Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Lihat item FAQ berikut untuk jawaban atas pertanyaan umum tentang SageMaker AI Inference Hosting.
Hosting Umum
Item FAQ berikut menjawab pertanyaan umum umum untuk Inferensi SageMaker AI.
J: Setelah Anda membuat dan melatih model, Amazon SageMaker AI menyediakan empat opsi untuk menerapkannya sehingga Anda dapat mulai membuat prediksi. Inferensi Real-Time cocok untuk beban kerja dengan persyaratan latensi milidetik, ukuran muatan hingga 6 MB, dan waktu pemrosesan hingga 60 detik. Batch Transform sangat ideal untuk prediksi offline pada batch besar data yang tersedia di muka. Inferensi Asinkron dirancang untuk beban kerja yang tidak memiliki persyaratan latensi sub-detik, ukuran muatan hingga 1 GB, dan waktu pemrosesan hingga 15 menit. Dengan Inferensi Tanpa Server, Anda dapat dengan cepat menerapkan model pembelajaran mesin untuk inferensi tanpa harus mengonfigurasi atau mengelola infrastruktur yang mendasarinya, dan Anda hanya membayar untuk kapasitas komputasi yang digunakan untuk memproses permintaan inferensi, yang ideal untuk beban kerja intermiten.
J: Diagram berikut dapat membantu Anda memilih opsi penerapan model SageMaker AI Hosting.
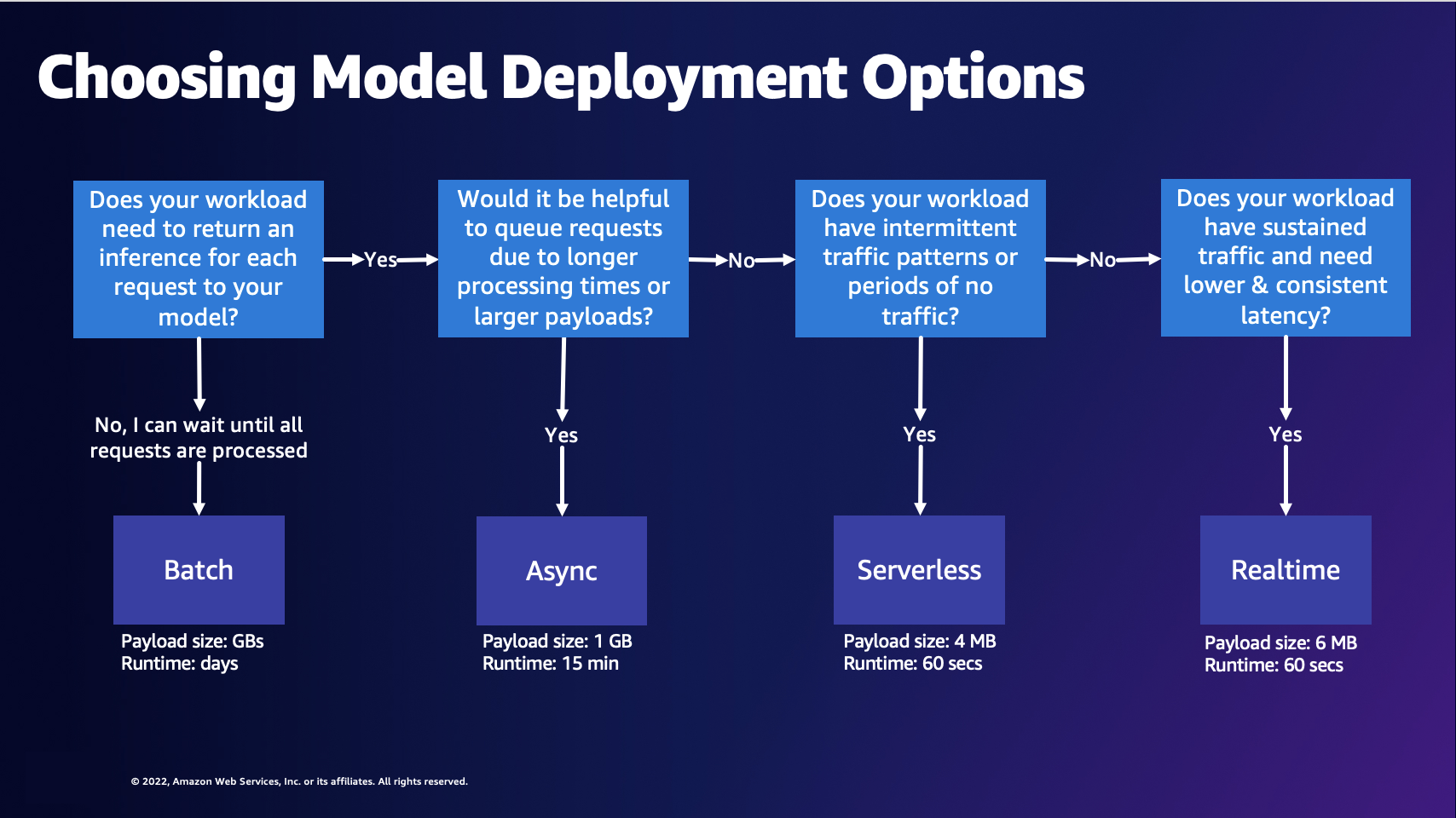
Diagram sebelumnya memandu Anda melalui proses keputusan berikut. Jika Anda ingin memproses permintaan dalam batch, Anda mungkin ingin memilih Batch Transform. Jika tidak, jika Anda ingin menerima inferensi untuk setiap permintaan ke model Anda, Anda mungkin ingin memilih Inferensi Asinkron, Inferensi Tanpa Server, atau Inferensi Waktu Nyata. Anda dapat memilih Inferensi Asinkron jika Anda memiliki waktu pemrosesan yang lama atau muatan besar dan ingin mengantri permintaan. Anda dapat memilih Inferensi Tanpa Server jika beban kerja Anda memiliki lalu lintas yang tidak dapat diprediksi atau terputus-putus. Anda dapat memilih Inferensi Real-Time jika Anda memiliki lalu lintas yang berkelanjutan dan membutuhkan latensi yang lebih rendah dan konsisten untuk permintaan Anda.
