Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migrazione fisica da MySQL utilizzando XtraBackup Percona e Amazon S3
Puoi copiare i file di backup completi e incrementali dal database MySQL versione 5.7 o 8.0 di origine a un bucket S3. Puoi quindi eseguire il ripristino in un cluster database Amazon Aurora MySQL con la stessa versione principale del motore d9 datahase da tali file.
Questa opzione può essere molto più veloce rispetto alla migrazione dei dati utilizzando mysqldump, in quanto l'utilizzo di mysqldump riproduce tutti i comandi per ricreare lo schema e i dati dal database di origine nel cluster di database Aurora MySQL. Copiando i file di dati MySQL origine, Aurora MySQL può immediatamente utilizzare quei file come dati per un cluster di database Aurora MySQL.
Puoi anche ridurre al minimo i tempi di inattività utilizzando la replica dei log binari durante il processo di migrazione. Se utilizzi la replica dei log binari, il database MySQL esterno rimane aperto per transazioni mentre i dati sono in fase di migrazione verso il cluster database Aurora MySQL. Dopo la creazione del cluster di database Aurora MySQL utilizza la replica dei log binari per sincronizzare il cluster di database Aurora MySQL con le transazioni avvenute dopo il backup. Quando il cluster di database Aurora MySQL è aggiornato con il database MySQL, la migrazione viene terminata passando completamente al cluster di database Aurora MySQL per le nuove transazioni. Per ulteriori informazioni, consulta Sincronizzazione del cluster database Amazon Aurora MySQL con il database MySQL utilizzando la replica.
Indice
Considerazioni e limitazioni
Le seguenti limitazioni e considerazioni si applicano al ripristino su un cluster database Amazon Aurora MySQL da un bucket Amazon S3:
-
Puoi eseguire la migrazione dei tuoi dati solo a un nuovo cluster database e non a un cluster database esistente.
-
È necessario utilizzare Percona per eseguire il backup dei dati XtraBackup su S3. Per ulteriori informazioni, consulta Installazione di Percona XtraBackup.
-
Il bucket Amazon S3 e il cluster Aurora MySQL DB devono trovarsi nella stessa regione. AWS
-
Non puoi eseguire il ripristino dai seguenti elementi:
-
Esportazione di uno snapshot cluster database in Amazon S3. Non è possibile eseguire la migrazione dei dati da un'esportazione snapshot del cluster database al bucket S3.
-
Un database di origine crittografato, ma puoi crittografare i dati migrati. Durante il processo di migrazione puoi anche lasciare i dati non crittografati.
-
Un database MySQL 5.5 o 5.6
-
-
Percona Server per MySQL non è supportato come database di origine, perché può contenere tabelle
compression_dictionary*nello schemamysql. -
Non è possibile eseguire il ripristino da un cluster database Aurora Serverless.
-
La migrazione alle versioni precedenti non è supportata per le versioni principali e secondarie. Ad esempio, non puoi eseguire la migrazione da MySQL versione 8.0 ad Aurora MySQL versione 2 (compatibile con MySQL 5.7), né da MySQL versione 8.0.32 ad Aurora MySQL versione 3.03, che è compatibile con la versione 8.0.26 della community MySQL.
-
Non è possibile migrare ad Aurora MySQL 3.05 e versioni successive da alcune versioni precedenti di MySQL 8.0, tra cui 8.0.11, 8.0.13 e 8.0.15. Si consiglia di eseguire l'aggiornamento a MySQL 8.0.28 prima della migrazione.
-
L'importazione da Amazon S3 non è supportata sulla classe di istanza database db.t2.micro. Tuttavia, puoi eseguire il ripristino in una classe istanza database diversa e modificare la classe di istanza in seguito. Per maggiori informazioni sulle classi di istanza database, consulta Amazon AuroraClassi di istanze database.
-
Amazon S3 limita la dimensione del file caricato in un bucket S3 a 5 TB. Se un file di backup supera i 5 TB, devi dividerlo in file più piccoli.
-
Amazon RDS limita il numero di file caricati in un bucket S3 a 1 milione. Se i dati di backup del database, inclusi tutti i backup completi e incrementali, superano 1 milione di file, utilizza un file Gzip (.gz), tar (.tar.gz) o Percona xbstream (.xbstream) per archiviare i file dei backup completi e incrementali nel bucket S3. Percona XtraBackup 8.0 supporta solo Percona xbstream per la compressione.
-
Per fornire servizi di gestione per ogni cluster database, viene creato l'utente
rdsadminal momento della creazione del cluster database. Poiché si tratta di un utente riservato in RDS, si applicano le seguenti limitazioni:-
Le funzioni, le procedure, le viste, gli eventi e i trigger con il definer
'rdsadmin'@'localhost'non vengono importati. Per ulteriori informazioni, consultare Oggetti archiviati con 'rdsadmin'@'localhost' come definer e Privilegi dell'utente master con Amazon Aurora MySQL.. -
Quando viene creato il cluster database Aurora MySQL, viene creato un utente master con i privilegi massimi supportati. Durante il ripristino dal backup, tutti i privilegi non supportati assegnati agli utenti importati vengono rimossi automaticamente durante l'importazione.
Per identificare gli utenti che potrebbero essere interessati da questo problema, consulta Account utente con privilegi non supportati. Per ulteriori informazioni sui privilegi supportati in Aurora MySQL, consulta Role-based modello di privilegio.
-
-
Per Aurora MySQL versione 3, i privilegi dinamici non vengono importati. Aurora-supported i privilegi dinamici possono essere importati dopo la migrazione. Per ulteriori informazioni, consulta Privilegi dinamici in Aurora MySQL versione 3.
-
User-created le tabelle dello
mysqlschema non vengono migrate. -
Il parametro
innodb_data_file_pathdeve essere configurato con un solo file di dati che utilizza il nome di file di dati predefinitoibdata1:12M:autoextend. I database con due file di dati o con un file di dati con un nome diverso non possono essere migrati utilizzando questo metodo.Di seguito sono riportati esempi di nomi di file non consentiti:
innodb_data_file_path=ibdata1:50M,ibdata2:50M:autoextendeinnodb_data_file_path=ibdata01:50M:autoextend. -
Non puoi eseguire la migrazione da un database di origine con tabelle definite all'esterno della directory dei dati MySQL predefinita.
-
La dimensione massima supportata per i backup non compressi che utilizzano questo metodo è attualmente limitata a 64 TiB. Per i backup compressi, questo limite viene ridotto per tenere conto dei requisiti dello spazio di decompressione. In questi casi, la dimensione massima di backup supportata sarebbe è (
64 TiB – compressed backup size). -
Aurora MySQL non supporta l'importazione di MySQL e di altri componenti e plugin esterni.
-
Aurora MySQL non ripristina tutto dal database. È consigliabile salvare lo schema e i valori del database per i seguenti elementi dal database MySQL di origine e quindi aggiungerli al cluster database Aurora MySQL ripristinato dopo che è stato creato:
-
Account utenti
-
Funzioni
-
Procedure archiviate
-
Informazioni fuso orario. Le informazioni sul fuso orario vengono caricate dal sistema operativo locale per il cluster database Aurora MySQL. Per ulteriori informazioni, consulta Fuso orario locale per i cluster DB Amazon Aurora.
-
Prima di iniziare
Prima di poter copiare i dati in un bucket Amazon S3 ed eseguire il ripristino in un cluster database da tali file, devi eseguire quanto segue:
-
Installa Percona XtraBackup sul tuo server locale.
-
Permetti a Aurora MySQL di accedere al bucket Amazon S3 per tuo conto.
Installazione di Percona XtraBackup
Amazon Aurora può ripristinare un cluster DB da file creati utilizzando Percona. XtraBackup Puoi installare Percona XtraBackup da Software Downloads
Per la migrazione a MySQL 5.7, usa Percona 2.4. XtraBackup
Per la migrazione a MySQL 8.0, usa Percona 8.0. XtraBackup Assicurati che la versione di Percona sia compatibile con la XtraBackup versione del motore del tuo database di origine.
Autorizzazioni richieste
Per migrare i dati MySQL in un cluster database Amazon Aurora MySQL, sono necessarie molte autorizzazioni:
-
L'utente che richiede ad Aurora di creare un nuovo cluster da un bucket Amazon S3 deve avere l'autorizzazione per elencare i bucket per il proprio account. AWS Concedi all'utente questa autorizzazione utilizzando una AWS Identity and Access Management policy (IAM).
-
Aurora richiede l'autorizzazione di agire per tuo conto per accedere al bucket Amazon S3 dove archivi i file utilizzati per creare il cluster di database Amazon Aurora MySQL. Concedi ad Aurora le autorizzazioni necessarie utilizzando un ruolo di servizio IAM.
-
L'utente che effettua la richiesta deve avere anche l'autorizzazione di elencare i ruoli IAM per l'account AWS .
-
Se l'utente che effettua la richiesta deve creare un ruolo di servizio IAM o richiedere che Aurora crei un ruolo di servizio IAM (utilizzando la console), l'utente deve avere l'autorizzazione di creare un ruolo IAM per l'account AWS .
