Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Opsi pemulihan bencana di cloud
Strategi pemulihan bencana yang tersedia untuk Anda dalam AWS dapat dikategorikan secara luas menjadi empat pendekatan, mulai dari biaya rendah dan kompleksitas rendah dalam membuat cadangan hingga strategi yang lebih kompleks menggunakan beberapa Wilayah aktif. Strategi aktif/pasif menggunakan situs aktif (seperti Wilayah AWS) untuk menampung beban kerja dan melayani lalu lintas. Situs pasif (seperti Wilayah AWS yang berbeda) digunakan untuk pemulihan. Situs pasif tidak aktif melayani lalu lintas sampai peristiwa failover dipicu.
Sangat penting untuk secara teratur menilai dan menguji strategi pemulihan bencana Anda sehingga Anda memiliki kepercayaan diri dalam menerapkannya, jika diperlukan. Gunakan AWS Resilience Hub
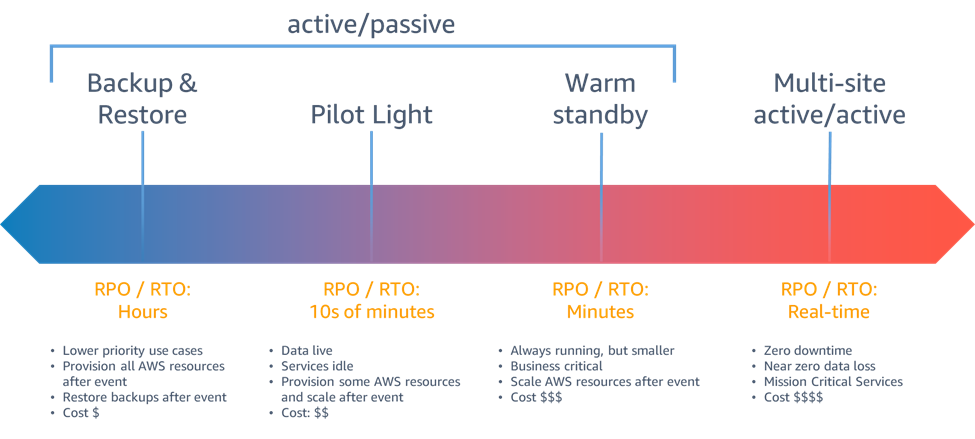
Gambar 6 - Strategi pemulihan bencana
Untuk peristiwa bencana berdasarkan gangguan atau hilangnya satu pusat data fisik untuk beban kerja yang dirancang dengan baik dan
Saat memilih strategi Anda, dan sumber daya AWS untuk mengimplementasikannya, ingatlah bahwa dalam AWS, kami biasanya membagi layanan ke dalam bidang data dan bidang kontrol. Bidang data bertanggung jawab untuk menghadirkan layanan waktu nyata sedangkan bidang kontrol digunakan untuk mengonfigurasi lingkungan. Untuk ketahanan maksimum, Anda harus menggunakan hanya operasi pesawat data sebagai bagian dari operasi failover Anda. Ini karena pesawat data biasanya memiliki tujuan desain ketersediaan yang lebih tinggi daripada bidang kontrol.
Pencadangan dan pemulihan
Backup and restore adalah pendekatan yang cocok untuk mengurangi kehilangan data atau korupsi. Pendekatan ini juga dapat digunakan untuk mengurangi bencana regional dengan mereplikasi data ke Wilayah AWS lainnya, atau untuk mengurangi kurangnya redundansi untuk beban kerja yang diterapkan ke satu Availability Zone. Selain data, Anda harus menerapkan ulang infrastruktur, konfigurasi, dan kode aplikasi di Wilayah pemulihan. Agar infrastruktur dapat digunakan kembali dengan cepat tanpa kesalahan, Anda harus selalu menerapkan menggunakan infrastruktur sebagai kode (IAc) menggunakan layanan seperti atau. AWS CloudFormationAWS Cloud Development Kit (AWS CDK)
