Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memulai dengan Data Wrangler
Amazon SageMaker Data Wrangler adalah fitur di Amazon SageMaker Studio Classic. Gunakan bagian ini untuk mempelajari cara mengakses dan mulai menggunakan Data Wrangler. Lakukan hal-hal berikut:
-
Selesaikan setiap langkahPrasyarat.
-
Ikuti prosedur Akses Data Wrangler untuk mulai menggunakan Data Wrangler.
Prasyarat
Untuk menggunakan Data Wrangler, Anda harus menyelesaikan prasyarat berikut.
-
Untuk menggunakan Data Wrangler, Anda memerlukan akses ke instans Amazon Elastic Compute Cloud (Amazon EC2). Untuk informasi selengkapnya tentang instans Amazon EC2 yang dapat Anda gunakan, lihat. Contoh Untuk mempelajari cara melihat kuota Anda dan, jika perlu, minta peningkatan kuota, lihat kuota AWS layanan.
-
Konfigurasikan izin yang diperlukan yang dijelaskan dalamKeamanan dan Izin.
-
Jika organisasi Anda menggunakan firewall yang memblokir lalu lintas internet, Anda harus memiliki akses ke URL berikut:
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
Untuk menggunakan Data Wrangler, Anda memerlukan instance Studio Classic yang aktif. Untuk mempelajari cara meluncurkan instance baru, lihatIkhtisar domain Amazon SageMaker AI. Saat instans Studio Classic Anda Siap, gunakan instruksi diAkses Data Wrangler.
Akses Data Wrangler
Prosedur berikut mengasumsikan Anda telah menyelesaikan. Prasyarat
Untuk mengakses Data Wrangler di Studio Classic, lakukan hal berikut.
-
Masuk ke Studio Classic. Untuk informasi selengkapnya, lihat Ikhtisar domain Amazon SageMaker AI.
-
Pilih Studio.
-
Pilih Luncurkan aplikasi.
-
Dari daftar dropdown, pilih Studio.
-
Pilih ikon Beranda.
-
Pilih Data.
-
Pilih Data Wrangler.
-
Anda juga dapat membuat aliran Data Wrangler dengan melakukan hal berikut.
-
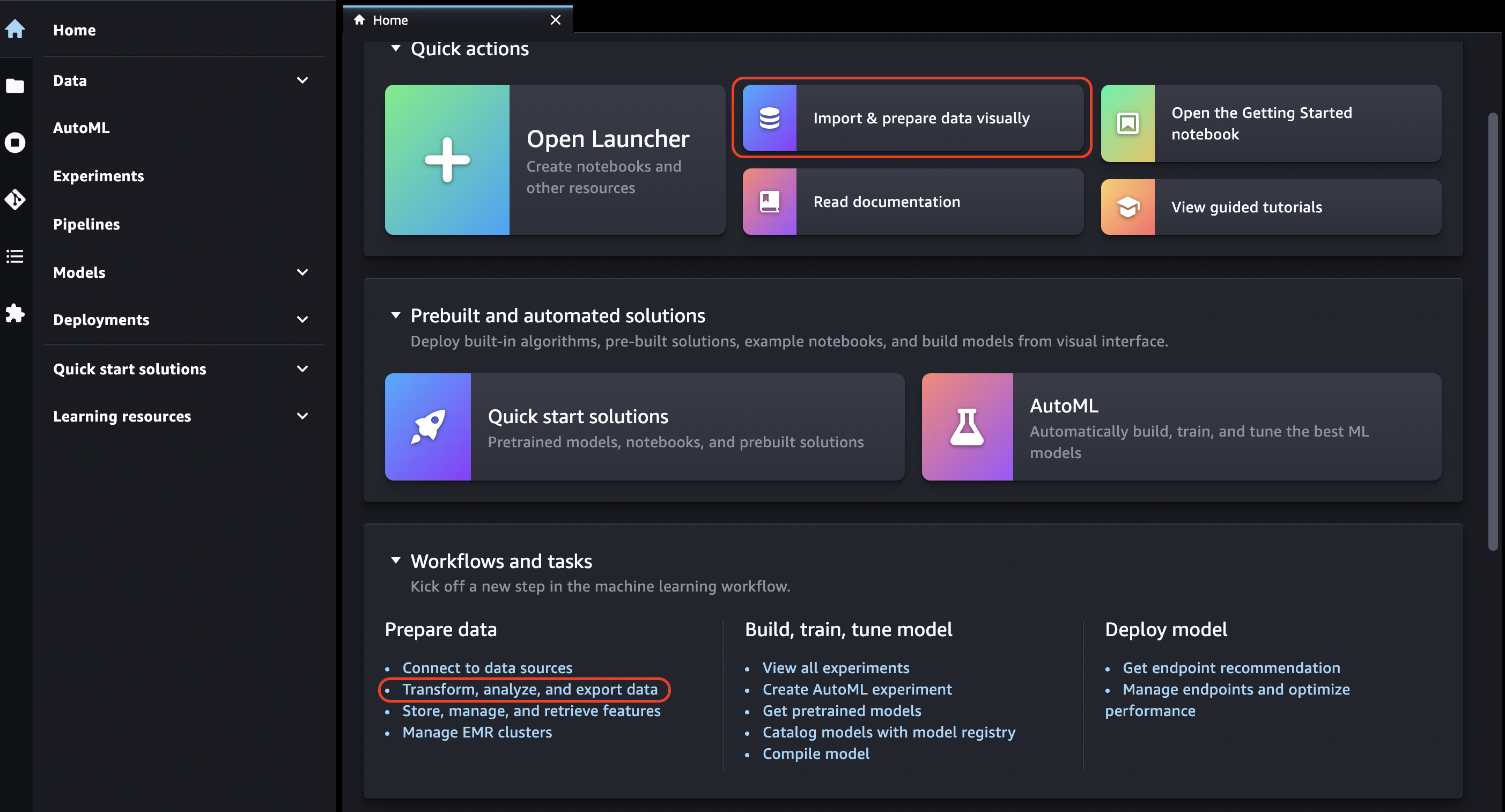
Di bilah navigasi atas, pilih File.
-
Pilih Baru.
-
Pilih Data Wrangler Flow.
-
-
(Opsional) Ganti nama direktori baru dan file.flow.
-
Saat Anda membuat file.flow baru di Studio Classic, Anda mungkin melihat carousel yang memperkenalkan Anda ke Data Wrangler.
Ini mungkin memakan waktu beberapa menit.
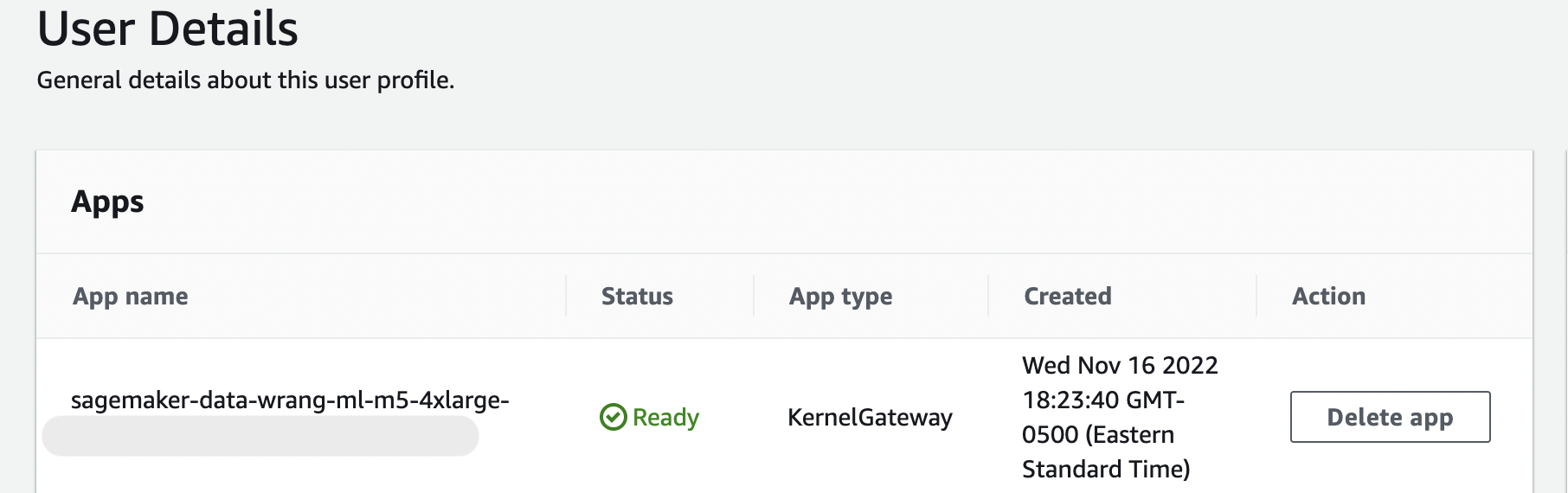
Pesan ini tetap ada selama KernelGatewayaplikasi di halaman Detail Pengguna Anda Tertunda. Untuk melihat status aplikasi ini, di konsol SageMaker AI di halaman Amazon SageMaker Studio Classic, pilih nama pengguna yang Anda gunakan untuk mengakses Studio Classic. Pada halaman Detail Pengguna, Anda melihat KernelGatewayaplikasi di bawah Aplikasi. Tunggu hingga status aplikasi ini Siap untuk mulai menggunakan Data Wrangler. Ini bisa memakan waktu sekitar 5 menit saat pertama kali Anda meluncurkan Data Wrangler.
-
Untuk memulai, pilih sumber data dan gunakan untuk mengimpor dataset. Lihat Impor untuk mempelajari selengkapnya.