J: Diagram berikut dapat membantu Anda memilih opsi penerapan model SageMaker AI Hosting.
Diagram sebelumnya memandu Anda melalui proses keputusan berikut. Jika Anda ingin memproses permintaan dalam batch, Anda mungkin ingin memilih Batch Transform. Jika tidak, jika Anda ingin menerima inferensi untuk setiap permintaan ke model Anda, Anda mungkin ingin memilih Inferensi Asinkron, Inferensi Tanpa Server, atau Inferensi Waktu Nyata. Anda dapat memilih Inferensi Asinkron jika Anda memiliki waktu pemrosesan yang lama atau muatan besar dan ingin mengantri permintaan. Anda dapat memilih Inferensi Tanpa Server jika beban kerja Anda memiliki lalu lintas yang tidak dapat diprediksi atau terputus-putus. Anda dapat memilih Inferensi Real-Time jika Anda memiliki lalu lintas yang berkelanjutan dan membutuhkan latensi yang lebih rendah dan konsisten untuk permintaan Anda.
J: Untuk mengoptimalkan biaya Anda dengan Inferensi SageMaker AI, Anda harus memilih opsi hosting yang tepat untuk kasus penggunaan Anda. Anda juga dapat menggunakan fitur Inferensi seperti Amazon SageMaker AI Savings Plans
J: Anda harus menggunakan Amazon SageMaker Inference Recommender jika Anda memerlukan rekomendasi untuk konfigurasi endpoint yang tepat untuk meningkatkan kinerja dan mengurangi biaya. Sebelumnya, ilmuwan data yang ingin menerapkan model mereka harus menjalankan tolok ukur manual untuk memilih konfigurasi titik akhir yang tepat. Pertama, mereka harus memilih jenis instans pembelajaran mesin yang tepat dari lebih dari 70 jenis instans yang tersedia berdasarkan kebutuhan sumber daya model dan muatan sampel mereka, dan kemudian mengoptimalkan model untuk memperhitungkan perangkat keras yang berbeda. Kemudian, mereka harus melakukan uji beban ekstensif untuk memvalidasi bahwa persyaratan latensi dan throughput terpenuhi dan biayanya rendah. Inference Recommender menghilangkan kompleksitas ini dengan membantu Anda melakukan hal berikut:
-
Mulailah dalam hitungan menit dengan rekomendasi instans.