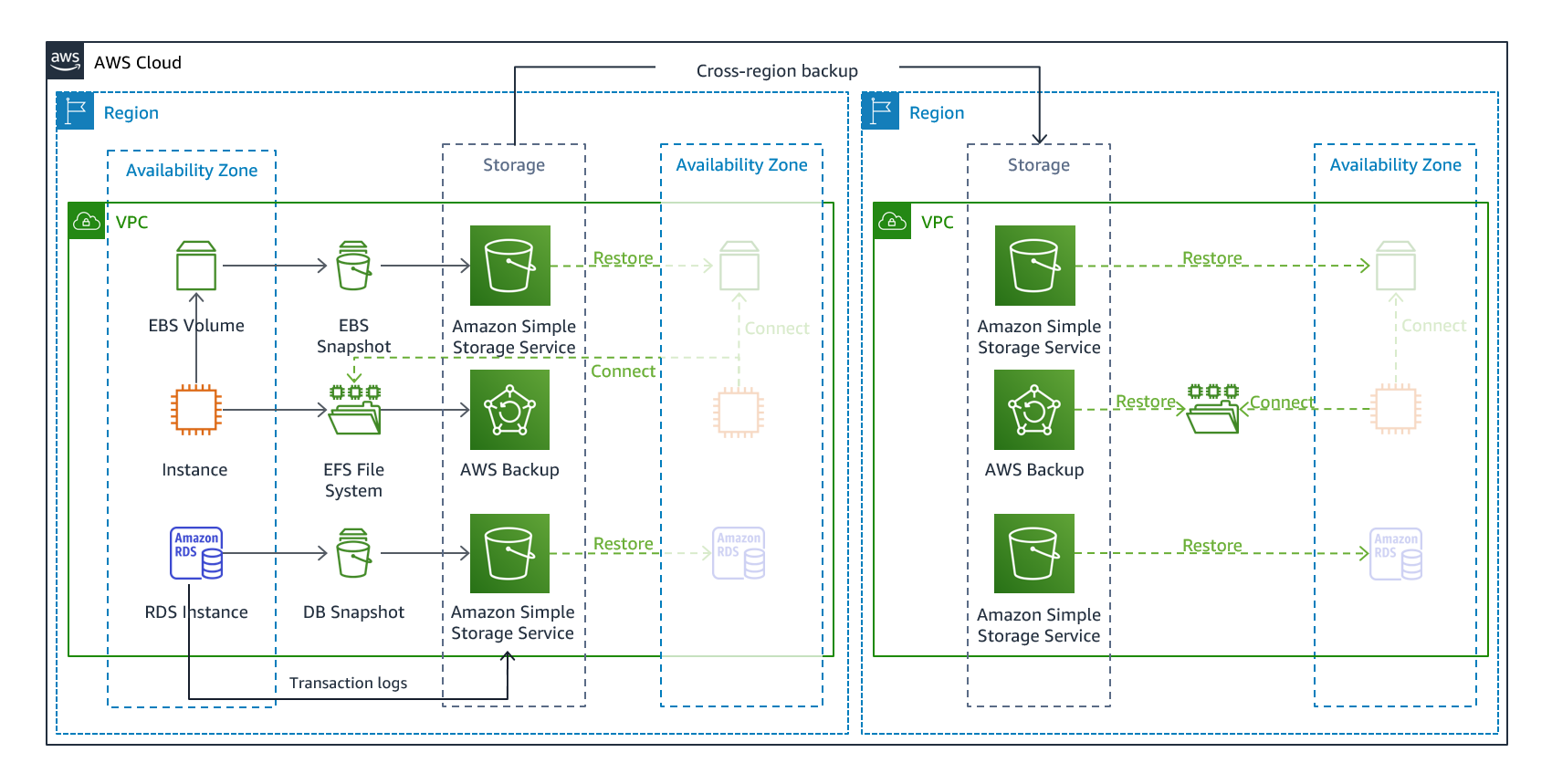
Gambar 7 - Backup dan Restore Arsitektur
Layanan AWS
Data beban kerja Anda akan memerlukan strategi cadangan yang berjalan secara berkala atau berkelanjutan. Seberapa sering Anda menjalankan cadangan Anda akan menentukan titik pemulihan yang dapat dicapai (yang harus selaras untuk memenuhi RPO Anda). Cadangan juga harus menawarkan cara untuk mengembalikannya ke titik waktu di mana ia diambil. Backup dengan point-in-time pemulihan tersedia melalui layanan dan sumber daya berikut:
-
Cadangan Amazon EFS (saat menggunakan AWS Backup)
-
Amazon FSx untuk Windows File Server, Amazon FSx untuk Lustre, Amazon untuk NetApp ONTAP, dan Amazon FSx untuk OpenZFS FSx
Untuk Amazon Simple Storage Service (Amazon S3), Anda dapat menggunakan Amazon S3 Cross-Region Replication (CRR
AWS Backup
-
EC2Contoh Amazon
-
Basis data Amazon Relational Database Service (Amazon RDS
) (termasuk database Amazon Aurora ) -
Volume AWS Storage Gateway
-
Amazon FSx untuk Windows File Server, Amazon FSx untuk Lustre, Amazon untuk NetApp ONTAP, dan Amazon FSx untuk OpenZFS FSx
AWS Backup mendukung penyalinan cadangan di seluruh Wilayah, seperti ke Wilayah pemulihan bencana.
Sebagai strategi pemulihan bencana tambahan untuk data Amazon S3 Anda, aktifkan versi objek S3. Pembuatan versi objek melindungi data Anda di S3 dari konsekuensi tindakan penghapusan atau modifikasi dengan mempertahankan versi asli sebelum tindakan. Pembuatan versi objek dapat menjadi mitigasi yang berguna untuk bencana jenis kesalahan manusia. Jika Anda menggunakan replikasi S3 untuk mencadangkan data ke wilayah DR Anda, maka, secara default, saat objek dihapus di bucket sumber, Amazon S3 hanya menambahkan penanda hapus di bucket sumber. Pendekatan ini melindungi data di Wilayah DR dari penghapusan berbahaya di Wilayah sumber.
Selain data, Anda juga harus mencadangkan konfigurasi dan infrastruktur yang diperlukan untuk memindahkan beban kerja Anda dan memenuhi Tujuan Waktu Pemulihan (RTO) Anda. AWS CloudFormation
Setiap data yang disimpan di Wilayah pemulihan bencana sebagai cadangan harus dipulihkan pada saat failover. AWS Backup menawarkan kemampuan pemulihan, tetapi saat ini tidak mengaktifkan pemulihan terjadwal atau otomatis. Anda dapat menerapkan pemulihan otomatis ke wilayah DR menggunakan AWS SDK APIs untuk AWS Backup dipanggil. Anda dapat mengatur ini sebagai pekerjaan berulang secara teratur atau memicu pemulihan setiap kali cadangan selesai. Gambar berikut menunjukkan contoh pemulihan otomatis menggunakan Amazon Simple Notification Service (Amazon AWS Lambda

Gambar 8 - Memulihkan dan menguji cadangan
catatan
Strategi pencadangan Anda harus mencakup pengujian cadangan Anda. Lihat bagian Menguji Pemulihan Bencana untuk informasi selengkapnya. Lihat AWS Well-Architected Lab: Menguji Backup dan Restore Data untuk demonstrasi
Pilot light
Dengan pendekatan pilot light, Anda mereplikasi data Anda dari satu Wilayah ke Wilayah lain dan menyediakan salinan infrastruktur beban kerja inti Anda. Sumber daya yang diperlukan untuk mendukung replikasi dan pencadangan data, misalnya basis data dan penyimpanan objek, selalu aktif. Elemen lain, seperti server aplikasi, dimuat dengan kode aplikasi dan konfigurasi, tetapi “dimatikan” dan hanya digunakan selama pengujian atau ketika failover pemulihan bencana dipanggil. Di cloud, Anda memiliki fleksibilitas untuk mengurangi sumber daya saat Anda tidak membutuhkannya, dan menyediakannya saat Anda melakukannya. Praktik terbaik untuk “dimatikan” adalah tidak menyebarkan sumber daya, dan kemudian membuat konfigurasi dan kemampuan untuk menerapkannya (“aktifkan”) bila diperlukan. Berbeda dengan pendekatan pencadangan dan pemulihan, infrastruktur inti Anda selalu tersedia dan Anda selalu memiliki opsi untuk menyediakan lingkungan produksi skala penuh dengan mengaktifkan dan meningkatkan skala server aplikasi Anda.
Gambar 9 - Arsitektur cahaya pilot
Pendekatan pilot light meminimalkan biaya pemulihan bencana yang sedang berlangsung dengan meminimalkan sumber daya aktif, dan menyederhanakan pemulihan pada saat bencana karena persyaratan infrastruktur inti semuanya ada. Opsi pemulihan ini mengharuskan Anda untuk mengubah pendekatan penerapan Anda. Anda perlu membuat perubahan infrastruktur inti ke setiap Wilayah dan menerapkan perubahan beban kerja (konfigurasi, kode) secara bersamaan ke setiap Wilayah. Langkah ini dapat disederhanakan dengan mengotomatiskan penerapan Anda dan menggunakan infrastruktur sebagai kode (IAc) untuk menyebarkan infrastruktur di beberapa akun dan Wilayah (penyebaran infrastruktur penuh ke Wilayah utama dan penyebaran infrastruktur yang diperkecil/dimatikan ke wilayah DR). Disarankan Anda menggunakan akun yang berbeda per Wilayah untuk menyediakan isolasi sumber daya dan keamanan tingkat tertinggi (dalam hal kredensi yang dikompromikan juga merupakan bagian dari rencana pemulihan bencana Anda).
Dengan pendekatan ini, Anda juga harus mengurangi bencana data. Replikasi data berkelanjutan melindungi Anda dari beberapa jenis bencana, tetapi mungkin tidak melindungi Anda dari korupsi atau penghancuran data kecuali strategi Anda juga mencakup versi data yang disimpan atau opsi untuk pemulihan. point-in-time Anda dapat mencadangkan data yang direplikasi di Wilayah bencana untuk membuat point-in-time cadangan di Wilayah yang sama.
Layanan AWS
Selain menggunakan layanan AWS yang tercakup dalam bagian Backup dan Restore untuk membuat point-in-time cadangan, pertimbangkan juga layanan berikut untuk strategi pilot light Anda.
Untuk pilot light, replikasi data berkelanjutan ke database langsung dan penyimpanan data di wilayah DR adalah pendekatan terbaik untuk RPO rendah (bila digunakan selain point-in-time cadangan yang dibahas sebelumnya). AWS menyediakan replikasi data asinkron yang berkelanjutan, lintas wilayah, dan asinkron untuk data menggunakan layanan dan sumber daya berikut:
Dengan replikasi berkelanjutan, versi data Anda segera tersedia di Wilayah DR Anda. Waktu replikasi aktual dapat dipantau menggunakan fitur layanan seperti S3 Replication Time Control (S3 RTC) untuk objek S3 dan fitur manajemen database global Amazon Aurora.
