Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Backtrack di un cluster database Aurora
Con Amazon Aurora MySQL-Compatible Edition, puoi eseguire il backtrack di un cluster DB fino a un'ora specifica, senza ripristinare i dati da un backup.
Importante
Il backtracking è supportato in Aurora MySQL versione 2, versione 3 e versione 8.4.
Indice
Considerazioni sull'aggiornamento per i cluster abilitati per backtrack
Configurazione del backtrack di un cluster di database Aurora MySQL
Esecuzione di un backtrack per un cluster di database Aurora MySQL
Monitoraggio del backtrack per un cluster di database Aurora MySQL
Disabilitazione del backtrack per un cluster di database Aurora MySQL
Panoramica del backtrack
Il backtrack "riavvolge" il cluster database all'orario che specifichi. Il backtrack non è un'operazione sostitutiva del backup del cluster database che consente di eseguire un ripristino point-in-time dello stesso. Fornisce tuttavia i seguenti vantaggi rispetto alle operazioni di backup e ripristino tradizionali:
Puoi annullare facilmente eventuali errori. Se esegui accidentalmente un'operazione distruttiva, come DELETE senza una clausola WHERE, puoi eseguire il backtrack del cluster database a un orario antecedente all'operazione distruttiva con un'interruzione minima del servizio.
Puoi eseguire il backtrack di un cluster database rapidamente. Il ripristino point-in-time di un cluster database avvia un nuovo cluster database e lo ripristina a partire dai dati di backup o da uno snapshot e questa operazione può durare varie ore. Il backtrack di un cluster database non richiede un nuovo cluster database e "riavvolge" il cluster all'orario specificato in pochi minuti.
Puoi esplorare le modifiche ai dati precedenti. Puoi eseguire ripetutamente il backtrack di un cluster database avanti e indietro nel tempo per determinare quando si è verificata una determinata modifica. Ad esempio, puoi eseguire il backtrack di un cluster database tre ore indietro e quindi un'ora avanti. In questo caso, l'orario di backtrack è due ore prima l'orario di origine.
Nota
Per informazioni sul ripristino point-in-time di un cluster database, consulta Panoramica di backup e ripristino di un cluster di database Aurora.
Finestra di backtrack
Con il backtrack, si ha una finestra di backtrack target e una finestra di backtrack effettiva:
-
La finestra di backtrack target è il periodo di tempo durante il quale desideri eseguire il backtrack del cluster di database. Quando abiliti il backtrack, specifichi una finestra di backtrack target. Ad esempio, potresti specificare una finestra di backtrack target di 24 ore se desideri eseguire un backtrack di un giorno per il cluster di database.
-
La finestra di backtrack effettiva è il periodo di tempo effettivo durante il quale puoi eseguire il backtrack del cluster di database, che può essere inferiore alla finestra di backtrack target. La finestra di backtrack effettiva è basata sul carico di lavoro e sullo storage disponibile per archiviare le informazioni relative alle modifiche del database denominate record di modifica.
Quando aggiorni il cluster di database Aurora con il backtrack abilitato, generi record di modifica. Aurora conserva i record di modifica per la finestra di backtrack di destinazione e per l’archiviazione di questi dati si applica una tariffa oraria. La finestra di backtrack target e il carico di lavoro sul cluster di database determinano il numero di record di modifica che vengono archiviati. Il carico di lavoro è il numero di modifiche che apporti al cluster di database in un determinato periodo di tempo. Il numero di record di modifica archiviati nella finestra di backtrack quando il carico di lavoro è pesante è maggiore rispetto a quello con un carico di lavoro leggero.
Puoi considerare la finestra di backtrack target come l'obiettivo per il periodo di tempo massimo durante il quale desideri eseguire il backtrack del cluster di database. Nella maggior parte dei casi, puoi eseguire un backtrack corrispondente al periodo di tempo massimo specificato. Tuttavia, in alcuni casi, il cluster di database non può archiviare un numero sufficiente di record di modifica per eseguire un backtrack corrispondente al periodo di tempo massimo e la finestra di backtrack effettiva è più piccola della finestra di backtrack target. In genere, la finestra di backtrack effettiva è più piccola di quella target quando il carico di lavoro è estremamente pesante sul cluster di database. Quando la finestra di backtrack effettiva è più piccola di quella target, ti inviamo una notifica.
Quando il backtrack è abilitato per un cluster di database ed elimini una tabella archiviata in quel cluster, Aurora conserva quella tabella nei record di modifica del backtrack. In questo modo, puoi ritornare a un orario antecedente a quello in cui hai eliminato la tabella. Se tuttavia non hai spazio sufficiente nella finestra di backtrack per archiviare la tabella, è possibile che questa venga rimossa dai record di modifica del backtrack.
Orario di backtrack
Aurora esegue sempre il backtrack a un orario coerente per il cluster di database. In questo modo, viene eliminata la possibilità di transazioni di cui non è stato eseguito il commit al completamento del backtrack. Quando specifichi un orario per un backtrack, Aurora sceglie automaticamente l'orario coerente più vicino possibile. Questo approccio significa che il backtrack completato potrebbe non corrispondere esattamente all'ora specificata, ma è possibile determinare l'ora esatta per un backtrack utilizzando il comando CLI AWS describe-db-cluster-backtracks. Per ulteriori informazioni, consulta Recupero di backtrack esistenti.
Limiti del backtrack
I seguenti limiti si applicano al backtrack:
-
Il backtrack è disponibile solo per i cluster di database creati con la funzionalità di backtrack abilitata. Non puoi modificare un cluster di database per abilitare la funzionalità di backtrack. Puoi abilitare il backtrack quando crei un nuovo cluster di database o ripristini uno snapshot di un cluster di database.
-
Il limite per una finestra di backtrack è 72 ore.
-
Il backtrack influisce sull'intero cluster di database. Ad esempio, non puoi eseguire un backtrack selettivo di una singola tabella o di un singolo aggiornamento di dati.
-
Non puoi creare repliche di lettura tra Regioni da un cluster abilitato al backtrack, ma puoi comunque abilitare la replica dei log binari (binlog) sul cluster. Se tenti di eseguire il backtrack di un cluster di database per il quale è abilitata la registrazione di log binari, in genere si verifica un errore a meno che tu non abbia scelto di forzare il backtrack. Qualsiasi tentativo di forzare un backtrack interromperà le repliche di lettura successive e interferirà con altre operazioni come le distribuzioni. blue/green
-
Non puoi eseguire il backtrack di un clone di database a un orario antecedente a quello di creazione del clone. Puoi tuttavia utilizzare il database originale per eseguire il backtrack a un orario antecedente a quello di creazione del clone. Per ulteriori informazioni sulla creazione di cloni di database, consulta Clonazione di un volume per un cluster di database Amazon Aurora.
-
Il backtrack comporta una breve interruzione dell'istanza database. Devi arrestare o interrompere le applicazioni prima di avviare un'operazione di backtrack per assicurarti che non vi siano nuove richieste di lettura o scrittura. Durante l'operazione di backtrack, Aurora interrompe il database, chiude tutte le connessioni aperte ed elimina le letture e scritture di cui non è stato eseguito il commit. Attende quindi il completamento dell'operazione di backtrack.
-
Non è possibile ripristinare un'istantanea interregionale di un cluster abilitato al backtrack in una regione che non supporta il backtracking. AWS
-
Se si esegue un aggiornamento sul posto per un cluster abilitato al backtrack da Aurora MySQL versione 2 alla versione 3 o dalla versione 3 alla versione 8.4, non è possibile tornare indietro a un momento precedente all'aggiornamento.
Disponibilità di regioni e versioni
Backtrack non è disponibile per Aurora PostgreSQL.
Di seguito sono riportati i motori supportati e la disponibilità nelle regioni per backtrack con Aurora MySQL.
| Region | Aurora MySQL versione 8.4 | Aurora MySQL versione 3 | Aurora MySQL versione 2 |
|---|---|---|---|
| Stati Uniti orientali (Virginia settentrionale) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Stati Uniti orientali (Ohio) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Stati Uniti occidentali (California settentrionale) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Stati Uniti occidentali (Oregon) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Africa (Città del Capo) | – | – | – |
| Asia Pacifico (Hong Kong) | – | – | – |
| Asia Pacifico (Giacarta) | – | – | – |
| Asia Pacifico (Malesia) | – | – | – |
| Asia Pacifico (Melbourne) | – | – | – |
| Asia Pacifico (Mumbai) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Asia Pacifico (Nuova Zelanda) | – | – | – |
| Asia Pacifico (Osaka) | Tutte le versioni | Tutte le versioni | Versione 2.07.3 e versioni successive |
| Asia Pacifico (Seul) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Asia Pacifico (Singapore) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Asia Pacifico (Sydney) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Asia Pacifico (Taipei) | – | – | – |
| Asia Pacifico (Thailandia) | – | – | – |
| Asia Pacifico (Tokyo) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Canada (Centrale) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Canada occidentale (Calgary) | – | – | – |
| Cina (Pechino) | – | – | – |
| Cina (Ningxia) | – | – | – |
| Europa (Francoforte) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Europa (Irlanda) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Europa (Londra) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Europa (Milano) | – | – | – |
| Europa (Parigi) | Tutte le versioni | Tutte le versioni | Tutte le versioni |
| Europa (Spagna) | – | – | – |
| Europa (Stoccolma) | – | – | – |
| Europa (Zurigo) | – | – | – |
| Israele (Tel Aviv) | – | – | – |
| Messico (centrale) | – | – | – |
| Medio Oriente (Bahrein) | – | – | – |
| Medio Oriente (Emirati Arabi Uniti) | – | – | – |
| Sud America (San Paolo) | – | – | – |
| AWS GovCloud (US-East) | – | – | – |
| AWS GovCloud (US-West) | – | – | – |
Considerazioni sull'aggiornamento per i cluster abilitati per backtrack
È possibile aggiornare un cluster DB abilitato al backtrack da Aurora MySQL versione 2 alla versione 3 o dalla versione 3 alla versione 8.4, poiché tutte le versioni minori di Aurora MySQL versione 3 e versione 8.4 sono supportate per Backtrack.
