Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice per Amazon RDS
Scopri le best practice per l'utilizzo di Amazon RDS. Man mano che vengono identificate nuove best practice, aggiorneremo questa sezione.
Argomenti
Nota
Per suggerimenti comuni per Amazon RDS, consulta Raccomandazioni da Amazon RDS.
Linee guida operative di base per Amazon RDS
Di seguito sono illustrate le linee guida operative di base e le best practice che tutti dovrebbero seguire durante l'utilizzo di Amazon RDS. Tieni presente che il contratto sul livello di servizio di Amazon RDS richiede che tu segua queste linee guida:
-
Usa i parametri per monitorare l'utilizzo della memoria, della CPU, del ritardo di replica e dello storage. Puoi configurare Amazon in modo che ti CloudWatch avvisi quando i modelli di utilizzo cambiano o quando la tua distribuzione si avvicina ai limiti di capacità. Ciò consente di mantenere le prestazioni e la disponibilità del sistema.
-
Incrementa la capacità dell'istanza database quando stai per raggiungere i limiti della capacità di storage. Avrai bisogno di memoria e storage aggiuntivi per soddisfare aumenti imprevisti della domanda delle tue applicazioni.
-
Abilita i backup automatici e configurane l'esecuzione nel momento della giornata in cui il carico di operazioni di scrittura I/O al secondo è inferiore. Questo quando un backup è meno dannoso per l'utilizzo del database.
-
Se il carico di lavoro del database richiede I/O più di quanto previsto, il ripristino dopo un failover o un errore del database sarà lento. Per aumentare la I/O capacità di un'istanza DB, esegui una o tutte le seguenti operazioni:
Esegui la migrazione a una classe di istanza DB diversa con I/O capacità elevata.
Esegui la conversione da SSD per uso generico a unità SSD Provisioned IOPS, a seconda dell'entità dell'incremento necessario. Per informazioni sui tipi di storage disponibili, consulta Tipi di storage Amazon RDS.
Se effettui la conversione allo storage Provisioned IOPS, assicurati di utilizzare anche una classe di istanza di database ottimizzata per le opzioni Provisioned IOPS. Per ulteriori informazioni sull'opzione Provisioned IOPS, consulta Storage SSD Provisioned IOPS.
Se utilizzi già lo storage Provisioned IOPS, assegna capacità di throughput ulteriore.
-
Se l'applicazione client memorizza nella cache i dati DNS (Domain Name Service) delle tue istanze di database, imposta un valore time-to-live (TTL) inferiore a 30 secondi. L'indirizzo IP sottostante di un'istanza DB può cambiare dopo un failover. La memorizzazione nella cache dei dati DNS per un periodo prolungato può causare errori di connessione. L'applicazione potrebbe tentare di connettersi a un indirizzo IP non più in uso.
-
Prova il failover per l'istanza database per capire quanto tempo impiega il processo per il caso d'uso particolare. Inoltre, garantisci che l'applicazione che accede all'istanza database è in grado di connettersi automaticamente alla nuova istanza database dopo il failover.
Suggerimenti relativi alla RAM per un'istanza di database
Una best practice per le prestazioni di Amazon RDS consiste nell'allocare RAM sufficiente in modo che il working set risieda quasi interamente nella memoria. Il working set è formato dai dati e dagli indici che vengono utilizzati spesso nell'istanza. Più utilizzi l'istanza DB, più il working set crescerà.
Per sapere se il tuo set di lavoro è quasi tutto in memoria, controlla la metrica ReadiOps (usando CloudWatch Amazon) mentre l'istanza DB è sotto carico. Il valore ReadIOPS dovrebbe essere di piccola entità e stabile. In alcuni casi, il passaggio della classe di istanza database a una classe con più RAM provoca un drastico calo di ReadIOPS. In questi casi, il set di lavoro non è completamente in memoria. Continua con l'incremento fino a quando il valore di ReadIOPS non diminuisce più drasticamente dopo un'operazione di dimensionamento o è di entità molto piccola. Per ulteriori informazioni sul monitoraggio dei parametri di un'istanza di database, consulta Visualizzazione delle metriche nella console Amazon RDS.
Mantenere aggiornate le versioni del motore di database
Aggiorna regolarmente la versione del motore di database per mantenere sicurezza, prestazioni e conformità. Amazon RDS rilascia nuove versioni minori e principali che includono patch di sicurezza, miglioramenti delle prestazioni e nuove funzionalità. L'esecuzione di un motore di database obsoleto può esporre i carichi di lavoro a vulnerabilità note, problemi di compatibilità e supporto ridotto da parte dei fornitori di database. AWS
Per ridurre al minimo le interruzioni, quando pianifichi gli aggiornamenti, considera quanto segue:
-
Esegui il test in un ambiente di staging: convalida la nuova versione in base al tuo carico di lavoro prima di aggiornare i database di produzione.
-
Usa gli aggiornamenti gestiti di Amazon RDS: abilita gli aggiornamenti automatici delle versioni secondarie per facilitare l’applicazione delle patch.
-
Pianifica gli aggiornamenti delle versioni principali: consulta le note di rilascio, verifica la compatibilità delle applicazioni e pianifica una finestra di aggiornamento controllata.
