Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Che cos'è Amazon S3?
Amazon Simple Storage Service (Amazon S3) è un servizio di archiviazione di oggetti che offre scalabilità, disponibilità dei dati, sicurezza e prestazioni tra le migliori del settore. I clienti di tutte le dimensioni e settori possono utilizzare Amazon S3 per archiviare e proteggere qualsiasi quantità di dati in un'ampia gamma di casi d'uso, come data lake, siti Web, applicazioni mobili, backup e ripristino, archivi, applicazioni per aziende, dispositivi IoT e analisi dei Big Data. Amazon S3 offre caratteristiche di gestione che consentono di ottimizzare, organizzare e configurare l'accesso ai dati per soddisfare specifici requisiti aziendali, organizzativi e di conformità.
Nota
Per ulteriori informazioni sull'utilizzo della classe di archiviazione Amazon S3 Express One Zone con bucket di directory, consulta S3 Express One Zone e Operazioni con i bucket di directory.
Argomenti
Caratteristiche di Amazon S3
Classi di archiviazione
Amazon S3 offre una gamma di classi di storage concepite per i diversi casi d'uso, Ad esempio, puoi archiviare i dati di produzione cruciali in S3 Standard o S3 Express One Zone per un accesso frequente, risparmiare sui costi archiviando i dati a cui si accede raramente in S3 Standard-IA o S3 One e archiviare i dati ai costi più bassi in S3 Glacier Instant Retrieval Zone-IA, S3 Glacier Flexible Retrieval e S3 Glacier Deep Archive.
Amazon S3 Express One Zone è una classe di archiviazione Amazon S3 a zona singola ad alte prestazioni, creata appositamente per fornire un accesso ai dati coerente di pochi millisecondi per le applicazioni sensibili alla latenza. S3 Express One Zone è la classe di storage di oggetti cloud con la latenza minima attualmente disponibile, con velocità di accesso ai dati fino a 10 volte maggiori e con costi di richiesta inferiori del 50% rispetto a S3 Standard. S3 Express One Zone è la prima classe di archiviazione S3 in cui è possibile selezionare una singola zona di disponibilità con la possibilità di co-ubicare l'archiviazione di oggetti con le risorse di calcolo, che offre la massima velocità di accesso possibile. Inoltre, per aumentare ulteriormente la velocità di accesso e supportare centinaia di migliaia di richieste al secondo, i dati vengono archiviati in un nuovo tipo di bucket: un bucket di directory Amazon S3. Per ulteriori informazioni, consultare S3 Express One Zone e Operazioni con i bucket di directory.
Puoi archiviare dati con modelli di accesso mutevoli o sconosciuti in S3 Intelligent-Tiering, il che ottimizza i costi di archiviazione spostando automaticamente i dati tra quattro livelli di accesso quando i modelli di accesso cambiano. Questi quattro livelli di accesso includono due livelli di accesso a bassa latenza ottimizzati per l'accesso frequente e sporadico e due livelli di accesso all'archivio progettati per l'accesso asincrono e per dati a cui accedi raramente.
Per ulteriori informazioni, consulta Comprensione e gestione delle classi di storage Amazon S3.
Gestione dello storage
Amazon S3 dispone di caratteristiche di gestione dell'archiviazione utilizzabili per gestire i costi, rispettare i requisiti normativi, ridurre la latenza e salvare più copie distinte dei dati per soddisfare i requisiti di conformità.
-
Ciclo di vita S3: consente di impostare la configurazione del ciclo di vita per gestire gli oggetti e archiviarli all'insegna dell'efficienza in termini di costi durante l'intero ciclo di vita. Puoi spostare gli oggetti in altre classi di archiviazione S3 o far scadere oggetti che raggiungono la fine del loro ciclo.
-
Blocco degli oggetti S3: impedisci che un oggetto di Amazon S3 venga eliminato o sovrascritto per un determinato periodo di tempo o in modo indefinito. Il blocco degli oggetti consente di soddisfare i requisiti normativi che richiedono l'archiviazione write-once-read-many (WORM) o semplicemente di aggiungere un ulteriore livello di protezione contro la modifica e l'eliminazione degli oggetti.
-
Replica S3: replica gli oggetti e i rispettivi metadati e tag degli oggetti in uno o più bucket di destinazione uguali o diversi Regioni AWS per ridurre latenza, conformità, sicurezza e altri casi d'uso.
-
Operazioni in batch S3: consente di gestire qualsiasi numero di oggetti su larga scala con una singola richiesta API S3 o pochi clic nella console di Amazon S3. È possibile utilizzare Batch Operations per eseguire operazioni come Copy, Invoke AWS Lambda e Restore su milioni o miliardi di oggetti.
Gestione degli accessi e sicurezza
Amazon S3 offre caratteristiche per la verifica e la gestione degli accessi ai tuoi bucket e oggetti. Per impostazione predefinita, i bucket S3 e gli oggetti al loro interno sono privati. Puoi accedere solo alle risorse S3 che hai creato. Per concedere autorizzazioni granulari delle risorse che supportano il tuo caso d'uso specifico o per verificare le autorizzazioni delle tue risorse Amazon S3, puoi utilizzare le seguenti caratteristiche.
