Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Gunakan Laporan Kualitas Data dan Wawasan untuk melakukan analisis data yang telah Anda impor ke Data Wrangler. Kami menyarankan Anda membuat laporan setelah Anda mengimpor dataset Anda. Anda dapat menggunakan laporan untuk membantu Anda membersihkan dan memproses data Anda. Ini memberi Anda informasi seperti jumlah nilai yang hilang dan jumlah outlier. Jika Anda memiliki masalah dengan data Anda, seperti kebocoran target atau ketidakseimbangan, laporan wawasan dapat membawa masalah tersebut ke perhatian Anda.
Gunakan prosedur berikut untuk membuat laporan Kualitas Data dan Wawasan. Ini mengasumsikan bahwa Anda telah mengimpor dataset ke dalam aliran Data Wrangler Anda.
Untuk membuat laporan Kualitas Data dan Wawasan
-
Pilih + di sebelah node dalam alur Data Wrangler Anda.
-
Pilih Dapatkan wawasan data.
-
Untuk nama Analisis, tentukan nama untuk laporan wawasan.
-
(Opsional) Untuk kolom Target, tentukan kolom target.
-
Untuk jenis Masalah, tentukan Regresi atau Klasifikasi.
-
Untuk ukuran Data, tentukan salah satu dari berikut ini:
-
50 K — Menggunakan 50000 baris pertama dari kumpulan data yang telah Anda impor untuk membuat laporan.
-
Seluruh kumpulan data — Menggunakan seluruh kumpulan data yang telah Anda impor untuk membuat laporan.
catatan
Membuat laporan Kualitas Data dan Wawasan di seluruh kumpulan data menggunakan pekerjaan SageMaker pemrosesan Amazon. Pekerjaan SageMaker Pemrosesan menyediakan sumber daya komputasi tambahan yang diperlukan untuk mendapatkan wawasan untuk semua data Anda. Untuk informasi selengkapnya tentang SageMaker Memproses pekerjaan, lihatBeban kerja transformasi data dengan SageMaker Processing.