Gli aggiornamenti regolari aiutano a garantire che il database rimanga sicuro, ottimizzato e allineato alle best practice AWS .
AWS driver del database
Consigliamo la AWS suite di driver per la connettività delle applicazioni. I driver sono stati progettati per fornire supporto per tempi di switchover e failover più rapidi e per l'autenticazione con AWS Secrets Manager, AWS Identity and Access Management (IAM) e Federated Identity. I driver AWS si basano sul monitoraggio dello stato dell’istanza database e conoscono la topologia dell’istanza per determinare il nuovo writer. Questo approccio riduce i tempi di switchover e failover a meno di dieci secondi, rispetto alle decine di secondi necessari per i driver open source.
Con l'introduzione di nuove funzionalità di servizio, l'obiettivo della AWS suite di driver è disporre di un supporto integrato per queste funzionalità di servizio.
Per ulteriori informazioni, consulta Connessione alle istanze DB con i driver AWS.
Utilizzo del monitoraggio avanzato per identificare problemi del sistema operativo
Quando il monitoraggio avanzato è abilitato, Amazon RDS fornisce parametri in tempo reale per il sistema operativo (OS) su cui viene eseguita l'istanza database. È possibile visualizzare le metriche per l'istanza DB utilizzando la console. Puoi anche utilizzare l'output JSON di Enhanced Monitoring di Amazon CloudWatch Logs in un sistema di monitoraggio a tua scelta. Per ulteriori informazioni su Enhanced Monitoring, consult Monitoraggio dei parametri del sistema operativo con il monitoraggio avanzato.
Utilizzo di parametri per identificare problemi a livello di prestazioni
Per identificare problemi a livello di prestazioni causati da risorse insufficienti e altri colli di bottiglia comuni, puoi monitorare i parametri disponibili per l'istanza di database Amazon RDS.
Visualizzazione dei parametri relativi alle prestazioni
Dovresti monitorare regolarmente i parametri relativi alle prestazione per osservare i valori medi, massimi e minimi per vari intervalli di tempo. Ciò ti consente di identificare quando le prestazioni subiscono un calo. Puoi anche impostare CloudWatch allarmi Amazon per determinate soglie metriche in modo da essere avvisato se vengono raggiunte.
Per risolvere i problemi relativi alle prestazioni, è importante comprendere le prestazioni di base del sistema. Quando configuri un'istanza database e la esegui con un carico di lavoro tipico, acquisisci i valori medi, massimi e minimi di tutte le metriche delle prestazioni. Puoi farlo a diversi intervalli (ad esempio, un'ora, 24 ore, una settimana, due settimane) e ti permette di avere un quadro dei valori normali. Ciò aiuta anche a effettuare confronti delle attività durante le ore di punta e non di punta. Puoi quindi utilizzare queste informazioni per identificare quando le prestazioni scendono al di sotto dei livelli standard.
Se utilizzi cluster Multi-AZ DB, monitora la differenza di orario tra l'ultima transazione sull'istanza DB di scrittura e l'ultima transazione applicata su un'istanza DB di lettura. Questa differenza è chiamata ritardo di replica. Per ulteriori informazioni, consulta Replica lag e cluster DB Multi-AZ.
Puoi visualizzare la combinazione di Performance Insights e CloudWatch metriche nella dashboard di Performance Insights e monitorare la tua istanza DB. Per utilizzare questa visualizzazione di monitoraggio, Performance Insights deve essere attivato per l'istanza database specifica. Per ulteriori informazioni su questa visualizzazione di monitoraggio, consulta Visualizzazione delle metriche combinate con la dashboard di Approfondimenti sulle prestazioni.
È possibile creare un report di analisi delle prestazioni per un periodo di tempo specifico e visualizzare le informazioni dettagliate identificate e i suggerimenti per risolvere i problemi. Per ulteriori informazioni, consulta Creazione di un report di analisi delle prestazioni in Approfondimenti sulle prestazioni.
Per visualizzare i parametri relativi alle prestazioni
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. Nel riquadro di navigazione, scegliere Databases (Database), quindi scegliere un'istanza database.
Selezionare Monitoring (Monitoraggio).
Il pannello di controllo fornisce le metriche sulle prestazioni. L'impostazione predefinita delle metriche consente di visualizzare le informazioni relative alle ultime tre ore.
Usa i pulsanti di impaginazione per sfogliare le metriche aggiuntive o modifica le impostazioni per visualizzare altre metriche.
Scegliere un parametro relativo alle prestazioni per regolare l'intervallo di tempo per la visualizzazione dei dati per i giorni diversi da quello corrente. È possibile modificare i valori dei campi Statistic (Statistica), Time Range (Intervallo di tempo) e Period (Periodo) in base alle informazioni che si desidera visualizzare. Ad esempio, potresti voler visualizzare i valori di picco di un parametro per ogni giorno nelle ultime due settimane. In tal caso, imposta Statistic (Statistiche) su Maximum (Massimo), Time Range (Intervallo di tempo) su Last 2 Weeks (Ultime 2 settimane) e Period (Periodo) su Day (Giorno).
È possibile anche visualizzare i parametri relativi alle prestazioni mediante CLI o API. Per ulteriori informazioni, consulta Visualizzazione delle metriche nella console Amazon RDS.
