Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo di Database globale Amazon Aurora
Con la funzionalità Database globale Amazon Aurora, puoi configurare più cluster di database Aurora che si estendono su più cluster. Regioni AWS Aurora sincronizza automaticamente tutte le modifiche apportate nel cluster di database primario con uno o più cluster secondari. Un database globale Aurora ha un cluster di database primario in una Regione e fino a dieci cluster di database secondari in Regioni differenti. Questa configurazione multi-Regione consente un ripristino di emergenza rapido in caso di eventuali interruzioni che potrebbero interessare un’intera Regione AWS. La disponibilità di una copia completa di tutti i dati in più aree geografiche consente inoltre operazioni di lettura a bassa latenza per le applicazioni che si connettono da località molto diverse in tutto il mondo.
Argomenti
Panoramica di Database globale Amazon Aurora
Utilizzando la funzionalità Database globale Amazon Aurora, puoi eseguire le applicazioni distribuite globalmente utilizzando un singolo database Aurora che si sviluppa su più Regioni AWS.
Un database globale Aurora è costituito da un database primario Regione AWS in cui vengono scritti i dati e fino a 10 secondari di sola lettura. Regioni AWS Emetti operazioni di scrittura al cluster di database primario nella Regione AWS primaria. Il modo più comodo per farlo è connettersi all’endpoint di scrittura del database globale Aurora, che punta sempre al cluster di database primario, anche dopo uno switchover o un failover verso un altro Regione AWS. Dopo ogni operazione di scrittura, Aurora replica i dati sul secondario Regioni AWS utilizzando un'infrastruttura dedicata, con una latenza in genere inferiore a un secondo.
Nel diagramma seguente, è possibile trovare un esempio di database globale Aurora che si estende su due. Regioni AWS
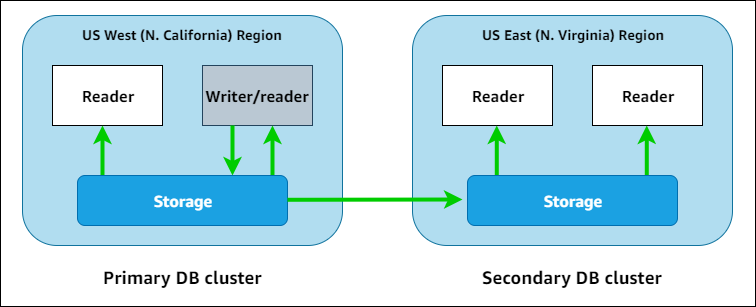
Puoi aumentare verticalmente le dimensioni del cluster secondario in maniera indipendente aggiungendo una o più istanze di lettura Aurora per servire carichi di lavoro di sola lettura. È possibile utilizzare Aurora serverless per le istanze di lettura per un dimensionamento ancora più granulare e flessibile.
Solo il cluster primario eseguire operazioni di scrittura. I client che eseguono operazioni di scrittura si connettono all’endpoint di scrittura del database globale Aurora, che punta sempre all’istanza di scrittura di database, che punta sempre all’istanza database del cluster di database. Come illustrato nel diagramma, Aurora utilizza il volume di archiviazione del cluster e non il motore di database per una replica rapida e con sovraccarico ridotto. Per ulteriori informazioni, consulta Panoramica dell'archiviazione di Amazon Aurora.
Il database globale Aurora è progettato per le applicazioni con una presenza globale. I cluster DB secondari multipli di sola lettura Regioni AWS aiutano a ottimizzare le operazioni di lettura più vicine agli utenti delle applicazioni. Attraverso la funzionalità di inoltro di scrittura, è possibile anche configurare un database globale in modo che i cluster secondari inviino i dati le richieste di scrittura al primario. Per ulteriori informazioni, consulta Utilizzo dell'inoltro di scrittura in un database globale Amazon Aurora.
Un database globale Aurora supporta due diverse operazioni per modificare la Regione del cluster di database primario, a seconda dello scenario: switchover del Database globale Aurora e failover globale del database Aurora.
-
Per le procedure operative pianificate come la rotazione delle Regioni, utilizza il meccanismo di switchover (precedentemente chiamato “failover pianificato gestito”). Con questa funzionalità, puoi rilocare il cluster primario di un Database globale Aurora integro in una delle Regioni secondarie senza alcuna perdita di dati. Per ulteriori informazioni, consulta Esecuzione di switchover per database globali Amazon Aurora.