Ketika gagal menjalankan beban kerja baca/tulis Anda dari Wilayah pemulihan bencana, Anda harus mempromosikan replika baca RDS untuk menjadi contoh utama. Untuk instans DB selain Aurora, prosesnya membutuhkan beberapa menit untuk diselesaikan dan reboot adalah bagian dari proses. Untuk Replikasi Lintas Wilayah (CRR) dan failover dengan RDS, menggunakan database global Amazon Aurora memberikan beberapa keuntungan. Database global menggunakan infrastruktur khusus yang membuat database Anda sepenuhnya tersedia untuk melayani aplikasi Anda, dan dapat mereplikasi ke Wilayah sekunder dengan latensi tipikal kurang dari satu detik (dan dalam Wilayah AWS kurang dari 100 milidetik). Dengan database global Amazon Aurora, jika Wilayah utama Anda mengalami penurunan kinerja atau pemadaman, Anda dapat mempromosikan salah satu wilayah sekunder untuk mengambil tanggung jawab baca/tulis dalam waktu kurang dari satu menit bahkan jika terjadi pemadaman regional total. Anda juga dapat mengonfigurasi Aurora untuk memantau jeda waktu RPO dari semua cluster sekunder untuk memastikan bahwa setidaknya satu cluster sekunder tetap berada dalam jendela RPO target Anda.
Versi infrastruktur beban kerja inti Anda yang diperkecil dengan sumber daya yang lebih sedikit atau lebih kecil harus diterapkan di Wilayah DR Anda. Dengan menggunakan AWS CloudFormation, Anda dapat menentukan infrastruktur dan menerapkannya secara konsisten di seluruh akun AWS dan di seluruh Wilayah AWS. AWS CloudFormation menggunakan parameter semu yang telah ditentukan sebelumnya untuk mengidentifikasi akun AWS dan Wilayah AWS tempat akun tersebut digunakan. Oleh karena itu, Anda dapat menerapkan logika kondisi di CloudFormation template Anda untuk menerapkan hanya versi infrastruktur yang diperkecil di Wilayah DR. EC2 Misalnya penerapan, Amazon Machine Image (AMI) menyediakan informasi seperti konfigurasi perangkat keras dan perangkat lunak yang diinstal. Anda dapat mengimplementasikan pipeline Image Builder yang membuat kebutuhan AMIs Anda dan menyalinnya ke Wilayah utama dan cadangan Anda. Ini membantu memastikan bahwa emas ini AMIs memiliki semua yang Anda butuhkan untuk menyebarkan kembali atau meningkatkan beban kerja Anda di wilayah baru, jika terjadi peristiwa bencana. EC2 Instans Amazon diterapkan dalam konfigurasi yang diperkecil (lebih sedikit instans daripada di Wilayah utama Anda). Untuk meningkatkan skala infrastruktur guna mendukung lalu lintas produksi, lihat Amazon Auto EC2 Scaling
Untuk konfigurasi aktif/pasif seperti lampu pilot, semua lalu lintas awalnya pergi ke Wilayah utama dan beralih ke Wilayah pemulihan bencana jika Wilayah utama tidak lagi tersedia. Operasi failover ini dapat dimulai secara otomatis dan manual. Failover yang dimulai secara otomatis berdasarkan pemeriksaan kesehatan atau alarm harus digunakan dengan hati-hati. Bahkan menggunakan praktik terbaik yang dibahas di sini, waktu pemulihan dan titik pemulihan akan lebih besar dari nol, menimbulkan beberapa kehilangan ketersediaan dan data. Jika Anda gagal ketika Anda tidak perlu (alarm palsu), maka Anda mengalami kerugian tersebut. Oleh karena itu, Failover yang dimulai secara manual sering digunakan. Dalam kasus ini, Anda masih harus mengotomatiskan langkah failover, sehingga inisiasi manual akan seperti menekan tombol.
Ada beberapa opsi manajemen lalu lintas yang perlu dipertimbangkan saat menggunakan AWS layanan.