Per impostare una sveglia CloudWatch
-
Accedi a Console di gestione AWS e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel riquadro di navigazione, scegliere Databases (Database), quindi scegliere un'istanza database.
-
Scegliere Logs & events (Log ed eventi).
-
Nella sezione CloudWatch Allarmi, scegli Crea allarme.
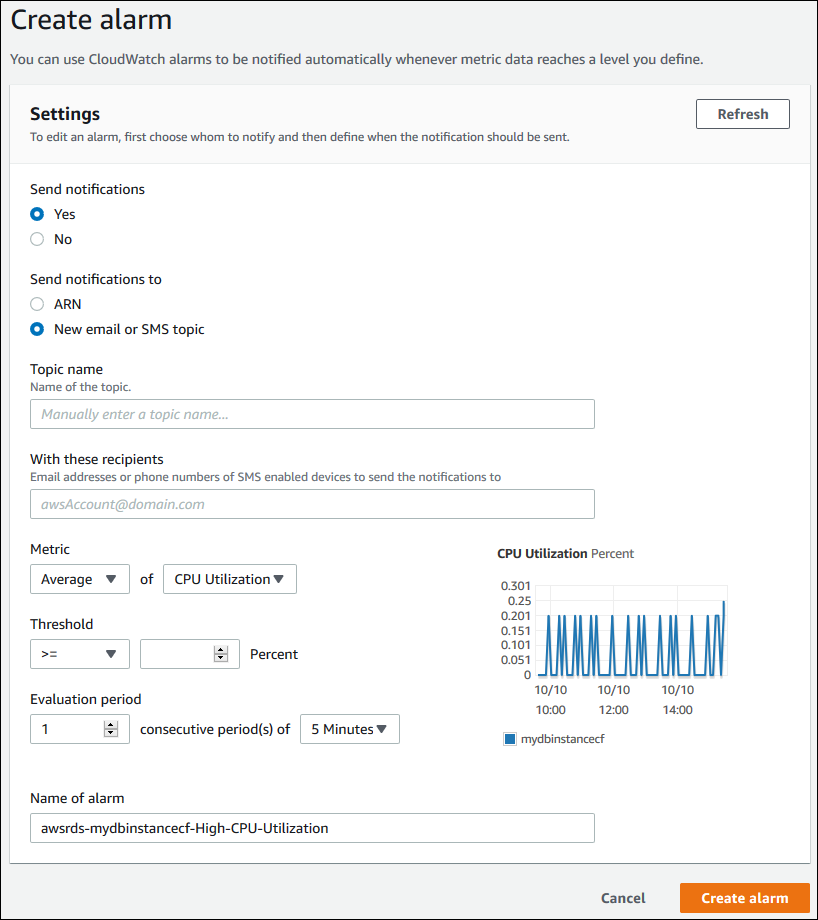
-
In Send notifications (Invia notifiche) scegliere Yes (Sì), mentre in Send notifications to (Invia notifiche a) seleziona New email or SMS topic (Nuovo argomento e-mail o SMS).
-
In Topic name (Nome argomento) digitare un nome per la notifica e in With these recipients (Con questi destinatari) digitare un elenco separato da virgole con gli indirizzi e-mail e i numeri di telefono.
-
In Metric (Parametro) scegliere la statistica e il parametro dell'allarme da impostare.
-
In Threshold (Soglia) specificare se il parametro deve essere maggiore, minore o uguale alla soglia e specificare il valore di soglia.
-
In Evaluation period (Periodo di valutazione), scegli il periodo di valutazione per l'allarme. In consecutive period(s) of (periodo/i consecutivo/i di) scegli il periodo durante il quale si deve raggiungere la soglia per attivare l'allarme.
-
Per Nome dell'allarme, inserire un nome per l'allarme.
-
Scegli Crea Alarm (Crea allarme).
L'allarme viene visualizzato nella sezione CloudWatch Allarmi.
Valutazione dei parametri relativi alle prestazioni
Un'istanza di database include diverse categorie di parametri e il modo in cui stabilire valori accettabili dipende dal parametro.
CPU
Utilizzo della CPU; percentuale di capacità di elaborazione del computer utilizzata.
Memoria
-
Memoria liberabile: quantità di RAM disponibile sull’istanza database in byte. Nella scheda Monitoring (Monitoraggio), la linea rossa indica un livello del 75% per i parametri CPU, Memory (Memoria) e Storage. Se il consumo di memoria dell'istanza supera regolarmente questa linea, significa che è necessario controllare il carico di lavoro o aggiornare l'istanza.
Utilizzo swap: quantità di spazio di swap che viene utilizzato dall’istanza database in byte.
Spazio su disco
Spazio di storage libero: quantità di spazio su disco non attualmente utilizzato dall'istanza database, in megabyte.
Input/output operazioni
IOPS di lettura, IOPS di scrittura: il numero medio di operazioni di scrittura o lettura su disco al secondo.
Latenza di lettura, Latenza di scrittura: il tempo medio per un'operazione di lettura o scrittura, in millisecondi.
Throughput di lettura, Throughput di scrittura: il numero medio di megabyte letti dal e scritti sul disco al secondo.
Profondità della coda: il numero di I/O operazioni che attendono di essere scritte o lette dal disco.