-
Se prevedi di crittografare i dati durante il processo di migrazione, aggiorna la policy IAM dell'utente che eseguirà la migrazione per concedere l'accesso RDS all'utente AWS KMS keys utilizzato per la crittografia dei backup. Per istruzioni, consulta Creazione di una policy IAM per accedere alle AWS KMS risorse.
Ad esempio, la seguente policy IAM concede all'utente le autorizzazioni minime necessarie per utilizzare la console per elencare ruoli IAM, creare un ruolo IAM, elencare i bucket Amazon S3 per l'account ed elencare le chiavi KMS.
Inoltre, affinché un utente associ un ruolo IAM a un bucket Amazon S3, l'utente IAM deve avere l'autorizzazione iam:PassRole per quel ruolo IAM. Quest'autorizzazione permette a un amministratore di limitare quali ruoli IAM un utente può associare a un bucket Amazon S3.
Ad esempio, la policy IAM permette a un utente di associare il ruolo denominato S3Access a un bucket Amazon S3.
Per ulteriori informazioni sulle autorizzazioni utente IAM, consulta Gestione dell’accesso tramite policy.
Creazione del ruolo del servizio IAM
Puoi Console di gestione AWS creare un ruolo per te scegliendo l'opzione Crea un nuovo ruolo (illustrata più avanti in questo argomento). Se selezioni questa opzione e specifichi un nome per il nuovo ruolo, Aurora crea il ruolo del servizio IAM necessario affinché Aurora acceda al bucket Amazon S3 con il nome che fornisci.
In alternativa, puoi creare manualmente il ruolo utilizzando la procedura seguente.
Per creare un ruolo IAM affinché Aurora possa accedere a Amazon S3
-
Completa le fasi descritte in Creazione di una policy IAM per l'accesso alle risorse Amazon S3.
-
Completa le fasi descritte in Creazione di un ruolo IAM per consentire ad Amazon Aurora di accedere ai servizi AWS.
-
Completa le fasi descritte in Associazione di un ruolo IAM a un cluster DB Amazon Aurora MySQL.
Esecuzione del backup di file da ripristinare come un cluster database Amazon Aurora MySQL
Puoi creare un backup completo dei file del tuo database MySQL utilizzando XtraBackup Percona e caricare i file di backup su un bucket Amazon S3. In alternativa, se utilizzi già Percona XtraBackup per eseguire il backup dei file del tuo database MySQL, puoi caricare le directory e i file di backup completi e incrementali esistenti su un bucket Amazon S3.
Argomenti
Creazione di un backup completo con Percona XtraBackup
Per creare un backup completo dei file del database MySQL che possono essere ripristinati da Amazon S3 per creare un cluster Aurora MySQL DB, utilizza l'utilità Percona () per eseguire il backup del database. XtraBackup xtrabackup
Ad esempio, il comando seguente consente di creare un backup di un database MySQL e memorizzare i file nella cartella /on-premises/s3-restore/backup.
xtrabackup --backup --user=<myuser>--password=<password>--target-dir=</on-premises/s3-restore/backup>
Se desideri comprimere il backup in un singolo file (che può essere diviso, se necessario), puoi utilizzare l'opzione --stream per salvare il backup in uno dei seguenti formati:
-
Gzip (.gz)
-
tar (.tar)
-
Percona xbstream (.xbstream)
Il comando seguente consente di creare un backup del database MySQL diviso in più file Gzip.
xtrabackup --backup --user=<myuser>--password=<password>--stream=tar \ --target-dir=</on-premises/s3-restore/backup>| gzip - | split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.tar.gz
Il comando seguente consente di creare un backup del database MySQL diviso in più file tar.
xtrabackup --backup --user=<myuser>--password=<password>--stream=tar \ --target-dir=</on-premises/s3-restore/backup>| split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.tar
Il comando seguente consente di creare un backup del database MySQL diviso in più file xbstream.
xtrabackup --backup --user=<myuser>--password=<password>--stream=xbstream \ --target-dir=</on-premises/s3-restore/backup>| split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.xbstream
Nota
Se viene visualizzato il seguente errore, potrebbe essere causato dalla combinazione di formati di file nel comando:
ERROR:/bin/tar: This does not look like a tar archive
Dopo aver eseguito il backup del database MySQL utilizzando l'utilità XtraBackup Percona, puoi copiare le directory e i file di backup in un bucket Amazon S3.
Per informazioni sulla creazione e il caricamento di un file in un bucket Amazon S3, consulta Nozioni di base su Amazon Simple Storage Service nella Guida alle operazioni di base di Amazon S3.
