Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat template tugas pekerja khusus
Untuk membuat pekerjaan pelabelan kustom, Anda perlu memperbarui template tugas pekerja, memetakan data input dari file manifes ke variabel yang digunakan dalam template, dan memetakan data keluaran ke Amazon S3. Untuk mempelajari lebih lanjut tentang fitur-fitur canggih yang menggunakan otomatisasi Liquid, lihatMenambahkan otomatisasi dengan Liquid.
Bagian berikut menjelaskan setiap langkah yang diperlukan.
Templat tugas pekerja
Template tugas pekerja adalah file yang digunakan oleh Ground Truth untuk menyesuaikan antarmuka pengguna pekerja (UI). Anda dapat membuat template tugas pekerja menggunakan HTML, CSS,, bahasa template Liquid JavaScript
Gunakan topik berikut untuk mempelajari cara membuat templat tugas pekerja. Anda dapat melihat repositori contoh template tugas pekerja Ground Truth. GitHub
Menggunakan template tugas pekerja dasar di konsol SageMaker AI
Anda dapat menggunakan editor template di konsol Ground Truth untuk mulai membuat template. Editor ini mencakup sejumlah templat dasar yang telah dirancang sebelumnya. Ini mendukung pengisian otomatis untuk kode HTML dan Crowd HTML Element.
Untuk mengakses editor template kustom Ground Truth:
-
Mengikuti instruksi diMembuat Job Pelabelan (Konsol).
-
Kemudian pilih Kustom untuk pekerjaan pelabelan Jenis tugas.
-
Pilih Berikutnya, lalu Anda dapat mengakses editor templat dan templat dasar di bagian Pengaturan tugas pelabelan khusus.
-
(Opsional) Pilih template dasar dari menu drop-down di bawah Template. Jika Anda lebih suka membuat template dari awal, pilih Custom dari menu drop-down untuk kerangka template minimal.
Gunakan bagian berikut untuk mempelajari cara memvisualisasikan template yang dikembangkan di konsol secara lokal.
Memvisualisasikan templat tugas pekerja Anda secara lokal
Anda harus menggunakan konsol untuk menguji bagaimana template Anda memproses data yang masuk. Untuk menguji tampilan dan nuansa HTML template Anda dan elemen kustom Anda dapat menggunakan browser Anda.
catatan
Variabel tidak akan diuraikan. Anda mungkin perlu menggantinya dengan konten sampel saat melihat konten Anda secara lokal.
Contoh cuplikan kode berikut memuat kode yang diperlukan untuk membuat elemen HTML kustom. Gunakan ini jika Anda ingin mengembangkan tampilan dan nuansa template Anda di editor pilihan Anda daripada di konsol.
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
Membuat contoh tugas HTML sederhana
Sekarang setelah Anda memiliki template tugas pekerja dasar, Anda dapat menggunakan topik ini untuk membuat template tugas berbasis HTML sederhana.
Berikut ini adalah contoh entri dari file manifes masukan.
{ "source": "This train is really late.", "labels": [ "angry" , "sad", "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }
Dalam template tugas HTML kita perlu memetakan variabel dari file manifes masukan ke template. Variabel dari manifes masukan contoh akan dipetakan menggunakan sintaks berikuttask.input.source,task.input.labels, dan. task.input.header
Berikut ini adalah contoh sederhana template tugas pekerja HTML untuk analisis tweet. Semua tugas dimulai dan diakhiri dengan <crowd-form> </crowd-form> elemen. Seperti <form> elemen HTML standar, semua kode formulir Anda harus berada di antara mereka. Ground Truth menghasilkan tugas pekerja langsung dari konteks yang ditentukan dalam template, kecuali Anda menerapkan Lambda pra-anotasi. taskInputObjek yang dikembalikan oleh Ground Truth atau Lambda pra-anotasi merupakan task.input objek dalam template Anda.
Untuk tugas analisis tweet sederhana, gunakan elemen. <crowd-classifier> Ini membutuhkan atribut berikut:
nama - Nama variabel output Anda. Anotasi pekerja disimpan ke nama variabel ini dalam manifes keluaran Anda.
kategori - array JSON diformat dari jawaban yang mungkin.
header - judul untuk alat anotasi
<crowd-classifier>Elemen ini membutuhkan setidaknya tiga elemen anak berikut.
<classification-target>- Teks pekerja akan mengklasifikasikan berdasarkan opsi yang ditentukan dalam
categoriesatribut di atas.<full-instructions>- Petunjuk yang tersedia dari tautan “Lihat instruksi lengkap” di alat. Ini dapat dibiarkan kosong, tetapi disarankan agar Anda memberikan instruksi yang baik untuk mendapatkan hasil yang lebih baik.
