Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pelatihan model
Tahap pelatihan siklus hidup pembelajaran mesin (ML) lengkap mencakup dari mengakses kumpulan data pelatihan Anda hingga menghasilkan model akhir dan memilih model berkinerja terbaik untuk penerapan. Bagian berikut memberikan gambaran umum tentang fitur SageMaker pelatihan yang tersedia dan sumber daya dengan informasi teknis yang mendalam untuk masing-masing.
Arsitektur dasar SageMaker Pelatihan
Jika Anda menggunakan SageMaker AI untuk pertama kalinya dan ingin menemukan solusi ML cepat untuk melatih model pada kumpulan data Anda, pertimbangkan untuk menggunakan solusi tanpa kode atau kode rendah seperti SageMaker Canvas, JumpStartdalam SageMaker Studio Classic, atau Autopilot. SageMaker
Untuk pengalaman pengkodean menengah, pertimbangkan untuk menggunakan notebook SageMaker Studio Classic atau Instans SageMaker Notebook. Untuk memulai, ikuti petunjuk di Latih Model panduan SageMaker Memulai AI. Kami merekomendasikan ini untuk kasus penggunaan di mana Anda membuat model dan skrip pelatihan Anda sendiri menggunakan kerangka kerja HTML.
Inti dari pekerjaan SageMaker AI adalah kontainerisasi beban kerja ML dan kemampuan mengelola sumber daya komputasi. Platform SageMaker Pelatihan menangani pengangkatan berat yang terkait dengan pengaturan dan pengelolaan infrastruktur untuk beban kerja pelatihan ML. Dengan SageMaker Pelatihan, Anda dapat fokus pada pengembangan, pelatihan, dan penyempurnaan model Anda.