Utilizzo di backup incrementali con Percona XtraBackup
Amazon Aurora MySQL supporta backup completi e incrementali creati con Percona. XtraBackup Se utilizzi già Percona XtraBackup per eseguire backup completi e incrementali dei file del tuo database MySQL, non è necessario creare un backup completo e caricare i file di backup su Amazon S3. Puoi, invece, risparmiare tempo copiando le directory e i file di backup esistenti per i tuoi backup completi e incrementali in un bucket Amazon S3. Per ulteriori informazioni, consulta Create an incremental backup
Durante la copia dei file del backup completo e incrementale in un bucket Amazon S3, devi copiare in modo ricorsivo i contenuti della directory di base. Questi contenuti includono il backup completo e anche tutte le directory e i file del backup incrementale. Questa copia deve mantenere la struttura di directory nel bucket Amazon S3. Aurora esegue l'iterazione di tutti i file e le directory. Aurora usa il file xtrabackup-checkpoints incluso con ogni backup incrementale per identificare la directory di base e ordinare i backup incrementali in base all'intervallo dei numeri di sequenza log (LSN).
Per informazioni sulla creazione e il caricamento di un file in un bucket Amazon S3, consulta Nozioni di base su Amazon Simple Storage Service nella Guida alle operazioni di base di Amazon S3.
Considerazioni sul backup
Aurora non supporta i backup parziali creati utilizzando Percona. XtraBackup Non puoi usare le opzioni seguenti per creare un backup parziale quando esegui il backup dei file di origine per il database: --tables, --tables-exclude, --tables-file, --databases, --databases-exclude o --databases-file.
Per ulteriori informazioni sul backup del database con Percona XtraBackup, consulta Percona XtraBackup - Documentation and Work with binary
Aurora supporta i backup incrementali creati utilizzando Percona. XtraBackup Per ulteriori informazioni, consulta Create an incremental backup
Aurora consuma i file di backup in base al nome del file. Assicurati di assegnare un nome ai file di backup con l'estensione file appropriata in base al formato file,— ad esempio, .xbstream per i file archiviati utilizzando il formato Percona xbstream.
Aurora consuma i file di backup in ordine alfabetico e anche in ordine numerico naturale. Utilizza sempre l'opzione split quando invii il comando xtrabackup per assicurarti che i file di backup vengano scritti e denominati nell'ordine corretto.
Amazon S3 limita la dimensione del file caricato in un bucket Amazon S3 a 5 TB. Se i dati di backup per il database eccedono 5 TB, utilizza il comando split per suddividere i file di backup in file multipli che hanno meno di 5 TB ciascuno.
Aurora limita il numero di file di origine caricati in un bucket Amazon S3 a 1 milione di file. In alcuni casi, i dati di backup per il database, compresi i backup completi e incrementali, possono ammontare a un numero alto di file. In questi casi, utilizza un file tarball (.tar.gz) per archiviare i file di backup completi e incrementali in un bucket Amazon S3.
Quando carichi un file in un bucket Amazon S3, puoi utilizzare la crittografia lato server per crittografare i dati. Puoi ripristinare un cluster database Amazon Aurora MySQL da quei file crittografati. Amazon Aurora MySQL può ripristinare un cluster di database con file crittografati utilizzando i seguenti tipi di crittografia lato server:
-
Server-side crittografia con chiavi gestite da Amazon S3 (SSE-S3): ogni oggetto è crittografato con una chiave unica che utilizza una potente crittografia multifattoriale.
-
Server-side crittografia con AWS KMS—managed keys (SSE-KMS) — Simile a SSE-S3, ma hai la possibilità di creare e gestire tu stesso le chiavi di crittografia e anche altre differenze.
Per informazioni sull'utilizzo della crittografia lato server durante il caricamento di file in un bucket Amazon S3, consulta Protezione dei dati con la crittografia lato server nella Guida per sviluppatori Amazon S3.
Ripristino di un cluster di database Amazon Aurora MySQL da un bucket Amazon S3
Puoi ripristinare i file di backup dal bucket Amazon S3 per creare un nuovo cluster di database Amazon Aurora MySQL utilizzando la console Amazon RDS.
Per ripristinare un cluster di database Amazon Aurora MySQL da file in un bucket Amazon S3
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nell'angolo in alto a destra della console Amazon RDS, scegli la AWS regione in cui creare il tuo cluster DB. Scegli la stessa AWS regione del bucket Amazon S3 che contiene il backup del database.
-
Nel riquadro di navigazione, scegliere Databases (Database) e Restore from S3 (Ripristina da S3).
-
Seleziona Ripristina da S3.