Traffico di rete
Throughput di ricezione di rete, Throughput di trasmissione di rete – La velocità del traffico di rete verso e dall'istanza database in megabyte al secondo.
Connessioni database
Connessioni DB: il numero di sessioni client connesse all'istanza database.
Per descrizioni individuali più dettagliate dei parametri disponibili relativi alle prestazioni, consultare Monitoraggio Amazon RDS metriche con Amazon CloudWatch.
In generale, i valori accettabili per i parametri relativi alle prestazioni dipendono dalla baseline e dall'attività dell'applicazione. Indagare le variazioni della baseline coerenti o che rappresentano dei trend. I seguenti sono alcuni suggerimenti su tipi di parametri specifici:
High CPU or RAM consumption (Consumo elevato di CPU o RAM): i valori elevati per il consumo di CPU o RAM potrebbero essere appropriati. Ad esempio, se sono in linea con gli obiettivi dell'applicazione (come velocità di trasmissione effettiva o simultaneità) e sono previsti.
Consumo dello spazio su disco: esamina il consumo dello spazio su disco se lo spazio usato supera costantemente l'85% dello spazio su disco totale. Verifica se è possibile eliminare dati dall'istanza o archiviare dati su un sistema diverso per liberare spazio.
Traffico di rete – Per il traffico di rete, rivolgiti al tuo amministratore di sistema per identificare il throughput previsto per la rete del dominio e la connessione Internet. Indaga il traffico di rete se il throughput è costantemente al di sotto del valore previsto.
Connessioni al database: valuta se limitare le connessioni al database se noti un numero elevato di connessioni utente e contemporaneamente un peggioramento delle prestazioni e del tempo di risposta delle istanze. Il numero ideale di connessioni utente per l'istanza di database dipende dalla classe di istanza e dalla complessità delle operazioni eseguite. Per determinare il numero di connessioni di database, associa l'istanza database a un gruppo di parametri. In questo gruppo, imposta il parametro User Connections (Connessioni utente) su un valore diverso da 0 (illimitate). Puoi utilizzare un gruppo di parametri esistente o crearne uno nuovo. Per ulteriori informazioni, consulta Gruppi di parametri per Amazon RDS.
Parametri di IOPS: poiché i valori previsti per i parametri di IOPS dipendono dalle specifiche del disco e dalla configurazione del server, usa i valori di riferimento per identificare i comportamenti tipici. Verifica se i valori sono costantemente diversi dalla baseline. Per prestazioni IOPS ottimali, assicurati che il working set tipico possa essere caricato nella memoria per ridurre al minimo le operazioni di lettura e scrittura.
In caso di problemi relativi alle metriche delle prestazioni, puoi ottimizzare le query più utilizzate e più costose per migliorare le prestazioni. Ottimizzale per vedere se così facendo riduci la pressione sulle risorse di sistema. Per ulteriori informazioni, consulta Ottimizzazione di query.
Se le query sono state ottimizzate e il problema persiste, valuta la possibilità di eseguire l'upgrade delle Classi di istanze database Amazon RDS. È possibile aggiornarlo a uno con più risorse (CPU, RAM, spazio su disco, larghezza di banda di rete, I/O capacità) correlate al problema.
Ottimizzazione di query
Uno dei modi migliori per migliorare le prestazioni di un'istanza database consiste nell'ottimizzare le query più comuni e a uso più intensivo di risorse. Puoi ottimizzarle per renderle meno costose da eseguire. Per informazioni sul miglioramento delle query, utilizzare le risorse seguenti:
-
MySQL – Consulta Optimizing SELECT statements (Ottimizzazione delle istruzioni SELECT)
nella documentazione MySQL. Per ulteriori risorse di ottimizzazione delle query, consulta MySQL performance tuning and optimization resources (Risorse di ottimizzazione delle prestazioni di MySQL) . -
Oracle – Consulta Database SQL Tuning Guide
(Guida all'ottimizzazione di database SQL) nella documentazione Oracle. -
SQL Server – Consulta Analyzing a query (Analisi di una query)
nella documentazione di Microsoft. È inoltre possibile utilizzare le viste di esecuzione, indice e gestione I/O-related dei dati (DMV) descritte in System Dynamic Management Views nella documentazione Microsoft per risolvere i problemi relativi alle query di SQL Server. Un aspetto comune dell'ottimizzazione delle query è la creazione di indici efficaci. Per potenziali miglioramenti dell'indice per l'istanza database, consulta Database Engine Tuning Advisor (Ottimizzazione guidata al motore di database)
nella documentazione di Microsoft. Per informazioni sull'utilizzo di Tuning Advisor su RDS per SQL Server, consulta Analisi del carico di lavoro del database su un'istanza database Amazon RDS for SQL Server con Tuning Advisor motore di database. -
PostgreSQL – Per informazioni su come analizzare un piano di query, consulta Using EXPLAIN (Utilizzo di EXPLAIN)
nella documentazione PostgreSQL. Puoi utilizzare queste informazioni per modificare una query o tabelle sottostanti in modo da migliorare le prestazioni della query. Per informazioni su come specificare le clausole join nella query per ottenere prestazioni ottimali, consulta Controlling the planner with explicit JOIN clauses (Controllo del pianificatore con clausole JOIN esplicite)
. -
MariaDB – Consulta Query optimizations (Ottimizzazioni delle query)
nella documentazione MariaDB.
