Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Annotazione di file PDF
Prima di poter annotare i PDF di allenamento in SageMaker AI Ground Truth, completa i seguenti prerequisiti:
-
Installa python3.8.x
-
Installazione di jq
-
Installa la AWS CLI
Se stai usando la regione us-east-1, puoi saltare l'installazione della CLI perché è già installata con AWS il tuo ambiente Python. In questo caso, crei un ambiente virtuale per usare Python 3.8 in Cloud9. AWS
-
AWS Configura le tue credenziali
-
Crea una forza lavoro SageMaker AI Ground Truth privata per supportare le annotazioni
Assicurati di registrare il nome del team di lavoro che hai scelto nella tua nuova forza lavoro privata, mentre lo usi durante l'installazione.
Argomenti
Configurazione dell'ambiente
-
Se usi Windows, installa Cygwin
; se usi Linux o Mac, salta questo passaggio. -
Scarica gli artefatti di annotazione
da. GitHub Decomprimere il file. -
Dalla finestra del terminale, accedi alla cartella decompressa (amazon-comprehend-semi-structured-documents-annotation-tools-main).
-
Questa cartella include una scelta da eseguire per installare le dipendenze, configurare un virtualenv Python e distribuire le risorse richieste.
MakefilesControlla il file readme per fare la tua scelta. -
L'opzione consigliata utilizza un solo comando per installare tutte le dipendenze in un virtualenv, crea lo stack a partire dal modello e distribuisce lo CloudFormation stack all'utente con una guida interattiva. Account AWS Esegui il comando seguente:
make ready-and-deploy-guidedQuesto comando presenta una serie di opzioni di configurazione. Assicurati che il tuo Regione AWS sia corretto. Per tutti gli altri campi, puoi accettare i valori predefiniti o inserire valori personalizzati. Se modifichi il nome CloudFormation dello stack, scrivilo quando ne hai bisogno nei passaggi successivi.
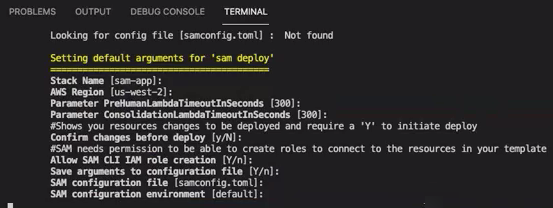
Lo CloudFormation stack crea e gestisce i AWS lambda
, i ruoli AWS IAM e i bucket AWS S3 necessari per lo strumento di annotazione. Puoi esaminare ciascuna di queste risorse nella pagina dei dettagli dello stack nella console. CloudFormation
-
Il comando richiede di avviare la distribuzione. CloudFormation crea tutte le risorse nella regione specificata.
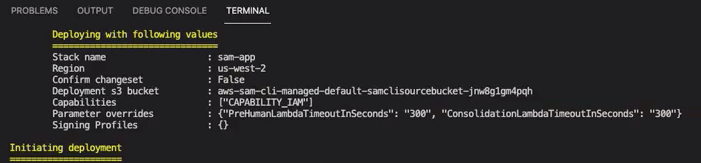
Quando lo stato dello CloudFormation stack passa a creazione/completamento, le risorse sono pronte per l'uso.
Caricamento di un PDF in un bucket S3
Nella sezione Configurazione, hai distribuito uno CloudFormation stack che crea un bucket S3 denominato comprehend-semi-structured-documents-$ {} -$ {}. AWS::Region AWS::AccountId Ora carichi i tuoi documenti PDF di origine in questo bucket.
Nota
Questo secchio contiene i dati necessari per il tuo lavoro di etichettatura. La policy Lambda Execution Role concede l'autorizzazione alla funzione Lambda per accedere a questo bucket.
Puoi trovare il nome del bucket S3 nei dettagli dello CloudFormation stack usando il tasto ''. SemiStructuredDocumentsS3Bucket
-
Crea una nuova cartella nel bucket S3. Assegna un nome a questa nuova cartella «src».
-
Aggiungi i tuoi file sorgente PDF alla cartella 'src'. In una fase successiva, aggiungi annotazioni a questi file per addestrare il tuo riconoscitore.