Salah satu opsinya adalah menggunakan Amazon Route 53
Pilihan lain adalah menggunakan AWS Global Accelerator
Amazon CloudFront
AWS Pemulihan Bencana Elastis
AWS Elastic Disaster Recovery

Gambar 10 - Arsitektur Pemulihan Bencana AWS Elastis
Warm standby
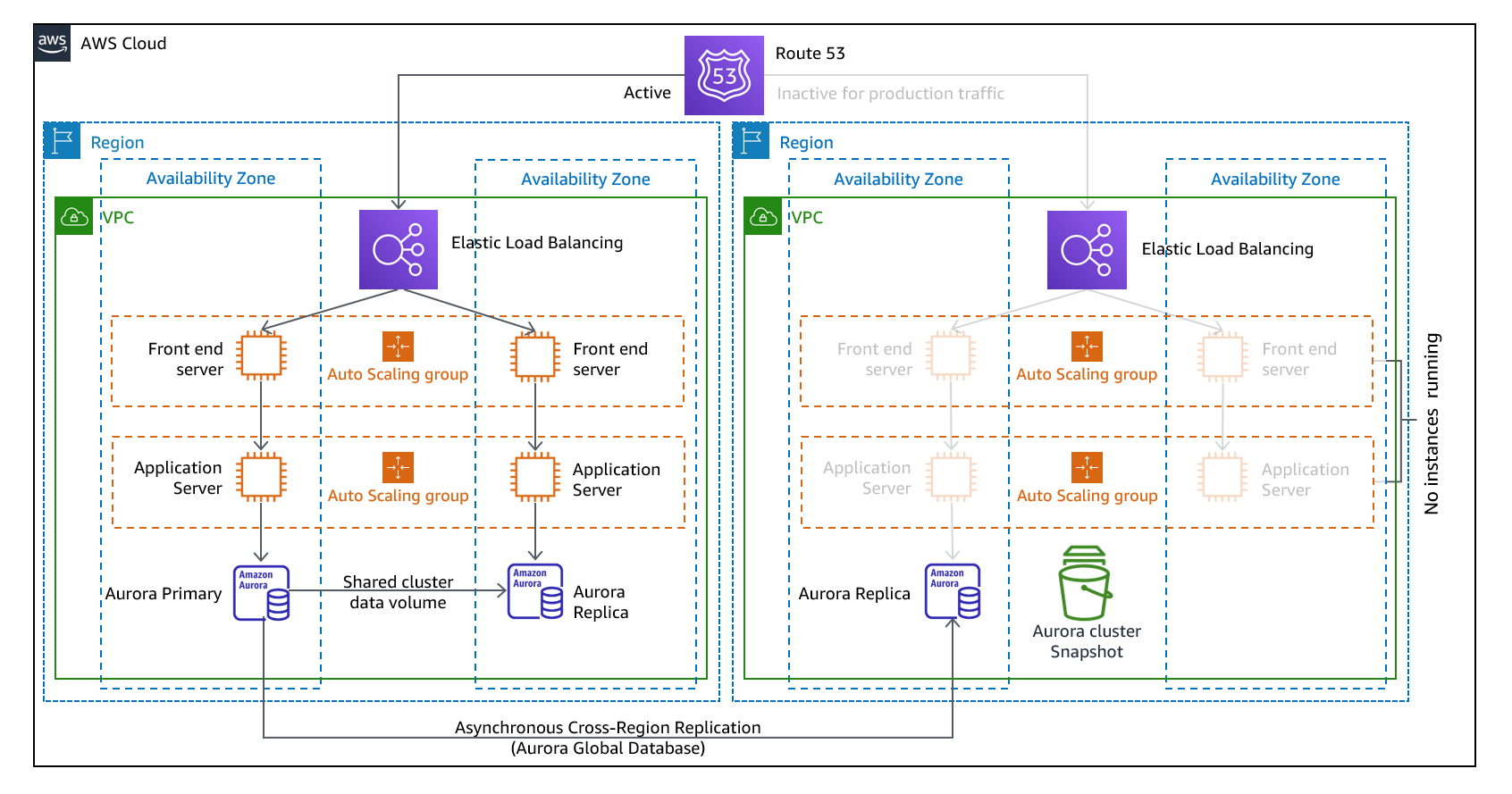
Pendekatan warm standby melibatkan memastikan ada salinan lingkungan produksi yang skalanya diturunkan tetapi berfungsi sepenuhnya di Wilayah lainnya. Pendekatan ini memperpanjang konsep pilot light dan mempercepat waktu pemulihan karena beban kerja selalu aktif di Wilayah lainnya. Pendekatan ini juga memungkinkan Anda untuk lebih mudah melakukan pengujian atau menerapkan pengujian berkelanjutan untuk meningkatkan kepercayaan pada kemampuan Anda untuk pulih dari bencana.
Gambar 11 - Arsitektur siaga hangat
Catatan: Perbedaan antara lampu pilot dan siaga hangat terkadang sulit dipahami. Keduanya mencakup lingkungan di Wilayah DR Anda dengan salinan aset Wilayah utama Anda. Perbedaannya adalah bahwa lampu pilot tidak dapat memproses permintaan tanpa tindakan tambahan yang diambil terlebih dahulu, sedangkan siaga hangat dapat menangani lalu lintas (pada tingkat kapasitas yang dikurangi) dengan segera. Pendekatan pilot light mengharuskan Anda untuk “menghidupkan” server, mungkin menerapkan infrastruktur tambahan (non-inti), dan meningkatkan skala, sedangkan siaga hangat hanya mengharuskan Anda untuk meningkatkan (semuanya sudah digunakan dan berjalan). Gunakan kebutuhan RTO dan RPO Anda untuk membantu Anda memilih di antara pendekatan ini.
