Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Otomatiskan pelabelan data
Jika Anda memilih, Amazon SageMaker Ground Truth dapat menggunakan pembelajaran aktif untuk mengotomatiskan pelabelan data input Anda untuk jenis tugas bawaan tertentu. Pembelajaran aktif adalah teknik pembelajaran mesin yang mengidentifikasi data yang harus diberi label oleh pekerja Anda. Dalam Ground Truth, fungsi ini disebut pelabelan data otomatis. Pelabelan data otomatis membantu mengurangi biaya dan waktu yang diperlukan untuk memberi label pada kumpulan data Anda dibandingkan dengan hanya menggunakan manusia. Saat Anda menggunakan pelabelan otomatis, Anda dikenakan biaya SageMaker pelatihan dan inferensi.
Kami merekomendasikan penggunaan pelabelan data otomatis pada kumpulan data besar karena jaringan saraf yang digunakan dengan pembelajaran aktif memerlukan sejumlah besar data untuk setiap kumpulan data baru. Biasanya, saat Anda memberikan lebih banyak data, potensi prediksi akurasi tinggi naik. Data hanya akan diberi label otomatis jika jaringan saraf yang digunakan dalam model pelabelan otomatis dapat mencapai tingkat akurasi yang cukup tinggi. Oleh karena itu, dengan kumpulan data yang lebih besar, ada lebih banyak potensi untuk memberi label data secara otomatis karena jaringan saraf dapat mencapai akurasi yang cukup tinggi untuk pelabelan otomatis. Pelabelan data otomatis paling tepat ketika Anda memiliki ribuan objek data. Jumlah minimum objek yang diizinkan untuk pelabelan data otomatis adalah 1.250, tetapi kami sangat menyarankan untuk menyediakan minimal 5.000 objek.
Pelabelan data otomatis hanya tersedia untuk tipe tugas bawaan Ground Truth berikut:
Pekerjaan pelabelan streaming tidak mendukung pelabelan data otomatis.
Untuk mempelajari cara membuat alur kerja pembelajaran aktif kustom menggunakan model Anda sendiri, lihatSiapkan alur kerja pembelajaran aktif dengan model Anda sendiri.
Kuota data input berlaku untuk pekerjaan pelabelan data otomatis. Lihat Kuota Data Masukan untuk informasi tentang ukuran set data, ukuran data input, dan batas resolusi.
catatan
Sebelum Anda menggunakan model pelabelan otomatis dalam produksi, Anda perlu menyempurnakan atau mengujinya, atau keduanya. Anda dapat menyempurnakan model (atau membuat dan menyetel model lain yang diawasi pilihan Anda) pada kumpulan data yang dihasilkan oleh pekerjaan pelabelan Anda untuk mengoptimalkan arsitektur dan hiperparameter model. Jika Anda memutuskan untuk menggunakan model untuk inferensi tanpa menyempurnakannya, kami sangat menyarankan untuk memastikan bahwa Anda mengevaluasi keakuratannya pada subset representatif (misalnya, dipilih secara acak) dari kumpulan data yang diberi label Ground Truth dan sesuai dengan harapan Anda.
Cara kerjanya
Anda mengaktifkan pelabelan data otomatis saat membuat pekerjaan pelabelan. Beginilah cara kerjanya:
-
Ketika Ground Truth memulai pekerjaan pelabelan data otomatis, ia memilih sampel acak objek data input dan mengirimkannya ke pekerja manusia. Jika lebih dari 10% objek data ini gagal, pekerjaan pelabelan akan gagal. Jika pekerjaan pelabelan gagal, selain meninjau pesan kesalahan apa pun yang dikembalikan Ground Truth, periksa apakah data input Anda ditampilkan dengan benar di UI pekerja, instruksi jelas, dan Anda telah memberi pekerja cukup waktu untuk menyelesaikan tugas.
-
Ketika data berlabel dikembalikan, itu digunakan untuk membuat set pelatihan dan set validasi. Ground Truth menggunakan kumpulan data ini untuk melatih dan memvalidasi model yang digunakan untuk pelabelan otomatis.
