Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
REL10-BP01 Melakukan deployment beban kerja ke beberapa lokasi
Distribusikan sumber daya dan data beban kerja ke beberapa Zona Ketersediaan atau, jika diperlukan, ke beberapa Wilayah AWS.
Prinsip dasar untuk desain layanan di AWS adalah untuk menghindari titik kegagalan tunggal, termasuk infrastruktur fisik yang mendasarinya. AWS menyediakan sumber daya dan layanan komputasi cloud secara global di berbagai lokasi geografis yang disebut Wilayah. Setiap Wilayah berdiri sendiri secara fisik dan logis, dan terdiri dari tiga Zona Ketersediaan (AZ) atau lebih. Zona Ketersediaan terletak berdekatan secara geografis, tetapi terpisah dan terisolasi secara fisik. Ketika Anda mendistribusikan beban kerja Anda di beberapa Zona Ketersediaan dan Wilayah, Anda mengurangi risiko ancaman seperti kebakaran, banjir, bencana terkait cuaca, gempa bumi, dan kesalahan manusia.
Buat strategi lokasi untuk memastikan ketersediaan tinggi yang sesuai dengan beban kerja Anda.
Hasil yang diinginkan: Beban kerja produksi didistribusikan di beberapa Zona Ketersediaan (AZ) atau Wilayah untuk mencapai toleransi kesalahan dan ketersediaan tinggi.
Anti-pola umum:
-
Anda hanya menempatkan beban kerja produksi di satu Zona Ketersediaan.
-
Anda mengimplementasikan arsitektur multi-Wilayah ketika arsitektur multi-AZ sudah dapat memenuhi persyaratan bisnis.
-
Deployment atau data Anda tidak lagi sinkron, sehingga terjadi penyimpangan konfigurasi atau data yang tidak direplikasi secara memadai.
-
Anda tidak memperhitungkan dependensi antar-komponen aplikasi jika ketahanan dan persyaratan multi-lokasi berbeda di antara komponen-komponen tersebut.
Manfaat menjalankan praktik terbaik ini:
-
Beban kerja Anda lebih tahan terhadap insiden, seperti pemadaman listrik atau kegagalan kontrol lingkungan, bencana alam, kegagalan layanan hulu, atau masalah jaringan yang berdampak pada AZ atau seluruh Wilayah.
-
Anda dapat mengakses inventaris instans Amazon EC2 yang lebih luas dan mengurangi kemungkinan InsufficientCapacityExceptions (ICE) saat meluncurkan jenis instans EC2 tertentu.
Tingkat risiko yang terjadi jika praktik terbaik ini tidak diterapkan: Tinggi
Panduan implementasi
Lakukan deployment dan operasikan semua beban kerja produksi di setidaknya dua Zona Ketersediaan (AZ) di sebuah Wilayah.
Menggunakan beberapa Zona Ketersediaan
Zona Ketersediaan adalah lokasi hosting sumber daya yang secara fisik terpisah satu sama lain untuk menghindari kegagalan yang berkorelasi akibat risiko seperti kebakaran, banjir, dan tornado. Setiap Zona Ketersediaan memiliki infrastruktur fisik independen, termasuk sambungan listrik lokal, sumber listrik cadangan, sistem mekanis, dan koneksi jaringan. Desain infrastruktur yang independen ini membatasi dampak kegagalan di salah satu komponen ini hanya pada Zona Ketersediaan yang terkena dampak. Misalnya, jika insiden di seluruh AZ membuat instans EC2 tidak tersedia di Zona Ketersediaan yang terpengaruh, instans Anda di Zona Ketersediaan lainnya tetap tersedia.
Meskipun terpisah secara fisik, Zona Ketersediaan di Wilayah AWS yang sama cukup dekat untuk menyediakan jaringan throughput tinggi dengan latensi rendah (milidetik satu digit). Anda dapat mereplikasi data secara sinkron antara Zona Ketersediaan untuk sebagian besar beban kerja tanpa memengaruhi pengalaman pengguna secara signifikan. Artinya Anda dapat menggunakan Zona Ketersediaan di sebuah Wilayah dalam konfigurasi aktif/aktif atau aktif/siaga.