-
Per ripristinare il database globale Aurora dopo un’interruzione nella Regione primaria, utilizza il meccanismo di failover. Con questa funzionalità, esegui il failover del cluster di database primario in un’altra Regione (failover tra Regioni). Per ulteriori informazioni, consulta Esecuzione di failover gestiti per database globali Aurora.
Vantaggi di Database globale Amazon Aurora
Utilizzando Database globale Aurora, è possibile ottenere i seguenti vantaggi:
Letture globali con latenza locale: le aziende che hanno uffici in tutto il mondo possono utilizzare Database globale Aurora per mantenere aggiornate le principali fonti di informazioni nella Regione AWS primaria. Gli uffici nelle altre regioni possono accedere alle informazioni nella propria regione, con una latenza locale.
Cluster di database Aurora secondari scalabili: è possibile dimensionare i cluster secondari aggiungendo più istanze di sola lettura a una Regione AWS secondaria. Il cluster secondario è di sola lettura, quindi può supportare fino a 16 istanze database di sola lettura, anziché il limite abituale di 15 per un singolo cluster Aurora.
Replica rapida dai cluster di database Aurora primari a quelli secondari – La replica eseguita da un database globale Aurora ha un impatto ridotto sulle prestazioni del cluster di database primario. Le risorse delle istanze database sono totalmente dedicate a servire carichi di lavoro di lettura e scrittura delle applicazioni.
Ripristino dalle Region-wide interruzioni: i cluster secondari consentono di rendere disponibile un database globale Aurora in un nuovo database primario Regione AWS più rapidamente (RTO inferiore) e con una minore perdita di dati (RPO inferiore) rispetto alle soluzioni di replica tradizionali.
Disponibilità di regioni e versioni
Il supporto e la disponibilità di questa funzionalità variano a seconda delle versioni specifiche di ciascun motore di database Aurora e tra Regioni AWS. Per ulteriori informazioni sulla disponibilità di versioni e Regioni con database globali Aurora, consulta Regioni e motori di database supportati per i database globali Aurora.
Limitazioni di Database globale Amazon Aurora
Le seguenti limitazioni si applicano attualmente ai database globali Aurora:
Aurora Global Database è disponibile in alcune Regioni AWS e per versioni specifiche di Aurora MySQL e Aurora PostgreSQL. Per ulteriori informazioni, consulta Regioni e motori di database supportati per i database globali Aurora.
I database globali Aurora hanno determinati requisiti di configurazione per le classi di istanza database Aurora supportate, il numero massimo di Regioni AWS e così via. Per ulteriori informazioni, consulta Requisiti di configurazione di un database globale Amazon Aurora.
Per Aurora MySQL con compatibilità MySQL 5.7, gli switchover di Database globale Aurora richiedono Aurora versione 2.09.1 o una versione secondaria superiore.
-
È possibile eseguire uno switchover o un failover gestito tra Regioni su un database globale Aurora solo se i cluster di database primario e secondario hanno la stessa versione principale e secondaria e le stesse versioni di motore. A seconda del motore e delle versioni del motore, può essere necessario che i livelli di patch siano identici oppure possono essere diversi. Per un elenco dei motori e delle versioni dei motori che consentono queste operazioni tra cluster primari e secondari con diversi livelli di patch, consulta Compatibilità del livello di patch per switchover e failover gestiti tra regioni. Se le versioni del motore richiedono identici livelli di patch, puoi eseguire il failover manualmente seguendo i passaggi indicati in Esecuzione di failover manuali per i Database globali Aurora.
Database globale Aurora attualmente non supporta le seguenti funzionalità di Aurora:
-
Backtrack in Aurora
-
Per le limitazioni all’utilizzo della funzionalità Server proxy per RDS con i database globali Aurora, consulta Limitazioni di Server proxy per RDS con i database globali.
L’aggiornamento automatico della versione secondaria non si applica ai cluster Aurora MySQL e Aurora PostgreSQL che fanno parte di un database globale. Si noti che questa impostazione può essere specificata per un'istanza database che fa parte di un cluster di database globale, ma l'impostazione non ha effetto.
Database globale Aurora attualmente non supporta il dimensionamento automatico per i cluster di database secondari.
Per utilizzare Database Activity Streams (DAS) su Database globale Aurora che esegue Aurora MySQL 5.7, la versione del motore deve essere la versione 2.08 o successiva. Per informazioni su DAS, consulta Monitoraggio Amazon Aurora con Database Activity Streams.