Sarà visualizzata la pagina Crea database ripristinando da S3 .
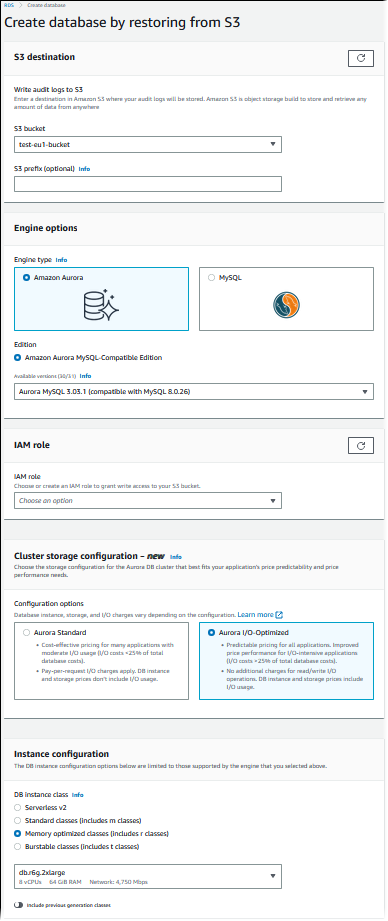
-
In Destinazione S3:
-
Selezionare il bucket S3 che contiene i file di backup.
-
(Facoltativo) Per S3 folder path prefix (Prefisso percorso cartella S3) inserire un prefisso del percorso per i file archiviati nel bucket Amazon S3.
Se non si specifica un prefisso, RDS crea l'istanza database utilizzando tutti i file e le cartelle nella cartella root del bucket S3. Se si specifica un prefisso, RDS crea l'istanza database utilizzando tutti i file e le cartelle nel bucket S3 in cui il percorso del file inizia con il prefisso specificato.
Ad esempio, si supponga di archiviare i file di backup su S3 in una sottocartella denominata backups e di disporre di più set di file di backup, ciascuno nella sua directory (gzip_backup1, gzip_backup2 e così via). In questo caso, si specifica il prefisso da backups/gzip_backup1 ripristinare dai file nella cartella gzip_backup1.
-
-
In Opzioni motore:
-
Per Engine type (Tipo di motore), seleziona Amazon Aurora.
-
Per Version (Versione), scegliere la versione del motore Aurora MySQL per l'istanza database ripristinata.
-
-
Per Ruolo IAM, puoi scegliere un ruolo IAM esistente.
-
(Facoltativo) Puoi anche creare un nuovo ruolo IAM selezionando Crea un nuovo ruolo. In tal caso:
-
Specifica il nome del ruolo IAM.
-
Specifica se consentire l'accesso alla chiave KMS:
-
Se non hai crittografato i file di backup, seleziona No.
-
Se hai crittografato i file di backup con AES-256 (SSE-S3) quando li hai caricati su Amazon S3, scegli No. In questo caso, i dati vengono decrittografati automaticamente.
-
Se hai crittografato i file di backup con la crittografia lato server AWS KMS (SSE-KMS) quando li hai caricati su Amazon S3, scegli Sì. In seguito, scegli la chiave corretta per AWS KMS key.
Console di gestione AWS Crea una policy IAM che consente ad Aurora di decrittografare i dati.
Per ulteriori informazioni, consulta Protezione dei dati con la crittografia lato server nella Guida per sviluppatori Amazon S3.
-
-
-
Scegliere le impostazioni per il cluster database, ad esempio la configurazione dell'archiviazione del cluster database, la classe di istanza database, l'identificatore del cluster database e le credenziali di accesso. Per informazioni su ciascuna impostazione, consulta Impostazioni per cluster di database Aurora.
-
Personalizzare le impostazioni aggiuntive per il cluster database Aurora MySQL in base alle esigenze.
-
Scegliere Create database (Crea database) per avviare l'istanza database Aurora.
Nella console Amazon RDS la nuova istanza database viene visualizzata nell'elenco delle istanze database. L'istanza database rimane nello stato creating (creazione in corso) fino a quando non è stata creata e non è pronta per l'uso. Quando lo stato passa su available (disponibile), puoi connetterti all'istanza principale per il cluster database. A seconda della classe di istanza database e dello store allocato, potrebbero trascorrere diversi minuti prima che la nuova istanza sia disponibile.
Per visualizzare il cluster appena creato, seleziona la visualizzazione Databases (Database) nella console Amazon RDS quindi seleziona il cluster di database. Per ulteriori informazioni, consulta Visualizzazione di un cluster di database Amazon Aurora.
