Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitoraggio di un database globale Amazon Aurora
Quando si creano i cluster di database Aurora che costituiscono il database globale Aurora, è possibile scegliere molte opzioni che consentono di monitorare le prestazioni del cluster di database. Queste opzioni includono:
Amazon RDS Performance Insights: abilita lo schema delle prestazioni nel motore di database Aurora sottostante. Per ulteriori informazioni su Performance Insights e database globali Aurora, consulta Monitoraggio di un database globale Amazon Aurora con Amazon Performance Insights RDS.
Monitoraggio avanzato: genera metriche per l'utilizzo di processi o thread su. CPU Per ulteriori informazioni sul monitoraggio avanzato, consulta Monitoraggio dei parametri del sistema operativo con il monitoraggio avanzato.
Amazon CloudWatch Logs: pubblica tipi di log specifici in Logs. CloudWatch I log degli errori vengono pubblicati per impostazione predefinita, ma è possibile scegliere altri log specifici per il motore di database Aurora.
Per i cluster Aurora DB SQL basati su Aurora My, è possibile esportare il registro di controllo, il registro generale e il registro delle query lente.
Per i cluster Aurora DB SQL basati su Aurora Postgre, è possibile esportare il registro Postgre. SQL
Per i database globali SQL basati su Aurora My, è possibile eseguire query su
information_schematabelle specifiche per verificare lo stato del database globale Aurora e delle relative istanze. Per scoprire come, consulta Monitoraggio dei database globali SQL basati su Aurora My.Per i database globali SQL basati su Aurora Postgre, è possibile utilizzare funzioni specifiche per controllare lo stato del database globale di Aurora e delle relative istanze. Per scoprire come, consulta Monitoraggio dei database globali basati su Aurora SQL Postgre.
La seguente schermata mostra alcune delle opzioni disponibili nella scheda Monitoraggio di un cluster di database Aurora primario in un database globale Aurora.
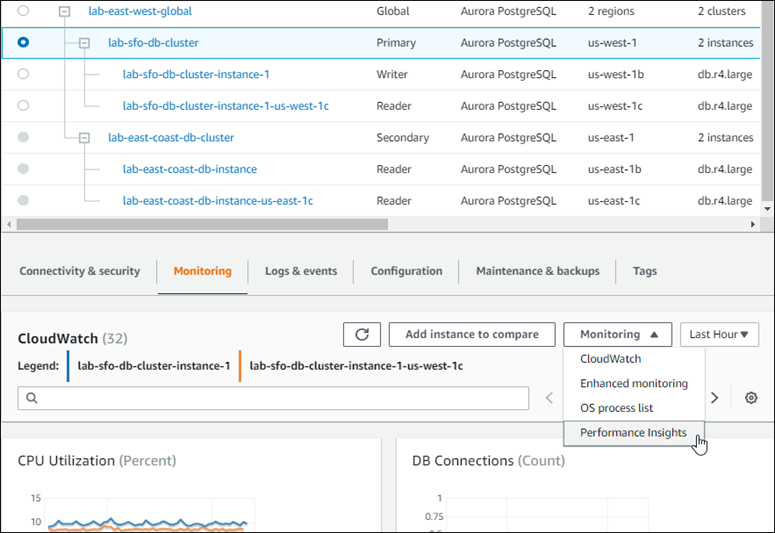
Per ulteriori informazioni, consulta Monitoraggio dei parametri in un cluster di database Amazon Aurora.
Monitoraggio di un database globale Amazon Aurora con Amazon Performance Insights RDS
Puoi usare Amazon RDS Performance Insights per i tuoi database globali Aurora. È possibile abilitare questa funzionalità singolarmente, per ogni cluster di database Aurora nel database globale Aurora. A tale scopo, scegliere Enable Performance Insights (Abilita Performance Insights) nella sezione Additional configuration (Configurazioni aggiuntive) della pagina Crea database. In alternativa, una volta operativi, è possibile modificare i cluster di database Aurora per utilizzare questa funzionalità. È possibile abilitare o disattivare Performance Insights per ciascun cluster che fa parte del database globale Aurora.