Diagram arsitektur berikut menunjukkan bagaimana SageMaker AI mengelola pekerjaan pelatihan ML dan menyediakan instans Amazon EC2 atas nama pengguna AI. SageMaker Anda sebagai pengguna SageMaker AI dapat membawa dataset pelatihan Anda sendiri, menyimpannya ke Amazon S3. Anda dapat memilih pelatihan model ML dari algoritme bawaan SageMaker AI yang tersedia, atau membawa skrip pelatihan Anda sendiri dengan model yang dibuat dengan kerangka kerja pembelajaran mesin yang populer.
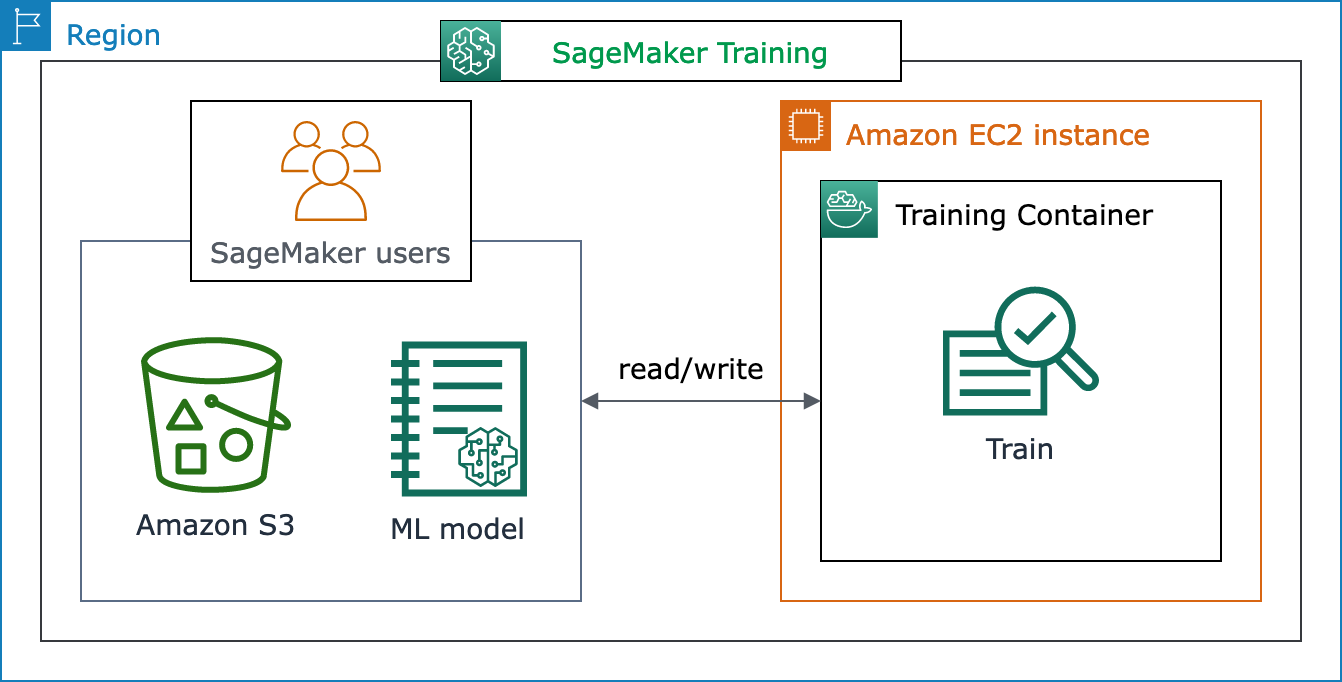
Tampilan penuh alur kerja dan fitur SageMaker Pelatihan
Perjalanan penuh pelatihan ML melibatkan tugas-tugas di luar konsumsi data ke model ML, model pelatihan tentang instance komputasi, dan memperoleh artefak dan output model. Anda perlu mengevaluasi setiap fase sebelum, selama, dan setelah pelatihan untuk memastikan model Anda dilatih dengan baik untuk memenuhi akurasi target untuk tujuan Anda.
Diagram alir berikut menunjukkan ikhtisar tingkat tinggi dari tindakan Anda (dalam kotak biru) dan fitur SageMaker Pelatihan yang tersedia (dalam kotak biru muda) selama fase pelatihan siklus hidup ML.
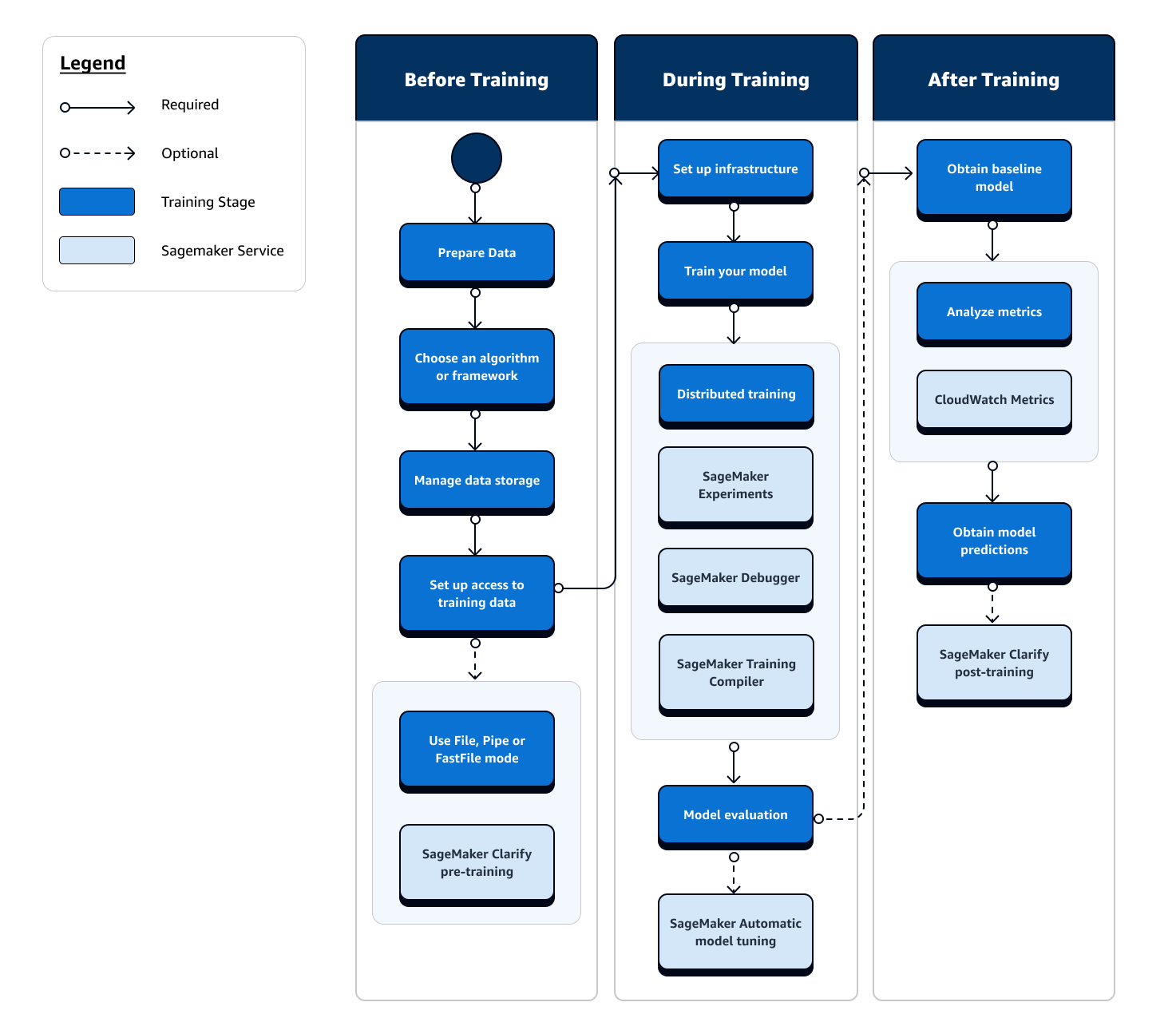
Bagian berikut memandu Anda melalui setiap fase pelatihan yang digambarkan dalam diagram alir sebelumnya dan fitur berguna yang ditawarkan oleh SageMaker AI di seluruh tiga sub-tahap pelatihan ML.
Sebelum pelatihan