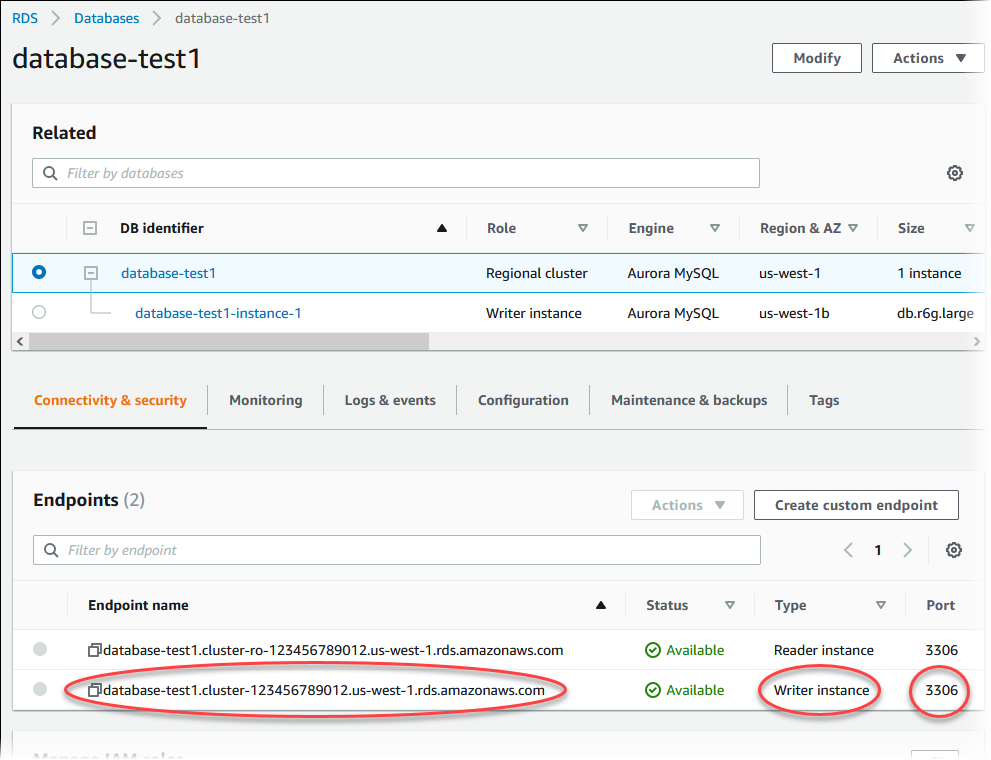
Prendi nota della porta e dell'endpoint di scrittura del cluster database. Utilizza la porta e l'endpoint di scrittura del cluster database nelle stringhe di connessione JDBC e ODBC per un'applicazione che esegue operazioni di scrittura o lettura.
Sincronizzazione del cluster database Amazon Aurora MySQL con il database MySQL utilizzando la replica
Per fare in modo che ci sia poco o nessun tempo di inattività durante la migrazione, puoi replicare le transazioni eseguite sul database MySQL nel cluster database Aurora MySQL. La replica permette al cluster database di essere aggiornato con le transazioni nel database MySQL avvenute durante la migrazione. Quando il cluster database è completamente aggiornato, puoi fermare la replica e terminare la migrazione su Aurora MySQL.
Argomenti
Configurazione del database MySQL esterno e del cluster database Aurora MySQL per la replica crittografata
Per replicare i dati in maniera sicura, puoi utilizzare la replica crittografata.
Nota
Se non hai bisogno di utilizzare la replica crittografata, puoi saltare queste fasi e passare alle istruzioni in Sincronizza il cluster database Amazon Aurora MySQL con il database MySQL esterno.
Seguono i prerequisiti per l'utilizzo della replica crittografata:
-
Secure Sockets Layer (SSL) deve essere abilitato su un database primario MySQL esterno.
-
Una chiave e un certificato client devono essere preparati per il cluster database Aurora MySQL.
Durante la replica crittografata, il cluster di database Aurora MySQL agisce come un client per il server di database MySQL. I certificati e le chiavi per il client Aurora MySQL sono in file in formato .pem.
Per configurare il database MySQL esterno e il cluster database Aurora MySQL per la replica crittografata
-
Assicurati di essere preparato per la replica crittografata:
-
Se SSL non è abilitato sul database MySQL primario esterno e non disponi di una chiave client e di un certificato client preparato, abilita SSL sul server di database MySQL e genera la chiave client e il certificato client necessari.
-
Se SSL è abilitato sul primario esterno, fornisci un certificato e una chiave client per il cluster database Aurora MySQL. Se non disponi di questi elementi, genera una nuova chiave e un nuovo certificato per il cluster di database Aurora MySQL. Per firmare il certificato client, devi avere la chiave autorità certificato che hai utilizzato per configurare SSL nel database primario esterno MySQL.
