Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un cluster database Aurora headless in una regione secondaria
Sebbene un database globale Aurora richieda almeno un cluster Aurora DB secondario in un cluster Regione AWS diverso da quello primario, è possibile utilizzare una configurazione headless per il cluster secondario. Un cluster database Aurora secondario headless è un cluster senza un'istanza database. Questo tipo di configurazione può ridurre le spese per un database globale Aurora. In un cluster database Aurora, il calcolo e l’archiviazione vengono disaccoppiati. Senza l'istanza database, non viene addebitato alcun costo per il calcolo, solo per lo storage. Se è configurato correttamente, il volume di archiviazione di un secondario headless viene mantenuto sincronizzato con il cluster database Aurora primario.
Puoi aggiungere il cluster secondario come si fa normalmente durante la creazione di un database globale Aurora. Se stai creando tutti i cluster nel database globale, segui la procedura riportata in Creazione di un database globale Amazon Aurora. Se disponi già di un cluster di database da utilizzare come cluster primario, segui la procedura riportata in Aggiungere un Regione AWS a un database globale di Amazon Aurora.
Dopo che il cluster di database Aurora primario inizia la replica nel secondario, è possibile eliminare l’istanza database Aurora di sola lettura dal cluster di database Aurora secondario. Questo cluster secondario è ora considerato “headless” perché non dispone più dell'istanza DB. Anche in assenza di istanze database Aurora, Aurora mantiene la sincronizzazione tra il volume di archiviazione e il cluster di database Aurora primario.
avvertimento
Con Aurora PostgreSQL, per creare un cluster headless in un secondario, usa l'API o RDS per aggiungere il secondario Regione AWS. AWS CLI Regione AWS Salta il passaggio per creare l'istanza DB di lettura per il cluster secondario. Attualmente, la creazione di un cluster headless non è supportata nella console RDS. Per l'utilizzo delle procedure CLI e API, consulta Aggiungere un Regione AWS a un database globale di Amazon Aurora.
Se il database globale utilizza una versione del motore Aurora PostgreSQL inferiore a 13.4, 12.8 o 11.13, la creazione di un’istanza database di lettura in una Regione secondaria e la successiva eliminazione potrebbero causare un problema di vacuum di Aurora PostgreSQL nell’istanza database di scrittura della Regione primaria. Se si verifica questo problema, riavviare l'istanza DB di scrittura della regione principale dopo aver eliminato l'istanza DB di lettura della regione secondaria.
Per aggiungere un cluster database Aurora secondario headless al database globale Aurora
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel pannello di navigazione di Console di gestione AWS, scegli Database.
-
Scegliere il database globale Aurora che richiede un cluster di database Aurora secondario. Assicurarsi che il cluster di database Aurora primario sia
Available. -
Per Azioni, scegli Aggiungi AWS regione.
-
Nella pagina Aggiungi una regione, scegli la secondaria Regione AWS.
Non puoi sceglierne uno Regione AWS che abbia già un cluster Aurora DB secondario per lo stesso database globale Aurora. Inoltre, non può essere la stessa regione del cluster database Aurora primario.
-
Completa i campi rimanenti per il cluster Aurora secondario nel nuovo. Regione AWS Queste sono le stesse opzioni di configurazione di qualsiasi istanza del cluster database Aurora.
Per un database globale Aurora basato su Aurora MySQL–, ignora l'opzione Abilita inoltro in scrittura della replica in lettura. Questa opzione non ha alcuna funzione dopo aver eliminato l'istanza del lettore.
Scegli Aggiungi AWS regione. Dopo aver aggiunto la regione al database globale di Aurora, puoi vederla nell'elenco dei database Console di gestione AWS come mostrato nello screenshot.

Controlla lo stato del cluster Aurora DB secondario e della relativa istanza di lettura prima di continuare, utilizzando Console di gestione AWS o il. AWS CLI Esempio:
$aws rds describe-db-clusters --db-cluster-identifiersecondary-cluster-id--query '*[].[Status]' --output textIl passaggio dello stato di un cluster database Aurora secondario appena aggiunto da
creatingaavailablepuò richiedere alcuni minuti. Quando il cluster database Aurora è disponibile, è possibile eliminare l'istanza di lettura.Seleziona l'istanza di lettura nel cluster database Aurora secondario, quindi scegli Elimina.

Dopo aver eliminato l'istanza di lettura, il cluster secondario rimane parte del database globale Aurora. Non ha alcuna istanza associata, come illustrato di seguito.
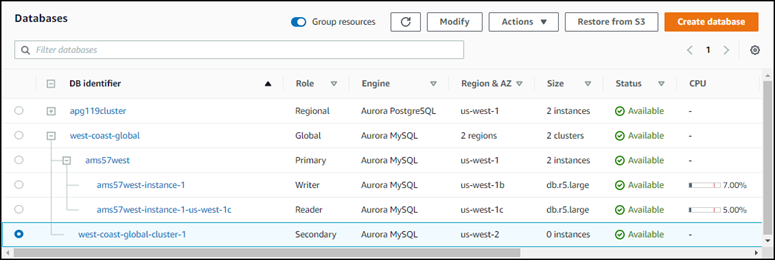
Puoi utilizzare questo cluster di database Aurora secondario headless per ripristinare manualmente il database globale Amazon Aurora da un'interruzione non pianificata nella Regione AWS principale se si verifica un'interruzione del servizio.