-
(Facoltativo) Ecco un esempio di AWS CLI che puoi usare per caricare i tuoi documenti sorgente da una directory locale in un bucket S3:
aws s3 cp --recursivelocal-path-to-your-source-docss3://deploy-guided/src/Oppure, con la tua regione e il tuo ID account:
aws s3 cp --recursivelocal-path-to-your-source-docss3://deploy-guided-Region-AccountID/src/ Ora hai una forza lavoro SageMaker AI Ground Truth privata e hai caricato i tuoi file sorgente nel bucket S3, deploy-guided/src/; sei pronto per iniziare ad annotare.
Creazione di un lavoro di annotazione
Lo script comprehend-ssie-annotation-tool-cli.py nella bin directory è un semplice comando wrapper che semplifica la creazione di un processo di etichettatura AI Ground SageMaker Truth. Lo script python legge i documenti sorgente dal bucket S3 e crea un corrispondente file manifest a pagina singola con un documento sorgente per riga. Lo script crea quindi un processo di etichettatura, che richiede il file manifest come input.
Lo script python utilizza il bucket e lo CloudFormation stack S3 configurati nella sezione Configurazione. I parametri di input richiesti per lo script includono:
-
input-s3-path: Uri S3 per i documenti sorgente che hai caricato nel tuo bucket S3. Ad esempio:
s3://deploy-guided/src/. Puoi anche aggiungere la tua regione e l'ID dell'account a questo percorso. Ad esempio:s3://deploy-guided-Region-AccountID/src/. -
cfn-name: il nome dello CloudFormation stack. Se hai usato il valore predefinito per il nome dello stack, il tuo cfn-name è sam-app.
-
work-team-name: il nome della forza lavoro che hai creato quando hai creato la forza lavoro privata in AI Ground Truth. SageMaker
-
job-name-prefix: il prefisso per il lavoro di etichettatura AI Ground SageMaker Truth. Nota che esiste un limite di 29 caratteri per questo campo. A questo valore viene aggiunto un timestamp. Ad esempio:
my-job-name-20210902T232116. -
entity-types: le entità che desideri utilizzare durante il processo di etichettatura, separate da virgole. Questo elenco deve includere tutte le entità che desideri annotare nel set di dati di addestramento. Il lavoro di etichettatura Ground Truth visualizza solo queste entità per consentire agli annotatori di etichettare il contenuto nei documenti PDF.
Per visualizzare gli argomenti aggiuntivi supportati dallo script, utilizzate l'-hopzione per visualizzare il contenuto della guida.
Eseguite lo script seguente con i parametri di input come descritto nell'elenco precedente.
python bin/comprehend-ssie-annotation-tool-cli.py \ --input-s3-path s3://deploy-guided-Region-AccountID/src/ \ --cfn-namesam-app\ --work-team-namemy-work-team-name\ --regionus-east-1\ --job-name-prefixmy-job-name-20210902T232116\ --entity-types "EntityA,EntityB,EntityC" \ --annotator-metadata "key=info,value=sample,key=Due Date,value=12/12/2021"Lo script produce il seguente output:
Downloaded files to temp local directory /tmp/a1dc0c47-0f8c-42eb-9033-74a988ccc5aa Deleted downloaded temp files from /tmp/a1dc0c47-0f8c-42eb-9033-74a988ccc5aa Uploaded input manifest file to s3://comprehend-semi-structured-documents-us-west-2-123456789012/input-manifest/my-job-name-20220203-labeling-job-20220203T183118.manifest Uploaded schema file to s3://comprehend-semi-structured-documents-us-west-2-123456789012/comprehend-semi-structured-docs-ui-template/my-job-name-20220203-labeling-job-20220203T183118/ui-template/schema.json Uploaded template UI to s3://comprehend-semi-structured-documents-us-west-2-123456789012/comprehend-semi-structured-docs-ui-template/my-job-name-20220203-labeling-job-20220203T183118/ui-template/template-2021-04-15.liquid Sagemaker GroundTruth Labeling Job submitted: arn:aws:sagemaker:us-west-2:123456789012:labeling-job/my-job-name-20220203-labeling-job-20220203t183118 (amazon-comprehend-semi-structured-documents-annotation-tools-main) user@3c063014d632 amazon-comprehend-semi-structured-documents-annotation-tools-main %
Annotazione con SageMaker AI Ground Truth
Ora che hai configurato le risorse richieste e creato un processo di etichettatura, puoi accedere al portale di etichettatura e annotare i tuoi PDF.