Best practice per l'utilizzo di MySQL
Sia le dimensioni delle tabelle che il numero di tabelle in un database MySQL possono influire sulle prestazioni.
Dimensione della tabella
In genere, i vincoli del sistema operativo sulle dimensioni dei file determinano la dimensione massima effettiva della tabella per i database MySQL. Quindi, i limiti di solito non sono determinati dai vincoli interni MySQL.
In un'istanza di database MySQL, evita che le tabelle nel database diventino troppo grandi. Sebbene il limite di storage generale sia 64 TiB, i limiti di storage forniti limitano la dimensione massima di un file di tabella MySQL a 16 TiB. Suddividi le tabelle più grandi in file di dimensioni ben al di sotto del limite di 16 TiB. Ciò può anche migliorare le prestazioni e i tempi di recupero. Per ulteriori informazioni, consulta Limiti delle dimensioni dei file MySQL in Amazon RDS.
Le tabelle di dimensioni molto grandi (maggiori di 100 GB) possono influire negativamente sulle prestazioni di lettura e scrittura (incluse le istruzioni DML e in particolare le istruzioni DDL). Gli indici sulle tabelle di grandi dimensioni possono migliorare significativamente le prestazioni selezionate, ma possono anche ridurre le prestazioni delle istruzioni DML. Le istruzioni DDL, ad esempio ALTER TABLE, possono essere significativamente più lente per le tabelle di grandi dimensioni perché tali operazioni potrebbero ricostruire completamente una tabella in alcuni casi. Queste istruzioni DDL potrebbero bloccare le tabelle per la durata dell'operazione.
La quantità di memoria richiesta da MySQL per le letture e le scritture dipende dalle tabelle coinvolte nelle operazioni. È una best practice avere almeno abbastanza RAM per contenere gli indici delle tabelle utilizzate attivamente . Per trovare le dieci tabelle e gli indici più grandi in un database, utilizzare la seguente query:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Numero di tabelle
Il file system sottostante può avere un limite al numero di file che rappresentano le tabelle. Tuttavia, MySQL non ha limiti per il numero di tabelle. Ciononostante, il numero totale di tabelle nel motore di archiviazione MySQL InnoDB può contribuire al deterioramento delle prestazioni, indipendentemente dalle dimensioni di tali tabelle. Per limitare l'impatto del sistema operativo, è possibile dividere le tabelle tra più database nella stessa istanza database MySQL. In questo modo potrebbe limitare il numero di file in una directory, ma non risolverà il problema generale.
Quando c'è un deterioramento delle prestazioni a causa di un gran numero di tabelle (più di 10 mila), è causato da MySQL che lavora con i file di archiviazione, inclusa l'apertura e la chiusura. Per risolvere questo problema, è possibile aumentare la dimensione dei parametri table_open_cache e table_definition_cache. Tuttavia, aumentare i valori di tali parametri potrebbe aumentare significativamente la quantità di memoria utilizzata da MySQL e potrebbe persino utilizzare tutta la memoria disponibile. Per ulteriori informazioni, consulta Apertura e chiusura delle tabelle in MySQL
Inoltre, troppe tabelle possono influenzare significativamente il tempo di avvio di MySQL. Possono essere interessati sia un arresto e un riavvio pulito che un ripristino da arresto anomalo, specialmente nelle versioni precedenti a MySQL 8.0.
Ti consigliamo di avere meno di 10.000 tabelle totali in tutti i database in un'istanza database. Per un caso d'uso con un gran numero di tabelle in un database MySQL, consulta Un milione di tabelle in MySQL 8.0
Motore di storage
Le funzionalità di ripristino point-in-time e ripristino di snapshot di Amazon RDS per MySQL richiedono un motore di archiviazione che supporti il recupero da arresto anomalo. Queste funzionalità sono supportate solo per il motore di archiviazione InnoDB. Sebbene MySQL supporti più motori di storage con funzionalità diverse, non tutti sono ottimizzati per il recupero da arresto anomalo e per la durata dei dati. Ad esempio, il motore di archiviazione MyISAM non supporta il recupero da arresto anomalo in modo affidabile e potrebbe impedire il corretto funzionamento di un ripristino point-in-time o di snapshot. Ciò può causare la perdita o il danneggiamento dei dati quando si riavvia MySQL dopo un arresto anomalo.
InnoDB è il motore di storage consigliato e supportato per istanze di database MySQL su Amazon RDS. Inoltre, a differenza delle istanze MyISAM, è possibile effettuare la migrazione delle istanze InnoDB su Aurora. Tuttavia, MyISAM offre prestazioni migliori di InnoDB quando sono richieste solide funzionalità di ricerca full-text. Se scegli comunque di usare MyISAM con Amazon RDS, le fasi illustrate in Backup automatici con motori di storage MySQL non supportati possono essere utili in determinati scenari per la funzionalità di ripristino da uno snapshot.
Se desideri convertire le tabelle MyISAM esistenti in tabelle InnoDB, puoi utilizzare la procedura illustrata nell’articolo Converting Tables from MyISAM to InnoDB
Inoltre, il Federated Storage Engine non è attualmente supportato da Amazon RDS for MySQL.