-
Lakukan pengujian beban di seluruh jenis instans untuk mendapatkan rekomendasi tentang konfigurasi titik akhir Anda dalam beberapa jam.
-
Secara otomatis menyetel parameter server kontainer dan model serta melakukan pengoptimalan model untuk jenis instance tertentu.
A: Titik akhir SageMaker AI adalah titik akhir HTTP REST yang menggunakan server web kontainer, yang mencakup server model. Wadah ini bertanggung jawab untuk memuat dan melayani permintaan untuk model pembelajaran mesin. Mereka mengimplementasikan server web yang merespons /invocations dan /ping pada port 8080.
Server model umum termasuk TensorFlow Serving, TorchServe dan Multi Model Server. SageMaker Wadah kerangka kerja AI memiliki server model bawaan ini.
J: Segala sesuatu dalam Inferensi SageMaker AI dikemas. SageMaker AI menyediakan kontainer terkelola untuk kerangka kerja populer seperti TensorFlow, SKlearn, dan HuggingFace. Untuk daftar lengkap yang diperbarui dari gambar-gambar tersebut, lihat Gambar yang Tersedia
Terkadang ada kerangka kerja khusus yang mungkin Anda perlukan untuk membangun wadah. Pendekatan ini dikenal sebagai Bring Your Own Container atau BYOC. Dengan pendekatan BYOC, Anda memberikan gambar Docker untuk menyiapkan kerangka kerja atau pustaka Anda. Kemudian, Anda mendorong gambar ke Amazon Elastic Container Registry (Amazon ECR) sehingga Anda dapat menggunakan gambar dengan AI. SageMaker Untuk contoh pendekatan BYOC, lihat Overivew of Containers
Atau, alih-alih membangun gambar dari awal, Anda dapat memperluas wadah. Anda dapat mengambil salah satu gambar dasar yang disediakan SageMaker AI dan menambahkan dependensi Anda di atasnya di Dockerfile Anda.
A: SageMaker AI menawarkan kapasitas untuk membawa model kerangka kerja terlatih Anda sendiri yang telah Anda latih di luar SageMaker AI dan menerapkannya pada salah satu opsi hosting SageMaker AI.
SageMaker AI mengharuskan Anda untuk mengemas model dalam model.tar.gz file dan memiliki struktur direktori tertentu. Setiap kerangka memiliki struktur modelnya sendiri (lihat pertanyaan berikut misalnya struktur). Untuk informasi selengkapnya, lihat dokumentasi SageMaker Python SDK untuk TensorFlow
Meskipun Anda dapat memilih dari gambar kerangka kerja bawaan seperti TensorFlow, PyTorch, dan MXNet untuk meng-host model terlatih Anda, Anda juga dapat membuat wadah Anda sendiri untuk meng-host model terlatih Anda di titik akhir SageMaker AI. Untuk penelusuran, lihat contoh Notebook Jupyter Membangun wadah algoritme Anda sendiri
A: SageMaker AI mengharuskan artefak model Anda dikompresi dalam .tar.gz file, atau tarball. SageMaker AI secara otomatis mengekstrak .tar.gz file ini ke /opt/ml/model/ direktori di wadah Anda. Tarball tidak boleh berisi symlink atau file unncessary. Jika Anda menggunakan salah satu wadah kerangka kerja, seperti TensorFlow, PyTorch, atau MXNet, wadah mengharapkan struktur TAR Anda menjadi sebagai berikut:
TensorFlow
model.tar.gz/
|--[model_version_number]/
|--variables
|--saved_model.pb
code/
|--inference.py
|--requirements.txtPyTorch
model.tar.gz/
|- model.pth
|- code/
|- inference.py
|- requirements.txt # only for versions 1.3.1 and higherMXNet
model.tar.gz/
|- model-symbol.json
|- model-shapes.json
|- model-0000.params
|- code/
|- inference.py
|- requirements.txt # only for versions 1.6.0 and higherA: ContentType adalah tipe MIME dari data input di badan permintaan (tipe MIME dari data yang Anda kirim ke titik akhir Anda). Server model menggunakan ContentType untuk menentukan apakah dapat menangani jenis yang disediakan atau tidak.
Acceptadalah tipe MIME dari respons inferensi (tipe MIME dari data yang dikembalikan titik akhir Anda). Server model menggunakan Accept tipe untuk menentukan apakah dapat menangani pengembalian tipe yang disediakan atau tidak.
Jenis MIME yang umum termasuktext/csv,application/json, danapplication/jsonlines.
A: SageMaker AI meneruskan permintaan apa pun ke wadah model tanpa modifikasi. Wadah harus berisi logika untuk deserialisasi permintaan. Untuk informasi tentang format yang ditentukan untuk algoritme bawaan, lihat Format Data Umum untuk Inferensi. Jika Anda membangun wadah sendiri atau menggunakan wadah SageMaker AI Framework, Anda dapat menyertakan logika untuk menerima format permintaan pilihan Anda.
Demikian pula, SageMaker AI juga mengembalikan respons tanpa modifikasi, dan kemudian klien harus deserialisasi respons. Dalam hal algoritma bawaan, mereka mengembalikan respons dalam format tertentu. Jika Anda membangun wadah sendiri atau menggunakan wadah SageMaker AI Framework, Anda dapat menyertakan logika untuk mengembalikan respons dalam format yang Anda pilih.
Gunakan panggilan API Invoke Endpoint untuk membuat inferensi terhadap titik akhir Anda.
Saat meneruskan input Anda sebagai payload ke InvokeEndpoint API, Anda harus memberikan jenis data input yang benar yang diharapkan model Anda. Saat meneruskan payload dalam panggilan InvokeEndpoint API, byte permintaan diteruskan langsung ke container model. Misalnya, untuk gambar, Anda dapat menggunakan application/jpeg untukContentType, dan memastikan bahwa model Anda dapat melakukan inferensi pada jenis data ini. Ini berlaku untuk JSON, CSV, video, atau jenis input lain yang mungkin Anda hadapi.
Faktor lain yang perlu dipertimbangkan adalah batas ukuran muatan. Dalam hal titik akhir real-time dan tanpa server, batas payload adalah 6 MB. Anda dapat membagi video Anda menjadi beberapa frame dan memanggil titik akhir dengan setiap frame satu per satu. Atau, jika kasus penggunaan memungkinkan, Anda dapat mengirim seluruh video dalam muatan menggunakan titik akhir asinkron, yang mendukung muatan hingga 1 GB.
Inferensi Waktu Nyata
Item FAQ berikut menjawab pertanyaan umum untuk Inferensi Real-Time SageMaker AI.
J: Anda dapat membuat titik akhir SageMaker AI melalui perkakas yang AWS didukung seperti, SDK SageMaker Python,,, dan. AWS SDKs AWS Management Console AWS CloudFormation AWS Cloud Development Kit (AWS CDK)
Ada tiga entitas kunci dalam pembuatan titik akhir: model SageMaker AI, konfigurasi titik akhir SageMaker AI, dan titik akhir SageMaker AI. Model SageMaker AI menunjuk ke data model dan gambar yang Anda gunakan. Konfigurasi endpoint mendefinisikan varian produksi Anda, yang mungkin mencakup jenis instance dan jumlah instance. Anda kemudian dapat menggunakan panggilan API create_endpoint
J: Tidak, Anda dapat menggunakan berbagai AWS SDKs (lihat Memanggil/Buat untuk tersedia SDKs) atau bahkan memanggil web yang sesuai APIs secara langsung.