-
Blocco dell'accesso pubblico di S3: blocca l'accesso pubblico a bucket S3 e oggetti. Per impostazione predefinita, le impostazioni Blocco dell'accesso pubblico sono attivate a livello di bucket. È consigliabile mantenere tutte le impostazioni Blocco dell'accesso pubblico disabilitate, a meno che non sia necessario disattivarne una o più di una per il caso d'uso specifico. Per ulteriori informazioni, consulta Configurazione delle impostazioni di blocco dell'accesso pubblico per i bucket S3.
-
AWS Identity and Access Management (IAM): IAM è un servizio Web che consente di controllare in modo sicuro l'accesso alle AWS risorse, incluse le risorse Amazon S3. Con IAM, puoi gestire centralmente le autorizzazioni che controllano le AWS risorse a cui gli utenti possono accedere. Utilizza IAM per controllare chi è autenticato (accesso effettuato) e autorizzato (dispone di autorizzazioni) per l’utilizzo di risorse.
-
Policy relative ai bucket: utilizza il linguaggio IAM-based delle policy per configurare le autorizzazioni basate sulle risorse per i bucket S3 e gli oggetti in essi contenuti.
-
Punto di accesso Amazon S3: configura gli endpoint di rete denominati con policy di accesso dedicate per gestire l'accesso ai dati su vasta scala per set di dati condivisi in Amazon S3.
-
Liste di controllo degli accessi (ACL): concedi autorizzazioni di lettura e scrittura per singoli bucket e oggetti agli utenti autorizzati. Come regola generale, è consigliabile utilizzare policy basate sulle risorse S3 (policy di bucket e policy dei punti di accesso) o policy utente IAM per il controllo degli accessi anziché ACL. Le policy sono un'opzione di controllo degli accessi semplificata e più flessibile. Con le policy dei bucket e le policy dei punti di accesso, puoi definire le regole applicabili globalmente a tutte le richieste alle risorse Amazon S3. Per ulteriori informazioni su casi specifici quando desideri utilizzare le ACL anziché le policy basate sulle risorse o le policy utente IAM, consultare Gestione degli accessi con le ACL.
-
S3 Proprietà dell'oggetto: consente di assumere la proprietà di ogni oggetto nel bucket, semplificando la gestione degli accessi per i dati archiviati in Amazon S3. S3 Proprietà dell'oggetto è un'impostazione a livello di bucket di Amazon S3 che puoi utilizzare per disabilitare o abilitare le ACL. Per impostazione predefinita, le ACL sono disabilitate. Con le ACL disabilitate, il proprietario del bucket possiede tutti gli oggetti nel bucket e gestisce l'accesso ai dati in maniera esclusiva utilizzando policy di gestione dell'accesso.
-
IAM Access Analyzer per S3: valuta e monitora le policy di accesso al bucket S3, assicurando che forniscano solo l'accesso previsto alle risorse S3.
Elaborazione dei dati
Per trasformare i dati e attivare i flussi di lavoro in modo che automatizzino una serie di altre attività di elaborazione su larga scala, puoi utilizzare le seguenti caratteristiche.
-
Lambda dell'oggetto S3: aggiungi il tuo codice alle richieste GET, HEAD e LIST di S3 per modificare ed elaborare i dati quando vengono restituiti a un'applicazione. Questa caratteristica consente di filtrare righe, ridimensionare dinamicamente immagini, oscurare dati riservati e molto altro ancora.
-
Notifiche di eventi: attiva flussi di lavoro che utilizzano Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS) e quando viene apportata una modifica alle tue risorse S3. AWS Lambda
Registrazione e monitoraggio dell'archiviazione
Amazon S3 fornisce strumenti di registrazione e monitoraggio che puoi utilizzare per monitorare e controllare come vengono utilizzate le tue risorse Amazon S3. Per ulteriori informazioni, Strumenti di monitoraggio.
Strumenti di monitoraggio automatici
-
CloudWatchParametri Amazon per Amazon S3: monitora lo stato operativo delle tue risorse S3 e configura avvisi di fatturazione quando gli addebiti stimati raggiungono una soglia definita dall'utente.
-
AWS CloudTrail— Registra le azioni intraprese da un utente, da un ruolo o da un utente Servizio AWS in Amazon S3. CloudTrail i log forniscono un tracciamento dettagliato delle API per le operazioni S3 a livello di bucket e a livello di oggetto.
Strumenti di monitoraggio manuali
-
Registrazione degli accessi al server: fornisce registri dettagliati per le richieste effettuate a un bucket. Puoi utilizzare i registri di accesso al server per molti casi d'uso, come eseguire verifiche di sicurezza e accesso, conoscere la tua base clienti o capire meglio la fattura Amazon S3.
-
AWS Trusted Advisor: valuta il tuo account utilizzando i controlli delle AWS migliori pratiche per identificare modi per ottimizzare l' AWS infrastruttura, migliorare la sicurezza e le prestazioni, ridurre i costi e monitorare le quote di servizio. Puoi quindi seguire i suggerimenti per ottimizzare i servizi e le risorse.
Analisi dei dati e informazioni dettagliate
Amazon S3 offre caratteristiche per aiutarti a ottenere visibilità sull'utilizzo dello spazio di archiviazione, che ti consente di comprendere, analizzare e ottimizzare meglio lo spazio di archiviazione su larga scala.