-
-
Pilih Buat.
Topik berikut menunjukkan bagian dari laporan:
Anda dapat mengunduh laporan atau melihatnya secara online. Untuk mengunduh laporan, pilih tombol unduh di sudut kanan atas layar. Gambar berikut menunjukkan tombol.

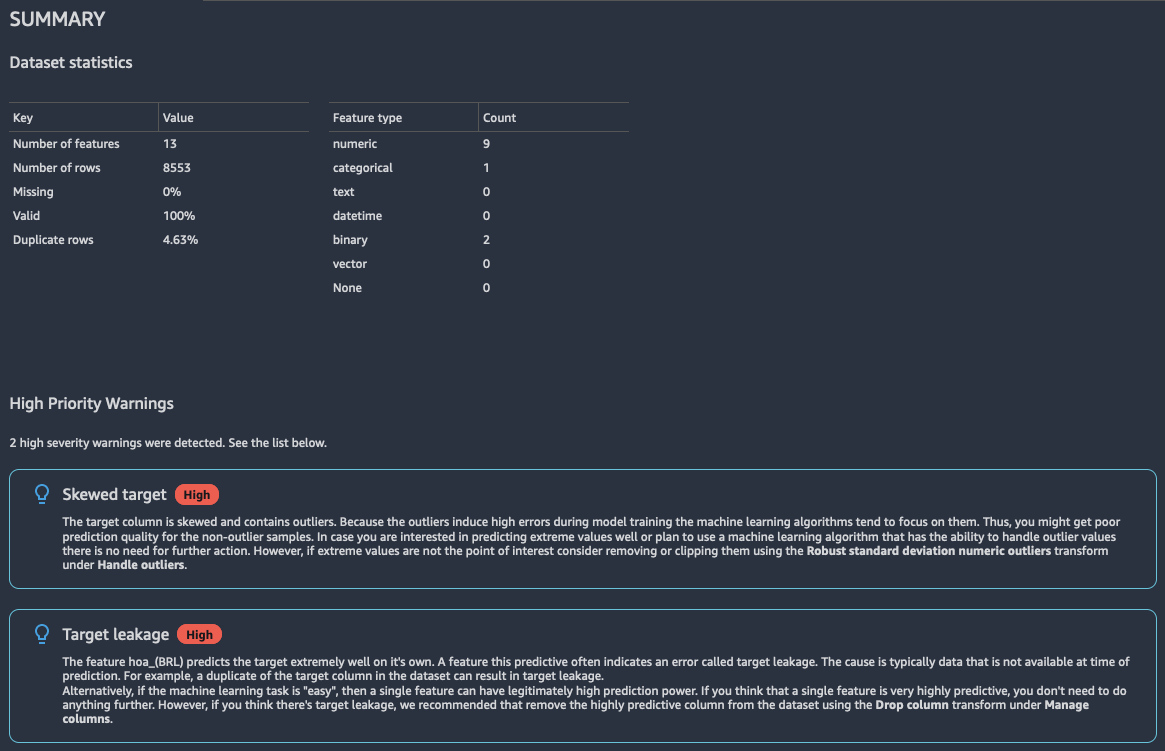
Ringkasan
Laporan wawasan memiliki ringkasan singkat dari data yang mencakup informasi umum seperti nilai yang hilang, nilai tidak valid, jenis fitur, jumlah outlier, dan banyak lagi. Ini juga dapat mencakup peringatan tingkat keparahan tinggi yang menunjukkan kemungkinan masalah dengan data. Kami menyarankan Anda menyelidiki peringatan tersebut.
Berikut ini adalah contoh ringkasan laporan.
Kolom target
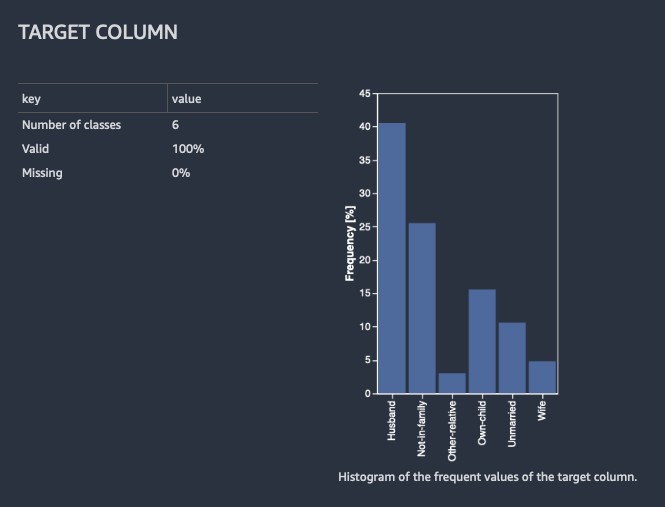
Saat Anda membuat laporan kualitas data dan wawasan, Data Wrangler memberi Anda opsi untuk memilih kolom target. Kolom target adalah kolom yang Anda coba prediksi. Saat Anda memilih kolom target, Data Wrangler secara otomatis membuat analisis kolom target. Ini juga memberi peringkat fitur dalam urutan kekuatan prediksi mereka. Saat memilih kolom target, Anda harus menentukan apakah Anda mencoba memecahkan masalah regresi atau klasifikasi.
Untuk klasifikasi, Data Wrangler menunjukkan tabel dan histogram dari kelas yang paling umum. Kelas adalah kategori. Ini juga menyajikan pengamatan, atau baris, dengan nilai target yang hilang atau tidak valid.
Gambar berikut menunjukkan contoh analisis kolom target untuk masalah klasifikasi.