-
Accedi alla console SageMaker AI
utilizzando i browser Web Chrome o Firefox. -
Seleziona Etichettatura della forza lavoro e scegli Privato.
-
In Riepilogo della forza lavoro privata, seleziona l'URL di accesso al portale di etichettatura che hai creato con la tua forza lavoro privata. Accedi con le credenziali appropriate.
Se non vedi nessun lavoro elencato, non preoccuparti: l'aggiornamento può richiedere del tempo, a seconda del numero di file che hai caricato per l'annotazione.
-
Seleziona l'attività e, nell'angolo in alto a destra, scegli Inizia a lavorare per aprire la schermata di annotazione.
Vedrai uno dei tuoi documenti aperto nella schermata di annotazione e, sopra di esso, i tipi di entità che hai fornito durante la configurazione. A destra dei tipi di entità, c'è una freccia che puoi usare per navigare tra i tuoi documenti.
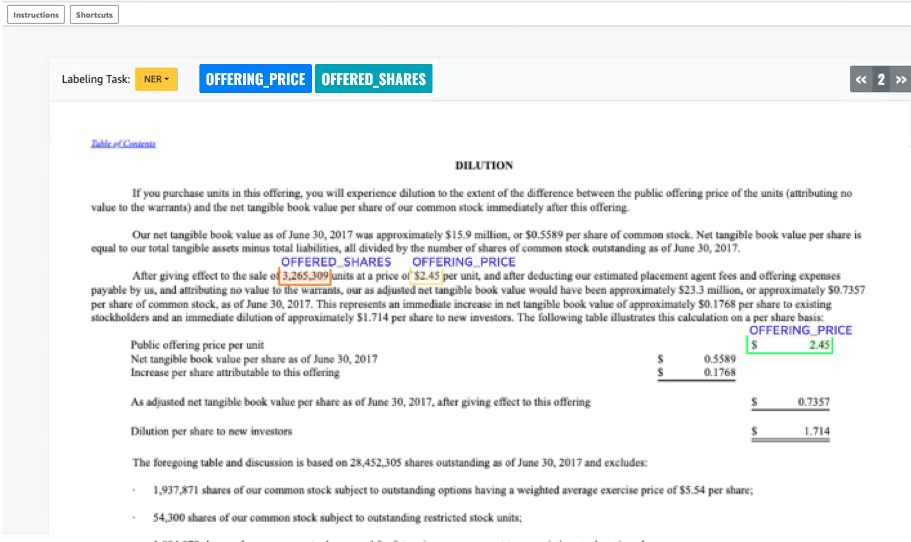
Annota il documento aperto. Puoi anche rimuovere, annullare o etichettare automaticamente le tue annotazioni su ogni documento; queste opzioni sono disponibili nel pannello a destra dello strumento di annotazione.
Per usare il tag auto, annota un'istanza di una delle tue entità; tutte le altre istanze di quella parola specifica vengono quindi annotate automaticamente con quel tipo di entità.
Una volta terminato, seleziona Invia in basso a destra, quindi usa le frecce di navigazione per passare al documento successivo. Ripeti l'operazione finché non avrai annotato tutti i tuoi PDF.
Dopo aver annotato tutti i documenti di formazione, puoi trovare le annotazioni in formato JSON nel bucket Amazon S3 in questa posizione:
/output/your labeling job name/annotations/
La cartella di output contiene anche un file manifest di output, che elenca tutte le annotazioni all'interno dei documenti di formazione. È possibile trovare il file manifesto di output nella seguente posizione.
/output/your labeling job name/manifests/
