Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Terminologi dan konsep Amazon Kinesis Data Streams
Sebelum Anda memulai Amazon Kinesis Data Streams, pelajari tentang arsitektur dan terminologinya.
Topik
Tinjau arsitektur tingkat tinggi Kinesis Data Streams
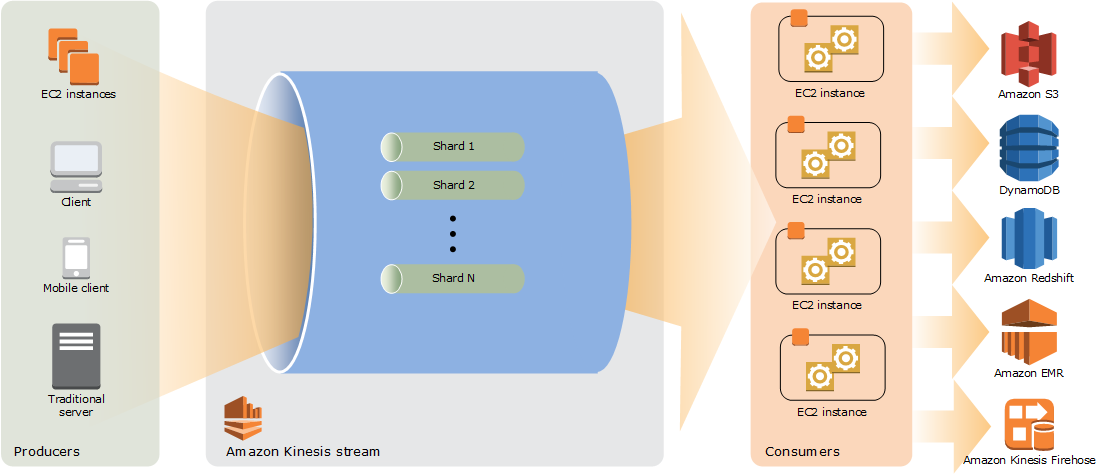
Diagram berikut menggambarkan arsitektur tingkat tinggi Kinesis Data Streams. Para produsen terus mendorong data ke Kinesis Data Streams, dan konsumen memproses data secara real time. Konsumen (seperti aplikasi khusus yang berjalan di Amazon EC2 atau aliran pengiriman Amazon Data Firehose) dapat menyimpan hasilnya menggunakan AWS layanan seperti Amazon DynamoDB, Amazon Redshift, atau Amazon S3.
Menjadi akrab dengan terminologi Kinesis Data Streams
Aliran Data Kinesis
Aliran data Kinesis adalah sekumpulan pecahan. Setiap pecahan memiliki urutan catatan data. Setiap catatan data memiliki nomor urut yang ditetapkan oleh Kinesis Data Streams.
Rekam Data
Catatan data adalah unit data yang disimpan dalam aliran data Kinesis. Catatan data terdiri dari nomor urut, kunci partisi, dan gumpalan data, yang merupakan urutan byte yang tidak dapat diubah. Kinesis Data Streams tidak memeriksa, menafsirkan, atau mengubah data dalam gumpalan dengan cara apa pun. Gumpalan data bisa mencapai 1 MB.
Mode Kapasitas
Mode kapasitas aliran data menentukan bagaimana kapasitas dikelola dan bagaimana Anda dikenakan biaya untuk penggunaan aliran data Anda. Saat ini, di Kinesis Data Streams, Anda dapat memilih antara mode sesuai permintaan dan mode yang disediakan untuk aliran data Anda. Untuk informasi selengkapnya, lihat Pilih mode yang tepat untuk streaming.
Dengan mode on-demand, Kinesis Data Streams secara otomatis mengelola pecahan untuk menyediakan throughput yang diperlukan. Anda hanya dikenakan biaya untuk throughput aktual yang Anda gunakan dan Kinesis Data Streams secara otomatis mengakomodasi kebutuhan throughput beban kerja Anda saat mereka naik atau turun. Untuk informasi selengkapnya, lihat Fitur mode Standar sesuai permintaan dan kasus penggunaan.
Dengan mode yang disediakan, Anda harus menentukan jumlah pecahan untuk aliran data. Kapasitas total aliran data adalah jumlah dari kapasitas pecahannya. Anda dapat menambah atau mengurangi jumlah pecahan dalam aliran data sesuai kebutuhan dan Anda dikenakan biaya untuk jumlah pecahan dengan tarif per jam. Untuk informasi selengkapnya, lihat Fitur mode yang disediakan dan kasus penggunaan.
Periode Retensi
Periode retensi adalah lamanya waktu rekaman data dapat diakses setelah ditambahkan ke aliran. Periode retensi stream diatur ke default 24 jam setelah pembuatan. Anda dapat meningkatkan periode retensi hingga 8760 jam (365 hari) menggunakan IncreaseStreamRetentionPeriodoperasi, dan mengurangi periode retensi hingga minimal 24 jam menggunakan DecreaseStreamRetentionPeriodoperasi. Biaya tambahan berlaku untuk streaming dengan periode retensi yang ditetapkan lebih dari 24 jam. Untuk informasi selengkapnya, lihat Harga Amazon Kinesis Data Streams
Produser
Produsen memasukkan catatan ke Amazon Kinesis Data Streams. Misalnya, server web yang mengirim data log ke aliran adalah produser.
Konsumen
Konsumen mendapatkan catatan dari Amazon Kinesis Data Streams dan memprosesnya. Konsumen ini dikenal sebagaiAplikasi Amazon Kinesis Data Streams.
Aplikasi Amazon Kinesis Data Streams
Aplikasi Amazon Kinesis Data Streams adalah konsumen aliran yang biasanya berjalan pada armada instans EC2.
Ada dua jenis konsumen yang dapat Anda kembangkan: konsumen fan-out bersama dan konsumen fan-out yang ditingkatkan. Untuk mempelajari tentang perbedaan di antara mereka, dan untuk melihat bagaimana Anda dapat membuat setiap jenis konsumen, lihatBaca data dari Amazon Kinesis Data Streams.
Output dari aplikasi Kinesis Data Streams dapat menjadi masukan untuk aliran lain, memungkinkan Anda untuk membuat topologi kompleks yang memproses data secara real time. Aplikasi juga dapat mengirim data ke berbagai AWS layanan lain. Mungkin ada beberapa aplikasi untuk satu aliran, dan setiap aplikasi dapat mengkonsumsi data dari aliran secara independen dan bersamaan.
Shard
Shard adalah urutan catatan data yang diidentifikasi secara unik dalam aliran. Aliran terdiri dari satu atau lebih pecahan, yang masing-masing menyediakan unit kapasitas tetap. Setiap pecahan dapat mendukung hingga 5 transaksi per detik untuk pembacaan, hingga total kecepatan baca data maksimum 2 MB per detik dan hingga 1.000 catatan per detik untuk penulisan, hingga total kecepatan penulisan data maksimum 1 MB per detik (termasuk kunci partisi). Kapasitas data aliran Anda adalah fungsi dari jumlah pecahan yang Anda tentukan untuk aliran. Kapasitas total aliran adalah jumlah dari kapasitas pecahannya.
Jika kecepatan data Anda meningkat, Anda dapat menambah atau mengurangi jumlah pecahan yang dialokasikan ke aliran Anda. Untuk informasi selengkapnya, lihat Reshard aliran.
Kunci partisi
Kunci partisi digunakan untuk mengelompokkan data dengan pecahan dalam aliran. Kinesis Data Streams memisahkan catatan data milik aliran menjadi beberapa pecahan. Ini menggunakan kunci partisi yang terkait dengan setiap catatan data untuk menentukan pecahan mana yang dimiliki oleh catatan data tertentu. Tombol partisi adalah string Unicode, dengan batas panjang maksimum 256 karakter untuk setiap tombol. Fungsi hash MD5 digunakan untuk memetakan kunci partisi ke nilai integer 128-bit dan untuk memetakan catatan data terkait ke pecahan menggunakan rentang kunci hash dari pecahan. Ketika sebuah aplikasi menempatkan data ke dalam aliran, itu harus menentukan kunci partisi.
Nomor Urutan
Setiap catatan data memiliki nomor urut yang unik per kunci partisi dalam pecahannya. Kinesis Data Streams menetapkan nomor urut setelah Anda menulis ke aliran dengan atau. client.putRecords client.putRecord Nomor urutan untuk kunci partisi yang sama umumnya meningkat dari waktu ke waktu. Semakin lama periode waktu antara permintaan tulis, semakin besar nomor urut menjadi.
catatan
Nomor urutan tidak dapat digunakan sebagai indeks untuk kumpulan data dalam aliran yang sama. Untuk memisahkan kumpulan data secara logis, gunakan kunci partisi atau buat aliran terpisah untuk setiap kumpulan data.
Perpustakaan Klien Kinesis
Kinesis Client Library dikompilasi ke dalam aplikasi Anda untuk mengaktifkan konsumsi data yang toleran terhadap kesalahan dari aliran. Kinesis Client Library memastikan bahwa untuk setiap pecahan ada prosesor rekaman yang menjalankan dan memproses pecahan itu. Perpustakaan juga menyederhanakan membaca data dari aliran. Perpustakaan Klien Kinesis menggunakan tabel Amazon DynamoDB untuk menyimpan metadata yang terkait dengan konsumsi data. Ini menciptakan tiga tabel per aplikasi yang memproses data. Untuk informasi selengkapnya, lihat Gunakan Perpustakaan Klien Kinesis.
Nama Aplikasi
Nama aplikasi Amazon Kinesis Data Streams mengidentifikasi aplikasi. Setiap aplikasi Anda harus memiliki nama unik yang dicakup ke AWS akun dan Wilayah yang digunakan oleh aplikasi. Nama ini digunakan sebagai nama untuk tabel kontrol di Amazon DynamoDB dan namespace untuk metrik Amazon. CloudWatch
Server-Side Enkripsi
Amazon Kinesis Data Streams dapat secara otomatis mengenkripsi data sensitif saat produsen memasukkannya ke dalam aliran. Kinesis Data AWS KMSStreams menggunakan kunci master untuk enkripsi. Untuk informasi selengkapnya, lihat Perlindungan data di Amazon Kinesis Data Streams.
catatan
Untuk membaca dari atau menulis ke aliran terenkripsi, produsen dan aplikasi konsumen harus memiliki izin untuk mengakses kunci master. Untuk informasi tentang pemberian izin kepada aplikasi produsen dan konsumen, lihat. Izin untuk menggunakan kunci KMS buatan pengguna
catatan
Menggunakan enkripsi sisi server menimbulkan biaya AWS Key Management Service ().AWS KMS Untuk informasi selengkapnya, lihat Harga Layanan Manajemen AWS Utama
