Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitoraggio degli endpoint Amazon Comprehend
È possibile regolare la velocità effettiva dell'endpoint aumentando o diminuendo il numero di unità di inferenza (UI). Per ulteriori informazioni sull'aggiornamento dell'endpoint, consulta. Aggiornamento degli endpoint Amazon Comprehend
Puoi determinare come regolare al meglio il throughput del tuo endpoint monitorandone l'utilizzo con la console Amazon CloudWatch .
Monitora l'utilizzo degli endpoint con CloudWatch
-
Accedi a AWS Management Console e apri la CloudWatch console
. -
A sinistra, scegli Metriche e seleziona Tutte le metriche.
-
In Tutte le metriche, scegli Comprehend.
-
La CloudWatch console visualizza le dimensioni per le metriche Comprehend. Scegliete la dimensione. EndpointArn
La console mostra ProvisionedInferenceUnits, RequestedInferenceUnitsConsumedInferenceUnits, e InferenceUtilizationper ciascuno dei tuoi endpoint.

Seleziona le quattro metriche e vai alla scheda Metriche grafiche.
-
Imposta le colonne delle statistiche per RequestedInferenceUnitse su Sum. ConsumedInferenceUnits
-
Imposta la colonna Statistica InferenceUtilizationper Sum.
-
Imposta la colonna Statistica ProvisionedInferenceUnitsper su Media.
-
Modifica la colonna Periodo per tutte le metriche su 1 minuto.
-
Seleziona InferenceUtilizatione seleziona la freccia per spostarla su un asse Y separato.
Il grafico è pronto per l'analisi.
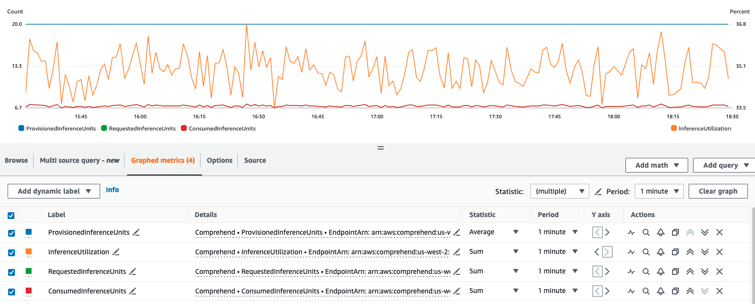
In base alle CloudWatch metriche, puoi anche impostare la scalabilità automatica per regolare automaticamente il throughput del tuo endpoint. Per ulteriori informazioni sull'utilizzo della scalabilità automatica con gli endpoint, consulta. Scalabilità automatica con endpoint
-
ProvisionedInferenceUnits- Questa metrica rappresenta il numero di UI medie fornite al momento della richiesta.
-
RequestedInferenceUnits- Si basa sull'utilizzo di ogni richiesta inviata al servizio che è stata inviata per essere elaborata. Questo può essere utile per confrontare la richiesta inviata per essere elaborata con quella effettivamente elaborata senza ricevere throttling ()ConsumedInferenceUnits. Il valore di questa metrica viene calcolato prendendo il numero di caratteri inviati per l'elaborazione e dividendolo per il numero di caratteri che possono essere elaborati in un minuto per 1 UI.
-
ConsumedInferenceUnits- Si basa sull'utilizzo di ogni richiesta inviata al servizio che è stata elaborata con successo (non limitata). Questo può essere utile quando si confronta ciò che si consuma con le UI fornite. Il valore di questa metrica viene calcolato prendendo il numero di caratteri elaborati e dividendolo per il numero di caratteri che possono essere elaborati in un minuto per 1 UI.
-
InferenceUtilization- Viene emesso per richiesta. Questo valore viene calcolato prendendo le UI consumate definite in ConsumedInferenceUnitse dividendole per ProvisionedInferenceUnitse convertendole in una percentuale su 100.
Nota
Tutte le metriche vengono emesse solo per le richieste riuscite. La metrica non verrà visualizzata se proviene da una richiesta limitata o non riuscita a causa di un errore interno del server o di un errore del cliente.