Per ulteriori informazioni, consulta Creating SSL Certificates and Keys Using openssl
nella documentazione MySQL. Hai bisogno del certificato autorità certificato, della chiave client e del certificato client.
-
-
Esegui la connessione al cluster database Aurora MySQL come primario utilizzando SSL.
Per informazioni sulla connessione a un cluster di database Aurora MySQL con SSL, consulta Connessioni TLS a cluster di database Aurora MySQL.
-
Esegui la procedura archiviata mysql.rds_import_binlog_ssl_material per importare le informazioni SSL nel cluster di database Aurora MySQL.
Per il parametro
ssl_material_valueinserisci le informazioni dai file in formato .pem per il cluster di database Aurora MySQL nel payload JSON corretto.L'esempio seguente importa le informazioni SSL in un cluster di database Aurora MySQL. Nei file in formato .pem, il codice del corpo è in genere più lungo del codice del corpo riportato nell'esempio.
call mysql.rds_import_binlog_ssl_material( '{"ssl_ca":"-----BEGIN CERTIFICATE----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END CERTIFICATE-----\n","ssl_cert":"-----BEGIN CERTIFICATE----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END CERTIFICATE-----\n","ssl_key":"-----BEGIN RSA PRIVATE KEY----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END RSA PRIVATE KEY-----\n"}');Per ulteriori informazioni, consultare mysql.rds_import_binlog_ssl_material e Connessioni TLS a cluster di database Aurora MySQL.
Nota
Dopo aver eseguito la procedura, i segreti vengono archiviati in file. Per eliminare i file in un secondo momento, puoi eseguire la stored procedure mysql.rds_remove_binlog_ssl_material.
Sincronizza il cluster database Amazon Aurora MySQL con il database MySQL esterno
Puoi sincronizzare i cluster database Amazon Aurora MySQL con il database MySQL utilizzando la replica.
Per sincronizzare il cluster database Aurora MySQL con il database MySQL utilizzando la replica
-
Assicurati che il file/etc/my.cnf per il database MySQL esterno contenga le voci pertinenti.
Se la replica crittografata non è necessaria, assicurati che il database MySQL esterno venga avviato con i bin binari (binlog) abilitati e SSL disabilitato. Di seguito sono riportate le voci pertinenti nel file/etc/my.cnf per i dati non crittografati.
log-bin=mysql-bin server-id=2133421 innodb_flush_log_at_trx_commit=1 sync_binlog=1Se la replica crittografata è necessaria, assicurati che il database MySQL esterno venga avviato con SSL e i binlog abilitati. Le voci nel file/etc/my.cnf includono le posizioni dei file.pem per il server di database MySQL.
log-bin=mysql-bin server-id=2133421 innodb_flush_log_at_trx_commit=1 sync_binlog=1 # Setup SSL. ssl-ca=/home/sslcerts/ca.pem ssl-cert=/home/sslcerts/server-cert.pem ssl-key=/home/sslcerts/server-key.pemPuoi verificare l'abilitazione di SSL utilizzando il seguente comando.
mysql>show variables like 'have_ssl';L'output deve essere simile a quanto segue.
+~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ | Variable_name | Value | +~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ | have_ssl | YES | +~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ 1 row in set (0.00 sec) -
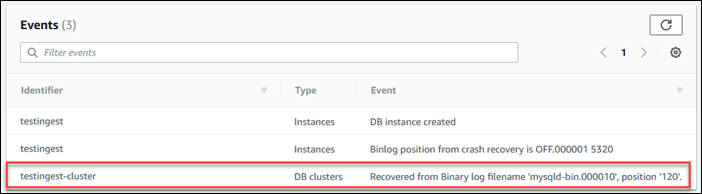
Determina la posizione iniziale del log binario per la replica: Specifichi la posizione per avviare la replica in una fase successiva.
Usando il Console di gestione AWS
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel riquadro di navigazione selezionare Events (Eventi).
-
Nell'elenco Events (Eventi), annota la posizione nell'evento Recovered from Binary log filename (Recuperato dal nome di file del log binario).
Utilizzando il AWS CLI
È inoltre possibile ottenere il nome e la posizione del file binlog utilizzando il comando AWS CLI describe-events. Di seguito viene illustrato un esempio del comando
describe-events.PROMPT> aws rds describe-eventsNell'output, identifica l'evento che mostra la posizione del binlog.