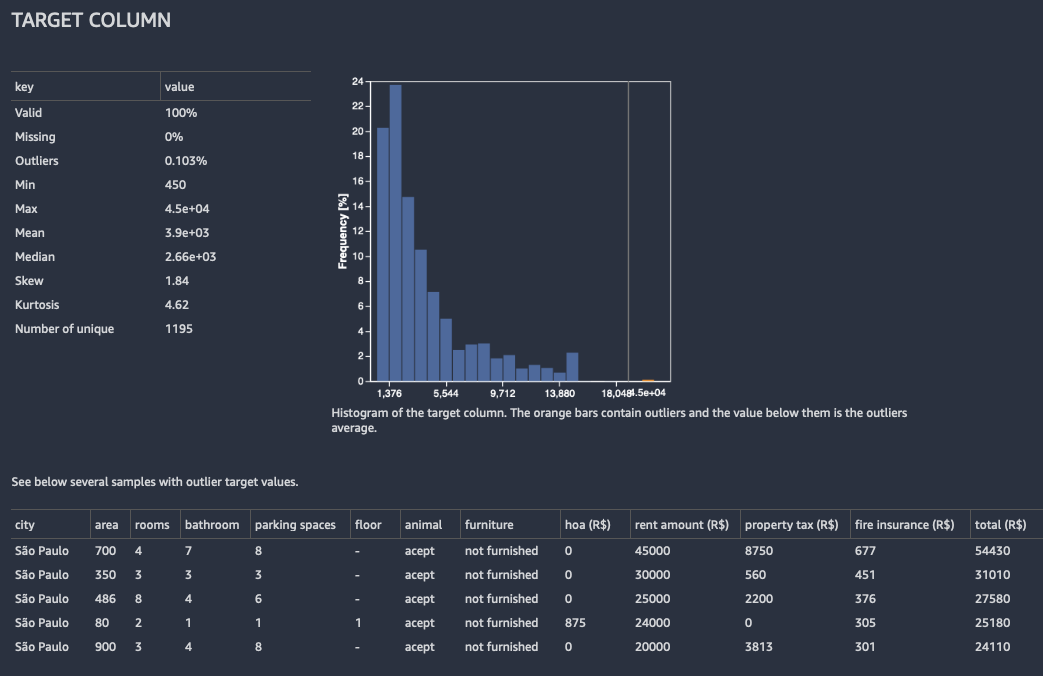
Untuk regresi, Data Wrangler menunjukkan histogram semua nilai di kolom target. Ini juga menyajikan pengamatan, atau baris, dengan nilai target yang hilang, tidak valid, atau outlier.
Gambar berikut menunjukkan contoh analisis kolom target untuk masalah regresi.
Model cepat
Model Cepat memberikan perkiraan kualitas prediksi yang diharapkan dari model yang Anda latih pada data Anda.
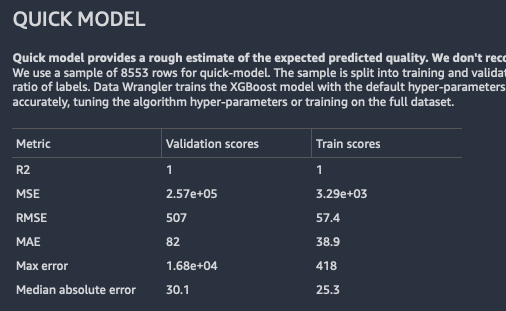
Data Wrangler membagi data Anda menjadi lipatan pelatihan dan validasi. Ini menggunakan 80% sampel untuk pelatihan dan 20% dari nilai untuk validasi. Untuk klasifikasi, sampel dibagi bertingkat. Untuk pemisahan bertingkat, setiap partisi data memiliki rasio label yang sama. Untuk masalah klasifikasi, penting untuk memiliki rasio label yang sama antara lipatan pelatihan dan klasifikasi. Data Wrangler melatih XGBoost model dengan hyperparameters default. Ini berlaku penghentian awal pada data validasi dan melakukan preprocessing fitur minimal.
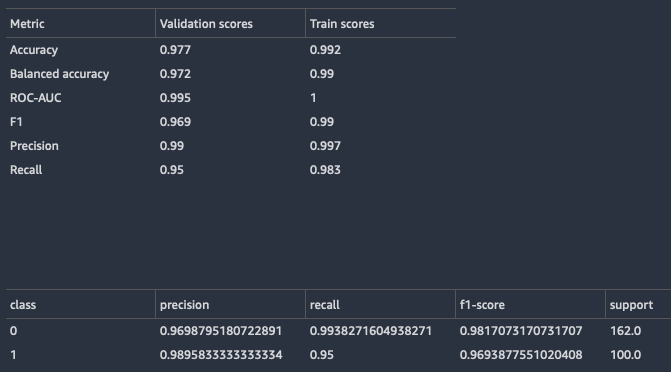
Untuk model klasifikasi, Data Wrangler mengembalikan ringkasan model dan matriks kebingungan.
Berikut ini adalah contoh ringkasan model klasifikasi. Untuk mempelajari lebih lanjut tentang informasi yang dikembalikan, lihatDefinisi.