I report creati da Performance Insights si applicano a ciascun cluster del database globale. Quando aggiungi un nuovo secondario Regione AWS a un database globale Aurora che utilizza già Performance Insights, assicurati di abilitare Performance Insights nel cluster appena aggiunto. Non eredita l'impostazione Performance Insights dal database globale esistente.
È possibile passare da un'istanza DB a un database globale Regioni AWS mentre si visualizza la pagina Performance Insights. Tuttavia, potresti non visualizzare le informazioni sulle prestazioni subito dopo la commutazione Regioni AWS. Sebbene le istanze DB possano avere nomi identici in ognuna Regione AWS, il Performance Insights associato URL è diverso per ogni istanza DB. Dopo la commutazione Regioni AWS, scegli nuovamente il nome dell'istanza DB nel riquadro di navigazione Performance Insights.
Per le istanze database associate a un database globale, i fattori che influiscono sulle prestazioni potrebbero essere diversi in ciascuna Regione AWS. Ad esempio, le istanze DB di ciascuna istanza Regione AWS potrebbero avere una capacità diversa.
Per ulteriori informazioni sull'utilizzo di Performance Insights, consulta Monitoraggio del carico del DB con Performance Insights su Amazon Aurora.
Monitoraggio dei database globali Aurora con i flussi di attività di database
Con i flussi di attività del database è possibile monitorare e impostare gli allarmi per l'attività di audit nei cluster database del database globale. Avvia un flusso di attività del database su ciascun cluster database separatamente. Ciascun cluster fornisce i dati di audit al proprio flusso Kinesis all'interno della propria Regione AWS. Per ulteriori informazioni, consulta Monitoraggio di Amazon Aurora tramite i flussi di attività del database.
Monitoraggio dei database globali SQL basati su Aurora My
Per visualizzare lo stato di un database globale SQL basato su Aurora My, interroga le tabelle information_schema.aurora_global_db_status andinformation_schema.aurora_global_db_instance_status.
Nota
Le information_schema.aurora_global_db_instance_status tabelle information_schema.aurora_global_db_status e sono disponibili solo con i database globali di Aurora My SQL 3.04.0 e versioni successive.
Per monitorare un database globale SQL basato su Aurora My
-
Connect all'endpoint del cluster primario del database globale utilizzando un SQL client My. Per ulteriori informazioni su come connettersi, consulta Connessione al database globale di Amazon Aurora.
-
Esegui la query sulla tabella
information_schema.aurora_global_db_statusin un comando mysql per elencare i volumi primari e secondari. Questa query restituisce i tempi di ritardo dei cluster database secondari del database globale, come nell'esempio seguente.mysql> select * from information_schema.aurora_global_db_status;AWS_REGION | HIGHEST_LSN_WRITTEN | DURABILITY_LAG_IN_MILLISECONDS | RPO_LAG_IN_MILLISECONDS | LAST_LAG_CALCULATION_TIMESTAMP | OLDEST_READ_VIEW_TRX_ID -----------+---------------------+--------------------------------+------------------------+---------------------------------+------------------------ us-east-1 | 183537946 | 0 | 0 | 1970-01-01 00:00:00.000000 | 0 us-west-2 | 183537944 | 428 | 0 | 2023-02-18 01:26:41.925000 | 20806982 (2 rows)L'output include una riga per ogni cluster DB del database globale contenente le seguenti colonne:
-
AWS_REGION— In Regione AWS cui si trova questo cluster DB. Per l'elenco delle tabelle Regioni AWS per motore, vedereDisponibilità nelle regioni.
-
HIGHEST_ LSN _ WRITTEN — Il numero di sequenza di log più alto (LSN) attualmente scritto su questo cluster DB.
