SageMaker Model Monitor dan SageMaker AI Clarify. Untuk mempelajari lebih lanjut, lihat Monitor SageMaker Model Amazon, Monitor Kualitas Data, Kualitas Model Monitor, Monitor Bias Drift, dan Monitor Fitur Atribusi Drift.
Tip
Untuk mendapatkan tinjauan manusia tentang prediksi ML kepercayaan rendah atau sampel prediksi acak, gunakan alur kerja tinjauan manusia Amazon Augmented AI. Untuk informasi selengkapnya, lihat Menggunakan Amazon Augmented AI for Human Review.