Semua komputasi yang terkait dengan beban kerja Anda harus didistribusikan di antara beberapa Zona Ketersediaan. Hal ini termasuk instans Amazon EC2
Anda juga harus mereplikasi data untuk beban kerja Anda dan membuatnya tersedia di beberapa Zona Ketersediaan. Beberapa layanan data yang dikelola AWS, seperti Amazon S3
Jika Anda menggunakan penyimpanan yang dikelola sendiri, seperti volume Amazon Elastic Block Store (EBS)
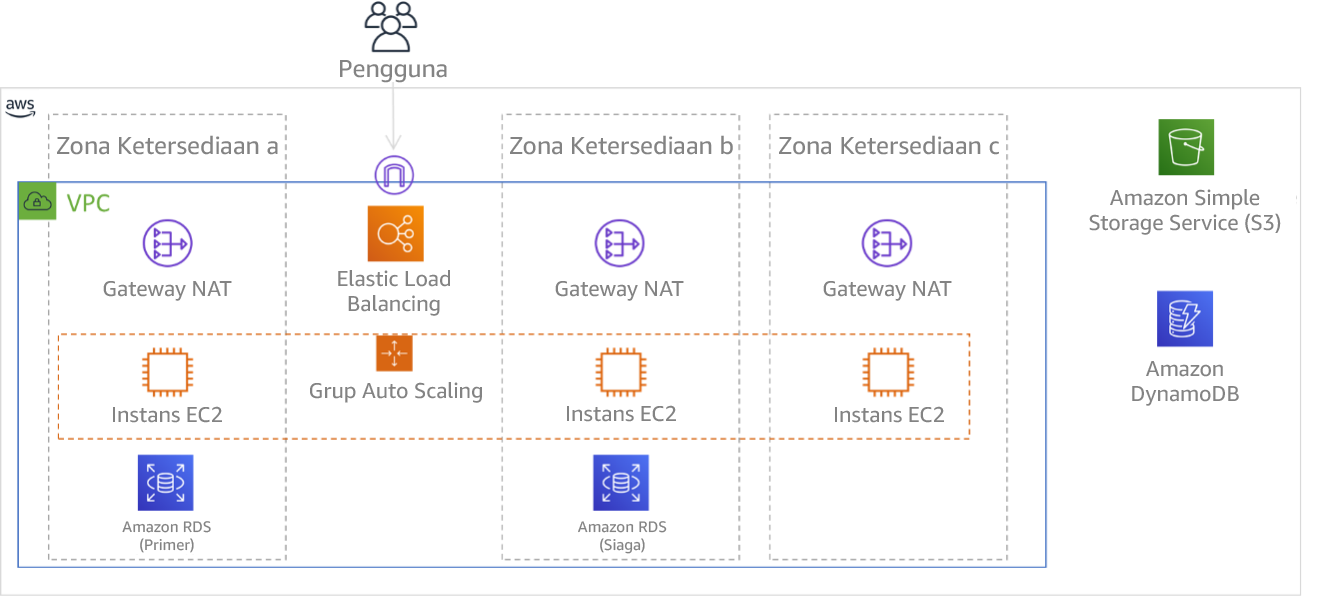
Gambar 9: Arsitektur multitingkat di-deploy di tiga Zona Ketersediaan. Perhatikan bahwa Amazon S3 dan Amazon DynamoDB selalu Multi-AZ secara otomatis. ELB juga di-deploy ke tiga zona.
Menggunakan beberapa Wilayah AWS
Jika Anda memiliki beban kerja yang memerlukan ketahanan ekstrem (seperti infrastruktur sangat penting, aplikasi terkait kesehatan, atau layanan dengan persyaratan ketersediaan yang ketat dari pelanggan atau berdasarkan peraturan), Anda mungkin memerlukan ketersediaan tambahan di luar apa yang dapat disediakan oleh sebuah Wilayah AWS. Dalam hal ini, Anda harus melakukan deployment dan mengoperasikan beban kerja Anda di setidaknya dua Wilayah AWS (dengan asumsi bahwa persyaratan residensi data Anda memungkinkan hal ini).
Wilayah AWS terletak di wilayah geografis yang berbeda-beda di seluruh dunia dan di berbagai benua. Wilayah AWS memiliki pemisahan dan isolasi fisik yang lebih besar daripada Zona Ketersediaan. Layanan AWS, dengan beberapa pengecualian, memanfaatkan desain ini untuk beroperasi sepenuhnya secara independen di antara Wilayah yang berbeda-beda (juga dikenal sebagai layanan Regional). Kegagalan suatu layanan Wilayah AWS dirancang agar tidak memengaruhi layanan di Wilayah yang berbeda.