Un numero di sequenza di log (LSN) è un numero sequenziale univoco che identifica un record nel log delle transazioni del database. LSNssono ordinati in modo tale che un LSN valore più grande rappresenti una transazione successiva.
-
DURABILITY_ LAG _IN_ MILLISECONDS — La differenza nei valori di timestamp tra il
HIGHEST_LSN_WRITTENcluster DB secondario e ilHIGHEST_LSN_WRITTENcluster DB primario. Questo valore è sempre 0 sul cluster database primario del database globale Aurora. -
RPO_ LAG _IN_ MILLISECONDS — Il ritardo dell'obiettivo del punto di ripristino (). RPO Il RPO ritardo è il tempo necessario per COMMIT archiviare la transazione utente più recente su un cluster DB secondario dopo che è stata archiviata nel cluster DB primario del database globale Aurora. Questo valore è sempre 0 sul cluster database primario del database globale Aurora.
In termini semplici, questa metrica calcola l'obiettivo del punto di ripristino per ogni cluster Aurora My SQL DB nel database globale Aurora, ovvero la quantità di dati che potrebbero andare persi in caso di interruzione. Come nel caso del ritardo, viene misurato in termini di tempo. RPO
-
LAST_ _ LAG CALCULATION _ TIMESTAMP — Il timestamp che specifica quando i valori sono stati calcolati l'ultima volta per e.
DURABILITY_LAG_IN_MILLISECONDSRPO_LAG_IN_MILLISECONDSIl valore temporale1970-01-01 00:00:00+00indica che questo è il cluster di database primario. -
OLDEST_ _ READ VIEW _ TRX _ID — L'ID della transazione più vecchia a cui l'istanza Writer DB può eliminare.
-
-
Esegui una query sulla tabella
information_schema.aurora_global_db_instance_statusper elencare tutte le istanze database secondarie per il cluster database primario e i cluster database secondari.mysql> select * from information_schema.aurora_global_db_instance_status;SERVER_ID | SESSION_ID | AWS_REGION | DURABLE_LSN | HIGHEST_LSN_RECEIVED | OLDEST_READ_VIEW_TRX_ID | OLDEST_READ_VIEW_LSN | VISIBILITY_LAG_IN_MSEC ---------------------+--------------------------------------+------------+-------------+----------------------+-------------------------+----------------------+------------------------ ams-gdb-primary-i2 | MASTER_SESSION_ID | us-east-1 | 183537698 | 0 | 0 | 0 | 0 ams-gdb-secondary-i1 | cc43165b-bdc6-4651-abbf-4f74f08bf931 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 0 ams-gdb-secondary-i2 | 53303ff0-70b5-411f-bc86-28d7a53f8c19 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 677 ams-gdb-primary-i1 | 5af1e20f-43db-421f-9f0d-2b92774c7d02 | us-east-1 | 183537697 | 183537698 | 20806930 | 183537691 | 21 (4 rows)L'output include una riga per ogni istanza DB del database globale contenente le colonne seguenti:
-
SERVER_ID — L'identificatore del server per l'istanza DB.
-
SESSION_ID — Un identificatore univoco per la sessione corrente. Il valore di
MASTER_SESSION_IDidentifica l'istanza database di lettura (primaria). -
AWS_REGION— In Regione AWS cui si trova questa istanza DB. Per l'elenco delle tabelle Regioni AWS per motore, vedereDisponibilità nelle regioni.
-
DURABLE_ LSN — Il LSN prodotto è resistente allo stoccaggio.
-
HIGHEST_ LSN _ RECEIVED — Il valore più alto LSN ricevuto dall'istanza DB dell'istanza Writer DB.
-
OLDEST_ READ _ VIEW _ TRX _ID — L'ID della transazione più vecchia a cui l'istanza Writer DB può eliminare.
-
OLDEST_ READ _ VIEW _ LSN — La più vecchia LSN utilizzata dall'istanza DB per la lettura dallo storage.