-
Amazon S3 Storage Lens: consente di comprendere, analizzare e ottimizzare l'archiviazione. S3 Storage Lens offre oltre 60 metriche di utilizzo e attività e dashboard interattivi per aggregare i dati per l'intera organizzazione, account specifici, bucket o prefissi. Regioni AWS
-
Analisi della classe di storage: consente di analizzare i modelli di accesso all'archiviazione per decidere quando è il momento di spostare i dati in una classe più conveniente.
-
S3 Inventory con report di Inventory: consente di verificare e creare report sugli oggetti e sui relativi metadati e configurare altre caratteristiche di Amazon S3 per intervenire sui report di Inventory. Ad esempio, puoi creare report sullo stato di replica e crittografia degli oggetti. Per un elenco di tutti i metadata disponibili per ogni oggetto nei report di Amazon S3 Inventory, consulta questa sezione.
Forte coerenza
Amazon S3 offre una forte coerenza di lettura dopo scrittura per le richieste PUT e DELETE di oggetti nel bucket Amazon S3 in generale. Regioni AWS Questo comportamento vale sia per le scritture dei nuovi oggetti che per le richieste PUT che sovrascrivono gli oggetti esistenti e le richieste DELETE. Inoltre, le operazioni di lettura su Amazon S3 Select, le liste di controllo accessi (ACL) Amazon S3, i tag oggetto Amazon S3 e i metadati degli oggetti (ad esempio, l'oggetto HEAD) sono fortemente coerenti. Per ulteriori informazioni, consulta Modello di consistenza dati Amazon S3.
Come funziona Amazon S3
Amazon S3 è un servizio di archiviazione di oggetti che archivia i dati come oggetti, dati gerarchici o dati tabulari all’interno di bucket. Un oggetto è un file e tutti i metadati che lo descrivono. Un bucket è un container per oggetti o file.
Per archiviare dati in Amazon S3, per prima cosa devi creare un bucket e specificarne nome e Regione AWS, quindi devi caricare i dati nel bucket come oggetti in Amazon S3. Ogni oggetto contiene una chiave (o nome chiave), che è l'identificatore univoco dell'oggetto nel bucket.
S3 fornisce funzionalità che puoi configurare per supportare il tuo caso d'uso specifico. Puoi utilizzare Controllo delle versioni S3 per mantenere più versioni di un oggetto in un unico bucket e consentire di ripristinare oggetti che vengono accidentalmente eliminati o sovrascritti.
I bucket e gli oggetti che contengono sono privati e accessibili solo se concedi esplicitamente le autorizzazioni di accesso. Puoi utilizzare policy bucket, policy AWS Identity and Access Management (IAM), liste di controllo degli accessi (ACL) e punti di accesso S3 per gestire l'accesso.
Argomenti
Bucket
Amazon S3 supporta quattro tipi di bucket: bucket per uso generico, bucket di directory, bucket di tabelle e bucket vettoriali. Ogni tipo di bucket offre un set unico di funzionalità per diversi casi d’uso.
Bucket per uso generico: i bucket per uso generico sono il tipo di bucket S3 originale e sono consigliati per la maggior parte dei casi d’uso e dei modelli di accesso. Un bucket per uso generico è un container per gli oggetti archiviati in Amazon S3 che può archiviare qualsiasi numero di oggetti e utilizzare tutte le classi di archiviazione (ad eccezione di S3 Express One Zone), in modo da poter archiviare oggetti in modo ridondante su più zone di disponibilità. Per ulteriori informazioni, consulta Creazione, configurazione e utilizzo di bucket per uso generico Amazon S3.
Per impostazione predefinita, i bucket generici esistono in un namespace globale, il che significa che ogni nome di bucket deve essere univoco all'interno di una partizione. Account AWS Regioni AWS Una partizione è un raggruppamento di regioni. AWS attualmente ha quattro partizioni: aws (Regioni standard), aws-cn (Regioni della Cina), aws-us-gov (AWS GovCloud (US)) e aws-eusc (European Sovereign Cloud). Quando crei un bucket generico, puoi scegliere di creare un bucket nello spazio dei nomi globale condiviso oppure puoi scegliere di creare un bucket nello spazio dei nomi regionale del tuo account. Lo spazio dei nomi regionale del tuo account è una suddivisione dello spazio dei nomi globale in cui solo il tuo account può creare bucket. I nuovi bucket generici creati nel namespace regionale del tuo account sono unici per il tuo account e non possono mai essere ricreati da un altro account. Per ulteriori informazioni sui namespace dei bucket, consulta Namespace per bucket generici.
Nota
Per impostazione predefinita, tutti i bucket per uso generico sono privati. È comunque possibile fornire l’accesso pubblico ai bucket per uso generico. È possibile controllare l’accesso ai bucket per uso generico a livello di bucket, prefisso (cartella) o tag dell’oggetto. Per ulteriori informazioni, consulta Controllo degli accessi in Amazon S3.