A: Titik Akhir Multi-Model adalah opsi Inferensi Waktu Nyata yang SageMaker disediakan AI. Dengan Endpoint Multi-Model, Anda dapat meng-host ribuan model di belakang satu titik akhir. Multi Model Server
A: SageMaker AI Real-Time Inference mendukung berbagai arsitektur penerapan model seperti Multi-Model Endpoint, Multi-Container Endpoint, dan Serial Inference Pipelines.
Multi-Model Endpoints (MME) — MME memungkinkan pelanggan untuk menggunakan 1000 model yang sangat personal dengan cara yang hemat biaya. Semua model dikerahkan pada armada sumber daya bersama. MME bekerja paling baik ketika model memiliki ukuran dan latensi yang sama dan termasuk dalam kerangka kerja ML yang sama. Titik akhir ini ideal ketika Anda tidak perlu memanggil model yang sama setiap saat. Anda dapat memuat model masing-masing secara dinamis ke titik akhir SageMaker AI untuk melayani permintaan Anda.
Multi-Container Endpoints (MCE) — MCE memungkinkan pelanggan untuk menyebarkan 15 kontainer berbeda dengan kerangka kerja dan fungsionalitas yang beragam tanpa cold start sementara hanya menggunakan satu titik akhir. SageMaker Anda dapat langsung memanggil wadah ini. MCE adalah yang terbaik ketika Anda ingin menyimpan semua model dalam memori.
Serial Inference Pipelines (SIP) - Anda dapat menggunakan SIP untuk menyatukan 2-15 kontainer pada satu titik akhir. SIP sebagian besar cocok untuk menggabungkan preprocessing dan inferensi model dalam satu titik akhir dan untuk operasi latensi rendah.
Inferensi Tanpa Server
Item FAQ berikut menjawab pertanyaan umum untuk Inferensi Tanpa SageMaker Server Amazon.
A: Terapkan model dengan Inferensi Tanpa SageMaker Server Amazon adalah opsi penyajian model tanpa server yang dibuat khusus yang membuatnya mudah untuk menerapkan dan menskalakan model ML. Titik akhir Inferensi Tanpa Server secara otomatis memulai sumber daya komputasi dan menskalakannya masuk dan keluar tergantung pada lalu lintas, sehingga Anda tidak perlu memilih jenis instans, menjalankan kapasitas yang disediakan, atau mengelola penskalaan. Anda dapat secara opsional menentukan persyaratan memori untuk titik akhir tanpa server Anda. Anda hanya membayar selama menjalankan kode inferensi dan jumlah data yang diproses, bukan untuk periode idle.
J: Inferensi Tanpa Server menyederhanakan pengalaman pengembang dengan menghilangkan kebutuhan untuk menyediakan kapasitas di muka dan mengelola kebijakan penskalaan. Inferensi Tanpa Server dapat menskalakan secara instan dari puluhan hingga ribuan inferensi dalam hitungan detik berdasarkan pola penggunaan, menjadikannya ideal untuk aplikasi ML dengan lalu lintas intermiten atau tidak dapat diprediksi. Misalnya, layanan chatbot yang digunakan oleh perusahaan pemrosesan penggajian mengalami peningkatan pertanyaan pada akhir bulan sementara lalu lintas terputus-putus selama sisa bulan itu. Penyediaan contoh untuk sebulan penuh dalam skenario seperti itu tidak hemat biaya, karena Anda akhirnya membayar untuk periode idle.
Inferensi Tanpa Server membantu mengatasi jenis kasus penggunaan ini dengan memberi Anda penskalaan otomatis dan cepat di luar kotak tanpa perlu memperkirakan lalu lintas di muka atau mengelola kebijakan penskalaan. Selain itu, Anda hanya membayar untuk waktu komputasi untuk menjalankan kode inferensi Anda dan untuk pemrosesan data, sehingga ideal untuk beban kerja dengan lalu lintas intermiten.