-
VISIBILITY_ LAG _IN_ MSEC — Per i lettori del cluster DB primario, in che misura questa istanza DB è in ritardo rispetto all'istanza DB di scrittura in millisecondi. Per istanze di lettura in un cluster database secondario, il ritardo in millisecondi di questa istanza database rispetto al volume secondario.
-
Per vedere come questi valori cambiano nel tempo, considerare il seguente blocco di transazioni in cui un inserimento di tabella richiede un'ora:
mysql> BEGIN;
mysql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
mysql> COMMIT;
In alcuni casi, potrebbe esserci una disconnessione di rete tra il cluster DB primario e il cluster DB secondario dopo l'istruzione BEGIN. In tal caso, il valore _ _IN_ del cluster DB secondario inizia ad aumentare. DURABILITY LAG MILLISECONDS Alla fine dell'INSERTistruzione, il MILLISECONDS valore DURABILITY_ LAG _IN_ è di 1 ora. Tuttavia, il MILLISECONDS valore RPO_ LAG _IN_ è 0 perché tutti i dati utente salvati tra il cluster DB primario e il cluster DB secondario sono sempre gli stessi. Non appena l'COMMITistruzione viene completata, il valore RPO_ LAG MILLISECONDS _IN_ aumenta.
Monitoraggio dei database globali basati su Aurora SQL Postgre
Per visualizzare lo stato di un database globale SQL basato su Aurora Postgre, usa le funzioni and. aurora_global_db_status aurora_global_db_instance_status
Nota
Solo Aurora Postgre SQL supporta le funzioni and. aurora_global_db_status aurora_global_db_instance_status
Per monitorare un database globale basato su Aurora SQL Postgre
-
Connect all'endpoint del cluster primario del database globale utilizzando un'SQLutilità Postgre come psql. Per ulteriori informazioni su come connettersi, consulta Connessione al database globale di Amazon Aurora.
-
Utilizzare la funzione
aurora_global_db_statusin un comando psql per elencare i volumi primari e secondari. Mostra i tempi di ritardo dei cluster DB secondari del database globale.postgres=> select * from aurora_global_db_status();aws_region | highest_lsn_written | durability_lag_in_msec | rpo_lag_in_msec | last_lag_calculation_time | feedback_epoch | feedback_xmin ------------+---------------------+------------------------+-----------------+----------------------------+----------------+--------------- us-east-1 | 93763984222 | -1 | -1 | 1970-01-01 00:00:00+00 | 0 | 0 us-west-2 | 93763984222 | 900 | 1090 | 2020-05-12 22:49:14.328+00 | 2 | 3315479243 (2 rows)L'output include una riga per ogni cluster DB del database globale contenente le seguenti colonne:
-
aws_region — In cui si trova questo cluster DB Regione AWS . Per l'elenco delle tabelle per motore Regioni AWS , vedi. Disponibilità nelle regioni
-
highest_lsn_written — Il numero di sequenza di log più alto (LSN) attualmente scritto su questo cluster DB.
Un numero di sequenza di log (LSN) è un numero sequenziale univoco che identifica un record nel log delle transazioni del database. LSNssono ordinati in modo tale che un LSN valore più grande rappresenti una transazione successiva.
-
durability_lag_in_msec – La differenza di timestamp tra il numero di sequenza di log più alto scritto su un cluster DB secondario (
highest_lsn_written) e ilhighest_lsn_writtensul cluster DB primario. -
rpo_lag_in_msec — Il ritardo dell'obiettivo del punto di ripristino (). RPO Questo ritardo è la differenza di tempo tra il commit delle transazioni utente più recenti memorizzate in un cluster DB secondario e il commit delle transazioni utente più recenti memorizzate nel cluster DB primario.