-
Ground Truth menjalankan tugas transformasi batch, menggunakan model yang divalidasi untuk inferensi pada data validasi. Inferensi Batch menghasilkan skor kepercayaan dan metrik kualitas untuk setiap objek dalam data validasi.
-
Komponen pelabelan otomatis akan menggunakan metrik kualitas dan skor kepercayaan ini untuk menciptakan ambang skor kepercayaan yang memastikan label kualitas.
-
Ground Truth menjalankan tugas transformasi batch pada data yang tidak berlabel dalam kumpulan data, menggunakan model tervalidasi yang sama untuk inferensi. Ini menghasilkan skor kepercayaan untuk setiap objek.
-
Komponen pelabelan otomatis Ground Truth menentukan apakah skor kepercayaan yang dihasilkan pada langkah 5 untuk setiap objek memenuhi ambang batas yang diperlukan yang ditentukan pada langkah 4. Jika skor kepercayaan memenuhi ambang batas, kualitas pelabelan otomatis yang diharapkan melebihi tingkat akurasi yang diminta dan objek tersebut dianggap berlabel otomatis.
-
Langkah 6 menghasilkan kumpulan data yang tidak berlabel dengan skor kepercayaan. Ground Truth memilih titik data dengan skor kepercayaan rendah dari kumpulan data ini dan mengirimkannya ke pekerja manusia.
-
Ground Truth menggunakan data berlabel manusia yang ada dan data berlabel tambahan dari pekerja manusia ini untuk memperbarui model.
-
Proses ini diulang sampai dataset sepenuhnya diberi label atau sampai kondisi penghentian lain terpenuhi. Misalnya, pelabelan otomatis berhenti jika anggaran anotasi manusia Anda tercapai.
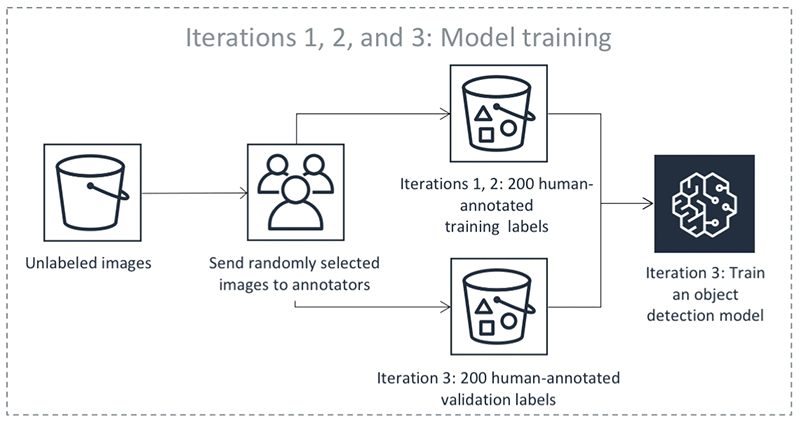
Langkah-langkah sebelumnya terjadi dalam iterasi. Pilih setiap tab dalam tabel berikut untuk melihat contoh proses yang terjadi di setiap iterasi untuk pekerjaan pelabelan otomatis deteksi objek. Jumlah objek data yang digunakan dalam langkah tertentu dalam gambar ini (misalnya, 200) khusus untuk contoh ini. Jika ada kurang dari 5.000 objek untuk diberi label, ukuran set validasi adalah 20% dari seluruh kumpulan data. Jika ada lebih dari 5.000 objek dalam kumpulan data input Anda, ukuran set validasi adalah 10% dari seluruh kumpulan data. Anda dapat mengontrol jumlah label manusia yang dikumpulkan per iterasi pembelajaran aktif dengan mengubah nilai MaxConcurrentTaskCountsaat menggunakan API operasi CreateLabelingJob. Nilai ini disetel ke 1.000 saat Anda membuat pekerjaan pelabelan menggunakan konsol. Dalam alur pembelajaran aktif yang diilustrasikan di bawah tab Pembelajaran Aktif, nilai ini diatur ke 200.