<short-instructions>- Deskripsi yang lebih singkat tentang tugas yang muncul di sidebar alat. Ini dapat dibiarkan kosong, tetapi disarankan agar Anda memberikan instruksi yang baik untuk mendapatkan hasil yang lebih baik.
Versi sederhana dari alat ini akan terlihat seperti berikut. Variabel {{ task.input.source }} adalah apa yang menentukan data sumber dari file manifes masukan Anda. {{ task.input.labels | to_json }}Ini adalah contoh filter variabel untuk mengubah array menjadi representasi JSON. categoriesAtribut harus JSON.
contoh menggunakan crowd-classifier dengan manifes masukan sampel json
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="tweetFeeling"categories="='{{ task.input.labels | to_json }}'" header="{{ task.input.header }}'" > <classification-target>{{ task.input.source }}</classification-target> <full-instructions header="Sentiment Analysis Instructions"> Try to determine the sentiment the author of the tweet is trying to express. If none seem to match, choose "cannot determine." </full-instructions> <short-instructions> Pick the term that best describes the sentiment of the tweet. </short-instructions> </crowd-classifier> </crowd-form>
Anda dapat menyalin dan menempelkan kode ke editor di alur kerja pembuatan pekerjaan pelabelan Ground Truth untuk melihat pratinjau alat, atau mencoba demo kode ini
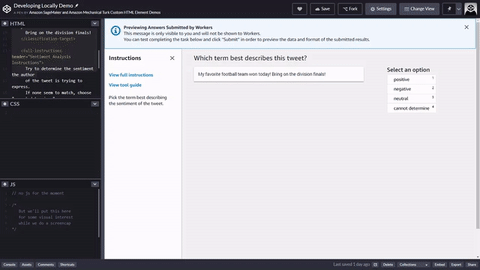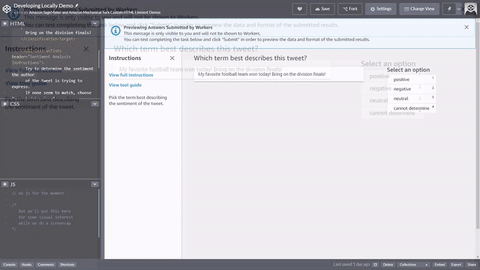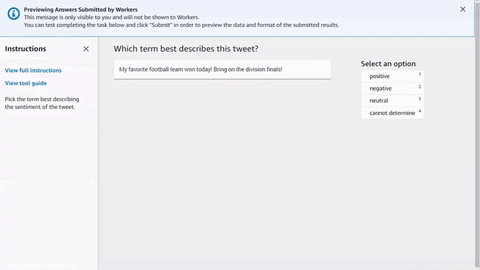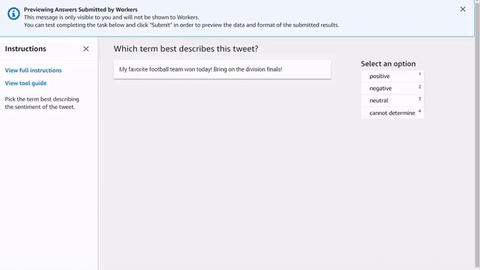
Masukan data, aset eksternal, dan templat tugas Anda
Bagian berikut menjelaskan penggunaan aset eksternal, persyaratan format data input, dan kapan harus mempertimbangkan untuk menggunakan fungsi Lambda pra-anotasi.
Persyaratan format data masukan
Saat membuat file manifes masukan untuk digunakan dalam pekerjaan pelabelan Ground Truth kustom, Anda harus menyimpan data di Amazon S3. File manifes masukan juga harus disimpan di tempat yang sama Wilayah AWS di mana pekerjaan pelabelan Ground Truth kustom Anda akan dijalankan. Selain itu, dapat disimpan di bucket Amazon S3 apa pun yang dapat diakses oleh peran layanan IAM yang Anda gunakan untuk menjalankan pekerjaan pelabelan khusus Anda di Ground Truth.
File manifes masukan harus menggunakan format baris JSON atau JSON yang dibatasi baris baru. Setiap baris dibatasi oleh jeda garis standar, \n atau. \r\n Setiap baris juga harus menjadi objek JSON yang valid.
Selanjutnya, setiap objek JSON dalam file manifes harus berisi salah satu kunci berikut: source-ref atausource. Nilai kunci ditafsirkan sebagai berikut:
-
source-ref— Sumber objek adalah objek Amazon S3 yang ditentukan dalam nilai. Gunakan nilai ini ketika objek adalah objek biner, seperti gambar. -
source— Sumber objek adalah nilainya. Gunakan nilai ini ketika objek adalah nilai teks.
Untuk mempelajari lebih lanjut tentang memformat file manifes masukan, lihatMasukan file manifes.
Fungsi Lambda pra-anotasi
Anda dapat secara opsional menentukan fungsi Lambda pra-anotasi untuk mengelola cara data dari file manifes masukan Anda ditangani sebelum pelabelan. Jika Anda telah menentukan pasangan isHumanAnnotationRequired kunci-nilai Anda harus kami fungsi Lambda pra-anotasi. Ketika Ground Truth mengirimkan fungsi Lambda pra-anotasi permintaan berformat JSON, ia menggunakan skema berikut.
contoh objek data diidentifikasi dengan pasangan source-ref kunci-nilai
{ "version": "2018-10-16", "labelingJobArn":arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source-ref":s3://input-data-bucket/data-object-file-name} }
contoh objek data diidentifikasi dengan pasangan source kunci-nilai
{ "version": "2018-10-16", "labelingJobArn" :arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source":Sue purchased 10 shares of the stock on April 10th, 2020} }
Berikut ini adalah respons yang diharapkan dari fungsi Lambda saat isHumanAnnotationRequired digunakan.
{ "taskInput":{ "source": "This train is really late.", "labels": [ "angry" , "sad" , "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }, "isHumanAnnotationRequired":False}
Menggunakan Aset Eksternal
Templat kustom Amazon SageMaker Ground Truth memungkinkan skrip eksternal dan style sheet disematkan. Misalnya, blok kode berikut menunjukkan bagaimana Anda akan menambahkan style sheet yang terletak di https://www.example.com/my-enhancement-styles.css template Anda.
<script src="https://www.example.com/my-enhancment-script.js"></script> <link rel="stylesheet" type="text/css" href="https://www.example.com/my-enhancement-styles.css">
Jika Anda menemukan kesalahan, pastikan bahwa server asal Anda mengirimkan jenis MIME yang benar dan encoding header dengan aset.
Misalnya, tipe MIME dan encoding untuk skrip jarak jauh adalah:. application/javascript;CHARSET=UTF-8
Jenis MIME dan encoding untuk stylesheet jarak jauh adalah:. text/css;CHARSET=UTF-8
Output data dan template tugas Anda
Bagian berikut menjelaskan data keluaran dari pekerjaan pelabelan khusus, dan kapan harus mempertimbangkan untuk menggunakan fungsi Lambda pasca-anotasi.
Data output
Saat tugas pelabelan khusus Anda selesai, data akan disimpan di bucket Amazon S3 yang ditentukan saat pekerjaan pelabelan dibuat. Data disimpan dalam output.manifest file.
catatan
labelAttributeNameadalah variabel placeholder. Dalam output Anda, itu adalah nama pekerjaan pelabelan Anda, atau nama atribut label yang Anda tentukan saat Anda membuat pekerjaan pelabelan.
-
sourceatausource-ref— Baik string atau pekerja URI S3 diminta untuk memberi label. -
labelAttributeName— Kamus yang berisi konten label konsolidasi dari fungsi Lambda pasca-anotasi. Jika fungsi Lambda pasca-anotasi tidak ditentukan, kamus ini akan kosong. -
labelAttributeName-metadata— Metadata dari pekerjaan pelabelan khusus Anda ditambahkan oleh Ground Truth. -
worker-response-ref— URI S3 dari bucket tempat data disimpan. Jika fungsi Lambda pasca-anotasi ditentukan, pasangan nilai kunci ini tidak akan muncul.
Dalam contoh ini objek JSON diformat untuk keterbacaan, dalam file output sebenarnya objek JSON berada pada satu baris.
{ "source" : "This train is really late.", "labelAttributeName" : {}, "labelAttributeName-metadata": { # These key values pairs are added by Ground Truth "job_name": "test-labeling-job", "type": "groundTruth/custom", "human-annotated": "yes", "creation_date": "2021-03-08T23:06:49.111000", "worker-response-ref": "s3://amzn-s3-demo-bucket/test-labeling-job/annotations/worker-response/iteration-1/0/2021-03-08_23:06:49.json" } }
Menggunakan anotasi posting Lambda untuk mengkonsolidasikan hasil dari pekerja Anda
Secara default Ground Truth menyimpan respons pekerja yang belum diproses di Amazon S3. Untuk memiliki kontrol yang lebih halus atas cara penanganan respons, Anda dapat menentukan fungsi Lambda pasca-anotasi. Misalnya, fungsi Lambda pasca-anotasi dapat digunakan untuk mengkonsolidasikan anotasi jika beberapa pekerja telah memberi label objek data yang sama. Untuk mempelajari selengkapnya tentang membuat fungsi Lambda pasca-anotasi, lihat. Lambda pasca-anotasi
Jika Anda ingin menggunakan fungsi Lambda pasca-anotasi, itu harus ditentukan sebagai bagian dari permintaan. AnnotationConsolidationConfigCreateLabelingJob
Untuk mempelajari lebih lanjut tentang cara kerja konsolidasi anotasi, lihat. Konsolidasi anotasi