Best practice per l'utilizzo di MariaDB
Sia le dimensioni delle tabelle che il numero di tabelle in un database MariaDB possono influire sulle prestazioni.
Dimensione della tabella
In genere, i vincoli del sistema operativo sulle dimensioni dei file determinano la dimensione massima effettiva della tabella per i database MariaDB. Quindi, i limiti di solito non sono determinati dai vincoli interni MariaDB.
In un'istanza database MariaDB, evita che le tabelle nel database diventino troppo grandi. Sebbene il limite di storage generale sia 64 TiB, i limiti di storage forniti limitano la dimensione massima di un file di tabella MariaDB a 16 TiB. Suddividi le tabelle più grandi in file di dimensioni ben al di sotto del limite di 16 TiB. Ciò può anche migliorare le prestazioni e i tempi di recupero.
Le tabelle di dimensioni molto grandi (maggiori di 100 GB) possono influire negativamente sulle prestazioni di lettura e scrittura (incluse le istruzioni DML e in particolare le istruzioni DDL). Gli indici sulle tabelle di grandi dimensioni possono migliorare significativamente le prestazioni selezionate, ma possono anche ridurre le prestazioni delle istruzioni DML. Le istruzioni DDL, ad esempio ALTER TABLE, possono essere significativamente più lente per le tabelle di grandi dimensioni perché tali operazioni potrebbero ricostruire completamente una tabella in alcuni casi. Queste istruzioni DDL potrebbero bloccare le tabelle per la durata dell'operazione.
La quantità di memoria richiesta da MariaDB per le letture e le scritture dipende dalle tabelle coinvolte nelle operazioni. È una best practice avere almeno abbastanza RAM per contenere gli indici delle tabelle utilizzate attivamente . Per trovare le dieci tabelle e gli indici più grandi in un database, utilizzare la seguente query:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Numero di tabelle
Il file system sottostante può avere un limite al numero di file che rappresentano le tabelle. Tuttavia, MariaDB non ha limiti per il numero di tabelle. Ciononostante, il numero totale di tabelle nel motore di archiviazione MariaDB InnoDB può contribuire al deterioramento delle prestazioni, indipendentemente dalle dimensioni di tali tabelle. Per limitare l'impatto del sistema operativo, è possibile dividere le tabelle tra più database nella stessa istanza database di MariaDB. In questo modo potrebbe limitare il numero di file in una directory, ma non risolve il problema generale.
Il deterioramento delle prestazioni a causa di un gran numero di tabelle (più di 10.000) è provocato da MariaDB che lavora con i file di archiviazione, compresa l'apertura e la chiusura dei file di archiviazione in MariaDB. Per risolvere questo problema, è possibile aumentare la dimensione dei parametri table_open_cache e table_definition_cache. Tuttavia, aumentando i valori di tali parametri potrebbe aumentare significativamente la quantità di memoria utilizzata da MariaDB e potrebbe anche utilizzare tutta la memoria disponibile. Per ulteriori informazioni, consulta Ottimizzazione di table_open_cache
Inoltre, troppe tabelle possono influenzare significativamente il tempo di avvio di MariaDB. Possono essere interessati sia un arresto e un riavvio pulito che un ripristino di arresto anomalo del sistema. Si consiglia di avere meno di diecimila tabelle totali in tutti i database in un'istanza database.
Motore di storage
Le funzionalità di ripristino point-in-time e ripristino di snapshot di Amazon RDS for MariaDB richiedono un motore di storage che supporti il recupero da arresto anomalo. Sebbene MariaDB supporti più motori di storage con funzionalità diverse, non tutti sono ottimizzati per il recupero da arresto anomalo e per la durata dei dati. Ad esempio, nonostante Aria sia un'alternativa a MyISAM che protegge da arresti anomali, potrebbe comunque impedire il corretto funzionamento di un ripristino point-in-time o di snapshot. Ciò può causare la perdita o il danneggiamento dei dati quando si riavvia MariaDB dopo un arresto anomalo. InnoDB è il motore di storage consigliato e supportato per istanze di database MariaDB su Amazon RDS. Se scegli comunque di usare Aria con Amazon RDS, le fasi illustrate in Backup automatici con motori di storage MariaDB non supportati possono essere utili in determinati scenari per la funzionalità di ripristino da uno snapshot.
Se desideri convertire le tabelle MyISAM esistenti in tabelle InnoDB, puoi utilizzare la procedura illustrata nell’articolo Converting Tables from MyISAM to InnoDB
Best practice per l'utilizzo di Oracle
Per informazioni sulle best practice per l'uso di Amazon RDS for Oracle, consulta la pagina relativa alle best practice per l'esecuzione di Oracle Database su Amazon Web Services.
Un workshop AWS virtuale del 2020 includeva una presentazione sull'esecuzione dei database Oracle di produzione su Amazon RDS. Un video della presentazione è disponibile qui:
Best practice per l'utilizzo di PostgreSQL
Esistono due momenti importanti in cui puoi migliorare le prestazioni con RDS per PostgreSQL: uno è quando carichi i dati in un'istanza database e l'altro è quando usi la funzione di vacuum automatico di PostgreSQL. Le sezioni seguenti illustrano alcune delle prassi suggerite per queste aree.
Per informazioni su come Amazon RDS implementa altre attività comuni del DBA PostgreSQL, consulta Attività DBA comuni per Amazon RDS for PostgreSQL.
Caricamento di dati in un'istanza di database PostgreSQL
Durante il caricamento di dati in un'istanza database Amazon RDS per PostgreSQL, dovresti modificare le impostazioni dell'istanza database e i valori del gruppo di parametri del database per consentire un'importazione più efficace dei dati nell'istanza database.
Modifica i parametri dell'istanza database come segue:
-
Disabilità i backup dell'istanza di database (imposta backup_retention su 0)
-
Disabilita Multi-AZ
Modifica il gruppo di parametri del database in modo da includere le seguenti impostazioni. Per individuare le impostazioni più efficienti per la tua istanza database è necessario testare le impostazioni dei parametri.
-
Incrementa il valore del parametro
maintenance_work_mem. Per ulteriori informazioni sui parametri relativi al consumo di risorse di PostgreSQL, consulta la documentazione di PostgreSQL. -
Incrementa il valore dei parametri
max_wal_sizeecheckpoint_timeoutper ridurre il numero di scritture nel registro WAL (write-ahead log). -
Disabilitare il parametro
synchronous_commit -
Disabilita il parametro di eliminazione automatica di PostgreSQL.
-
Verifica che tutte le tabelle che stai importando siano registrate. I dati memorizzati in tabelle non registrate potrebbero andare smarriti durante un failover. Per ulteriori informazioni, consulta CREATE TABLE UNLOGGED (CREA TABELLA NON REGISTRATA)
.
Utilizza i comandi pg_dump -Fc (compresso) o pg_restore -j (parallelo) con queste impostazioni.
Al termine dell'operazione di caricamento, ripristina le normali impostazioni dell'istanza database e dei parametri database.
Utilizzo della funzione di eliminazione automatica di PostgreSQL
La funzione di eliminazione automatica per i database di PostgreSQL è una funzione vivamente consigliata per mantenere l'integrità dell'istanza di database di PostgreSQL. La funzione di eliminazione automatica automatizza l'esecuzione dei comandi VACUUM e ANALYZE. Il suo utilizzo è richiesto da PostgreSQL, non imposto da Amazon RDS, ed è essenziale per garantire buone prestazioni. La funzione è abilitata per impostazione predefinita per tutte le nuove istanze database Amazon RDS per PostgreSQL e i relativi parametri di configurazione sono impostati in modo appropriato per impostazione predefinita.
L'amministratore del database è tenuto a conoscere e a comprendere questa operazione di manutenzione. Per la documentazione PostgreSQL sull'autovacuum, consulta The Autovacuum Daemon (Daemon di autovacuum)
La funzione di eliminazione automatica non è un'operazione "priva di risorse", ma viene eseguita in background e, per quanto possibile, assegna la precedenza alle operazioni dell'utente. Se abilitata, verifica la presenza di tabelle con un numero elevato di tuple aggiornate o eliminate. Inoltre, protegge dalla perdita di dati molto vecchi in seguito a wraparound dell'ID transazione. Per ulteriori informazioni, consulta Impedire gli errori di wraparound dell'ID transazione
La funzione di eliminazione automatica non deve essere considerata un'operazione dal sovraccarico elevato che può essere limitata per migliorare le prestazioni. Al contrario, le tabelle con un'elevata velocità di aggiornamento ed eliminazione si deteriorano rapidamente nel tempo se non viene eseguita la funzione di eliminazione automatica.
Importante
La mancata esecuzione della funzione di eliminazione automatica potrebbe comportare l'interruzione delle attività per eseguire un'operazione di eliminazione molto più intrusiva. In alcuni casi, l'istanza database RDS per PostgreSQL potrebbe non essere disponibile a causa di un uso troppo conservativo del vacuum automatico. In questi casi, il database PostgreSQL si arresta per proteggersi. A quel punto, Amazon RDS deve eseguire un'operazione di eliminazione completa in modalità utente singolo direttamente nell'istanza database, la quale può comportare un'interruzione delle attività di diverse ore. Pertanto, è consigliabile non disattivare la funzione di eliminazione automatica, che è abilitata per impostazione predefinita.
I parametri della funzione di eliminazione automatica determinano quando viene eseguita e con quale intensità. I parametri autovacuum_vacuum_threshold e autovacuum_vacuum_scale_factor determinano quando viene eseguita la funzione di eliminazione automatica. I parametri autovacuum_max_workers, autovacuum_nap_time, autovacuum_cost_limit e autovacuum_cost_delay determinano con quale intensità viene eseguita la funzione di eliminazione automatica. Per ulteriori informazioni sull'autovacuum, su quando viene eseguito e sui parametri richiesti, consulta la Routine Vacuuming (Vacuum di routine)
La seguente query mostra il numero di tuple "inattive" in una tabella denominata table1:
SELECT relname, n_dead_tup, last_vacuum, last_autovacuum FROM pg_catalog.pg_stat_all_tables WHERE n_dead_tup > 0 and relname = 'table1';
I risultati della query saranno simili a quelli nell'esempio seguente:
relname | n_dead_tup | last_vacuum | last_autovacuum ---------+------------+-------------+----------------- tasks | 81430522 | | (1 row)
Video su best practice di Amazon RDS for PostgreSQL
La conferenza AWS re:Invent 2020 ha incluso una presentazione sulle nuove funzionalità e le best practice per lavorare con PostgreSQL su Amazon RDS. Un video della presentazione è disponibile qui:
Best practice per l'utilizzo di SQL Server
Le migliori pratiche per una Multi-AZ distribuzione con un'istanza DB di SQL Server includono quanto segue:
Utilizza eventi di database Amazon RDS per monitorare i failover. Ad esempio, puoi ricevere un avvio via sms o e-mail in caso di failover di un'istanza di database. Per ulteriori informazioni sugli eventi di Amazon RDS, consulta Utilizzo della notifica degli eventi di Amazon RDS.
Se l'applicazione memorizza nella cache i valori DNS, imposta un time to live (TTL) inferiore a 30 secondi. Impostare il TTL in questo modo è utile in caso di failover. In un failover, l'indirizzo IP può cambiare e il valore memorizzato nella cache non essere più in uso.
Si consiglia di non abilitare le seguenti modalità perché disattivano la registrazione delle transazioni, necessaria per Multi-AZ:
-
Modalità di recupero semplice
-
Modalità offline
-
Read-only modalità
-
Esegui un test per determinare il tempo di failover dell'istanza di database. Il tempo di failover può variare in base al tipo di database, alla classe dell'istanza e al tipo di storage che utilizzi. Dovresti inoltre verificare la capacità dell'applicazione di continuare a funzionare in caso di failover.
Per ridurre il tempo di failover, procedi come indicato di seguito:
Assicurati di disporre di sufficienti IOPS assegnati per il carico di lavoro. Una soluzione inadeguata I/O può allungare i tempi di failover. Il ripristino del database richiede. I/O
Utilizza transazioni di piccole dimensioni. Il ripristino del database si basa sulle transazioni, per cui suddividendo le transazioni di grandi dimensioni in più transazioni di dimensioni inferiori, il tempo di failover dovrebbe ridursi.
Tieni presente che durante un failover le latenze sono elevate. Nell'ambito del processo di failover, Amazon RDS esegue automaticamente la replica dei dati in una nuova istanza di standby. Questa replica significa che viene eseguito il commit dei nuovi dati su due diverse istanze database. Pertanto, fino a quando l'istanza database in standby non raggiunge la nuova istanza database principale, potrebbe verificarsi una latenza.
Distribuisci le applicazioni in tutte le zone di disponibilità. Se una zona di disponibilità non è raggiungibile, le applicazioni saranno ancora disponibili nelle altre zone di disponibilità.
Quando lavori con una Multi-AZ distribuzione di SQL Server, ricorda che Amazon RDS crea repliche per tutti i database SQL Server sulla tua istanza. Se non desideri che database specifici abbiano repliche secondarie, configura un'istanza DB separata che non utilizzi Multi-AZ per quei database.
Video su best practice di Amazon RDS for SQL Server
La conferenza AWS re:Invent 2019 ha incluso una presentazione sulle nuove funzionalità e sulle best practice per lavorare con SQL Server su Amazon RDS. Un video della presentazione è disponibile qui:
Utilizzo di gruppi di parametri di database
È consigliabile provare le modifiche al gruppo di parametri di database su un'istanza di database di test prima di applicarle a istanze di database di produzione. Un'impostazione non corretta dei parametri del motore di un database in un gruppo di parametri di database può avere ripercussioni negative non previste, tra cui prestazioni scadenti e instabilità del sistema. Fai sempre attenzione quando modifichi i parametri del motore di un database ed effettui il backup di un'istanza di database prima di modificare un gruppo di parametri di database.
Per ulteriori informazioni sul backup di un'istanza di database, consulta Backup, ripristino ed esportazione dei dati.
Best practice per automatizzare la creazione di istanze database
È una best practice di Amazon RDS creare un'istanza database con la versione secondaria preferita del motore di database. Puoi utilizzare l' AWS CLI API Amazon RDS o automatizzare la creazione AWS CloudFormation di istanze DB. Quando utilizzi questi metodi, puoi specificare solo la versione principale e Amazon RDS crea automaticamente l'istanza con la versione secondaria preferita. Ad esempio, se PostgreSQL 12.5 è la versione secondaria preferita e se si specifica la versione 12 con create-db-instance, l'istanza database sarà la versione 12.5.
Per determinare la versione secondaria preferita, è possibile eseguire il comando describe-db-engine-versions con l'opzione --default-only come mostrato nell'esempio seguente.
aws rds describe-db-engine-versions --default-only --engine postgres { "DBEngineVersions": [ { "Engine": "postgres", "EngineVersion": "12.5", "DBParameterGroupFamily": "postgres12", "DBEngineDescription": "PostgreSQL", "DBEngineVersionDescription": "PostgreSQL 12.5-R1", ...some output truncated... } ] }
Per informazioni sulla creazione di istanze database a livello di programmazione, vedere le seguenti risorse:
Utilizzo dell'API Amazon RDS – CreateDBInstance
Utilizzo di AWS CloudFormation — AWS: :RDS: :dbInstance
Video sulle nuove funzionalità di Amazon RDS
La conferenza AWS re:Invent del 2023 ha incluso una presentazione sulle nuove funzionalità di Amazon RDS. Un video della presentazione è disponibile qui:
