Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ripristino di un backup in un’istanza database Amazon RDS per MySQL
Amazon RDS supporta l’importazione di database MySQL con file di backup. È possibile creare un backup del database, archiviarlo nel file di backup in Amazon S3 e quindi ripristinare il file di backup in una nuova istanza database Amazon RDS che esegue MySQL. Amazon RDS supporta l’importazione di file di backup da Amazon S3 in tutte le Regioni AWS.
Lo scenario descritto in questa sezione ripristina un backup di un database locale. Purché il database sia accessibile, è possibile utilizzare questa tecnica per i database in altre posizioni, ad esempio Amazon EC2 o altri servizi cloud.
Il seguente diagramma mostra lo scenario supportato.
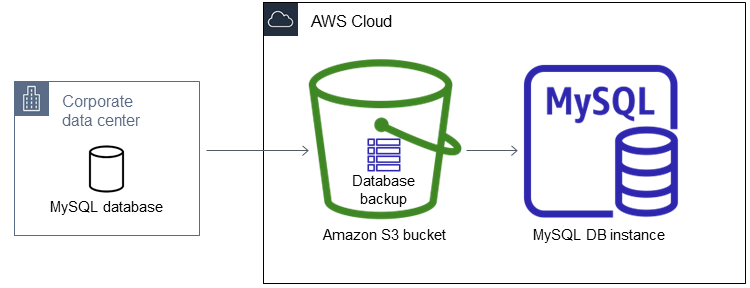
Se il database on-premises può rimanere offline durante la creazione, la copia e il ripristino dei file di backup, è consigliabile importare il database in Amazon RDS utilizzando i file di backup. Se il database non può rimanere offline, puoi utilizzare uno dei seguenti metodi:
-
Log binari: per prima cosa, importa i file di backup da Amazon S3 in Amazon RDS, come illustrato in questo argomento. Quindi utilizza la replica di log binari (binlog) per aggiornare il database. Per ulteriori informazioni, consulta Configurazione della replica della posizione del file di log binario con un'istanza di origine esterna..
-
AWS Database Migration Service— Utilizzalo AWS Database Migration Service per migrare il tuo database su Amazon RDS. Per ulteriori informazioni, consulta Cos'è? AWS Database Migration Service
Panoramica della configurazione per l’importazione di file di backup da Amazon S3 in Amazon RDS
Per l’importazione di file di backup da Amazon S3 in Amazon RDS, sono necessari i seguenti componenti:
Un bucket Amazon S3 per archiviare i file di backup.
Se hai già un bucket Amazon S3, puoi utilizzarlo. Se non hai un bucket Amazon S3, creane uno nuovo. Per ulteriori informazioni, consulta Creazione di un bucket.
Un backup del database locale creato da XtraBackup Percona.
Per ulteriori informazioni, consulta Creazione del backup di database.
-
Un ruolo AWS Identity and Access Management (IAM) per consentire ad Amazon RDS di accedere al bucket S3.
Se hai già un ruolo IAM, puoi utilizzarlo e collegarvi policy di attendibilità e di autorizzazione. Per ulteriori informazioni, consulta Creazione di un ruolo IAM manualmente.
Se non hai un ruolo IAM, puoi scegliere una di queste due opzioni:
-
Creare un nuovo ruolo IAM manualmente. Per ulteriori informazioni, consulta Creazione di un ruolo IAM manualmente.
-
Impostare la creazione automatica di un ruolo IAM in Amazon RDS. Se desideri che Amazon RDS crei un nuovo ruolo IAM per te, segui la procedura che utilizza la Importazione di dati da Amazon S3 in una nuova istanza database MySQL sezione AWS Management Console in.
-
Creazione del backup di database
Usa il XtraBackup software Percona per creare il tuo backup. Ti consigliamo di utilizzare l'ultima versione di XtraBackup Percona. È possibile installare Percona XtraBackup da Software Downloads sul sito Web
avvertimento
Durante la creazione di un backup del database, XtraBackup potrebbe salvare le credenziali nel file xtrabackup_info. Assicurati che l’impostazione tool_command nel file xtrabackup_info non contenga informazioni sensibili.
La XtraBackup versione di Percona che usi dipende dalla versione di MySQL di cui stai eseguendo il backup.
-
MySQL 8.4 — Usa la versione 8.4 di Percona. XtraBackup
-
MySQL 8.0 — Usa la versione 8.0 di Percona. XtraBackup
Nota
Percona XtraBackup 8.0.12 e versioni successive supportano la migrazione di tutte le versioni di MySQL 8.0. Se stai migrando a RDS for MySQL 8.0.32 o versioni successive, devi usare Percona 8.0.12 o versioni successive. XtraBackup
-
MySQL 5.7 — Usa la versione 2.4 di Percona. XtraBackup
Puoi usare Percona XtraBackup per creare un backup completo dei file del tuo database MySQL. In alternativa, se utilizzi già Percona XtraBackup per eseguire il backup dei file del database MySQL, puoi caricare le directory e i file di backup completi e incrementali esistenti.
Per ulteriori informazioni sul backup del database con Percona, consulta Percona - Documentazione sul sito XtraBackup Web di XtraBackup Percona
Creazione di un backup completo con Percona XtraBackup
Per creare un backup completo dei file del database MySQL che Amazon RDS può ripristinare da Amazon S3, usa l'utilità Percona (). XtraBackup xtrabackup
Ad esempio, il comando seguente consente di creare un backup di un database MySQL e memorizzare i file nella cartella /on-premises/s3-restore/backup.
xtrabackup --backup --user=myuser--password=password--target-dir=/on-premises/s3-restore/backup
Se desideri comprimere il backup in un singolo file (che potrai suddividere in seguito, se necessario), puoi salvare il backup in uno dei seguenti formati, a seconda della versione di MySQL:
Gzip (.gz): per MySQL 5.7 e versioni precedenti
tar (.tar): per MySQL 5.7 e versioni precedenti
Percona xbstream (.xbstream): per tutte le versioni di MySQL
Nota
Percona XtraBackup 8.0 e versioni successive supportano solo Percona xbstream per la compressione.
MySQL 5.7 e versioni precedenti
Il comando seguente consente di creare un backup del database MySQL diviso in più file Gzip. Sostituisci i valori con le tue informazioni.
xtrabackup --backup --user=my_user--password=password--stream=tar \ --target-dir=/on-premises/s3-restore/backup| gzip - | split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.tar.gz
MySQL 5.7 e versioni precedenti
Il comando seguente consente di creare un backup del database MySQL diviso in più file tar. Sostituisci i valori con le tue informazioni.
xtrabackup --backup --user=my_user--password=password--stream=tar \ --target-dir=/on-premises/s3-restore/backup| split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.tar
Tutte le versioni di MySQL
Il comando seguente consente di creare un backup del database MySQL diviso in più file xbstream. Sostituisci i valori con le tue informazioni.
xtrabackup --backup --user=myuser--password=password--stream=xbstream \ --target-dir=/on-premises/s3-restore/backup| split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.xbstream
Nota
Se viene visualizzato il seguente errore, è possibile che il problema sia dovuto dalla combinazione di formati di file diversi nel comando:
ERROR:/bin/tar: This does not look like a tar archive
Utilizzo di backup incrementali con Percona XtraBackup
Se utilizzi già Percona XtraBackup per eseguire backup completi e incrementali dei file del tuo database MySQL, non è necessario creare un backup completo e caricare i file di backup su Amazon S3. In alternativa, per risparmiare tempo, copia le directory e i file di backup esistenti nel bucket Amazon S3. Per ulteriori informazioni sulla creazione di backup incrementali utilizzando Percona, consulta Creare un backup incrementale sul sito Web di Percona XtraBackup.
Durante la copia dei file del backup completo e incrementale in un bucket Amazon S3, devi copiare in modo ricorsivo i contenuti della directory di base. Questi contenuti includono sia il backup completo sia tutte le directory e tutti i file del backup incrementale. Questa copia deve mantenere la struttura di directory nel bucket Amazon S3. Amazon RDS esegue l'iterazione di tutti i file e le directory. Amazon RDS utilizza il file xtrabackup-checkpoints incluso con ogni backup incrementale per identificare la directory di base e ordinare i backup incrementali in base all’intervallo dei numeri di sequenza di log (LSN).
Considerazioni sul backup per Percona XtraBackup
Amazon RDS consuma i file di backup in base al nome del file. Assegna un nome ai file di backup con l’estensione file appropriata in base al formato. Ad esempio, utilizza .xbstream per i file archiviati nel formato Percona xbstream.
Amazon RDS consuma i file di backup in ordine alfabetico e anche in ordine numerico naturale. Per assicurarti che i file di backup vengano scritti e denominati nell’ordine corretto, utilizza l’opzione split quando invii il comando xtrabackup.
Amazon RDS non supporta backup parziali creati con Percona. XtraBackup Non puoi utilizzare le opzioni seguenti per creare un backup parziale quando esegui il backup dei file di origine del database:
-
--tables -
--tables-exclude -
--tables-file -
--databases -
--databases-exclude -
--databases-file
Creazione di un ruolo IAM manualmente
Se non hai già un ruolo IAM, puoi creane uno nuovo manualmente. Tuttavia, se ripristini il database utilizzando il AWS Management Console, ti consigliamo di fare in modo che Amazon RDS crei questo nuovo ruolo IAM per te. A tale scopo, segui la procedura descritta nella sezione Importazione di dati da Amazon S3 in una nuova istanza database MySQL.
Per creare manualmente un nuovo ruolo IAM per l’importazione del database da Amazon S3, crea un ruolo per delegare le autorizzazioni da Amazon RDS al bucket Amazon S3. Quando crei un ruolo IAM, vengono collegate le policy di attendibilità e autorizzazione. Per importare i file di backup da Amazon S3, utilizza policy di attendibilità e autorizzazione simili agli esempi seguenti. Per ulteriori informazioni sulla creazione del ruolo, consulta Creazione di un ruolo per delegare le autorizzazioni a un servizio. AWS
Le policy di attendibilità e autorizzazione richiedono che venga fornito un Amazon Resource Name (ARN). Per ulteriori informazioni sulla formattazione ARN, consulta Amazon Resource Names (ARNs) e service namespace. AWS
Esempio policy di attendibilità per l’importazione da Amazon S3
Esempio policy di autorizzazione per l’importazione da Amazon S3 – autorizzazioni dell’utente IAM
Nell'esempio seguente, sostituiscilo con il tuo valore. iam_user_id
Esempio policy di autorizzazione per l’importazione da Amazon S3 – autorizzazioni di ruolo
Nell'esempio seguente, sostituisci amzn-s3-demo-bucket e prefix con i tuoi valori.
Nota
Se includi un prefisso del nome file, aggiungi l'asterisco (*) dopo il prefisso. Se non intendi specificare un prefisso, specifica solo un asterisco.
Importazione di dati da Amazon S3 in una nuova istanza database MySQL
Puoi importare dati da Amazon S3 in una nuova istanza DB MySQL utilizzando l' AWS Management Console API, o RDS. AWS CLI
Per importare dati da Amazon S3 in una nuova istanza database MySQL
-
Accedi a AWS Management Console e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nella console Amazon RDS, scegli Regione AWS dove vuoi creare la tua istanza DB. Scegli lo Regione AWS stesso bucket Amazon S3 che contiene il backup del database.
-
Nel pannello di navigazione, seleziona Database.
-
Seleziona Ripristina da S3.
Sarà visualizzata la pagina Crea database ripristinando da S3 .
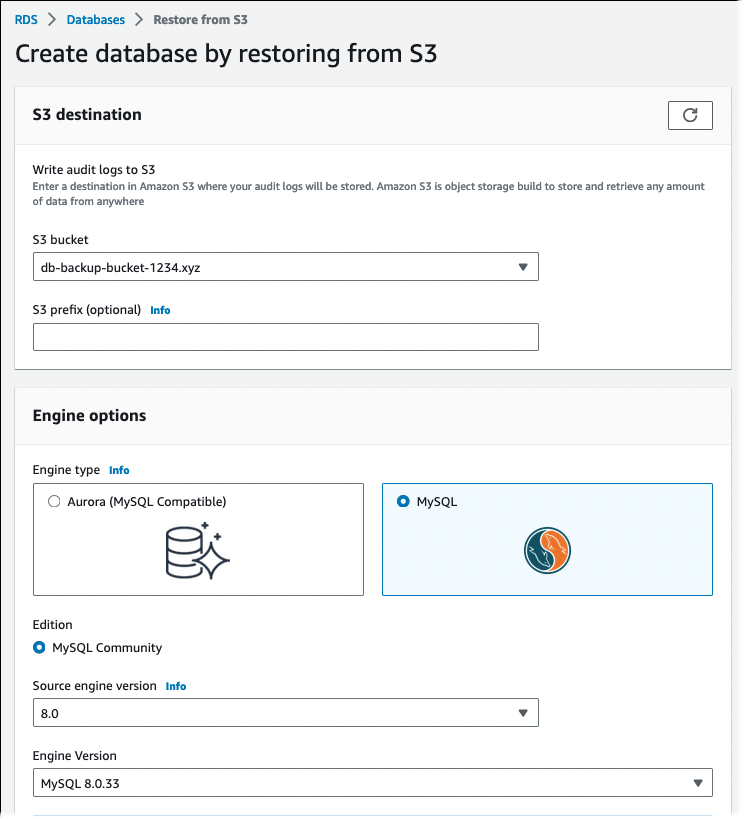
-
Nell’area S3 source:
-
Seleziona il bucket S3 che contiene il backup.
-
(Facoltativo) Per S3 prefix inserisci un prefisso del percorso per i file archiviati nel bucket Amazon S3.
Se non specifichi un prefisso, Amazon RDS crea l’istanza database utilizzando tutti i file e le cartelle nella cartella root del bucket S3. Se invece specifichi un prefisso, Amazon RDS crea l’istanza database utilizzando i file e le cartelle nel bucket S3 in cui il percorso del file inizia con il prefisso specificato.
Ad esempio, supponi di archiviare i file di backup su S3 in una sottocartella denominata backups e di avere più set di file di backup, ciascuno nella rispettiva directory (gzip_backup1, gzip_backup2 e così via). In questo caso, per eseguire il ripristino dai file nella cartella gzip_backup1, devi specificare il prefisso. backups/gzip_backup1
-
-
In Opzioni motore:
-
Per Tipo di motore, seleziona MySQL.
-
In Versione motore di origine, seleziona la versione MySQL del database di origine.
-
Per Versione motore, scegli la versione secondaria predefinita della versione principale di MySQL nella Regione AWS.
In, è disponibile solo AWS Management Console la versione secondaria predefinita. Al termine dell’importazione, puoi aggiornare l’istanza database.
-
-
Per il ruolo IAM, crea o scegli il ruolo IAM con le policy di attendibilità e di autorizzazione richieste che consentono ad Amazon RDS di accedere al bucket Amazon S3. Eseguire una delle seguenti operazioni:
(Consigliato) Scegliere Crea nuovo ruolo e inserire il nome del ruolo IAM. Con questa opzione, Amazon RDS crea automaticamente il ruolo con le policy di attendibilità e di autorizzazione.
Scegliere un ruolo IAM esistente. Assicurarsi che il ruolo soddisfi tutti i criteri definiti in Creazione di un ruolo IAM manualmente.
-
Specifica le informazioni sull'istanza database. Per informazioni su ciascuna impostazione, consulta Impostazioni per istanze database.
Nota
Assicurati di allocare archiviazione sufficiente per la nuova istanza database in modo che l’operazione di ripristino vada a buon fine.
Per consentire automaticamente una crescita futura, in Configurazione di archiviazione aggiuntiva, scegli Abilita il dimensionamento automatico dello storage.
-
Scegliere impostazioni aggiuntive in base alle esigenze.
-
Scegliere Create database (Crea database).
Per importare dati da Amazon S3 in una nuova istanza DB MySQL utilizzando, esegui il comando restore-db-instance-from-s3 con le seguenti opzioni. AWS CLI Per informazioni su ciascuna impostazione, consulta Impostazioni per istanze database.
Nota
Assicurati di allocare archiviazione sufficiente per la nuova istanza database in modo che l’operazione di ripristino vada a buon fine.
Per abilitare il dimensionamento automatico dell’archiviazione e consentire automaticamente una crescita futura, utilizza l’opzione --max-allocated-storage.
--allocated-storage--db-instance-identifier--db-instance-class--engine--master-username--manage-master-user-password--s3-bucket-name--s3-ingestion-role-arn--s3-prefix--source-engine--source-engine-version
Esempio
Per Linux, macOS o Unix:
aws rds restore-db-instance-from-s3 \ --allocated-storage250\ --db-instance-identifiermy_identifier\ --db-instance-classdb.m5.large\ --enginemysql\ --master-usernameadmin\ --manage-master-user-password \ --s3-bucket-nameamzn-s3-demo-bucket\ --s3-ingestion-role-arnarn:aws:iam::account-number:role/rolename\ --s3-prefixbucket_prefix\ --source-enginemysql\ --source-engine-version8.0.32\ --max-allocated-storage1000
Per Windows:
aws rds restore-db-instance-from-s3 ^ --allocated-storage250^ --db-instance-identifiermy_identifier^ --db-instance-classdb.m5.large^ --enginemysql^ --master-usernameadmin^ --manage-master-user-password ^ --s3-bucket-nameamzn-s3-demo-bucket^ --s3-ingestion-role-arnarn:aws:iam::account-number:role/rolename^ --s3-prefixbucket_prefix^ --source-enginemysql^ --source-engine-version8.0.32^ --max-allocated-storage1000
Per importare dati da Amazon S3 in una nuova istanza DB MySQL utilizzando l'API Amazon RDS, chiama l'operazione. RestoreDBInstanceFromS3
Considerazioni e limitazioni per l’importazione di file di backup in Amazon RDS da Amazon S3
Le seguenti considerazioni e limitazioni si applicano all’importazione di file di backup da Amazon S3 in un’istanza database RDS per MySQL:
-
È possibile eseguire la migrazione dei dati solo in una nuova istanza database e non in una già esistente.
-
È necessario utilizzare Percona XtraBackup per eseguire il backup dei dati su Amazon S3. Per ulteriori informazioni, consulta Creazione del backup di database.
-
Il bucket Amazon S3 e l’istanza database RDS per MySQL devono trovarsi nella stessa Regione AWS.
-
Non è possibile eseguire il ripristino dalle seguenti origini:
-
Esportazione di uno snapshot dell’istanza database in Amazon S3. Non è nemmeno possibile eseguire la migrazione dei dati da un’esportazione di uno snapshot dell’istanza database nel bucket Amazon S3.
-
Un database di origine crittografato. È tuttavia possibile crittografare i dati che vengono migrati. Durante il processo di migrazione puoi anche lasciare i dati non crittografati.
-
Un database MySQL 5.5 o 5.6.
-
-
RDS per MySQL non supporta Percona Server for MySQL come database di origine perché può contenere tabelle
compression_dictionary*nellomysql schema. -
RDS per MySQL non supporta la migrazione alle versioni precedenti per le versioni principali o secondarie. Ad esempio, non è possibile eseguire la migrazione da MySQL versione 8.0 a RDS per MySQL 5.7 e nemmeno da MySQL versione 8.0.32 a RDS per MySQL versione 8.0.26.
-
Amazon RDS non supporta l’importazione nella classe di istanza database db.t2.micro da Amazon S3. È tuttavia possibile eseguire il ripristino in una classe di istanza database diversa e modificare tale classe in seguito. Per ulteriori informazioni sulle classi di istanza, consulta Specifiche hardware per le classi di istanze DB.
-
Amazon S3 limita la dimensione del file caricato in un bucket Amazon S3 a 5 TB. Se un file di backup supera i 5 TB, devi dividerlo in file più piccoli.
-
Amazon RDS limita il numero di file caricati in un bucket Amazon S3 a 1 milione. Se i dati di backup del database, inclusi tutti i backup completi e incrementali, superano 1 milione di file, utilizza un file Gzip (.gz), tar (.tar.gz) o Percona xbstream (.xbstream) per memorizzare i file dei backup completi e incrementali nel bucket Amazon S3. Percona XtraBackup 8.0 supporta solo Percona xbstream per la compressione.
-
Per fornire servizi di gestione per ogni istanza database, Amazon RDS crea l’utente
rdsadminal momento della creazione dell’istanza database. Poichérdsaminè un utente riservato in Amazon RDS, si applicano le seguenti limitazioni:-
Amazon RDS non importa le funzioni, le procedure, le viste, gli eventi e i trigger con il definer
'rdsadmin'@'localhost'. Per ulteriori informazioni, consultare Oggetti archiviati con ‘rdsadmin’@’localhost’ come definer e Privilegi dell'account utente master. -
Durante la creazione dell’istanza database, Amazon RDS crea un utente master con i privilegi massimi supportati. Durante il ripristino dal backup, Amazon RDS rimuove automaticamente i privilegi non supportati assegnati agli utenti importati.
Per identificare gli utenti che potrebbero essere interessati da questo problema, consulta Account utente con privilegi non supportati. Per ulteriori informazioni sui privilegi supportati in RDS per MySQL, consulta Role-based modello di privilegi per RDS for MySQL.
-
-
Amazon RDS non esegue la migrazione delle tabelle create dall’utente nello schema
mysql. -
Il parametro
innodb_data_file_pathdeve essere configurato con un solo file di dati che utilizza il nome di file di dati predefinitoibdata1:12M:autoextend. È possibile eseguire la migrazione del database con due file di dati, o con un file di dati con un nome diverso, utilizzando questo metodo.Di seguito sono riportati esempi di nomi di file non consentiti in Amazon RDS:
-
innodb_data_file_path=ibdata1:50M -
ibdata2:50M:autoextend -
innodb_data_file_path=ibdata01:50M:autoextend
-
-
Non puoi eseguire la migrazione da un database di origine con tabelle definite all'esterno della directory dei dati MySQL predefinita.
-
La dimensione massima supportata per i backup non compressi che utilizzano questo metodo è limitata a 64 TiB. Per i backup compressi, questo limite è inferiore per tenere conto dei requisiti dello spazio di decompressione. In questi casi, la dimensione massima di backup supportata è
64 TiB - compressed backup size.Per informazioni sulla dimensione massima del database supportata da Amazon RDS per MySQL, consulta Storage SSD per scopi generici e Storage SSD Provisioned IOPS.
-
Amazon RDS non supporta l’importazione di MySQL e di altri componenti e plugin esterni.
-
Amazon RDS non ripristina la totalità dei dati dal database. È consigliabile salvare lo schema del database e i valori relativi ai seguenti elementi dal database di sistema MySQL di origine e quindi aggiungerli all’istanza database RDS per MySQL ripristinata dopo che è stata creata:
-
Account utenti
-
Funzioni
-
Procedure archiviate
-
Informazioni fuso orario. Le informazioni sul fuso orario vengono caricate dal sistema operativo locale dell’istanza database RDS per MySQL. Per ulteriori informazioni, consulta Fuso orario locale per le istanze database MySQL.
-
Oggetti archiviati con ‘rdsadmin’@’localhost’ come definer
Amazon RDS non importa le funzioni, le procedure, le viste, gli eventi e i trigger con 'rdsadmin'@'localhost' come definer.
Puoi usare il seguente script SQL nel database MySQL di origine per elencare gli oggetti archiviati con il definire non supportato.
-- This SQL query lists routines with `rdsadmin`@`localhost` as the definer. SELECT ROUTINE_SCHEMA, ROUTINE_NAME FROM information_schema.routines WHERE definer = 'rdsadmin@localhost'; -- This SQL query lists triggers with `rdsadmin`@`localhost` as the definer. SELECT TRIGGER_SCHEMA, TRIGGER_NAME, DEFINER FROM information_schema.triggers WHERE DEFINER = 'rdsadmin@localhost'; -- This SQL query lists events with `rdsadmin`@`localhost` as the definer. SELECT EVENT_SCHEMA, EVENT_NAME FROM information_schema.events WHERE DEFINER = 'rdsadmin@localhost'; -- This SQL query lists views with `rdsadmin`@`localhost` as the definer. SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.views WHERE DEFINER = 'rdsadmin@localhost';
Account utente con privilegi non supportati
Gli account utente con privilegi non supportati da RDS per MySQL vengono importati senza tali privilegi. Per l'elenco dei privilegi supportati, consulta Role-based modello di privilegi per RDS for MySQL.
Puoi eseguire la seguente query SQL sul database di origine per elencare gli account utente con privilegi non supportati.
SELECT user, host FROM mysql.user WHERE Shutdown_priv = 'y' OR File_priv = 'y' OR Super_priv = 'y' OR Create_tablespace_priv = 'y';