Ketika Anda mengoperasikan beban kerja Anda di beberapa Wilayah, Anda harus mempertimbangkan persyaratan tambahan. Karena sumber daya di Wilayah yang berbeda-beda saling terpisah dan independen satu sama lain, Anda harus menduplikasi komponen beban kerja Anda di setiap Wilayah. Hal ini termasuk infrastruktur dasar, seperti VPC, selain komputasi dan layanan data.
CATATAN: Saat Anda mempertimbangkan desain multi-Regional, pastikan bahwa beban kerja Anda mampu berjalan di satu Wilayah. Jika Anda membuat dependensi antar-Wilayah yang membuat komponen di satu Wilayah bergantung pada layanan atau komponen di Wilayah lain, Anda dapat meningkatkan risiko kegagalan dan melemahkan postur keandalan Anda secara signifikan.
Untuk memudahkan deployment multi-Regional dan menjaga konsistensi, AWS CloudFormation StackSets dapat mereplikasi seluruh infrastruktur AWS Anda di beberapa Wilayah. AWS CloudFormation
Anda juga harus mereplikasi data Anda di setiap Wilayah yang Anda pilih. Banyak layanan data yang dikelola AWS menyediakan kemampuan replikasi lintas Wilayah, termasuk Amazon S3, Amazon DynamoDB, Amazon RDS, Amazon Aurora, Amazon Redshift, Amazon ElastiCache, dan Amazon EFS. Tabel global Amazon DynamoDB
AWS juga menyediakan kemampuan untuk merutekan lalu lintas permintaan ke deployment Regional Anda dengan fleksibilitas tinggi. Misalnya, Anda dapat mengonfigurasi catatan DNS Anda menggunakan Amazon Route 53
Meskipun Anda memilih untuk tidak beroperasi di beberapa Wilayah untuk ketersediaan tinggi, pertimbangkanlah untuk menggunakan beberapa Wilayah sebagai bagian dari strategi pemulihan bencana (DR) Anda. Jika memungkinkan, replikasi data dan komponen infrastruktur beban kerja Anda dalam konfigurasi warm standby atau pilot light di Wilayah sekunder. Dalam desain ini, Anda mereplikasi infrastruktur dasar dari Wilayah primer seperti VPC, grup Auto Scaling, orkestrator kontainer, dan komponen lainnya, tetapi Anda mengonfigurasi komponen berukuran variabel di Wilayah siaga (seperti jumlah instans EC2 dan replika basis data) menjadi ukuran minimal yang dapat beroperasi. Anda juga mengatur replikasi data berkelanjutan dari Wilayah primer ke Wilayah siaga. Jika suatu insiden terjadi, Anda kemudian dapat menskalakan, atau menambah, sumber daya di Wilayah siaga, lalu mengubahnya menjadi Wilayah primer.
Langkah-langkah implementasi
-
Bekerjasamalah dengan pemangku kepentingan bisnis dan ahli residensi data untuk menentukan Wilayah AWS mana yang dapat digunakan untuk meng-host sumber daya dan data Anda.
-
Libatkan para pemangku kepentingan bisnis dan teknis untuk mengevaluasi beban kerja Anda, dan tentukan apakah kebutuhan ketahanannya dapat dipenuhi dengan pendekatan multi-AZ (Wilayah AWS tunggal) atau jika kebutuhannya adalah pendekatan multi-Wilayah (jika penggunaan beberapa Wilayah diizinkan). Penggunaan beberapa Wilayah dapat mencapai ketersediaan yang lebih besar, tetapi juga dapat meningkatkan kompleksitas dan biaya. Pertimbangkan faktor-faktor berikut dalam evaluasi Anda:
-
Tujuan bisnis dan persyaratan pelanggan: Berapa lama waktu henti yang diizinkan jika insiden yang berdampak pada beban kerja terjadi di sebuah Zona Ketersediaan atau Wilayah? Evaluasi tujuan titik pemulihan Anda seperti yang dibahas dalam REL13-BP01 Menetapkan sasaran pemulihan untuk waktu henti dan kehilangan data.
-
Persyaratan pemulihan bencana (DR): Potensi bencana seperti apa yang ingin Anda antisipasi? Pertimbangkan kemungkinan kehilangan data atau ketidaktersediaan dalam jangka panjang pada berbagai cakupan dampak, mulai dari satu Zona Ketersediaan hingga keseluruhan Wilayah. Jika Anda mereplikasi data dan sumber daya di beberapa Zona Ketersediaan, dan satu Zona Ketersediaan mengalami gangguan berkepanjangan, Anda dapat memulihkan layanan di Zona Ketersediaan lainnya. Jika Anda mereplikasi data dan sumber daya di beberapa Wilayah, Anda dapat memulihkan layanan di Wilayah lain.