-
Le seguenti limitazioni si applicano attualmente a Database globale Aurora:
Non è possibile applicare un gruppo di parametri personalizzato al cluster di database globale mentre si esegue un aggiornamento della versione principale del database globale Aurora. È possibile creare i gruppi di parametri personalizzati in ciascuna Regione del cluster globale e applicarli manualmente ai cluster regionali dopo l'aggiornamento.
-
Con un database globale Aurora basato su Aurora MySQL, non puoi eseguire un aggiornamento locale da Aurora MySQL versione 2 alla versione 3 se il parametro
lower_case_table_namesè attivato. Per ulteriori informazioni sui metodi disponibili all'uso, consulta Aggiornamenti di una versione principale. Con Database globale Aurora basato su Aurora PostgreSQL, non è possibile eseguire un aggiornamento della versione principale del motore Aurora PostgreSQL DB se la funzionalità Obiettivo del punto di ripristino (RPO) è attivata. Per ulteriori informazioni sulla caratteristica RPO, consulta Gestione degli RPO per database globali basati su Aurora PostgreSQL–.
Con Database globale Aurora basato su Aurora MySQL, non è possibile eseguire un aggiornamento della versione secondaria dalla versione 3.01 o 3.02 alla versione 3.03 o successiva di Aurora MySQL utilizzando il processo standard. Per informazioni dettagliate sul processo da usare, consulta Aggiornamento di Aurora MySQL modificando la versione del motore.
Per informazioni sull’aggiornamento di Database globale Aurora, consulta Aggiornamento di un database globale Amazon Aurora.
Non è possibile interrompere o avviare i cluster di database Aurora nel database globale in modo individuale. Per ulteriori informazioni, consulta Avvio e arresto di un cluster di database Amazon Aurora.
Le istanze database di lettura Aurora collegate al cluster di database Aurora secondario possono essere riavviate in determinate circostanze. Se l'istanza Writer DB principale Regione AWS viene riavviata o failover, vengono riavviate anche le istanze DB Reader nelle regioni secondarie. Il cluster secondario non sarà quindi disponibile fino a quando tutte le istanze database di lettura al suo interno non sono nuovamente sincronizzate con l’istanza di scrittura del cluster di database primario. Il comportamento del cluster primario durante il riavvio o il failover è uguale a quello di un singolo cluster di database non globale. Per ulteriori informazioni, consulta Replica con Amazon Aurora.
Prima di apportare modifiche al cluster di database primario, assicurarsi di comprendere l’impatto sul database globale. Per ulteriori informazioni, consulta Ripristino di un database globale Amazon Aurora da un'interruzione non pianificata.
Aurora Global Database attualmente non supporta lo
inaccessible-encryption-credentials-recoverablestato in cui Amazon Aurora perde l'accesso alla chiave per AWS KMS il cluster DB. In questi casi, il cluster database crittografato entra nello stato terminaleinaccessible-encryption-credentials. Per ulteriori informazioni su questi stati, consulta Visualizzazione dello stato del cluster del DB.-
Secrets Manager non supporta Database globale Aurora. Quando aggiungi una Regione a un database globale, è necessario prima disattivare l’integrazione di Secrets Manager per l’istanza database.
Non è possibile rinominare un cluster Aurora DB regionale mentre è membro di un database globale Aurora. Tuttavia, è possibile modificare l'identificatore globale del cluster e gli identificatori delle singole istanze DB all'interno di un cluster membro.
-
I cluster di database basati su Aurora PostgreSQL che utilizzano un database globale Aurora hanno le seguenti limitazioni:
La gestione della cache del cluster non è supportata per i cluster di database secondari Aurora PostgreSQL che fanno parte dei database globali Aurora.
-
Se il cluster di database primario del database globale è basato su una replica di un’istanza PostgreSQL Amazon RDS, non è possibile creare un cluster secondario. Non tentate di creare un file secondario da quel cluster utilizzando l'operazione Console di gestione AWS AWS CLI, the o l'
CreateDBClusterAPI. I tentativi di eseguire questa operazione scadono e il cluster secondario non viene creato.
Per i database globali si consiglia di creare cluster di database secondari utilizzando la stessa versione del motore di database Aurora del cluster primario. Per ulteriori informazioni, consulta Creazione di un database globale Amazon Aurora.