Layanan AWS
Semua layanan AWS yang tercakup dalam pencadangan dan pemulihan dan lampu pilot juga digunakan dalam keadaan siaga hangat untuk pencadangan data, replikasi data, perutean lalu lintas aktif/pasif, dan penyebaran infrastruktur termasuk instance. EC2
EC2 Auto Scaling Amazon
Karena Auto Scaling adalah aktivitas bidang kontrol, mengambil ketergantungan padanya akan menurunkan ketahanan strategi pemulihan Anda secara keseluruhan. Ini adalah trade-off. Anda dapat memilih untuk menyediakan kapasitas yang cukup sehingga Wilayah pemulihan dapat menangani beban produksi penuh seperti yang digunakan. Konfigurasi stabil statis ini disebut hot standby (lihat bagian selanjutnya). Atau Anda dapat memilih untuk menyediakan lebih sedikit sumber daya yang biayanya lebih murah, tetapi bergantung pada Auto Scaling. Beberapa implementasi DR akan menggunakan sumber daya yang cukup untuk menangani lalu lintas awal, memastikan RTO rendah, dan kemudian mengandalkan Auto Scaling untuk meningkatkan lalu lintas berikutnya.
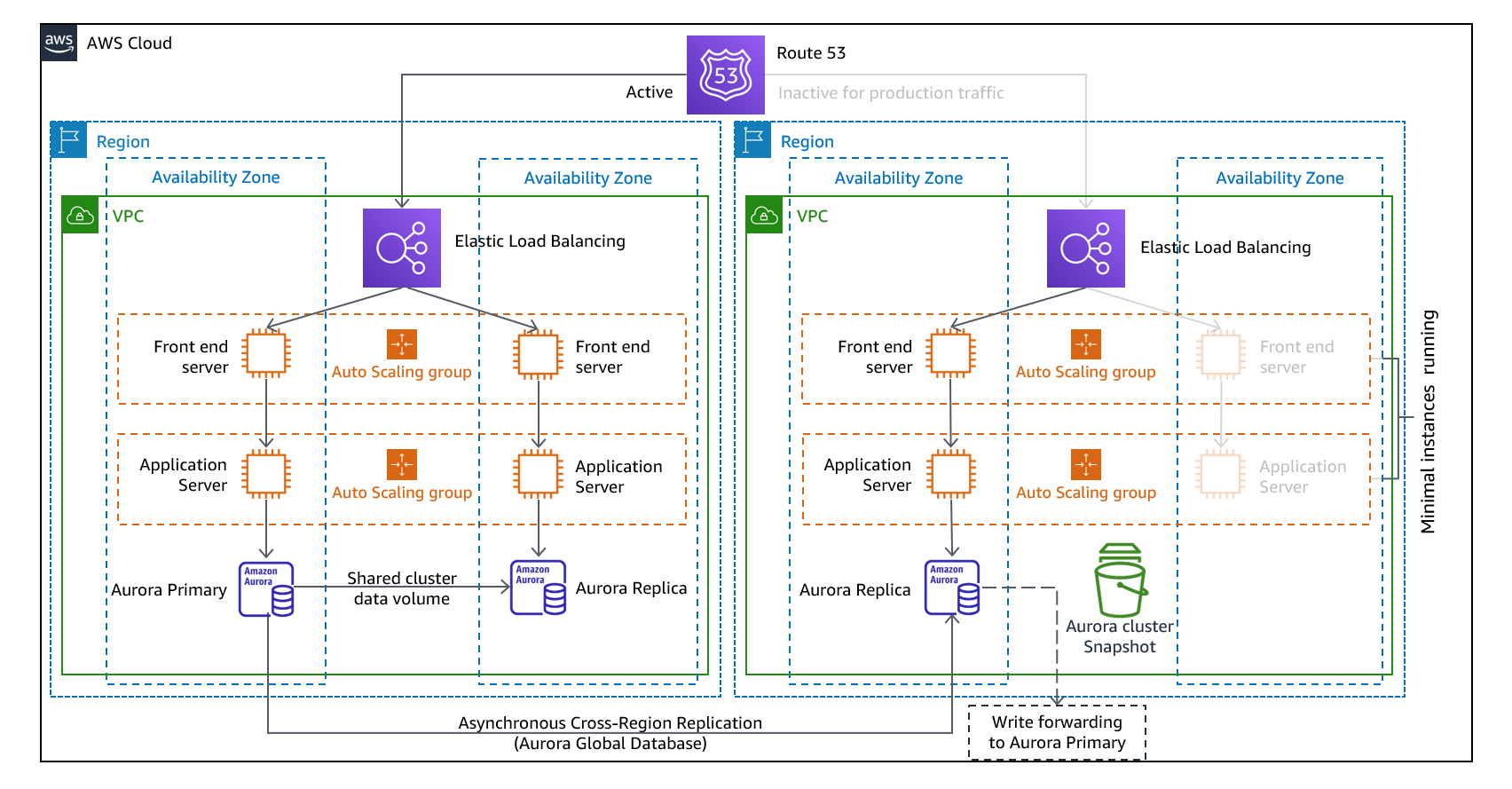
Multi-situs aktif/aktif
Anda dapat menjalankan beban kerja Anda secara bersamaan di beberapa Wilayah sebagai bagian dari strategi aktif/aktif aktif atau siaga aktif multi-situs aktif/pasif. Multi-situsactive/active serves traffic from all regions to which it is deployed, whereas hot standby serves traffic only from a single region, and the other Region(s) are only used for disaster recovery. With a multi-site active/active approach, users are able to access your workload in any of the Regions in which it is deployed. This approach is the most complex and costly approach to disaster recovery, but it can reduce your recovery time to near zero for most disasters with the correct technology choices and implementation (however data corruption may need to rely on backups, which usually results in a non-zero recovery point). Hot standby uses an active/passive configuration where users are only directed to a single region and DR regions do not take traffic. Most customers find that if they are going to stand up a full environment in the second Region, it makes sense to use it active/active. Atau, jika Anda tidak ingin menggunakan kedua Wilayah untuk menangani lalu lintas pengguna, maka Warm Standby menawarkan pendekatan yang lebih ekonomis dan operasional kurang kompleks.