Berikut ini adalah contoh matriks kebingungan yang dikembalikan oleh model cepat.
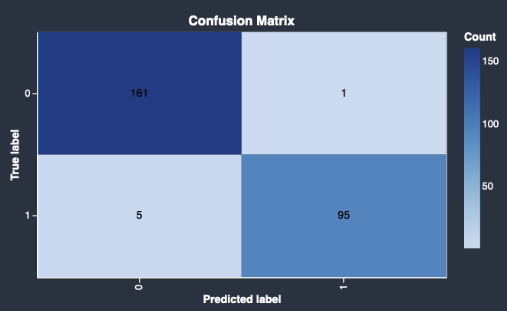
Matriks kebingungan memberi Anda informasi berikut:
-
Berapa kali label yang diprediksi cocok dengan label sebenarnya.
-
Berapa kali label yang diprediksi tidak cocok dengan label sebenarnya.
Label sebenarnya mewakili pengamatan aktual dalam data Anda. Misalnya, jika Anda menggunakan model untuk mendeteksi transaksi penipuan, label sebenarnya mewakili transaksi yang sebenarnya curang atau tidak curang. Label yang diprediksi mewakili label yang ditetapkan model Anda ke data.
Anda dapat menggunakan matriks kebingungan untuk melihat seberapa baik model memprediksi ada atau tidak adanya suatu kondisi. Jika Anda memprediksi transaksi penipuan, Anda dapat menggunakan matriks kebingungan untuk memahami sensitivitas dan kekhususan model. Sensitivitas mengacu pada kemampuan model untuk mendeteksi transaksi penipuan. Kekhususan mengacu pada kemampuan model untuk menghindari mendeteksi transaksi non-penipuan sebagai penipuan.
Berikut ini adalah contoh output model cepat untuk masalah regresi.
Ringkasan fitur
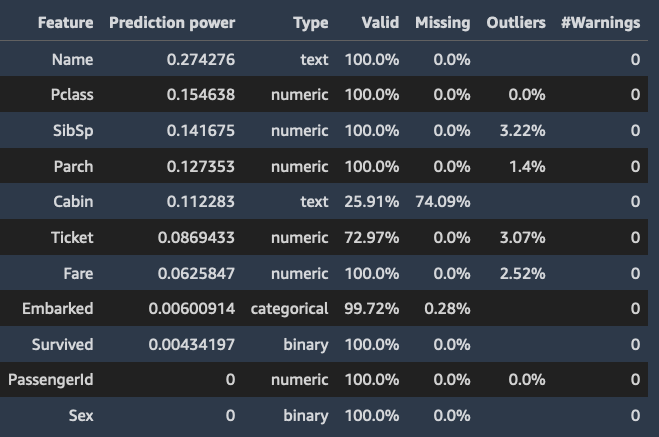
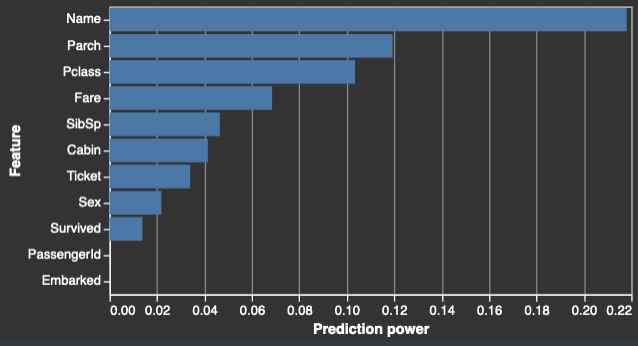
Saat Anda menentukan kolom target, Data Wrangler memesan fitur berdasarkan kekuatan prediksinya. Kekuatan prediksi diukur pada data setelah dibagi menjadi 80% pelatihan dan 20% lipatan validasi. Data Wrangler cocok dengan model untuk setiap fitur secara terpisah pada lipatan pelatihan. Ini menerapkan preprocessing fitur minimal dan mengukur kinerja prediksi pada data validasi.
Ini menormalkan skor ke kisaran [0,1]. Skor prediksi yang lebih tinggi menunjukkan kolom yang lebih berguna untuk memprediksi target sendiri. Skor yang lebih rendah menunjuk ke kolom yang tidak memprediksi kolom target.