Saat Anda mengimpor kumpulan data, itu muncul di aliran data Anda. Untuk mempelajari selengkapnya, lihat Membuat dan Menggunakan Data Wrangler Flow.
-
Setelah Anda mengimpor dataset, Data Wrangler secara otomatis menyimpulkan jenis data di setiap kolom. Pilih + di samping langkah Jenis data dan pilih Edit tipe data.
penting
Setelah menambahkan transformasi ke langkah Tipe data, Anda tidak dapat memperbarui jenis kolom secara massal menggunakan jenis Perbarui.
-
Gunakan aliran data untuk menambahkan transformasi dan analisis. Untuk mempelajari lebih lanjut lihat Transformasi Data danAnalisis dan Visualisasikan.
-
Untuk mengekspor aliran data lengkap, pilih Ekspor dan pilih opsi ekspor. Untuk mempelajari selengkapnya, lihat Ekspor.
-
Terakhir, pilih ikon Components and registries, dan pilih Data Wrangler dari daftar dropdown untuk melihat semua file.flow yang telah Anda buat. Anda dapat menggunakan menu ini untuk menemukan dan berpindah antar aliran data.
Setelah Anda meluncurkan Data Wrangler, Anda dapat menggunakan bagian berikut untuk menelusuri bagaimana Anda dapat menggunakan Data Wrangler untuk membuat aliran persiapan data ML.
Perbarui Data Wrangler
Kami menyarankan Anda memperbarui aplikasi Data Wrangler Studio Classic secara berkala untuk mengakses fitur dan pembaruan terbaru. Nama aplikasi Data Wrangler dimulai dengan sagemaker-data-wrang. Untuk mempelajari cara memperbarui aplikasi Studio Classic, lihatMatikan dan Perbarui Aplikasi Amazon SageMaker Studio Classic.