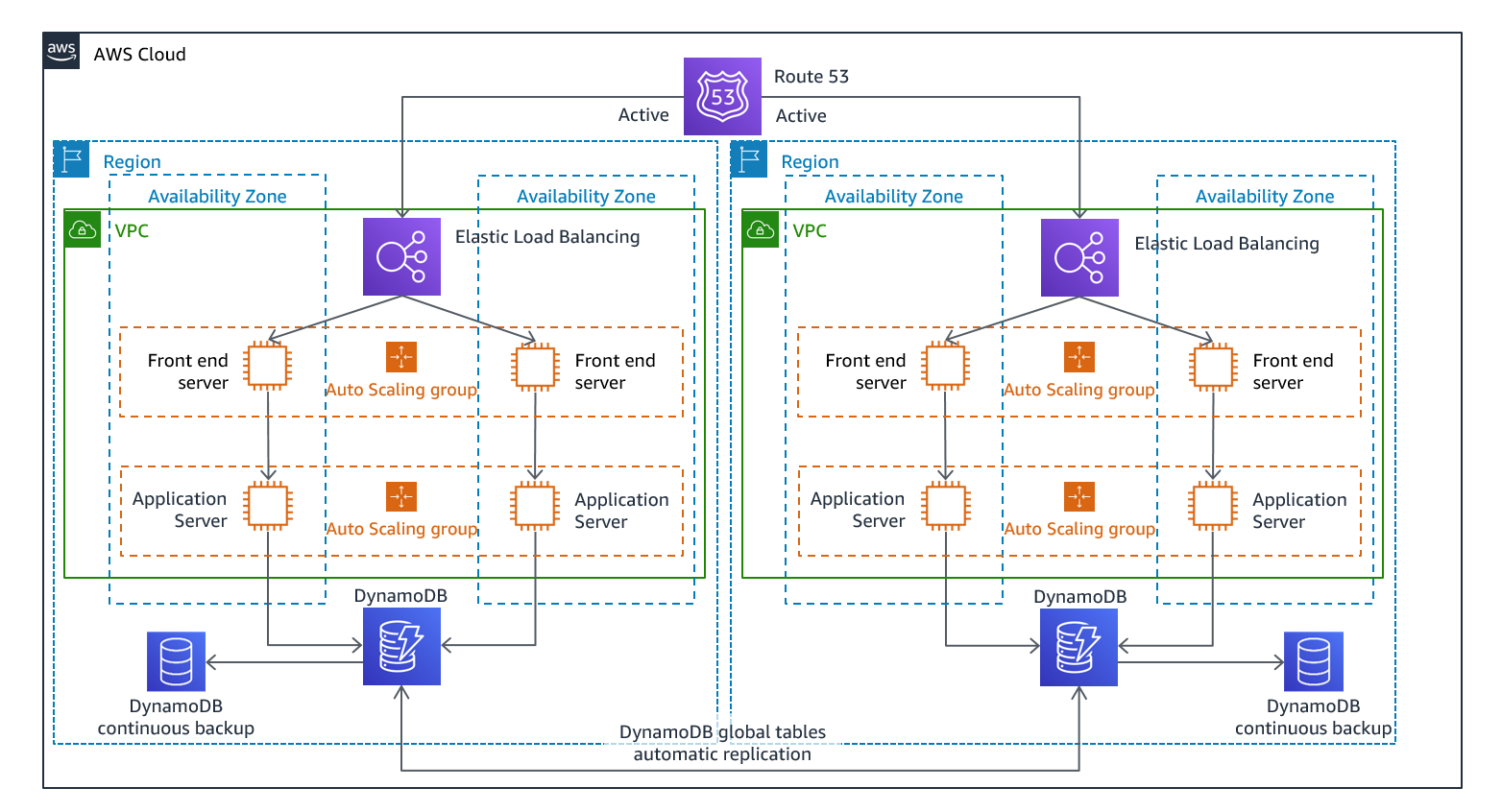
Gambar 12 - Arsitektur aktif/aktif multi-situs (ubah satu jalur Aktif menjadi Tidak Aktif untuk siaga panas)
Dengan pendekatan multi-situs active/active, because the workload is running in more than one Region, there is no such thing as failover in this scenario. Disaster recovery testing in this case would focus on how the workload reacts to loss of a Region: Is traffic routed away from the failed Region? Can the other Region(s) handle all the traffic? Testing for a data disaster is also required. Backup and recovery are still required and should be tested regularly. It should also be noted that recovery times for a data disaster involving data corruption, deletion, or obfuscation will always be greater than zero and the recovery point will always be at some point before the disaster was discovered. If the additional complexity and cost of a multi-site active/active (atau siaga panas) diperlukan untuk mempertahankan waktu pemulihan mendekati nol, maka upaya tambahan harus dilakukan untuk menjaga keamanan dan untuk mencegah kesalahan manusia untuk mengurangi bencana manusia.