Akurasi label otomatis
Definisi akurasi tergantung pada jenis tugas bawaan yang Anda gunakan dengan pelabelan otomatis. Untuk semua jenis tugas, persyaratan akurasi ini ditentukan sebelumnya oleh Ground Truth dan tidak dapat dikonfigurasi secara manual.
-
Untuk klasifikasi gambar dan klasifikasi teks, Ground Truth menggunakan logika untuk menemukan tingkat kepercayaan prediksi label yang sesuai dengan setidaknya 95% akurasi label. Ini berarti Ground Truth mengharapkan keakuratan label otomatis setidaknya 95% jika dibandingkan dengan label yang akan diberikan oleh pelabel manusia untuk contoh-contoh tersebut.
-
Untuk kotak pembatas, rata-rata yang diharapkan Intersection Over Union (IoU)
dari gambar berlabel otomatis adalah 0,6. Untuk menemukan mean IoU, Ground Truth menghitung rata-rata IoU dari semua kotak yang diprediksi dan terlewat pada gambar untuk setiap kelas, dan kemudian rata-rata nilai-nilai ini di seluruh kelas. -
Untuk segmentasi semantik, rata-rata IoU yang diharapkan dari gambar berlabel otomatis adalah 0,7. Untuk menemukan mean IoU, Ground Truth mengambil mean dari nilai IoU dari semua kelas dalam gambar (tidak termasuk latar belakang).
Pada setiap iterasi Pembelajaran Aktif (langkah 3-6 dalam daftar di atas), ambang kepercayaan ditemukan menggunakan set validasi beranotasi manusia sehingga akurasi yang diharapkan dari objek berlabel otomatis memenuhi persyaratan akurasi tertentu yang telah ditentukan sebelumnya.
Buat pekerjaan pelabelan data otomatis (konsol)
Untuk membuat pekerjaan pelabelan yang menggunakan pelabelan otomatis di SageMaker konsol, gunakan prosedur berikut.
Untuk membuat pekerjaan pelabelan data otomatis (konsol)
-
Buka bagian pekerjaan Ground Truth Labeling di SageMaker konsol:https://console.aws.amazon.com/sagemaker/groundtruth
. -
Menggunakan Membuat Job Pelabelan (Konsol) sebagai panduan, lengkapi bagian Job overview dan Task type. Perhatikan bahwa pelabelan otomatis tidak didukung untuk jenis tugas khusus.
-
Di bawah Pekerja, pilih jenis tenaga kerja Anda.
-
Di bagian yang sama, pilih Aktifkan pelabelan data otomatis.
-
Menggunakan Konfigurasikan Alat Kotak Bounding sebagai panduan, buat instruksi pekerja di bagian
Task Typealat pelabelan. Misalnya, jika Anda memilih segmentasi Semantik sebagai jenis pekerjaan pelabelan Anda, bagian ini disebut Alat pelabelan segmentasi semantik. -
Untuk melihat pratinjau instruksi dan dasbor pekerja Anda, pilih Pratinjau.
-
Pilih Buat. Ini menciptakan dan memulai pekerjaan pelabelan Anda dan proses pelabelan otomatis.
Anda dapat melihat pekerjaan pelabelan Anda muncul di bagian Pekerjaan pelabelan di konsol. SageMaker Data keluaran Anda muncul di bucket Amazon S3 yang Anda tentukan saat membuat pekerjaan pelabelan. Untuk informasi selengkapnya tentang format dan struktur file data keluaran pekerjaan pelabelan Anda, lihatPelabelan data keluaran pekerjaan.
Buat pekerjaan pelabelan data otomatis () API
Untuk membuat pekerjaan pelabelan data otomatis menggunakan SageMaker API, gunakan LabelingJobAlgorithmsConfigparameter CreateLabelingJoboperasi. Untuk mempelajari cara memulai pekerjaan pelabelan menggunakan CreateLabelingJob operasi, lihatMembuat Job Pelabelan (API).
Tentukan Amazon Resource Name (ARN) dari algoritma yang Anda gunakan untuk pelabelan data otomatis dalam LabelingJobAlgorithmSpecificationArnparameter. Pilih salah satu dari empat algoritma bawaan Ground Truth yang didukung dengan pelabelan otomatis:
Ketika pekerjaan pelabelan data otomatis selesai, Ground Truth mengembalikan model ARN yang digunakan untuk pekerjaan pelabelan data otomatis. Gunakan model ini sebagai model awal untuk jenis pekerjaan pelabelan otomatis serupa dengan menyediakanARN, dalam format string, dalam parameter. InitialActiveLearningModelArn Untuk mengambil modelARN, gunakan perintah AWS Command Line Interface (AWS CLI) yang mirip dengan berikut ini.
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
Untuk mengenkripsi data pada volume penyimpanan yang dilampirkan ke instance komputasi ML yang digunakan dalam pelabelan otomatis, sertakan kunci AWS Key Management Service (AWS KMS) dalam parameter. VolumeKmsKeyId Untuk informasi tentang AWS KMS kunci, lihat Apa itu Layanan Manajemen AWS Kunci? dalam Panduan Pengembang Layanan Manajemen AWS Kunci.
Untuk contoh yang menggunakan CreateLabelingJoboperasi untuk membuat pekerjaan pelabelan data otomatis, lihat contoh object_detection_tutorial di bagian Contoh, Pekerjaan Pelabelan SageMaker Ground Truth pada instance notebook. SageMaker Untuk mempelajari cara membuat dan membuka instance notebook, lihatMembuat instance SageMaker notebook Amazon. Untuk mempelajari cara mengakses SageMaker contoh buku catatan, lihatAkses contoh notebook.
EC2Instans Amazon diperlukan untuk pelabelan data otomatis
Tabel berikut mencantumkan instans Amazon Elastic Compute Cloud (AmazonEC2) yang Anda perlukan untuk menjalankan pelabelan data otomatis untuk tugas pelatihan dan inferensi batch.
| Jenis Pekerjaan Pelabelan Data Otomatis | Jenis Instans Pelatihan | Jenis Inferensi Inferensi |
|---|---|---|
|
Klasifikasi gambar |
ml.p3.2xbesar* |
ml.c5.xlarge |
|
Deteksi objek (kotak pembatas) |
ml.p3.2xbesar* |
ml.c5.4xlarge |
|
Klasifikasi teks |
ml.c5.2xlarge |
db.m4.xlarge |
|
Segmentasi semantik |
ml.p3.2xbesar* |
ml.p3.2xbesar* |
* Di Wilayah Asia Pasifik (Mumbai) (ap-south-1) gunakan ml.p2.8xlarge sebagai gantinya.
Ground Truth mengelola instance yang Anda gunakan untuk pekerjaan pelabelan data otomatis. Ini membuat, mengonfigurasi, dan mengakhiri instance sesuai kebutuhan untuk melakukan pekerjaan Anda. Instans ini tidak muncul di dasbor EC2 instans Amazon Anda.
Siapkan alur kerja pembelajaran aktif dengan model Anda sendiri
Anda dapat membuat alur kerja pembelajaran aktif dengan algoritme Anda sendiri untuk menjalankan pelatihan dan kesimpulan dalam alur kerja tersebut untuk memberi label otomatis pada data Anda. Notebook bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb menunjukkan ini menggunakan algoritma bawaan,. SageMaker BlazingText Notebook ini menyediakan AWS CloudFormation tumpukan yang dapat Anda gunakan untuk menjalankan alur kerja ini menggunakan AWS Step Functions. Anda dapat menemukan notebook dan file pendukung di GitHub repositori
Anda juga dapat menemukan buku catatan ini di repositori SageMaker Contoh. Lihat Menggunakan Contoh Buku Catatan untuk mempelajari cara menemukan buku catatan SageMaker contoh Amazon.