-
last_lag_calculation_time – Il timestamp in cui sono stati calcolati i valori per
durability_lag_in_msecerpo_lag_in_msec. -
feedback_epoch – L'epoca utilizzata da un cluster di database secondario quando genera informazioni di standby a caldo.
Hot Standby – Si verifica quando un cluster DB può connettersi e interrogare mentre il server è in modalità di ripristino o standby. Il feedback hot standby è costituito da informazioni sul cluster DB quando è in standby. Per ulteriori informazioni, consulta Hot standby nella documentazione di Postgre.
SQL -
feedback_xmin – L'ID minimo della transazione attiva (meno recente) utilizzato da un cluster di database secondario.
-
-
Utilizzare la funzione
aurora_global_db_instance_statusper elencare tutte le istanze database secondarie sia per il cluster DB primario che per i cluster DB secondari.postgres=> select * from aurora_global_db_instance_status();server_id | session_id | aws_region | durable_lsn | highest_lsn_rcvd | feedback_epoch | feedback_xmin | oldest_read_view_lsn | visibility_lag_in_msec --------------------------------------------+--------------------------------------+------------+-------------+------------------+----------------+---------------+----------------------+------------------------ apg-global-db-rpo-mammothrw-elephantro-1-n1 | MASTER_SESSION_ID | us-east-1 | 93763985102 | | | | | apg-global-db-rpo-mammothrw-elephantro-1-n2 | f38430cf-6576-479a-b296-dc06b1b1964a | us-east-1 | 93763985099 | 93763985102 | 2 | 3315479243 | 93763985095 | 10 apg-global-db-rpo-elephantro-mammothrw-n1 | 0d9f1d98-04ad-4aa4-8fdd-e08674cbbbfe | us-west-2 | 93763985095 | 93763985099 | 2 | 3315479243 | 93763985089 | 1017 (3 rows)L'output include una riga per ogni istanza DB del database globale contenente le colonne seguenti:
-
server_id – Identificatore del server per l'istanza DB.
-
session_id – Un identificatore univoco per la sessione corrente.
-
aws_region — La cartella in cui si trova Regione AWS questa istanza DB. Per l'elenco delle tabelle per motore Regioni AWS , vedi. Disponibilità nelle regioni
-
durable_lsn — Il LSN prodotto è durevole nello stoccaggio.
-
highest_lsn_rcvd — Il valore più alto ricevuto dall'istanza DB dall'istanza DB writer. LSN
-
feedback_epoch – L'epoca utilizzata dall'istanza DB quando genera informazioni di hot standby.
Standby a caldo è quando un'istanza database può connettersi ed eseguire query mentre il server è in modalità di ripristino o standby. Il feedback hot standby consiste in informazioni sull'istanza DB quando è in hot standby. Per ulteriori informazioni, consulta la documentazione di Postgre su Hot standby. SQL
-
feedback_xmin – L'ID della transazione attiva minimo (meno recente) utilizzato dall'istanza DB.
-
oldest_read_view_lsn — Il più vecchio utilizzato dall'istanza DB per leggere dallo storage. LSN
-
visibility_lag_in_msec – Quanto questa istanza DB è in ritardo rispetto all'istanza DB di scrittura.
-
Per vedere come questi valori cambiano nel tempo, considerare il seguente blocco di transazioni in cui un inserimento di tabella richiede un'ora:
psql> BEGIN;
psql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
psql> COMMIT;In alcuni casi, potrebbe esserci una disconnessione di rete tra il cluster DB primario e il cluster DB secondario dopo l'istruzione BEGIN. In tal caso, il valore durability_lag_in_msec del cluster DB secondario inizia ad aumentare. Alla fine dell'istruzione INSERT, il valore durability_lag_in_msec è 1 ora. Tuttavia, il valore rpo_lag_in_msec è 0 perché tutti i dati utente impegnati tra il cluster DB primario e il cluster DB secondario sono ancora gli stessi. Non appena l'istruzione COMMIT viene completata, il valore rpo_lag_in_msec aumenta.