Demo: Panduan Set Data Wrangler Titanic
Bagian berikut memberikan panduan untuk membantu Anda mulai menggunakan Data Wrangler. Panduan ini mengasumsikan bahwa Anda telah mengikuti langkah-langkah Akses Data Wrangler dan membuka file aliran data baru yang ingin Anda gunakan untuk demo. Anda mungkin ingin mengganti nama file.flow ini menjadi sesuatu yang mirip dengan. titanic-demo.flow
Panduan ini menggunakan dataset Titanic
Dalam tutorial ini, Anda melakukan langkah-langkah berikut.
-
Lakukan salah satu tindakan berikut:
-
Buka alur Data Wrangler Anda dan pilih Use Sample Dataset.
-
Unggah kumpulan data Titanic
ke Amazon Simple Storage Service (Amazon S3) Simple Storage Service (Amazon S3), lalu impor kumpulan data ini ke Data Wrangler.
-
-
Analisis dataset ini menggunakan analisis Data Wrangler.
-
Tentukan aliran data menggunakan transformasi data Wrangler Data.
-
Ekspor alur Anda ke Notebook Jupyter yang dapat Anda gunakan untuk membuat pekerjaan Data Wrangler.
-
Memproses data Anda, dan memulai pekerjaan SageMaker pelatihan untuk melatih XGBoost Binary Classifier.
Unggah Dataset ke S3 dan Impor
Untuk memulai, Anda dapat menggunakan salah satu metode berikut untuk mengimpor dataset Titanic ke Data Wrangler:
-
Mengimpor dataset langsung dari aliran Data Wrangler
-
Mengunggah kumpulan data ke Amazon S3 dan kemudian mengimpornya ke Data Wrangler
Untuk mengimpor dataset langsung ke Data Wrangler, buka alur dan pilih Use Sample Dataset.
Mengunggah kumpulan data ke Amazon S3 dan mengimpornya ke Data Wrangler lebih dekat dengan pengalaman Anda mengimpor data Anda sendiri. Informasi berikut memberi tahu Anda cara mengunggah kumpulan data Anda dan mengimpornya.
Sebelum Anda mulai mengimpor data ke Data Wrangler, unduh dataset Titanic
Jika Anda adalah pengguna baru Amazon S3, Anda dapat melakukan ini menggunakan drag and drop di konsol Amazon S3. Untuk mempelajari caranya, lihat Mengunggah File dan Folder dengan Menggunakan Seret dan Jatuhkan di Panduan Pengguna Layanan Penyimpanan Sederhana Amazon.
penting
Unggah kumpulan data Anda ke bucket S3 di AWS Wilayah yang sama yang ingin Anda gunakan untuk menyelesaikan demo ini.
Ketika dataset Anda telah berhasil diunggah ke Amazon S3, Anda dapat mengimpornya ke Data Wrangler.
Impor dataset Titanic ke Data Wrangler
-
Pilih tombol Impor data di tab Aliran data Anda atau pilih tab Impor.
-
Pilih Amazon S3.
-
Gunakan tabel Impor kumpulan data dari S3 untuk menemukan bucket tempat Anda menambahkan kumpulan data Titanic. Pilih file CSV kumpulan data Titanic untuk membuka panel Detail.
-
Di bawah Detail, jenis File harus CSV. Periksa Baris pertama adalah header untuk menentukan bahwa baris pertama dari dataset adalah header. Anda juga dapat memberi nama kumpulan data dengan sesuatu yang lebih ramah, seperti
Titanic-train. -
Pilih tombol Impor.
Ketika dataset Anda diimpor ke Data Wrangler, itu muncul di tab Aliran Data Anda. Anda dapat mengklik dua kali pada node untuk memasukkan tampilan detail node, yang memungkinkan Anda menambahkan transformasi atau analisis. Anda dapat menggunakan ikon plus untuk akses cepat ke navigasi. Di bagian selanjutnya, Anda menggunakan aliran data ini untuk menambahkan analisis dan mengubah langkah-langkah.
Aliran Data
Di bagian aliran data, satu-satunya langkah dalam aliran data adalah dataset Anda yang baru saja diimpor dan langkah tipe Data. Setelah menerapkan transformasi, Anda dapat kembali ke tab ini dan melihat seperti apa aliran datanya. Sekarang, tambahkan beberapa transformasi dasar di bawah tab Siapkan dan Analisis.
Mempersiapkan dan memvisualisasikan
Data Wrangler memiliki transformasi dan visualisasi bawaan yang dapat Anda gunakan untuk menganalisis, membersihkan, dan mengubah data Anda.
Tab Data dari tampilan detail simpul mencantumkan semua transformasi bawaan di panel kanan, yang juga berisi area di mana Anda dapat menambahkan transformasi khusus. Kasus penggunaan berikut menampilkan cara menggunakan transformasi ini.
Untuk mendapatkan informasi yang dapat membantu Anda dalam eksplorasi data dan rekayasa fitur, buat laporan kualitas data dan wawasan. Informasi dari laporan dapat membantu Anda membersihkan dan memproses data Anda. Ini memberi Anda informasi seperti jumlah nilai yang hilang dan jumlah outlier. Jika Anda memiliki masalah dengan data Anda, seperti kebocoran target atau ketidakseimbangan, laporan wawasan dapat membawa masalah tersebut ke perhatian Anda. Untuk informasi selengkapnya tentang membuat laporan, lihatDapatkan Wawasan Tentang Kualitas Data dan Data.
Eksplorasi Data
Pertama, buat ringkasan tabel data menggunakan analisis. Lakukan hal-hal berikut:
-
Pilih + di sebelah langkah Tipe data dalam aliran data Anda dan pilih Tambahkan analisis.
-
Di area Analisis, pilih Ringkasan tabel dari daftar dropdown.
-
Berikan ringkasan tabel sebuah Nama.
-
Pilih Pratinjau untuk melihat pratinjau tabel yang akan dibuat.
-
Pilih Simpan untuk menyimpannya ke aliran data Anda. Itu muncul di bawah Semua Analisis.
Dengan menggunakan statistik yang Anda lihat, Anda dapat melakukan pengamatan yang serupa dengan yang berikut tentang kumpulan data ini:
-
Rata-rata tarif (rata-rata) adalah sekitar $33, sedangkan maks lebih dari $500. Kolom ini kemungkinan memiliki outlier.
-
Dataset ini menggunakan? untuk menunjukkan nilai yang hilang. Sejumlah kolom memiliki nilai yang hilang: cabin, embarked, dan home.dest
-
Kategori usia tidak memiliki lebih dari 250 nilai.
Selanjutnya, bersihkan data Anda menggunakan wawasan yang diperoleh dari statistik ini.
Jatuhkan Kolom yang Tidak Digunakan
Dengan menggunakan analisis dari bagian sebelumnya, bersihkan kumpulan data untuk mempersiapkannya untuk pelatihan. Untuk menambahkan transformasi baru ke aliran data Anda, pilih + di sebelah langkah Jenis data dalam aliran data Anda dan pilih Tambahkan transformasi.
Pertama, jatuhkan kolom yang tidak ingin Anda gunakan untuk pelatihan. Anda dapat menggunakan pustaka analisis data panda
Gunakan prosedur berikut untuk menjatuhkan kolom yang tidak digunakan.
Untuk menjatuhkan kolom yang tidak digunakan.
-
Buka alur Data Wrangler.
-
Ada dua node dalam aliran Data Wrangler Anda. Pilih + di sebelah kanan node tipe Data.
-
Pilih Tambahkan transformasi.
-
Di kolom Semua langkah, pilih Tambahkan langkah.
-
Dalam daftar Transformasi standar, pilih Kelola Kolom. Transformasi standar sudah jadi, transformasi bawaan. Pastikan kolom Drop dipilih.
-
Di bawah Kolom untuk dijatuhkan, periksa nama kolom berikut:
-
kabin
-
karcis
-
name
-
sibsp
-
parch
-
rumah.dest
-
perahu
-
body
-
-
Pilih Pratinjau.
-
Verifikasi bahwa kolom telah dijatuhkan, lalu pilih Tambah.
Untuk melakukan ini menggunakan panda, ikuti langkah-langkah ini.
-
Di kolom Semua langkah, pilih Tambahkan langkah.
-
Dalam daftar Custom transform, pilih Custom transform.
-
Berikan nama untuk transformasi Anda, dan pilih Python (Pandas) dari daftar dropdown.
-
Masukkan skrip Python berikut di kotak kode.
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
Pilih Pratinjau untuk melihat pratinjau perubahan, lalu pilih Tambah untuk menambahkan transformasi.
Bersihkan Nilai yang Hilang
Sekarang, bersihkan nilai yang hilang. Anda dapat melakukan ini dengan Menangani grup transformasi nilai yang hilang.
Sejumlah kolom memiliki nilai yang hilang. Dari kolom yang tersisa, usia dan tarif mengandung nilai yang hilang. Periksa ini menggunakan Custom Transform.
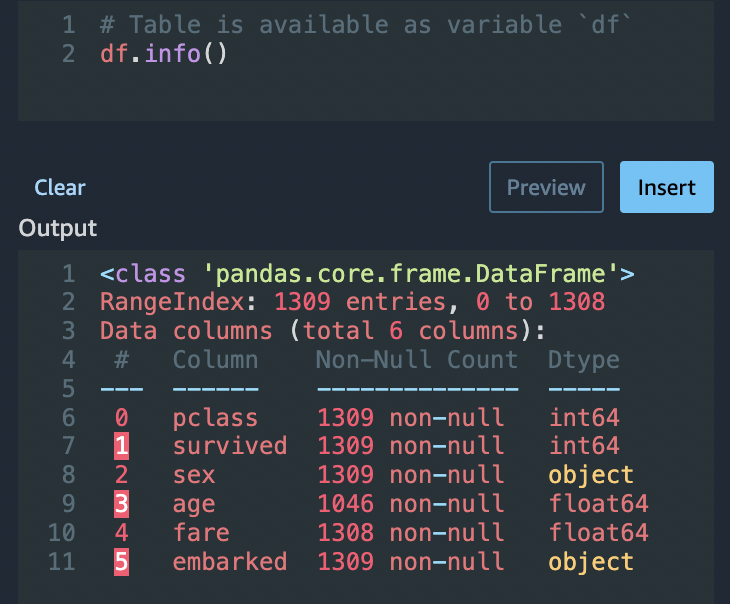
Menggunakan opsi Python (Pandas), gunakan yang berikut ini untuk meninjau dengan cepat jumlah entri di setiap kolom:
df.info()
Untuk menjatuhkan baris dengan nilai yang hilang dalam kategori usia, lakukan hal berikut:
-
Pilih Handle hilang.
-
Pilih Drop missing untuk Transformer.
-
Pilih usia untuk kolom Input.
-
Pilih Pratinjau untuk melihat bingkai data baru, lalu pilih Tambah untuk menambahkan transformasi ke alur Anda.
-
Ulangi proses yang sama untuk ongkos.
Anda dapat menggunakan df.info() di bagian Custom transform untuk mengonfirmasi bahwa semua baris sekarang memiliki 1.045 nilai.
Panda Kustom: Encode
Coba pengkodean datar menggunakan Pandas. Pengkodean data kategoris adalah proses menciptakan representasi numerik untuk kategori. Misalnya, jika kategori Anda Dog danCat, Anda dapat menyandikan informasi ini menjadi dua vektor: [1,0] untuk mewakiliDog, dan [0,1] untuk mewakili. Cat
-
Di bagian Custom Transform, pilih Python (Pandas) dari daftar dropdown.
-
Masukkan yang berikut ini di kotak kode.
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
Pilih Pratinjau untuk melihat pratinjau perubahan. Versi yang dikodekan dari setiap kolom ditambahkan ke kumpulan data.
-
Pilih Tambah untuk menambahkan transformasi.
Kustom SQL: PILIH Kolom
Sekarang, pilih kolom yang ingin Anda gunakan SQL. Untuk demo ini, pilih kolom yang tercantum dalam SELECT pernyataan berikut. Karena bertahan adalah kolom target Anda untuk pelatihan, letakkan kolom itu terlebih dahulu.
-
Di bagian Custom Transform, pilih SQL (PySpark SQL) dari daftar dropdown.
-
Masukkan yang berikut ini di kotak kode.
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
Pilih Pratinjau untuk melihat pratinjau perubahan. Kolom yang tercantum dalam
SELECTpernyataan Anda adalah satu-satunya kolom yang tersisa. -
Pilih Tambah untuk menambahkan transformasi.
Ekspor ke Notebook Data Wrangler
Setelah selesai membuat aliran data, Anda memiliki sejumlah opsi ekspor. Bagian berikut menjelaskan cara mengekspor ke buku catatan pekerjaan Data Wrangler. Pekerjaan Data Wrangler digunakan untuk memproses data Anda menggunakan langkah-langkah yang ditentukan dalam aliran data Anda. Untuk mempelajari lebih lanjut tentang semua opsi ekspor, lihatEkspor.
Ekspor ke Data Wrangler Job Notebook
Saat Anda mengekspor aliran data menggunakan pekerjaan Data Wrangler, proses akan secara otomatis membuat Notebook Jupyter. Buku catatan ini secara otomatis terbuka di instans Studio Classic Anda dan dikonfigurasi untuk menjalankan pekerjaan SageMaker Pemrosesan untuk menjalankan aliran data Wrangler Data Anda, yang disebut sebagai pekerjaan Data Wrangler.
-
Simpan aliran data Anda. Pilih File dan kemudian pilih Save Data Wrangler Flow.
-
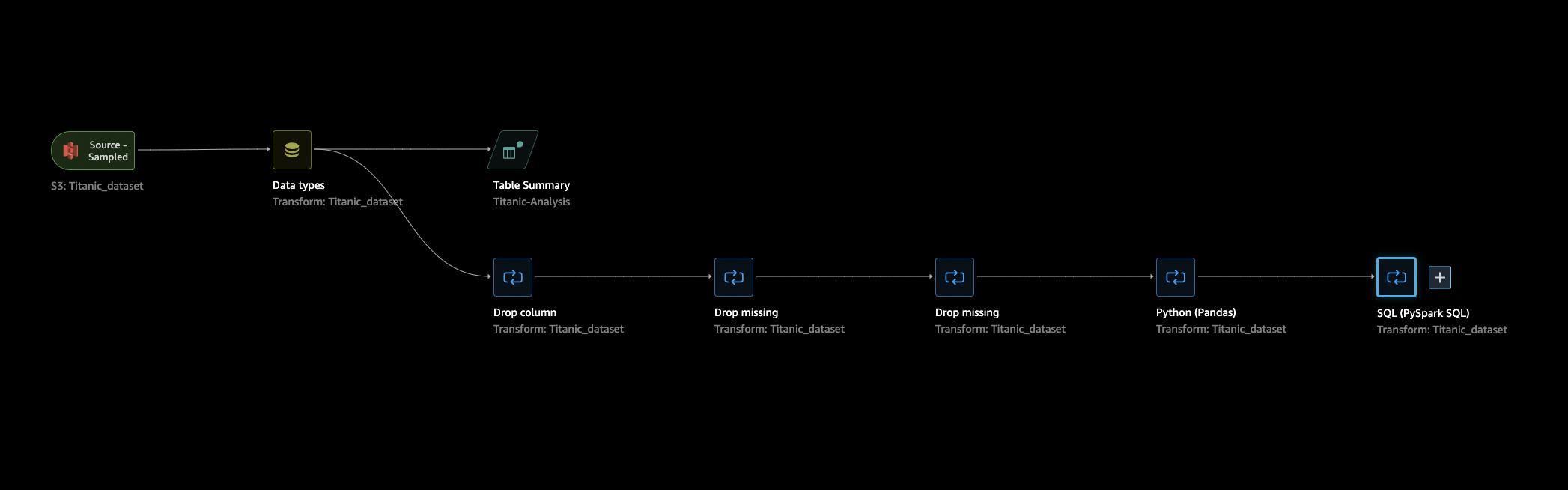
Kembali ke tab Aliran Data, pilih langkah terakhir dalam aliran data Anda (SQL), lalu pilih + untuk membuka navigasi.
-
Pilih Ekspor, dan Amazon S3 (melalui Jupyter Notebook). Ini membuka Notebook Jupyter.
-
Pilih kernel Python 3 (Data Science) untuk Kernel.
-
Saat kernel dimulai, jalankan sel di buku catatan hingga Kick off SageMaker Training Job (Opsional).
-
Secara opsional, Anda dapat menjalankan sel di Kick off SageMaker Training Job (Opsional) jika Anda ingin membuat pekerjaan pelatihan SageMaker AI untuk melatih pengklasifikasi XGBoost. Anda dapat menemukan biaya untuk menjalankan pekerjaan SageMaker pelatihan di Amazon SageMaker Pricing
. Atau, Anda dapat menambahkan blok kode yang ditemukan di notebook dan menjalankannya Pelatihan XGBoost Classifier untuk menggunakan pustaka sumber terbuka XGBoost
untuk melatih pengklasifikasi XGBoost. -
Hapus komentar dan jalankan sel di bawah Pembersihan dan jalankan untuk mengembalikan SageMaker Python SDK ke versi aslinya.
Anda dapat memantau status pekerjaan Data Wrangler Anda di konsol SageMaker AI di tab Processing. Selain itu, Anda dapat memantau pekerjaan Data Wrangler Anda menggunakan Amazon. CloudWatch Untuk informasi tambahan, lihat Memantau Pekerjaan SageMaker Pemrosesan Amazon dengan CloudWatch Log dan Metrik.
Jika Anda memulai pekerjaan pelatihan, Anda dapat memantau statusnya menggunakan konsol SageMaker AI di bawah Pekerjaan Pelatihan di bagian Pelatihan.
Pelatihan XGBoost Classifier
Anda dapat melatih XGBoost Binary Classifier menggunakan notebook Jupyter atau Amazon Autopilot. SageMaker Anda dapat menggunakan Autopilot untuk secara otomatis melatih dan menyetel model pada data yang telah Anda ubah langsung dari alur Data Wrangler Anda. Untuk informasi tentang Autopilot, lihat. Secara Otomatis Melatih Model pada Alur Data Anda
Di buku catatan yang sama yang memulai pekerjaan Data Wrangler, Anda dapat menarik data dan melatih XGBoost Binary Classifier menggunakan data yang disiapkan dengan persiapan data minimal.
-
Pertama, tingkatkan modul yang diperlukan menggunakan
pipdan hapus file _SUCCESS (file terakhir ini bermasalah saat menggunakanawswrangler).! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
Baca data dari Amazon S3. Anda dapat menggunakan
awswrangleruntuk membaca semua file CSV secara rekursif di awalan S3. Data kemudian dibagi menjadi fitur dan label. Label adalah kolom pertama dari kerangka data.import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
Terakhir, buat DMatrices (struktur primitif XGBoost untuk data) dan lakukan validasi silang menggunakan klasifikasi biner XGBoost.
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
Matikan Data Wrangler
Setelah selesai menggunakan Data Wrangler, kami sarankan Anda mematikan instans yang dijalankan untuk menghindari biaya tambahan. Untuk mempelajari cara mematikan aplikasi Data Wrangler dan instance terkait, lihat. Matikan Data Wrangler