Bucket di directory: sono consigliati per i casi d’uso della bassa latenza e della residenza dei dati. Per impostazione predefinita, è possibile creare fino a 100 bucket di directory nell’ Account AWS, senza limiti al numero di oggetti che si possono archiviare in un bucket di directory. I bucket di directory organizzano gli oggetti in directory gerarchiche (prefissi) anziché nella struttura di archiviazione piatta dei bucket per uso generico. Questo tipo di bucket non ha limiti di prefissi e le singole directory possono essere scalate orizzontalmente. Per ulteriori informazioni, consulta Utilizzo dei bucket di directory.
-
Per i casi d'uso a bassa latenza, puoi creare un bucket di directory in una singola zona di disponibilità per archiviare i dati. AWS I bucket di directory nelle zone di disponibilità supportano la classe di storage S3 Express One Zone. Con S3 Express One Zone, i dati vengono archiviati in modo ridondante su più dispositivi all'interno di una singola zona di disponibilità. La classe di storage S3 Express One Zone è consigliata se la tua applicazione è sensibile alle prestazioni e beneficia di latenze a una cifra al millisecondo
PUTeGET. Per ulteriori informazioni sulla creazione di bucket di directory nelle zone di disponibilità, consulta Carichi di lavoro ad alte prestazioni. -
Per i casi d'uso relativi alla residenza dei dati, è possibile creare un bucket di directory in un'unica zona locale AWS dedicata (DLZ) per archiviare i dati. In Zone locali dedicate è possibile creare bucket di directory S3 per archiviare i dati in un perimetro dei dati specifico, che aiuta a supportare i casi d’uso della residenza dei dati e dell’isolamento dei dati. I bucket di directory in Local Zones supportano la classe di storage S3 One Zone-Infrequent Access (S3 One Zone-IA; Z-IA). Per ulteriori informazioni sulla creazione di bucket di directory in Zone locali, consulta Carichi di lavoro di residenza dei dati.
Nota
Per impostazione predefinita, i bucket di directory hanno l’accesso pubblico disabilitato. Questo comportamento non può essere modificato. Non è possibile concedere l'accesso agli oggetti archiviati nei bucket di directory, ma solo ai bucket di directory. Per ulteriori informazioni, consulta Autenticazione e autorizzazione delle richieste.
Bucket di tabelle: consigliati per l’archiviazione di dati tabulari, come le transazioni di acquisto giornaliere, i dati dei sensori di streaming o le ad impression. I dati tabulari rappresentano i dati in colonne e righe, come in una tabella di database. I bucket di tabelle forniscono un’archiviazione S3 ottimizzata per i carichi di lavoro di analisi e machine learning, con funzionalità progettate per migliorare costantemente le prestazioni delle query e ridurre i costi di archiviazione per le tabelle. Tabelle S3 è progettato appositamente per l’archiviazione di dati tabulari nel formato Apache Iceberg. Puoi interrogare i dati tabulari nelle tabelle S3 con i motori di query più diffusi, tra cui Amazon Athena, Amazon Redshift e Apache Spark. Per impostazione predefinita, puoi creare fino a 10 bucket di tabella per ogni tabella Regione AWS e fino a 10.000 tabelle Account AWS per bucket. Per ulteriori informazioni, consulta Utilizzo di Tabelle S3 e bucket di tabelle.
Nota
Tutti i bucket di tabelle e le tabelle sono privati e non possono essere resi pubblici. L'accesso a queste risorse è possibile solo per gli utenti a cui è concesso esplicitamente l'accesso. Per concedere l'accesso, è possibile utilizzare le policy basate sulle risorse IAM per i bucket di tabelle e le tabelle e per le policy basate sull'identità IAM per utenti e ruoli. Per ulteriori informazioni, consulta Sicurezza per Tabelle S3.
Bucket di vettori: i bucket vettoriali S3 sono un tipo di bucket Amazon S3 creato appositamente per poter archiviare e sottoporre a query i vettori. I bucket vettoriali utilizzano operazioni API dedicate per scrivere e sottoporre a query i dati vettoriali in modo efficiente. Con i bucket vettoriali S3, puoi archiviare incorporamenti vettoriali per modelli di machine learning, eseguire ricerche di similarità e integrarti con servizi come Amazon Bedrock e Amazon. OpenSearch
I bucket vettoriali S3 organizzano i dati utilizzando indici vettoriali, ovvero risorse all’interno di un bucket che archiviano e organizzano i dati vettoriali per eseguire operazioni di ricerca per similarità in modo efficiente. Ogni indice vettoriale può essere configurato con dimensioni, metriche della distanza (come la somiglianza del coseno) e configurazioni di metadati specifiche da ottimizzare per il caso d’uso specifico. Per ulteriori informazioni, consulta Utilizzo di S3 Vectors e bucket vettoriali.
Ulteriori informazioni su tutti i tipi di bucket
Quando crei un bucket, inserisci un nome e scegli la Regione AWS dove si troverà. Dopo avere creato un bucket, non puoi modificarne il nome né la regione. I nomi dei bucket devono seguire le seguenti regole di denominazione:
I bucket inoltre:
-
Organizzano lo spazio dei nomi Amazon S3 al livello più alto. Per i bucket per uso generico, questo namespace è
S3. Per i bucket di directory, questo namespace ès3express. Per i bucket di tabelle, questo namespace ès3tables. -
Identificano l'account responsabile del costo di archiviazione e trasferimento dati.
-
Servono come unità di aggregazione per i report di utilizzo.
Oggetti
Entità fondamentali archiviate in Amazon S3, gli oggetti sono composti da dati e metadata. I metadati sono invece un set di coppie nome-valore che descrivono l'oggetto. Queste coppie includono alcuni metadati di default, ad esempio la data dell'ultima modifica, e metadati HTTP standard, come Content-Type. È anche possibile specificare metadata personalizzati al momento dell'archiviazione dell'oggetto.
Ogni oggetto è contenuto in un bucket. Ad esempio, se l’oggetto denominato photos/puppy.jpg è archiviato nel bucket per uso generico amzn-s3-demo-bucket nella Regione Stati Uniti occidentali (Oregon), è indirizzabile tramite l’URL https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg. Per ulteriori informazioni, consulta Accesso a un bucket.
Un oggetto viene identificato in modo univoco in un bucket tramite un (nome) chiave e un ID versione (se Controllo delle versioni S3 è abilitato nel bucket). Per ulteriori informazioni sugli oggetti, consulta Panoramica degli oggetti di Amazon S3.
Chiavi
Una chiave oggetto (o nome chiave) è l'identificatore univoco di un oggetto in un bucket. Per ogni oggetto in un bucket è presente esattamente una chiave. La combinazione di bucket, chiave oggetto e, facoltativamente, ID versione (se il Controllo delle versioni S3 è abilitato per il bucket) identificherà in modo univoco ogni oggetto. Quindi puoi pensare ad Amazon S3 come a una mappa di dati di base tra "bucket + chiave + versione" e l'oggetto stesso.
Si può fare riferimento in modo univoco a ogni oggetto in Amazon S3 tramite la combinazione di endpoint del servizio Web, nome del bucket, chiave e, facoltativamente, una versione. Ad esempio, nell'URL https://, amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpgamzn-s3-demo-bucketphotos/puppy.jpg è la chiave.
Per ulteriori informazioni sulle chiavi degli oggetti, consulta Denominazione di oggetti Amazon S3.
Funzione Controllo delle versioni S3
Puoi utilizzare Controllo delle versioni S3 per conservare più versioni di un oggetto nello stesso bucket. Puoi utilizzare Controllo delle versioni S3 per conservare, recuperare e ripristinare qualsiasi versione di ogni oggetto archiviato nei bucket . Puoi facilmente eseguire il ripristino dopo errori dell'applicazione e operazioni non intenzionali dell'utente.
Per ulteriori informazioni, consulta Conservazione di più versioni degli oggetti con Controllo delle versioni S3.
ID versione
Se abiliti Controllo delle versioni S3 per un bucket, Amazon S3 genera un ID versione univoco per tutti gli oggetti aggiunti a tale bucket. Gli oggetti già esistenti nel bucket al momento dell'attivazione del controllo delle versioni hanno un ID versione null. Se modifichi questi (o altri) oggetti con altre operazioni, come CopyObjecte, i nuovi oggetti ottengono un ID di versione PutObjectunivoco.
Per ulteriori informazioni, consulta Conservazione di più versioni degli oggetti con Controllo delle versioni S3.
Policy del bucket
Una bucket policy è una policy basata sulle risorse AWS Identity and Access Management (IAM) che puoi utilizzare per concedere le autorizzazioni di accesso al tuo bucket e agli oggetti in esso contenuti. Solo il proprietario del bucket può associare una policy a un bucket. Le autorizzazioni allegate a un bucket si applicano a tutti gli oggetti del bucket di proprietà del proprietario del bucket. Le policy di bucket sono limitate a dimensioni di 20 KB.
Le policy Bucket utilizzano un linguaggio di policy di JSON-based accesso che è standard in tutti. AWS Puoi utilizzare policy di bucket per aggiungere o negare autorizzazioni per gli oggetti in un bucket. Le policy di bucket approvano o negano le richieste in base agli elementi che contengono, inclusi richiedente, operazioni S3, risorse e aspetti o condizioni della richiesta (ad esempio, l'indirizzo IP utilizzato per inviarla). Ad esempio, puoi creare una policy che conceda autorizzazioni tra account per caricare oggetti in un bucket S3 garantendo al contempo che il proprietario del bucket abbia il pieno controllo degli oggetti caricati. Per ulteriori informazioni, consulta Esempi di policy del bucket Amazon S3.
Nella policy di bucket puoi utilizzare caratteri jolly negli Amazon Resource Name (ARN) e altri valori per concedere autorizzazioni a un sottoinsieme di oggetti. Ad esempio, puoi controllare l'accesso a gruppi di oggetti che iniziano con un prefisso comune o terminano con una determinata estensione, come .html.
Punti di accesso S3
I punti di accesso Amazon S3 sono endpoint di rete denominati con policy di accesso dedicate che descrivono come è possibile accedere ai dati utilizzando tali endpoint. I punti di accesso sono collegati a un’origine dati sottostante, ad esempio un bucket per uso generico, un bucket di directory o un volume FSx per OpenZFS, che è possibile utilizzare per eseguire operazioni sugli oggetti S3, ad esempio GetObject e PutObject. Gli Access Point semplificano la gestione dell'accesso ai dati su vasta scala per set di dati condivisi in Amazon S3.
Ogni punto di accesso ha una propria policy. È inoltre possibile configurare le impostazioni di Blocco dell’accesso pubblico per ciascun punto di accesso collegato a un bucket. Per limitare l'accesso ai dati di Amazon S3 a una rete privata puoi configurare qualsiasi punto di accesso per accettare le richieste solo da un virtual private cloud (VPC).
Per ulteriori informazioni sui punti di accesso per bucket per uso generico, consulta Gestione dell'accesso a set di dati condivisi con punti di accesso. Per ulteriori informazioni sui punti di accesso per bucket di directory, consulta Gestione dell’accesso ai set di dati condivisi in bucket di directory con punti di accesso.
Liste di controllo degli accessi (ACL)
È possibile utilizzare le ACL per fornire autorizzazioni di lettura e scrittura per singoli oggetti e bucket per uso generico agli utenti autorizzati. A ogni oggetto e bucket per uso generico è collegata una ACL come risorsa secondaria. L'ACL definisce a quali Account AWS gruppi è concesso l'accesso e il tipo di accesso. Le ACL sono un meccanismo di controllo degli accessi che precede IAM. Per ulteriori informazioni sulle ACL, consulta Panoramica delle liste di controllo accessi (ACL).
S3 Proprietà dell'oggetto è un'impostazione a livello di bucket Amazon S3 che è possibile utilizzare per controllare la proprietà degli oggetti caricati nel bucket e per disabilitare o abilitare le liste di controllo degli accessi (ACL). Per impostazione predefinita, Proprietà dell'oggetto è impostata su Proprietario del bucket applicato e tutte le liste di controllo degli accessi (ACL) sono disabilitate. Quando le ACL sono disabilitate, il proprietario del bucket dispone di tutti gli oggetti nel bucket e gestisce l'accesso ad essi in maniera esclusiva utilizzando policy di gestione dell'accesso.
La maggior parte degli attuali casi d'uso in Amazon S3 non richiede più l'uso delle ACL. È consigliabile mantenere le ACL disabilitate, tranne nelle circostanze in cui è necessario controllare individualmente l’accesso per ciascun oggetto. Con le ACL disabilitate, puoi utilizzare le policy per controllare l'accesso a tutti gli oggetti nel bucket, a prescindere da chi ha caricato gli oggetti nel bucket. Per ulteriori informazioni, consulta Controllo della proprietà degli oggetti e disabilitazione degli ACL per il bucket.
Regioni
Puoi scegliere l'area geografica Regione AWS in cui Amazon S3 archivia i bucket che crei. La scelta di una regione permette di ottimizzare la latenza, ridurre al minimo i costi o rispondere ai requisiti normativi. Gli oggetti archiviati in un'altra regione Regione AWS non escono mai dalla regione a meno che non vengano trasferiti o replicati esplicitamente in un'altra regione. Ad esempio, gli oggetti archiviati nella regione Europa (Irlanda) non lasceranno mai tale regione.
Nota
Puoi accedere ad Amazon S3 e alle sue funzionalità solo nelle versioni abilitate per il Regioni AWS tuo account. Per ulteriori informazioni sull'abilitazione di una regione per la creazione e la gestione di AWS risorse, consulta Managing Regioni AWS in the Riferimenti generali di AWS.
Per un elenco degli endpoint e delle regioni Amazon S3 disponibili, consultare la sezione relativa a regioni ed endpoint nella Riferimenti generali di AWS.
Modello di consistenza dati Amazon S3
Amazon S3 offre una forte coerenza di lettura dopo scrittura per le richieste PUT e DELETE di oggetti nel bucket Amazon S3 in generale. Regioni AWS Questo comportamento vale sia per le scritture di nuovi oggetti che per le richieste PUT che sovrascrivono gli oggetti esistenti e le richieste DELETE. Inoltre, le operazioni di lettura su Amazon S3 Select, le liste di controllo accessi Amazon S3, i tag oggetto Amazon S3 e i metadati degli oggetti (ad esempio, l'oggetto HEAD) sono fortemente coerenti.
Gli aggiornamenti a una singola chiave sono atomici. Ad esempio, se esegui una richiesta PUT su una chiave esistente da un thread ed esegui poi una richiesta GET sulla stessa chiave da un secondo thread contemporaneamente, otterrai i vecchi dati o i nuovi dati, ma mai dati parziali o danneggiati.
Amazon S3 ottiene un'alta disponibilità replicando i dati su più server in data center AWS . Se una richiesta PUT ha esito positivo, i dati verranno archiviati in totale sicurezza. Qualsiasi lettura (richiesta GET o LIST) avviata dopo la ricezione di una risposta PUT riuscita restituirà i dati scritti dall'operazione PUT. Di seguito sono riportati alcuni esempi di questo comportamento.
-
Un processo scrive un nuovo oggetto in Amazon S3 ed elenca immediatamente le chiavi nel relativo bucket. Il nuovo oggetto viene visualizzato nell'elenco.
-
Un processo sostituisce un oggetto esistente e tenta immediatamente di effettuarne la lettura. Amazon S3 restituisce i nuovi dati.
-
Un processo elimina un oggetto esistente e tenta immediatamente di effettuarne la lettura. Amazon S3 non restituisce alcun dato poiché l'oggetto è stato eliminato.
-
Un processo elimina un oggetto esistente ed elenca immediatamente le chiavi nel relativo bucket. L'oggetto non viene visualizzato nell'elenco.
Nota
-
Amazon S3 non supporta il blocco degli oggetti per istanze di scrittura simultanee. Se vengono effettuate simultaneamente due richieste PUT per la stessa chiave, la richiesta con l'ultimo timestamp ha la precedenza. Se questo rappresenta un problema, devi creare un meccanismo di blocco degli oggetti nell'applicazione.
-
Gli aggiornamenti sono basati su chiave. Non è possibile eseguire aggiornamenti atomici tra le chiavi. Non si può ad esempio eseguire l'aggiornamento di una chiave dipendente dall'aggiornamento di un'altra chiave, a meno che non si progetti questa funzionalità nell'applicazione.
Le configurazioni dei bucket hanno un modello di consistenza. In particolare, questo significa che:
-
Se elimini un bucket e visualizzi immediatamente tutti i bucket, il bucket eliminato potrebbe comunque essere visualizzato nell'elenco.
-
Se abiliti il controllo delle versioni su un bucket per la prima volta, potrebbe essere necessario un breve periodo di tempo per la propagazione completa della modifica. Suggeriamo di attendere 15 minuti dopo aver abilitato il controllo delle versioni prima di eseguire operazioni di scrittura (richieste PUT o DELETE) sugli oggetti nel bucket.
Applicazioni simultanee
In questa sezione sono riportati esempi di comportamento previsto da Amazon S3 quando più client scrivono sugli stessi articoli.
In questo esempio, entrambe le richieste di scrittura W1 e W2 terminano prima dell'avvio delle letture R1 e R2. Poiché S3 è fortemente consistente, R1 e R2 restituiscono entrambi color = ruby.
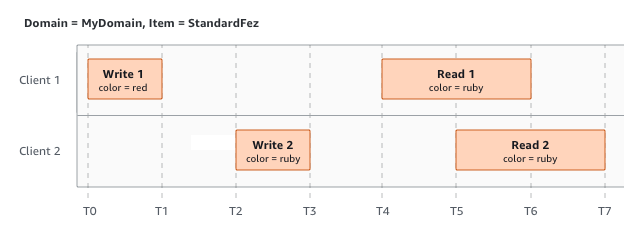
Nell'esempio successivo, la scrittura W2 non termina prima dell'avvio della lettura R1. Pertanto, R1 potrebbe restituire color = ruby o color = garnet. Tuttavia, dal momento che W1 e W2 terminano prima dell'inizio di R2, R2 restituisce color =
garnet.
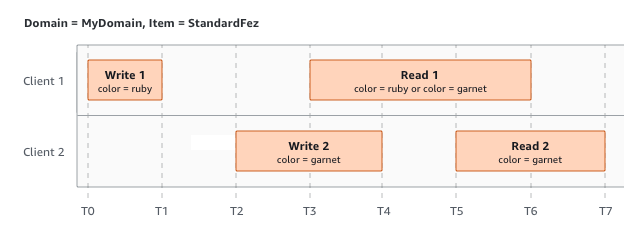
Nell'ultimo esempio, W2 inizia prima che W1 abbia ricevuto una notifica. Pertanto, queste scritture sono considerate simultanee. Amazon S3 utilizza internamente la semantica last-writer-wins per determinare quale scrittura ha la precedenza. Tuttavia, l'ordine in cui Amazon S3 riceve le richieste e l'ordine in cui le applicazioni ricevono le notifiche non possono essere previsti a causa di vari fattori quali la latenza della rete. Ad esempio, W2 potrebbe essere avviata da un'istanza Amazon EC2 nella stessa regione, mentre W1 potrebbe essere avviata da un host più lontano. Il modo migliore per determinare il valore finale è eseguire una lettura dopo che entrambe le scritture sono state riconosciute.

Servizi correlati
Dopo aver caricato i dati in Amazon S3, puoi utilizzarli con altri AWS servizi. Di seguito vengono riportati i servizi che potresti utilizzare più di frequente:
-
Amazon Elastic Compute Cloud (Amazon EC2)
: fornisce capacità di calcolo scalabile e sicura in Cloud AWS. L'utilizzo di Amazon EC2 elimina la necessità di investimenti anticipati in hardware e ti permette di sviluppare e implementare più rapidamente le applicazioni. Puoi utilizzare Amazon EC2 per avviare il numero di server virtuali necessari, configurare la sicurezza e i servizi di rete, nonché gestire l’archiviazione. -
Amazon EMR
: consente ad aziende, ricercatori, analisti e sviluppatori di elaborare un'enorme quantità di dati in modo semplice ed economico. Amazon EMR usa un framework Hadoop gestito eseguito sull'infrastruttura a livello Web di Amazon EC2 e Amazon S3. -
AWS Transfer Family
: fornisce supporto completamente gestito per i trasferimenti di file diretti in entrata e uscita da Amazon S3 o Amazon Elastic File System (Amazon EFS) utilizzando i protocolli SFTP, FTPS e FTP.
Accesso ad Amazon S3
Puoi lavorare con Amazon S3 nei modi descritti di seguito:
Console di gestione AWS
La console è un'interfaccia utente basata sul Web per la gestione di Amazon S3 AWS e delle risorse. Se ti sei registrato a Account AWS, puoi accedere alla console Amazon S3 accedendo Console di gestione AWS e scegliendo S3 dalla Console di gestione AWS home page.
AWS Command Line Interface
Puoi usare gli strumenti della AWS riga di comando per impartire comandi o creare script dalla riga di comando del tuo sistema per eseguire attività AWS (incluso S3).
Il AWS Command Line Interface (AWS CLI)
AWS SDK
AWS fornisce SDK (kit di sviluppo software) costituiti da librerie e codice di esempio per vari linguaggi e piattaforme di programmazione (Java, Python, Ruby, .NET, iOS, Android e così via). Gli AWS SDK offrono un modo pratico per creare l'accesso programmatico a S3 e. AWS Amazon S3 è un servizio REST. Puoi inviare richieste ad Amazon S3 utilizzando le librerie AWS SDK, che racchiudono l'API REST di Amazon S3 sottostante e semplificano le attività di programmazione. Ad esempio, gli SDK si occupano di attività quali il calcolo delle firme, la firma crittografica delle richieste, la gestione degli errori e la ripetizione automatica delle richieste. Per informazioni sugli AWS SDK, incluso come scaricarli e installarli, consulta Tools for. AWS
Ogni interazione con Amazon S3 è autenticata o anonima. Se utilizzi gli AWS SDK, le librerie calcolano la firma per l'autenticazione dalle chiavi che fornisci. Per ulteriori informazioni su come effettuare richieste ad Amazon S3, consulta Esecuzione di richieste.
API REST di Amazon S3
L'architettura di Amazon S3 è ideata per essere indipendente dal linguaggio di programmazione e per utilizzare le interfacce supportate da AWS per archiviare e recuperare oggetti. Puoi accedere a S3 e AWS a livello di programmazione utilizzando l'API REST di Amazon S3. L'API REST è un'interfaccia HTTP per Amazon S3. Con l'API REST, uilizzi le richieste HTTP standard per creare, recuperare ed eliminare bucket e oggetti.
Per utilizzare l'API REST, puoi servirti di qualunque kit di strumenti in grado di supportare HTTP. Puoi anche utilizzare un browser per recuperare gli oggetti, purché siano leggibili in modo anonimo.
Poiché l'API REST utilizza codici di stato e intestazioni HTTP standard, i kit di strumenti e i browser standard funzionano come previsto. In alcune aree sono state aggiunte funzionalità ad HTTP, ad esempio le intestazioni per il supporto del controllo accessi. Le nuove funzionalità sono state in tali casi aggiunte in modo da essere conformi allo stile di utilizzo di HTTP standard.
Se effettui chiamate API REST direttamente dall'applicazione in uso, devi scrivere il codice per calcolare la firma e aggiungerlo alla richiesta. Per ulteriori informazioni su come effettuare richieste ad Amazon S3, consulta Esecuzione di richieste nella documentazione di riferimento delle API Amazon S3.
Nota
Il supporto API SOAP su HTTP è obsoleto ma è ancora disponibile su HTTPS. Le funzioni più recenti di Amazon S3 non sono supportate per SOAP. Ti consigliamo di utilizzare l'API REST o gli AWS SDK.
Prezzi di Amazon S3
La determinazione dei prezzi di Amazon S3 è stata concepita in modo da non dover pianificare requisiti di storage per la tua applicazione. La maggior parte dei provider di archiviazione richiede l'acquisto di una quantità predeterminata di capacità di archiviazione e di trasferimento di rete. In questi casi, se superi questa capacità, il servizio viene disattivato o ti vengono addebitati costi aggiuntivi elevati. Se non si supera tale capacità, si pagherà comunque l'importo per l'intera capacità.
Con Amazon S3 si paga esclusivamente ciò che si utilizza, senza costi nascosti o aggiuntivi. Questo modello ti offre un servizio a costo variabile che può crescere con la tua azienda, offrendoti al contempo i vantaggi in termini di costi dell'infrastruttura. AWS Per ulteriori informazioni, consulta Prezzi di Amazon S3
Quando ti registri AWS, il tuo Account AWS viene automaticamente registrato per tutti i servizi in AWS, incluso Amazon S3. Tuttavia, vengono addebitati solo i servizi che utilizzi. Se sei un nuovo cliente Amazon S3, puoi iniziare a utilizzare Amazon S3 gratuitamente. Per ulteriori informazioni, consulta Piano gratuito AWS
Per vedere la tua fattura, vai sul Pannello di controllo Gestione fatturazione e costi nella console Gestione costi e fatturazione AWS
Conformità PCI DSS
Amazon S3 supporta l'elaborazione, l'archiviazione e la trasmissione di dati di carte di credito da parte di un esercente o di un provider di servizi, oltre a essere conforme allo standard Payment Card Industry Data Security Standard (PCI DSS). Per ulteriori informazioni su PCI DSS, incluso come richiedere una copia del PCI AWS Compliance Package, vedere PCI