-
-
Lakukan deployment sumber daya komputasi Anda ke beberapa Zona Ketersediaan.
-
Di VPC Anda, buat beberapa subnet di Zona Ketersediaan yang berbeda-beda. Konfigurasikan setiap subnet agar cukup besar untuk mengakomodasi sumber daya yang dibutuhkan untuk melayani beban kerja, bahkan saat terjadi gangguan. Untuk detail selengkapnya, lihat REL02-BP03 Pastikan alokasi subnet IP memperhitungkan ekspansi dan ketersediaan.
-
Jika Anda menggunakan instans Amazon EC2, gunakan EC2 Auto Scaling
untuk mengelola instans Anda. Tentukan subnet yang Anda pilih pada langkah sebelumnya saat Anda membuat grup Auto Scaling. -
Jika Anda menggunakan komputasi AWS Fargate untuk Amazon ECS atau Amazon EKS, pilih subnet yang Anda pilih pada langkah pertama saat Anda membuat Layanan ECS, luncurkan tugas ECS, atau buat profil Fargate untuk EKS.
-
Jika Anda menggunakan fungsi AWS Lambda yang perlu dijalankan di VPC Anda, pilih subnet yang Anda pilih pada langkah pertama saat Anda membuat fungsi Lambda. Untuk fungsi apa pun yang tidak memiliki konfigurasi VPC, AWS Lambda mengelola ketersediaan untuk Anda secara otomatis.
-
Tempatkan pengarah lalu lintas seperti penyeimbang beban di depan sumber daya komputasi Anda. Jika penyeimbangan beban lintas zona diaktifkan, Penyeimbang Beban Aplikasi AWS dan Penyeimbang Beban Jaringan akan mendeteksi saat target seperti instans dan kontainer EC2 tidak dapat dijangkau karena gangguan Zona Ketersediaan lalu mengalihkan lalu lintas ke target di Zona Ketersediaan yang sehat. Jika Anda menonaktifkan penyeimbangan beban lintas zona, gunakan Amazon Application Recovery Controller (ARC) untuk menyediakan kemampuan peralihan zona. Jika Anda menggunakan penyeimbang beban pihak ketiga atau telah menerapkan penyeimbang beban Anda sendiri, konfigurasikan dengan beberapa frontend di Zona Ketersediaan yang berbeda-beda.
-
-
Replikasi data beban kerja Anda di beberapa Zona Ketersediaan.
-
Jika Anda menggunakan layanan data yang dikelola AWS seperti Amazon RDS, Amazon ElastiCache, atau Amazon FSx, pelajari panduan penggunanya untuk memahami kemampuan replikasi data dan ketahanannya. Aktifkan replikasi dan failover lintas-AZ jika perlu.
-
Jika Anda menggunakan layanan penyimpanan yang dikelola AWS seperti Amazon S3, Amazon EFS, dan Amazon FSx, jangan menggunakan konfigurasi satu AZ atau Satu Zona untuk data yang memerlukan daya tahan tinggi. Gunakan konfigurasi multi-AZ untuk layanan-layanan ini. Periksa panduan pengguna layanan masing-masing untuk menentukan apakah replikasi multi-AZ diaktifkan secara default atau apakah Anda harus mengaktifkannya.
-
Jika Anda menjalankan basis data, antrean, atau layanan penyimpanan lainnya yang Anda kelola sendiri, atur replikasi multi-AZ sesuai dengan petunjuk atau praktik terbaik aplikasi. Pahami prosedur failover untuk aplikasi Anda.
-
-
Konfigurasikan layanan DNS Anda untuk mendeteksi gangguan pada AZ dan mengalihkan lalu lintas ke Zona Ketersediaan yang sehat. Amazon Route 53, apabila penggunaannya dikombinasikan dengan Penyeimbang Beban Elastis, dapat melakukan hal ini secara otomatis. Route 53 juga dapat dikonfigurasikan dengan catatan failover yang menggunakan pemeriksaan kondisi untuk merespons kueri dengan alamat IP yang sehat saja. Untuk data DNS apa pun yang digunakan untuk failover, tentukan nilai time to live (TTL) yang singkat (misalnya, 60 detik atau kurang) untuk membantu mencegah caching data menghambat pemulihan (data alias Route 53 menyediakan TTL yang sesuai untuk Anda).
Langkah-langkah tambahan saat menggunakan beberapa Wilayah AWS
-
Buat replikasi semua sistem operasi (OS) dan kode aplikasi yang digunakan oleh beban kerja Anda di seluruh Wilayah yang Anda pilih. Buat replikasi Amazon Machine Image (AMI) yang digunakan oleh instans EC2 Anda jika perlu menggunakan solusi seperti Amazon EC2 Image Builder. Buat replikasi image kontainer yang disimpan dalam registri menggunakan solusi seperti replikasi lintas Wilayah Amazon ECR. Aktifkan replikasi Regional untuk bucket Amazon S3 apa pun yang digunakan untuk menyimpan sumber daya aplikasi.
-
Lakukan deployment sumber daya komputasi dan metadata konfigurasi Anda (seperti parameter yang disimpan di Penyimpanan Parameter AWS Systems Manager) ke beberapa Wilayah. Gunakan prosedur yang sama yang dijelaskan dalam langkah sebelumnya, tetapi replikasikan konfigurasi untuk setiap Wilayah yang Anda gunakan untuk beban kerja Anda. Gunakan solusi infrastruktur sebagai kode seperti AWS CloudFormation untuk mereproduksi konfigurasi antar-Wilayah secara seragam. Jika Anda menggunakan Wilayah sekunder dalam konfigurasi pilot light untuk pemulihan bencana, Anda dapat mengurangi jumlah sumber daya komputasi Anda ke nilai minimum untuk menghemat biaya, dengan peningkatan waktu pemulihan yang sesuai.
-
Buat replikasi data Anda dari Wilayah primer Anda ke Wilayah sekunder Anda.
-
Tabel global Amazon DynamoDB menyediakan replika global data Anda yang dapat ditulis dari dan ke Wilayah mana pun yang didukung. Dengan layanan data lain yang dikelola AWS, seperti Amazon RDS, Amazon Aurora, dan Amazon ElastiCache, Anda menetapkan Wilayah primer (baca/tulis) dan Wilayah replika (hanya-baca). Lihat panduan pengguna dan developer layanan masing-masing untuk detail tentang replikasi Regional.
-
Jika Anda menjalankan basis data yang Anda kelola sendiri, atur replikasi multi-Wilayah sesuai dengan petunjuk atau praktik terbaik aplikasi tersebut. Pahami prosedur failover untuk aplikasi Anda.
-
Jika beban kerja Anda menggunakan AWS EventBridge, Anda mungkin perlu meneruskan peristiwa yang dipilih dari Wilayah primer Anda ke Wilayah sekunder Anda. Untuk melakukannya, tentukan bus peristiwa di Wilayah sekunder Anda sebagai target untuk peristiwa yang cocok di Wilayah primer Anda.
-
-
Pertimbangkan apakah Anda ingin menggunakan kunci enkripsi yang identik di seluruh Wilayah dan sejauh apa penggunaannya. Pendekatan umum yang menyeimbangkan keamanan dan kemudahan penggunaan adalah melalui penggunaan kunci dengan cakupan Wilayah untuk data dan autentikasi lokal Wilayah, dan penggunaan kunci dengan cakupan global untuk enkripsi data yang direplikasi di antara Wilayah yang berbeda. AWS Key Management Service (KMS)
mendukung kunci multi-wilayah untuk mendistribusikan dan melindungi kunci yang dibagikan secara aman di berbagai Wilayah. -
Pertimbangkan AWS Global Accelerator untuk meningkatkan ketersediaan aplikasi Anda dengan mengarahkan lalu lintas ke Wilayah yang berisi titik akhir yang sehat.
Sumber daya
Praktik-praktik terbaik terkait:
Dokumen terkait:
-
Amazon EC2 Auto Scaling: Contoh: Mendistribusikan instans di beberapa Zona Ketersediaan
-
Bagaimana Amazon ECS menempatkan tugas pada instans kontainer (termasuk Fargate)
-
Panduan Developer Amazon Application Recovery Controller (ARC)
-
Mengirim dan menerima peristiwa Amazon EventBridge antara Wilayah AWS
-
Arsitektur Pemulihan Bencana (DR) di AWS, Bagian I: Strategi untuk Pemulihan di Cloud
-
Arsitektur Pemulihan Bencana (DR) di AWS, Bagian III: Pilot Light dan Warm Standby
Video terkait:
