Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kategorikan teks dengan klasifikasi teks (Single Label)
Untuk mengkategorikan artikel dan teks ke dalam kategori yang telah ditentukan, gunakan klasifikasi teks. Misalnya, Anda dapat menggunakan klasifikasi teks untuk mengidentifikasi sentimen yang disampaikan dalam ulasan atau emosi yang mendasari bagian teks. Gunakan klasifikasi teks Amazon SageMaker Ground Truth untuk meminta pekerja mengurutkan teks ke dalam kategori yang Anda tentukan. Anda membuat pekerjaan pelabelan klasifikasi teks menggunakan bagian Ground Truth di konsol Amazon SageMaker AI atau CreateLabelingJoboperasinya.
penting
Jika Anda membuat file manifes masukan secara manual, gunakan "source" untuk mengidentifikasi teks yang ingin diberi label. Untuk informasi selengkapnya, lihat Data input.
Membuat Job Pelabelan Klasifikasi Teks (Konsol)
Anda dapat mengikuti petunjuk Membuat Job Pelabelan (Konsol) untuk mempelajari cara membuat pekerjaan pelabelan klasifikasi teks di konsol SageMaker AI. Pada Langkah 10, pilih Teks dari menu tarik-turun kategori tugas, dan pilih Klasifikasi Teks (Label Tunggal) sebagai jenis tugas.
Ground Truth menyediakan UI pekerja yang mirip dengan yang berikut ini untuk tugas pelabelan. Saat membuat pekerjaan pelabelan dengan konsol, Anda menentukan petunjuk untuk membantu pekerja menyelesaikan pekerjaan dan label yang dapat dipilih pekerja.
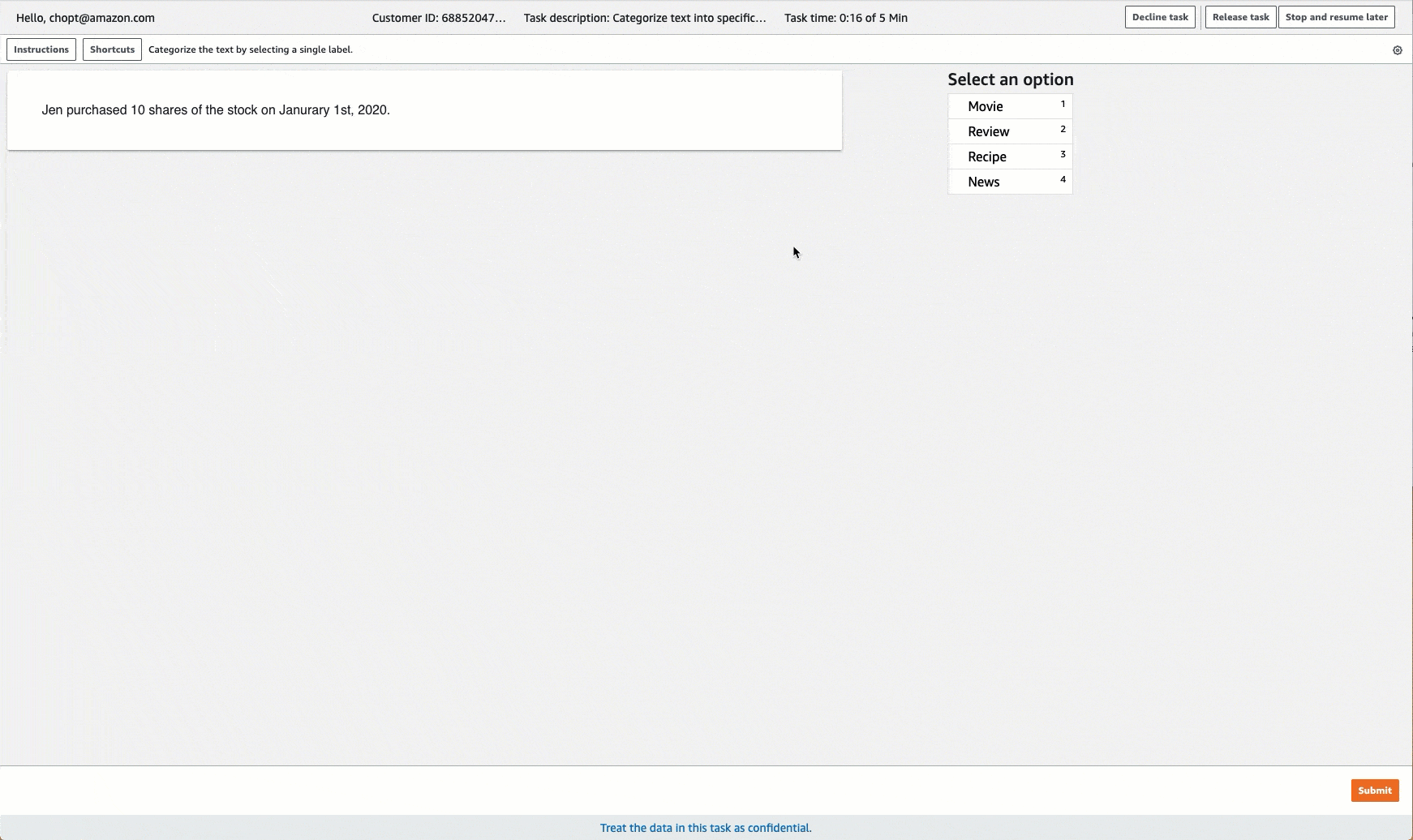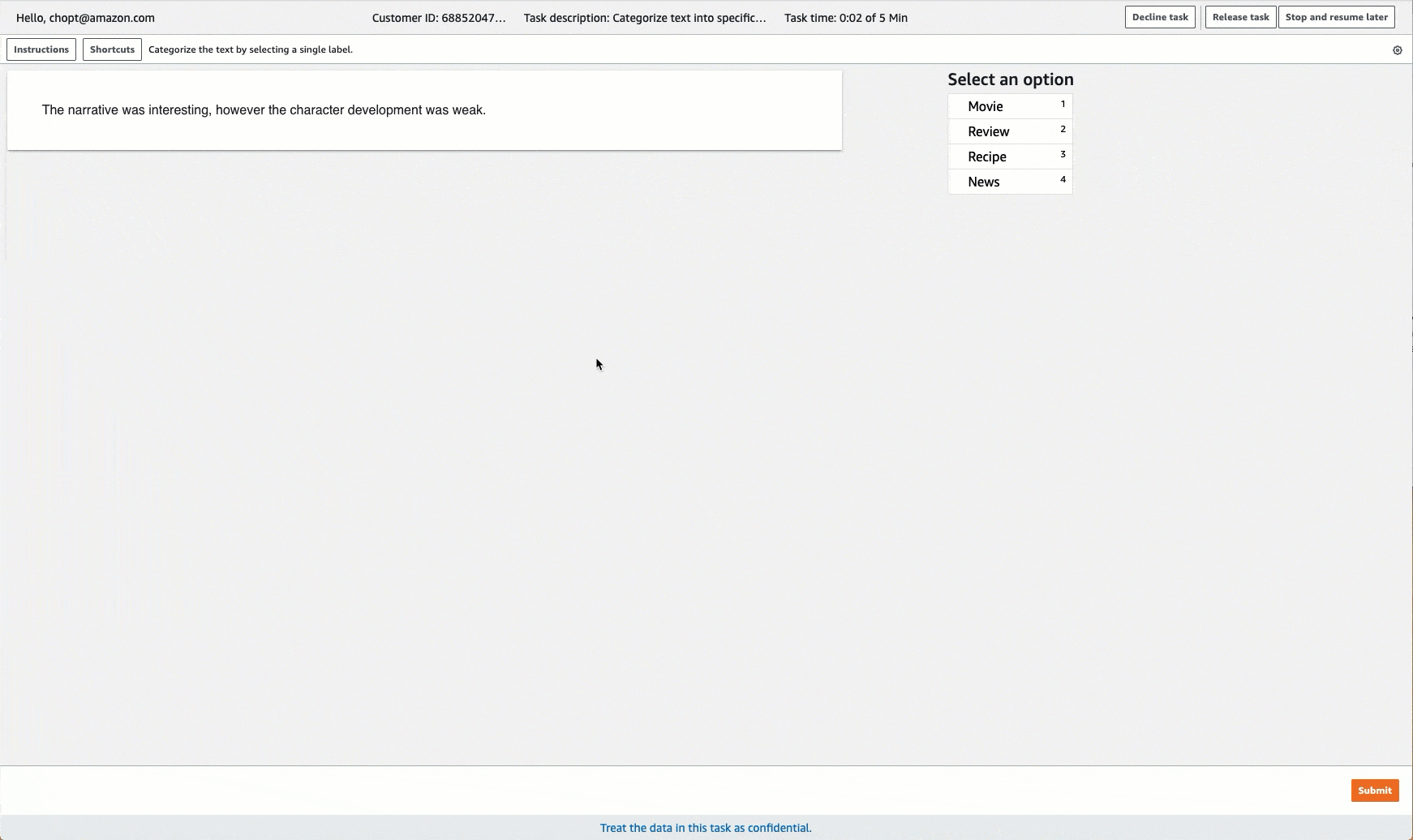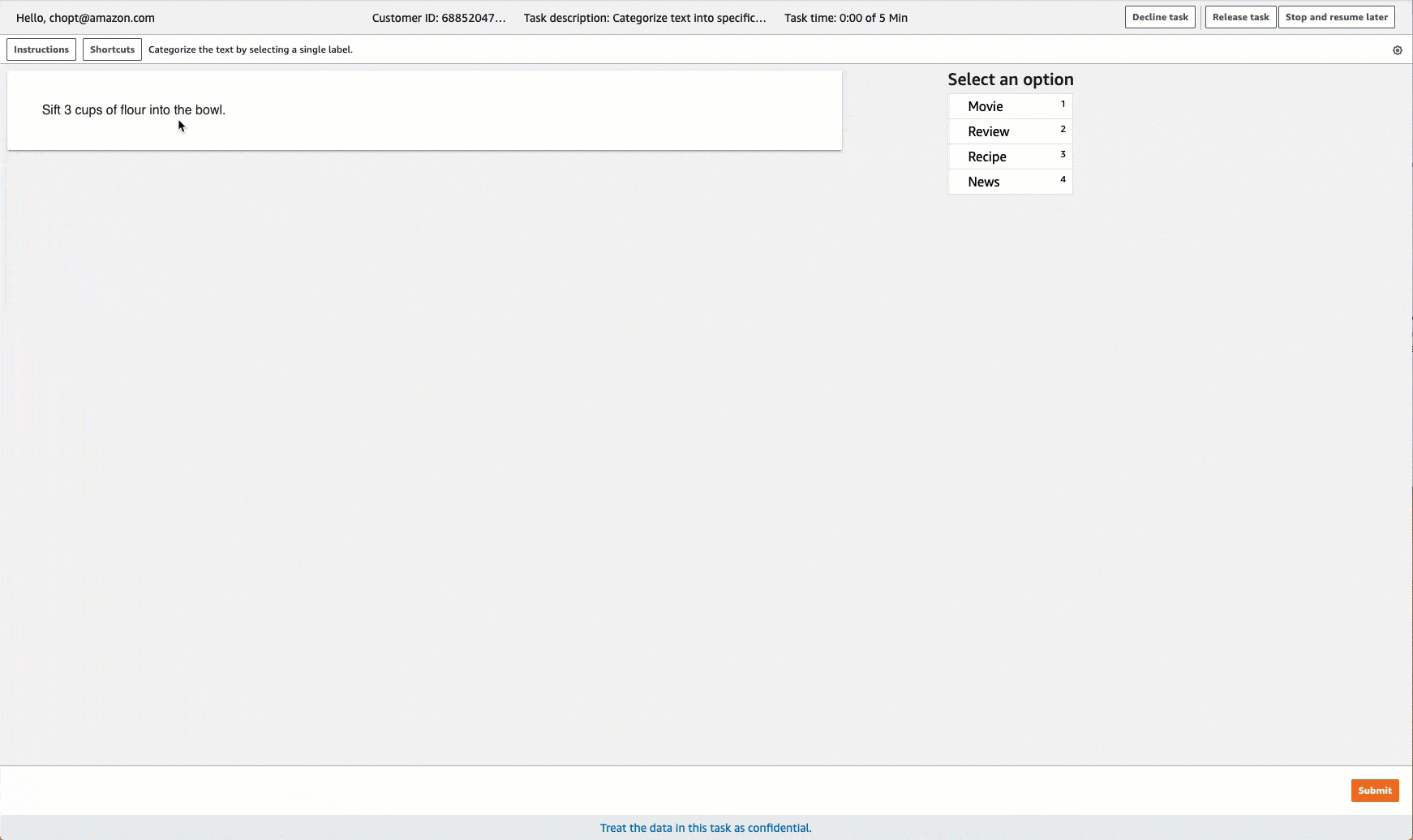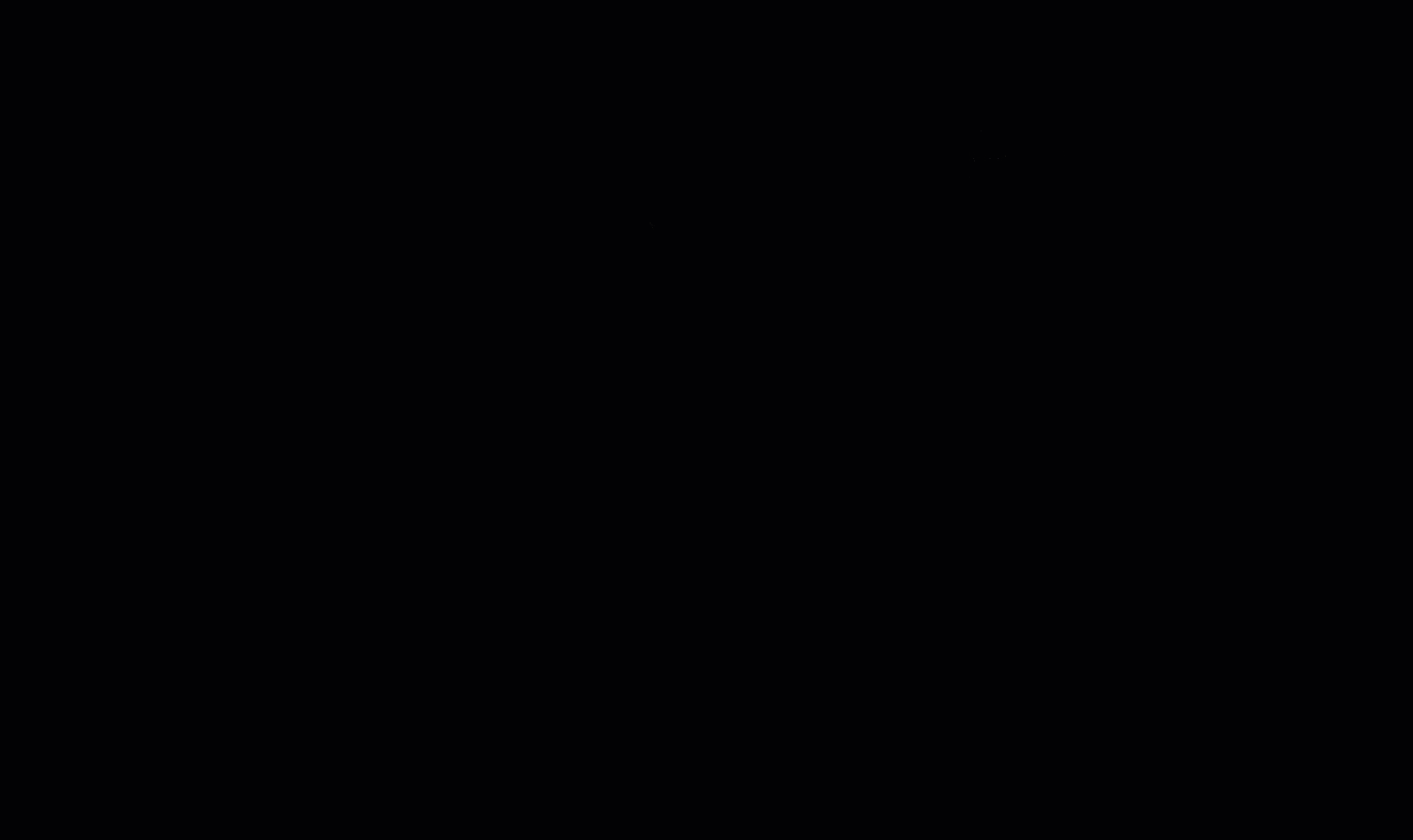
Membuat Job Pelabelan Klasifikasi Teks (API)
Untuk membuat tugas pelabelan klasifikasi teks, gunakan operasi SageMaker CreateLabelingJob API. API ini mendefinisikan operasi ini untuk semua AWS SDK. Untuk melihat daftar SDK khusus bahasa yang didukung untuk operasi ini, tinjau bagian Lihat Juga. CreateLabelingJob
Ikuti petunjuk Membuat Job Pelabelan (API) dan lakukan hal berikut saat Anda mengonfigurasi permintaan Anda:
-
Pre-annotation Fungsi Lambda untuk jenis tugas ini diakhiri dengan.