Abbonamento a un evento di backtrack con la console
La procedura seguente descrive come abbonarsi a un evento di backtrack mediante la console. L'evento ti invia un'email o una notifica di testo quando la finestra di backtrack effettiva è più piccola della finestra di backtrack target.
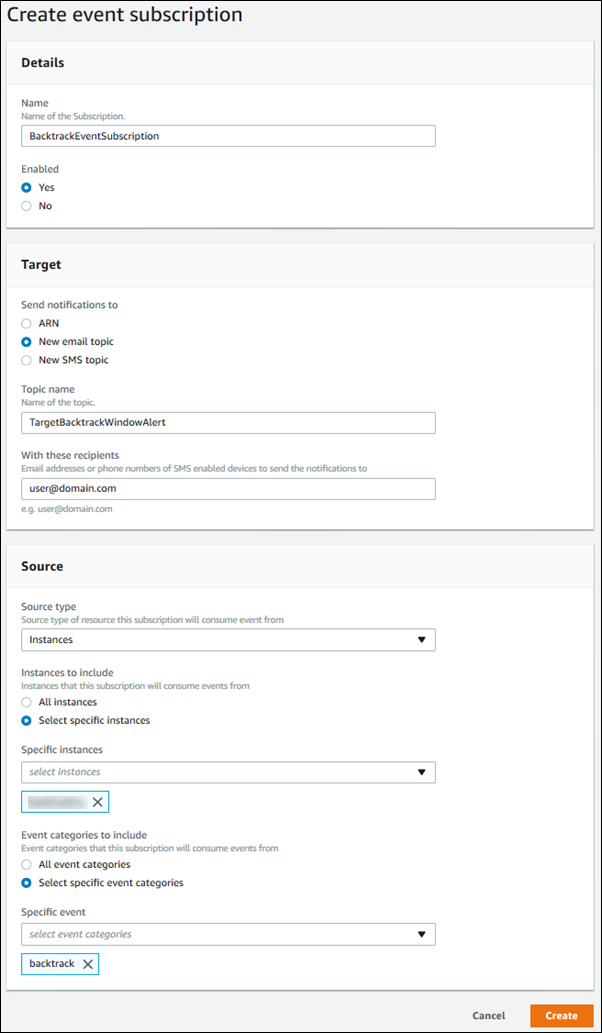
Per visualizzare le informazioni di backtrack mediante la console
Accedi a AWS Management Console e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Scegliere Event subscriptions (Abbonamenti a eventi).
-
Scegliere Create event subscription (Crea abbonamento a eventi).
-
Nella casella Name (Nome), digitare un nome per l'abbonamento all'evento e assicurarsi che Yes (Sì) è selezionato per Enabled (Abilitato).
-
Nella sezione Target, scegliere New email topic (Nuovo argomento e-mail).
-
In Topic name (Nome argomento), digitare un nome per l'argomento e in With these recipients (Con questi destinatari), digitare gli indirizzi e-mail o i numeri di telefono per ricevere le notifiche.
-
Nella sezione Source (origine), scegliere Instances (Istanze) per Source type (Tipo origine).
-
Per Instances to include (Istanze da includere), scegliere Select specific instances (Seleziona specifiche istanze) e scegliere l'istanza database.
-
In Event categories to include (Categorie di eventi da includere), scegliere Select specific event categories (Seleziona specifiche categorie di eventi), quindi scegliere Backtrack.
La pagina dovrebbe essere simile alla seguente.
-
Scegli Create (Crea).
Recupero di backtrack esistenti
Puoi recuperare informazioni relative a backtrack esistenti per un cluster di database. Queste informazioni includono l'identificatore univoco del backtrack, la data e l'ora di inizio e di fine del backtrack, la data e l'ora in cui il backtrack è stato richiesto e lo stato corrente del backtrack.
Nota
Non è attualmente possibile recuperare backtrack esistenti mediante la console.
La procedura seguente descrive come recuperare backtrack esistenti per un cluster di database mediante l AWS CLI.
Per recuperare i backtrack esistenti utilizzando il AWS CLI
-
Chiamare il comando describe-db-cluster-backtracks dell'CLI AWS e specificare i seguenti valori:
-
--db-cluster-identifier:– il nome del cluster database.
L'esempio seguente recupera i backtrack esistenti per
sample-cluster.Per Linux, macOS o Unix:
aws rds describe-db-cluster-backtracks \ --db-cluster-identifier sample-clusterPer Windows:
aws rds describe-db-cluster-backtracks ^ --db-cluster-identifier sample-cluster -
Per recuperare informazioni sui backtrack per un cluster DB utilizzando l'API Amazon RDS, utilizza l'operazione. DescribeDBClusterBacktracks Questa operazione restituisce le informazioni relative ai backtrack per il cluster database specificato nel valore DBClusterIdentifier.