Ini jarang untuk kolom yang tidak prediktif sendiri untuk menjadi prediktif ketika digunakan bersama-sama dengan kolom lain. Anda dapat dengan yakin menggunakan skor prediksi untuk menentukan apakah fitur dalam kumpulan data Anda bersifat prediktif.
Skor rendah biasanya menunjukkan fitur tersebut berlebihan. Skor 1 menyiratkan kemampuan prediksi sempurna, yang sering menunjukkan kebocoran target. Kebocoran target biasanya terjadi ketika kumpulan data berisi kolom yang tidak tersedia pada waktu prediksi. Misalnya, itu bisa menjadi duplikat dari kolom target.
Berikut ini adalah contoh tabel dan histogram yang menunjukkan nilai prediksi dari setiap fitur.
Sampel
Data Wrangler memberikan informasi tentang apakah sampel Anda anomali atau jika ada duplikat dalam kumpulan data Anda.
Data Wrangler mendeteksi sampel anomali menggunakan algoritma hutan isolasi. Hutan isolasi mengaitkan skor anomali dengan setiap sampel (baris) dari kumpulan data. Skor anomali yang rendah menunjukkan sampel anomali. Skor tinggi dikaitkan dengan sampel non-anomali. Sampel dengan skor anomali negatif biasanya dianggap anomali dan sampel dengan skor anomali positif dianggap non-anomali.
Ketika Anda melihat sampel yang mungkin anomali, kami sarankan Anda memperhatikan nilai-nilai yang tidak biasa. Misalnya, Anda mungkin memiliki nilai anomali yang dihasilkan dari kesalahan dalam mengumpulkan dan memproses data. Sebaiknya gunakan pengetahuan domain dan logika bisnis saat Anda memeriksa sampel anomali.
Data Wrangler mendeteksi baris duplikat dan menghitung rasio baris duplikat dalam data Anda. Beberapa sumber data dapat menyertakan duplikat yang valid. Sumber data lain dapat memiliki duplikat yang menunjukkan masalah dalam pengumpulan data. Sampel duplikat yang dihasilkan dari pengumpulan data yang salah dapat mengganggu proses pembelajaran mesin yang mengandalkan pemisahan data menjadi pelatihan independen dan lipatan validasi.
Berikut ini adalah elemen laporan wawasan yang dapat dipengaruhi oleh sampel duplikat:
-
Model cepat
-
Estimasi daya prediksi
-
Penyetelan hyperparameter otomatis
Anda dapat menghapus sampel duplikat dari kumpulan data menggunakan transformasi Drop duplikat di bawah Kelola baris. Data Wrangler menunjukkan baris yang paling sering diduplikasi.
Definisi
Berikut ini adalah definisi untuk istilah teknis yang digunakan dalam laporan wawasan data.
Berikut ini adalah definisi untuk masing-masing jenis fitur:
-
Numerik — Nilai numerik dapat berupa float atau bilangan bulat, seperti usia atau pendapatan. Model pembelajaran mesin mengasumsikan bahwa nilai numerik diurutkan dan jarak ditentukan di atasnya. Misalnya, 3 lebih dekat ke 4 daripada 10 dan 3 < 4 < 10.
-
Categorical - Entri kolom milik satu set nilai unik, yang biasanya jauh lebih kecil dari jumlah entri di kolom. Misalnya, kolom dengan panjang 100 dapat berisi nilai unik
Dog,Cat, danMouse. Nilainya bisa berupa numerik, teks, atau kombinasi keduanya.Horse,House,8,Love, dan semuanya3.1akan menjadi nilai yang valid dan dapat ditemukan di kolom kategoris yang sama. Model pembelajaran mesin tidak mengasumsikan urutan atau jarak pada nilai-nilai fitur kategoris, sebagai lawan dari fitur numerik, bahkan ketika semua nilai adalah angka. -
Biner — Fitur biner adalah jenis fitur kategoris khusus di mana kardinalitas himpunan nilai unik adalah 2.
-
Teks - Kolom teks berisi banyak nilai unik non-numerik. Dalam kasus ekstrim, semua elemen kolom itu unik. Dalam kasus ekstrim, tidak ada dua entri yang sama.
-
Datetime - Kolom datetime berisi informasi tentang tanggal atau waktu. Ini dapat memiliki informasi tentang tanggal dan waktu.