PRE-TextMultiClassUntuk menemukan Lambda ARN pra-anotasi untuk Wilayah Anda, lihat. PreHumanTaskLambdaArn -
Annotation-consolidation Fungsi Lambda untuk jenis tugas ini diakhiri dengan.
ACS-TextMultiClassUntuk menemukan Lambda ARN konsolidasi anotasi untuk Wilayah Anda, lihat. AnnotationConsolidationLambdaArn
Berikut ini adalah contoh permintaan AWS Python SDK (Boto3)
response = client.create_labeling_job( LabelingJobName='example-text-classification-labeling-job, LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://bucket/path/manifest-with-input-data.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://bucket/path/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/path/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:region:*:workteam/private-crowd/*', 'UiConfig': { 'UiTemplateS3Uri':'s3://bucket/path/worker-task-template.html'}, 'PreHumanTaskLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:PRE-TextMultiClass, 'TaskKeywords': [Text classification', ], 'TaskTitle':Text classification task', 'TaskDescription':'Carefully read and classify this text using the categories provided.', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-TextMultiClass' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
Berikan Template untuk Pekerjaan Pelabelan Klasifikasi Teks
Jika Anda membuat pekerjaan pelabelan menggunakan API, Anda harus menyediakan template tugas pekerja diUiTemplateS3Uri. Salin dan modifikasi template berikut. Hanya memodifikasi short-instructions, full-instructions, danheader.
Unggah template ini ke S3, dan berikan URI S3 untuk file ini. UiTemplateS3Uri
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="crowd-classifier" categories="{{ task.input.labels | to_json | escape }}" header="classify text" > <classification-target style="white-space: pre-wrap"> {{ task.input.taskObject }} </classification-target> <full-instructions header="Classifier instructions"> <ol><li><strong>Read</strong> the text carefully.</li> <li><strong>Read</strong> the examples to understand more about the options.</li> <li><strong>Choose</strong> the appropriate labels that best suit the text.</li></ol> </full-instructions> <short-instructions> <p>Enter description of the labels that workers have to choose from</p> <p><br></p><p><br></p><p>Add examples to help workers understand the label</p> <p><br></p><p><br></p><p><br></p><p><br></p><p><br></p> </short-instructions> </crowd-classifier> </crowd-form>
Data Output Klasifikasi Teks
Setelah Anda membuat tugas pelabelan klasifikasi teks, data keluaran Anda akan ditempatkan di bucket Amazon S3 yang ditentukan dalam S3OutputPath parameter saat menggunakan API atau di bidang lokasi kumpulan data Output di bagian Ikhtisar pekerjaan konsol.
Untuk mempelajari lebih lanjut tentang file manifes keluaran yang dihasilkan oleh Ground Truth dan struktur file yang digunakan Ground Truth untuk menyimpan data keluaran Anda, lihatPelabelan data keluaran pekerjaan.
Untuk melihat contoh file manifes keluaran dari pekerjaan pelabelan klasifikasi teks, lihatKlasifikasi output pekerjaan.
