Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Come funziona Knowledge Base per Amazon Bedrock
Knowledge Base per Amazon Bedrock ti consente di sfruttare la generazione potenziata da recupero dati (RAG), una tecnica popolare che prevede l’estrazione di informazioni da un archivio dati per arricchire le risposte generate dai modelli linguistici di grandi dimensioni (LLM). Quando configuri una knowledge base con le tue origini dati, l’applicazione può eseguire query sulla knowledge base per restituire informazioni utili a rispondere alla query con citazioni dirette dalle origini o con risposte naturali generate dai risultati della query.
Con Knowledge Base per Amazon Bedrock, è possibile creare applicazioni arricchite dal contesto ottenuto dall’esecuzione di query su una knowledge base. Consente di accelerare il time to market astraendo dal lavoro impegnativo della creazione di pipeline e fornendo una soluzione RAG pronta all'uso per ridurre i tempi di costruzione della tua applicazione. L'aggiunta di una knowledge base aumenta anche l'efficacia dei costi, eliminando la necessità di addestrare continuamente il modello per poter sfruttare i dati privati.
I seguenti diagrammi illustrano schematicamente come viene eseguita la RAG. La knowledge base semplifica la configurazione e l'implementazione della RAG automatizzando diverse fasi di questo processo.
Pre-elaborazione di dati non strutturati
Una pratica comune per consentire un recupero efficace dai dati privati non strutturati (dati che non esistono in un archivio di dati strutturato) consiste nel convertire i dati in testo e dividerli in parti gestibili. Le parti o blocchi vengono quindi convertiti in embedding e scritti in un indice vettoriale, mantenendo al contempo una mappatura al documento originale. Questi incorporamenti vengono utilizzati per determinare la somiglianza semantica tra le query e il testo delle origini dati. L'immagine seguente illustra la pre-elaborazione dei dati per il database vettoriale.
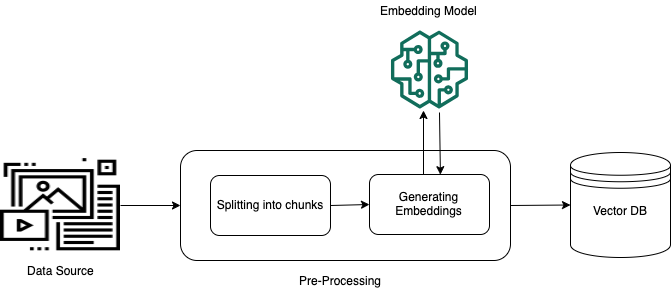
Gli embedding vettoriali sono una serie di numeri che rappresentano ogni blocco di testo. Un modello converte ogni blocco di testo in serie di numeri, note come vettori, in modo che i testi possano essere confrontati matematicamente. Questi vettori possono essere numeri a virgola mobile (float32) o numeri binari. La maggior parte dei modelli di embedding supportati da Amazon Bedrock utilizza vettori a virgola mobile per impostazione predefinita. Tuttavia, alcuni modelli supportano i vettori binari. Se scegli un modello di embedding binario, devi scegliere anche un modello e un archivio vettoriale che supporti i vettori binari.
I vettori binari, che utilizzano solo 1 bit per dimensione, sono meno costosi, in termini di archiviazione, dei vettori a virgola mobile (float32), che utilizzano 32 bit per dimensione. D’altra parte, non sono precisi come i vettori a virgola mobile nella rappresentazione del testo.
L’esempio seguente mostra una parte di testo in tre rappresentazioni:
| Rappresentazione | Valore |
|---|---|
| Testo | “Amazon Bedrock utilizza modelli di fondazione ad alte prestazioni delle principali aziende IA e di Amazon.” |
| Vettore a virgola mobile | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| Vettore binario | [1,1,0,0,0, ...] |
Esecuzione in fase di runtime
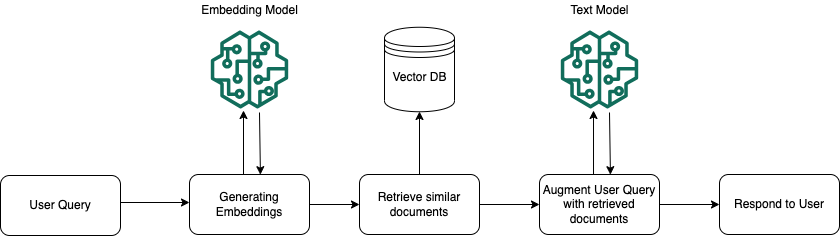
In fase di runtime, viene utilizzato un modello di incorporamento per convertire la query dell'utente in un vettore. L'indice vettoriale viene quindi interrogato per trovare blocchi semanticamente simili alla query dell'utente confrontando i vettori del documento con il vettore di query dell'utente. Nel passaggio finale, il prompt dell'utente viene aumentato con il contesto aggiuntivo proveniente dai blocchi recuperati dall'indice vettoriale. Il prompt insieme al contesto aggiuntivo viene quindi inviato al modello per generare una risposta per l'utente. L'immagine seguente mostra come la RAG opera in fase di runtime per migliorare le risposte alle query degli utenti.
Per ulteriori informazioni su come trasformare i dati in una knowledge base, su come eseguire query sulla knowledge base dopo averla configurata e sulle personalizzazioni che è possibile applicare all’origine dati durante l’importazione, consulta i seguenti argomenti:
Argomenti