Ada sejumlah skenario pengaturan sumber daya data dan akses yang perlu Anda pertimbangkan sebelum pelatihan. Lihat diagram berikut dan detail dari setiap tahap sebelum pelatihan untuk memahami keputusan apa yang perlu Anda buat.
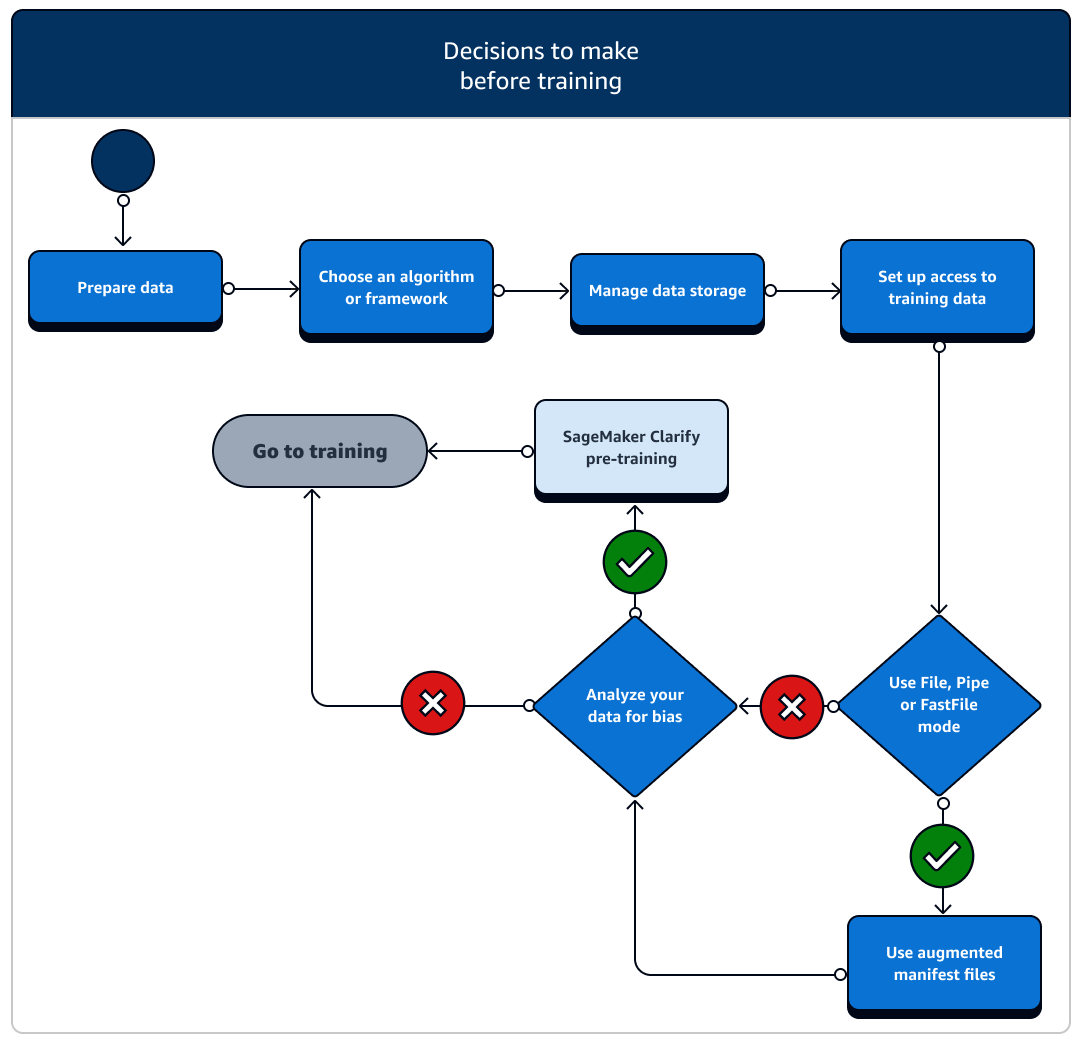
-
Siapkan data: Sebelum pelatihan, Anda harus menyelesaikan pembersihan data dan rekayasa fitur selama tahap persiapan data. SageMaker AI memiliki beberapa pelabelan dan alat rekayasa fitur untuk membantu Anda. Lihat Label Data, Mempersiapkan dan Menganalisis Kumpulan Data, Memproses Data, dan Membuat, Menyimpan, dan Berbagi Fitur untuk informasi selengkapnya.
-
Pilih algoritma atau kerangka kerja: Bergantung pada seberapa banyak penyesuaian yang Anda butuhkan, ada opsi berbeda untuk algoritme dan kerangka kerja.
-
Jika Anda lebih suka implementasi kode rendah dari algoritma pra-bangun, gunakan salah satu algoritma bawaan yang ditawarkan oleh AI. SageMaker Untuk informasi selengkapnya, lihat Memilih Algoritma.
-
Jika Anda membutuhkan lebih banyak fleksibilitas untuk menyesuaikan model Anda, jalankan skrip pelatihan Anda menggunakan kerangka kerja dan toolkit pilihan Anda dalam AI. SageMaker Untuk informasi selengkapnya, lihat Kerangka Kerja dan Toolkit ML.
-
Untuk memperluas gambar SageMaker AI Docker yang sudah dibuat sebelumnya sebagai gambar dasar wadah Anda sendiri, lihat Menggunakan gambar Pre-built SageMaker AI Docker.
-