Layanan AWS
Semua layanan AWS yang tercakup dalam pencadangan dan pemulihan, lampu pilot, dan siaga hangat juga digunakan di sini untuk pencadangan point-in-time data, replikasi data, perutean lalu lintas aktif/aktif, serta penyebaran dan penskalaan infrastruktur termasuk instance. EC2
Untuk skenario aktif/pasif yang dibahas sebelumnya (Pilot Light dan Warm Standby), Amazon Route 53 dan AWS Global Accelerator dapat digunakan untuk rute lalu lintas jaringan ke wilayah aktif. Untuk strategi aktif/aktif di sini, kedua layanan ini juga memungkinkan definisi kebijakan yang menentukan pengguna mana yang pergi ke titik akhir regional aktif mana. Dengan AWS Global Accelerator Anda mengatur panggilan lalu lintas untuk mengontrol persentase lalu lintas yang diarahkan ke setiap titik akhir aplikasi. Amazon Route 53 mendukung pendekatan persentase ini, dan juga beberapa kebijakan lain yang tersedia termasuk kebijakan berbasis geoproximity dan latensi. Global Accelerator secara otomatis memanfaatkan jaringan ekstensif server AWS edge, untuk mengarahkan lalu lintas ke backbone jaringan AWS sesegera mungkin, sehingga latensi permintaan lebih rendah.
Replikasi data asinkron dengan strategi ini memungkinkan RPO mendekati nol. Layanan AWS seperti database global Amazon Aurora menggunakan infrastruktur khusus yang membuat database Anda sepenuhnya tersedia untuk melayani aplikasi Anda, dan dapat mereplikasi hingga lima Wilayah sekunder dengan latensi tipikal kurang dari satu detik. Dengan active/passive strategies, writes occur only to the primary Region. The difference with active/active merancang bagaimana konsistensi data dengan penulisan ke setiap Wilayah aktif ditangani. Merupakan hal yang umum untuk merancang bacaan pengguna untuk dilayani dari Wilayah terdekat dengan mereka, yang dikenal sebagai baca lokal. Dengan menulis, Anda memiliki beberapa opsi:
-
Rute strategi global tulis semuanya menulis ke satu Wilayah. Dalam kasus kegagalan Wilayah itu, Wilayah lain akan dipromosikan untuk menerima tulisan. Basis data global Aurora sangat cocok untuk menulis global, karena mendukung sinkronisasi dengan replika baca di seluruh Wilayah, dan Anda dapat mempromosikan salah satu Wilayah sekunder untuk mengambil tanggung jawab baca/tulis dalam waktu kurang dari satu menit. Aurora juga mendukung penerusan tulis, yang memungkinkan cluster sekunder dalam database global Aurora meneruskan pernyataan SQL yang melakukan operasi tulis ke cluster primer.
-
Rute strategi lokal tulis menulis ke Wilayah terdekat (seperti membaca). Tabel global Amazon DynamoDB memungkinkan strategi semacam itu, memungkinkan baca dan tulis dari setiap wilayah tabel global Anda digunakan. Tabel global Amazon DynamoDB menggunakan penulis terakhir memenangkan rekonsiliasi antara pembaruan bersamaan.
-
Strategi partisi tulis menetapkan penulisan ke Wilayah tertentu berdasarkan kunci partisi (seperti ID pengguna) untuk menghindari konflik penulisan. Replikasi Amazon S3 yang dikonfigurasi dua arah
dapat digunakan untuk kasus ini, dan saat ini mendukung replikasi antara dua Wilayah. Saat menerapkan pendekatan ini, pastikan untuk mengaktifkan sinkronisasi modifikasi replika pada bucket A dan B untuk mereplikasi perubahan metadata replika seperti daftar kontrol akses objek (ACLs), tag objek, atau kunci objek pada objek yang direplikasi. Anda juga dapat mengonfigurasi apakah akan mereplikasi penanda hapus antar bucket di Wilayah aktif atau tidak. Selain replikasi, strategi Anda juga harus menyertakan point-in-time cadangan untuk melindungi terhadap korupsi data atau peristiwa penghancuran.
AWS CloudFormation adalah alat yang ampuh untuk menegakkan infrastruktur yang diterapkan secara konsisten di antara akun AWS di beberapa Wilayah AWS. AWS CloudFormation StackSetsmemperluas fungsi ini dengan memungkinkan Anda membuat, memperbarui, atau menghapus CloudFormation tumpukan di beberapa akun dan Wilayah dengan satu operasi. Meskipun AWS CloudFormation menggunakan YAMAL atau JSON untuk mendefinisikan Infrastruktur sebagai Kode, AWS Cloud Development Kit (AWS CDK)