A: Endpoint tanpa server Anda memiliki ukuran RAM minimum 1024 MB (1 GB), dan ukuran RAM maksimum yang dapat Anda pilih adalah 6144 MB (6 GB). Ukuran memori yang dapat Anda pilih adalah 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB, atau 6144 MB. Inferensi Tanpa Server secara otomatis menetapkan sumber daya komputasi sebanding dengan memori yang Anda pilih. Jika Anda memilih ukuran memori yang lebih besar, wadah Anda memiliki akses ke lebih banyak vCPUs.
Pilih ukuran memori endpoint Anda sesuai dengan ukuran model Anda. Umumnya, ukuran memori harus setidaknya sebesar ukuran model Anda. Anda mungkin perlu melakukan benchmark untuk memilih pilihan memori yang tepat untuk model Anda berdasarkan latensi SLAs Anda. Peningkatan ukuran memori memiliki harga yang berbeda; lihat halaman SageMaker harga Amazon
Transformasi Batch
Item FAQ berikut menjawab pertanyaan umum untuk SageMaker AI Batch Transform.
J: Untuk format file tertentu seperti CSV, RecorDio TFRecord dan SageMaker , AI dapat membagi data Anda menjadi batch mini rekaman tunggal atau multi-rekaman dan mengirimkannya sebagai muatan ke wadah model Anda. Ketika nilainyaMultiRecord, SageMaker AI mengirimkan jumlah catatan maksimum di setiap permintaan, hingga MaxPayloadInMB batasnya. BatchStrategy Ketika nilainyaSingleRecord, SageMaker AI mengirimkan catatan individual di setiap permintaan. BatchStrategy
J: Batas waktu maksimum untuk Batch Transform adalah 3600 detik. Ukuran muatan maksimum untuk catatan (per batch mini) adalah 100 MB.
J: Jika Anda menggunakan CreateTransformJob API, Anda dapat mengurangi waktu yang diperlukan untuk menyelesaikan pekerjaan transformasi batch dengan menggunakan nilai optimal untuk parameter sepertiMaxPayloadInMB,MaxConcurrentTransforms, atauBatchStrategy. Nilai ideal untuk MaxConcurrentTransforms sama dengan jumlah pekerja komputasi dalam pekerjaan transformasi batch. Jika Anda menggunakan konsol SageMaker AI, Anda dapat menentukan nilai parameter optimal ini di bagian Konfigurasi tambahan pada halaman konfigurasi pekerjaan transformasi Batch. SageMaker AI secara otomatis menemukan pengaturan parameter optimal untuk algoritme bawaan. Untuk algoritme kustom, berikan nilai-nilai ini melalui titik akhir parameter eksekusi.
A: Batch Transform mendukung CSV dan JSON.
Inferensi Asinkron
Item FAQ berikut menjawab pertanyaan umum umum untuk Inferensi Asinkron SageMaker AI.
A: Inferensi Asinkron mengantri permintaan yang masuk dan memprosesnya secara asinkron. Opsi ini sangat ideal untuk permintaan dengan ukuran muatan besar atau waktu pemrosesan yang lama yang perlu diproses saat tiba. Secara opsional, Anda dapat mengonfigurasi pengaturan auto-scaling untuk menurunkan jumlah instans menjadi nol saat tidak memproses permintaan secara aktif.
J: Amazon SageMaker AI mendukung penskalaan otomatis (penskalaan otomatis) titik akhir asinkron Anda. Penskalaan otomatis secara dinamis menyesuaikan jumlah instance yang disediakan untuk model sebagai respons terhadap perubahan beban kerja Anda. Tidak seperti model host lainnya yang didukung SageMaker AI, dengan Asynchronous Inference Anda juga dapat menurunkan instans titik akhir asinkron Anda menjadi nol. Permintaan yang diterima ketika tidak ada instance akan diantrian untuk diproses setelah titik akhir meningkat. Untuk informasi selengkapnya, lihat Skala otomatis titik akhir asinkron.
Inferensi SageMaker Tanpa Server Amazon juga secara otomatis menurunkan skala ke nol. Anda tidak akan melihat ini karena SageMaker AI mengelola penskalaan titik akhir tanpa server Anda, tetapi jika Anda tidak mengalami lalu lintas apa pun, infrastruktur yang sama berlaku.