Untuk membawa kontainer Docker kustom Anda ke SageMaker AI, lihat Mengadaptasi wadah Docker Anda sendiri agar berfungsi dengan AI. SageMaker Anda perlu menginstal sagemaker-training-toolkit
ke wadah Anda.
-
-
Mengelola penyimpanan data: Memahami pemetaan antara penyimpanan data (seperti Amazon S3, Amazon EFS, atau Amazon FSx) dan wadah pelatihan yang berjalan di instans komputasi Amazon EC2. SageMaker AI membantu memetakan jalur penyimpanan dan jalur lokal dalam wadah pelatihan. Anda juga dapat menentukannya secara manual. Setelah pemetaan selesai, pertimbangkan untuk menggunakan salah satu mode transmisi data: File, Pipa, dan FastFile mode. Untuk mempelajari cara SageMaker AI memetakan jalur penyimpanan, lihat Folder Penyimpanan Pelatihan.
-
Siapkan akses ke data pelatihan: Gunakan domain Amazon SageMaker AI, profil pengguna domain, IAM, Amazon VPC, AWS KMS dan untuk memenuhi persyaratan organisasi yang paling sensitif terhadap keamanan.
-
Untuk administrasi akun, lihat Domain Amazon SageMaker AI.
-
Untuk referensi lengkap tentang kebijakan dan keamanan IAM, lihat Keamanan di Amazon SageMaker AI.
-
-
Streaming data input Anda: SageMaker AI menyediakan tiga mode input data, File, Pipe, dan FastFile. Mode input default adalah mode File, yang memuat seluruh kumpulan data selama menginisialisasi pekerjaan pelatihan. Untuk mempelajari praktik terbaik umum untuk streaming data dari penyimpanan data Anda ke wadah pelatihan, lihat Mengakses Data Pelatihan.
Dalam kasus mode Pipe, Anda juga dapat mempertimbangkan untuk menggunakan file manifes tambahan untuk mengalirkan data Anda langsung dari Amazon Simple Storage Service (Amazon S3) dan melatih model Anda. Menggunakan mode pipa mengurangi ruang disk karena Amazon Elastic Block Store hanya perlu menyimpan artefak model akhir Anda, daripada menyimpan kumpulan data pelatihan lengkap Anda. Untuk informasi selengkapnya, lihat Menyediakan Metadata Set Data ke Pekerjaan Pelatihan dengan File Manifes Tertambah.
-
Analisis data Anda untuk bias: Sebelum pelatihan, Anda dapat menganalisis kumpulan data dan memodelkan bias terhadap grup yang tidak disukai sehingga Anda dapat memeriksa apakah model Anda mempelajari kumpulan data yang tidak bias menggunakan Clarify. SageMaker
-
Pilih SageMaker SDK mana yang akan digunakan: Ada dua cara untuk meluncurkan pekerjaan pelatihan di SageMaker AI: menggunakan AI SageMaker Python SDK tingkat tinggi, atau menggunakan SageMaker API tingkat rendah untuk SDK for Python (Boto3) atau. AWS CLI SageMaker Python SDK mengabstraksi SageMaker API tingkat rendah untuk menyediakan alat yang nyaman. Seperti disebutkan di atasArsitektur dasar SageMaker Pelatihan, Anda juga dapat mengejar opsi tanpa kode atau kode minimal menggunakan SageMaker Canvas, JumpStart dalam SageMaker Studio Classic, atau AI Autopilot. SageMaker
Selama pelatihan
Selama pelatihan, Anda perlu terus meningkatkan stabilitas pelatihan, kecepatan pelatihan, efisiensi pelatihan sambil menskalakan sumber daya komputasi, pengoptimalan biaya, dan, yang paling penting, kinerja model. Baca terus untuk informasi lebih lanjut tentang tahapan pelatihan selama dan fitur SageMaker Pelatihan yang relevan.
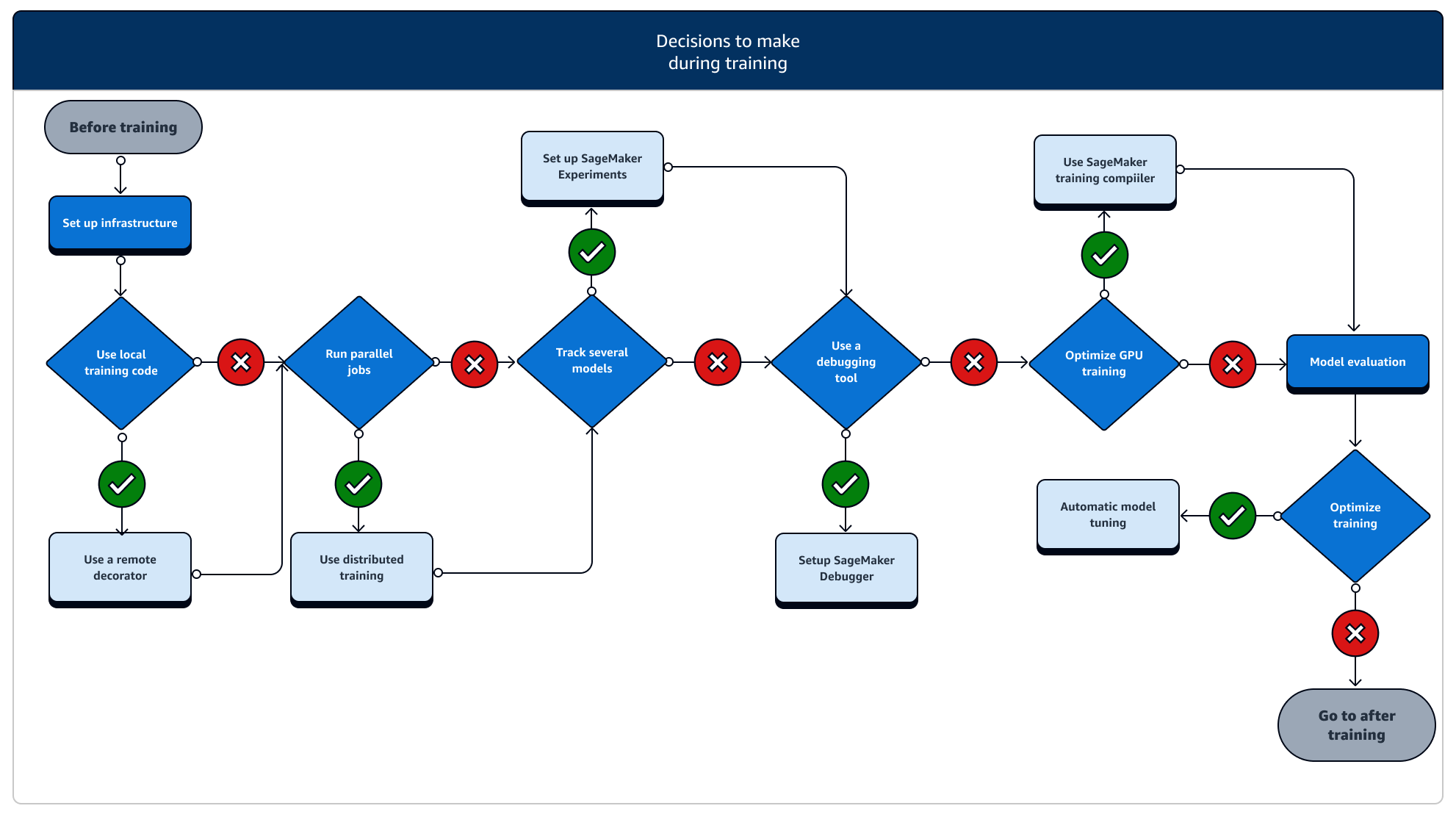
-
Siapkan infrastruktur: Pilih jenis instans dan alat manajemen infrastruktur yang tepat untuk kasus penggunaan Anda. Anda dapat memulai dari contoh kecil dan meningkatkan tergantung pada beban kerja Anda. Untuk melatih model pada kumpulan data tabular, mulailah dengan instance CPU terkecil dari keluarga instance C4 atau C5. Untuk melatih model besar untuk visi komputer atau pemrosesan bahasa alami, mulailah dengan instance GPU terkecil dari keluarga instance P2, P3, G4dn atau G5. Anda juga dapat mencampur berbagai jenis instans dalam klaster, atau menyimpan instance di kolam hangat menggunakan alat manajemen instans berikut yang ditawarkan oleh SageMaker AI. Anda juga dapat menggunakan cache persisten untuk mengurangi latensi dan waktu yang dapat ditagih pada pekerjaan pelatihan berulang selama pengurangan latensi dari kolam hangat saja. Untuk mempelajari lebih lanjut, lihat topik berikut.
Anda harus memiliki kuota yang cukup untuk menjalankan pekerjaan pelatihan. Jika Anda menjalankan pekerjaan pelatihan Anda pada contoh di mana Anda memiliki kuota yang tidak mencukupi, Anda akan menerima
ResourceLimitExceededkesalahan. Untuk memeriksa kuota yang tersedia saat ini di akun Anda, gunakan konsol Service QuotasAnda. Untuk mempelajari cara meminta peningkatan kuota, lihat Wilayah dan Kuota yang Didukung. Juga, untuk menemukan informasi harga dan jenis instans yang tersedia tergantung pada Wilayah AWS, cari tabel di halaman SageMaker Harga Amazon . -
Jalankan pekerjaan pelatihan dari kode lokal: Anda dapat membuat anotasi kode lokal Anda dengan dekorator jarak jauh untuk menjalankan kode Anda sebagai pekerjaan SageMaker pelatihan dari dalam Amazon SageMaker Studio Classic, SageMaker notebook Amazon, atau dari lingkungan pengembangan terintegrasi lokal Anda. Untuk informasi selengkapnya, lihat Jalankan kode lokal Anda sebagai pekerjaan SageMaker pelatihan.
-
Lacak pekerjaan pelatihan: Pantau dan lacak pekerjaan pelatihan Anda menggunakan SageMaker Eksperimen, SageMaker Debugger, atau Amazon. CloudWatch Anda dapat menonton kinerja model dalam hal akurasi dan konvergensi, dan menjalankan analisis komparatif metrik antara beberapa pekerjaan pelatihan dengan menggunakan SageMaker Eksperimen AI. Anda dapat menonton tingkat pemanfaatan sumber daya komputasi dengan menggunakan alat profil SageMaker Debugger atau Amazon. CloudWatch Untuk mempelajari lebih lanjut, lihat topik berikut.
Selain itu, untuk tugas pembelajaran mendalam, gunakan alat SageMaker debugging model Amazon Debugger dan aturan bawaan untuk mengidentifikasi masalah yang lebih kompleks dalam proses konvergensi model dan pembaruan bobot.
-
Pelatihan terdistribusi: Jika pekerjaan pelatihan Anda memasuki tahap yang stabil tanpa putus karena kesalahan konfigurasi infrastruktur pelatihan atau masalah di luar memori, Anda mungkin ingin menemukan lebih banyak opsi untuk meningkatkan skala pekerjaan Anda dan menjalankan dalam jangka waktu yang lama untuk berhari-hari dan bahkan berbulan-bulan. Saat Anda siap untuk meningkatkan, pertimbangkan pelatihan terdistribusi. SageMaker AI menyediakan berbagai opsi untuk komputasi terdistribusi dari beban kerja MS ringan hingga beban kerja pembelajaran mendalam yang berat.
Untuk tugas pembelajaran mendalam yang melibatkan pelatihan model yang sangat besar pada kumpulan data yang sangat besar, pertimbangkan untuk menggunakan salah satu strategi pelatihan terdistribusi SageMaker AI untuk meningkatkan dan mencapai paralelisme data, paralelisme model, atau kombinasi keduanya. Anda juga dapat menggunakan SageMaker Training Compiler untuk mengkompilasi dan mengoptimalkan grafik model pada instance GPU. Fitur SageMaker AI ini mendukung kerangka pembelajaran mendalam seperti PyTorch, TensorFlow, dan Hugging Face Transformers.
-
Penyetelan hiperparameter model: Setel hiperparameter model Anda menggunakan Penyetelan Model Otomatis dengan AI. SageMaker SageMaker AI menyediakan metode penyetelan hiperparameter seperti pencarian grid dan pencarian Bayesian, meluncurkan pekerjaan penyetelan hyperparameter paralel dengan fungsionalitas penghentian awal untuk pekerjaan penyetelan hiperparameter yang tidak meningkatkan.
-
Checkpointing dan penghematan biaya dengan instans Spot: Jika waktu pelatihan bukan masalah besar, Anda dapat mempertimbangkan untuk mengoptimalkan biaya pelatihan model dengan instans Spot terkelola. Perhatikan bahwa Anda harus mengaktifkan checkpointing untuk pelatihan Spot agar tetap memulihkan dari jeda pekerjaan intermiten karena penggantian instans Spot. Anda juga dapat menggunakan fungsionalitas pos pemeriksaan untuk mencadangkan model Anda jika terjadi pemutusan hubungan kerja pelatihan yang tidak terduga. Untuk mempelajari lebih lanjut, lihat topik berikut.
Setelah pelatihan
Setelah pelatihan, Anda mendapatkan artefak model akhir untuk digunakan untuk penerapan dan inferensi model. Ada tindakan tambahan yang terlibat dalam fase setelah pelatihan seperti yang ditunjukkan pada diagram berikut.
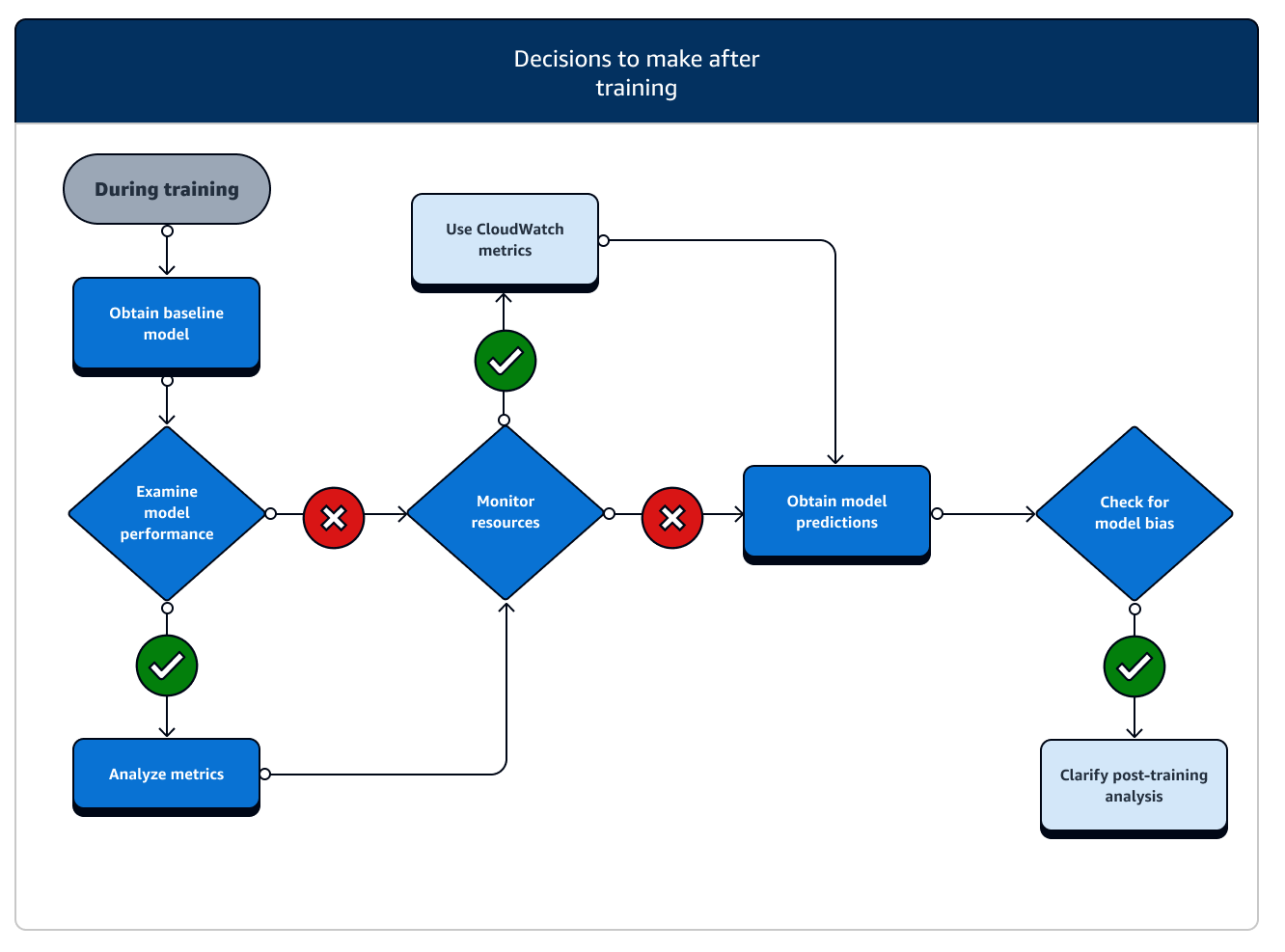
-
Dapatkan model dasar: Setelah Anda memiliki artefak model, Anda dapat mengaturnya sebagai model dasar. Pertimbangkan tindakan pasca-pelatihan berikut dan gunakan fitur SageMaker AI sebelum beralih ke penerapan model ke produksi.
-
Periksa kinerja model dan periksa bias: Gunakan CloudWatch Metrik Amazon dan SageMaker Klarifikasi untuk bias pasca-pelatihan untuk mendeteksi bias apa pun dalam data dan model yang masuk dari waktu ke waktu terhadap baseline. Anda perlu mengevaluasi data baru dan prediksi model Anda terhadap data baru secara teratur atau secara real time. Dengan menggunakan fitur-fitur ini, Anda dapat menerima peringatan tentang perubahan atau anomali akut, serta perubahan bertahap atau penyimpangan dalam data dan model.
-
Anda juga dapat menggunakan fungsionalitas Pelatihan Inkremental SageMaker AI untuk memuat dan memperbarui model Anda (atau menyempurnakan) dengan kumpulan data yang diperluas.
-
Anda dapat mendaftarkan pelatihan model sebagai langkah dalam Pipeline SageMaker AI Anda atau sebagai bagian dari fitur Alur Kerja lain yang ditawarkan oleh SageMaker AI untuk mengatur siklus hidup ML penuh.