-
Durante la connessione al database esterno MySQL, crea un utente da utilizzare per la replica. Questo account viene utilizzato unicamente per la replica e deve essere limitato al dominio personale per aumentare la sicurezza. Di seguito è riportato un esempio.
mysql>CREATE USER '<user_name>'@'<domain_name>' IDENTIFIED BY '<password>';L'utente richiede i privilegi
REPLICATION CLIENTeREPLICATION SLAVE. Concedi questi privilegi all'utente.GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO '<user_name>'@'<domain_name>';Se non hai bisogno di utilizzare la replica crittografata, richiedi le connessioni SSL per l'utente replica. Ad esempio, puoi usare la seguente istruzione per richiedere connessioni SSL per l'account utente
<user_name>GRANT USAGE ON *.* TO '<user_name>'@'<domain_name>' REQUIRE SSL;Nota
Se
REQUIRE SSLnon è incluso, la connessione di replica potrebbe ridiventare una connessione non crittografata. -
Nella console Amazon RDS, aggiungi l'indirizzo IP del server che ospita il database MySQL esterno al gruppo di sicurezza VPC per il cluster di database Aurora MySQL. Per ulteriori informazioni sulla modifica di un gruppo di sicurezza VPC, consulta Gruppi di sicurezza per il VPC nella Guida per l'utente di Amazon Virtual Private Cloud.
Potrebbe anche essere necessario configurare la rete locale per consentire le connessioni dall'indirizzo IP del cluster database Aurora MySQL, affinché possa comunicare con il database MySQL esterno. Per individuare l'indirizzo IP del cluster di database Aurora MySQL, utilizzare il comando
host.host<db_cluster_endpoint>Il nome host è il nome DNS dell'endpoint del cluster di database Aurora MySQL.
-
Abilita la replica del log binario eseguendo la stored procedure mysql.rds_reset_external_master (Aurora MySQL versione 2) o mysql.rds_reset_external_source (Aurora MySQL versione 3). Questa procedura archiviata ha la seguente sintassi.
CALL mysql.rds_set_external_master ( host_name , host_port , replication_user_name , replication_user_password , mysql_binary_log_file_name , mysql_binary_log_file_location , ssl_encryption ); CALL mysql.rds_set_external_source ( host_name , host_port , replication_user_name , replication_user_password , mysql_binary_log_file_name , mysql_binary_log_file_location , ssl_encryption );Per informazioni sui parametri, consulta mysql.rds_reset_external_master (Aurora MySQL versione 2) e mysql.rds_reset_external_source (Aurora MySQL versione 3).
Per
mysql_binary_log_file_nameemysql_binary_log_file_location, utilizza la posizione nell'evento Recovered from Binary log filename (Recuperato dal nome di file del log binario) che hai annotato in precedenza.Se i dati nel cluster di database Aurora MySQL non sono crittografati, il parametro
ssl_encryptiondeve essere impostato su0. Se i dati sono crittografati, il parametrossl_encryption, deve essere impostato su1.L'esempio seguente esegue la procedura per un cluster database Aurora MySQL che ha dati crittografati.
CALL mysql.rds_set_external_master( 'Externaldb.some.com', 3306, 'repl_user'@'mydomain.com', 'password', 'mysql-bin.000010', 120, 1); CALL mysql.rds_set_external_source( 'Externaldb.some.com', 3306, 'repl_user'@'mydomain.com', 'password', 'mysql-bin.000010', 120, 1);Questa procedura archiviata imposta i parametri che il cluster database Aurora MySQL utilizza per la connessione al database MySQL esterno e per leggere il log binario. Se i dati sono crittografati, scarica anche il certificato autorità certificato SSL, il certificato client e la chiave client nel disco locale.
-
Avvia la replica del log binario eseguendo la procedura archiviata mysql.rds_start_replication.
CALL mysql.rds_start_replication; -
Monitora quanto è indietro il cluster database Aurora MySQL rispetto al database primario MySQL di replica. A questo scopo, esegui la connessione al cluster database Aurora MySQL ed esegui il comando seguente.
Aurora MySQL version 2: SHOW SLAVE STATUS; Aurora MySQL version 3: SHOW REPLICA STATUS;Nell'output del comando, il campo
Seconds Behind Masterindica quanto è indietro il cluster database Aurora MySQL rispetto al primario MySQL. Quando questo valore corrisponde a0(zero), il cluster database Aurora MySQL è aggiornato rispetto al primario e puoi passare alla fase successiva per interrompere la replica. -
Esegui la connessione al database primario MySQL di replica e interrompi la replica. Per eseguire questa operazione, chiama la stored procedure mysql.rds_stop_replication.
CALL mysql.rds_stop_replication;
