Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Apprendimento per rinforzo in AWS DeepRacer
Nell'apprendimento per rinforzo, un agente, come un DeepRacer veicolo AWS fisico o virtuale, con l'obiettivo di raggiungere un obiettivo prefissato interagisce con un ambiente per massimizzare la ricompensa totale dell'agente. L'agente esegue un'azione, guidato da una strategia definita come policy, in un determinato stato dell'ambiente e raggiunge un nuovo stato. A ogni azione è associata una ricompensa immediata. La ricompensa è un parametro dell'auspicabilità dell'azione. Questa ricompensa immediata deve essere restituita dall'ambiente.
L'obiettivo dell'apprendimento per rinforzo in AWS DeepRacer è apprendere la politica ottimale in un determinato ambiente. L'apprendimento è un processo iterativo di prove ed errori. L'agente esegue l'azione iniziale casuale per raggiungere un nuovo stato. Quindi l'agente itera il passaggio dal nuovo stato al successivo. Nel corso del tempo, l'agente identifica azioni associate alle massime ricompense a lungo termine. L'interazione dell'agente da uno stato iniziale a uno stato terminale è definita episodio.
Il disegno seguente illustra questo processo di apprendimento:
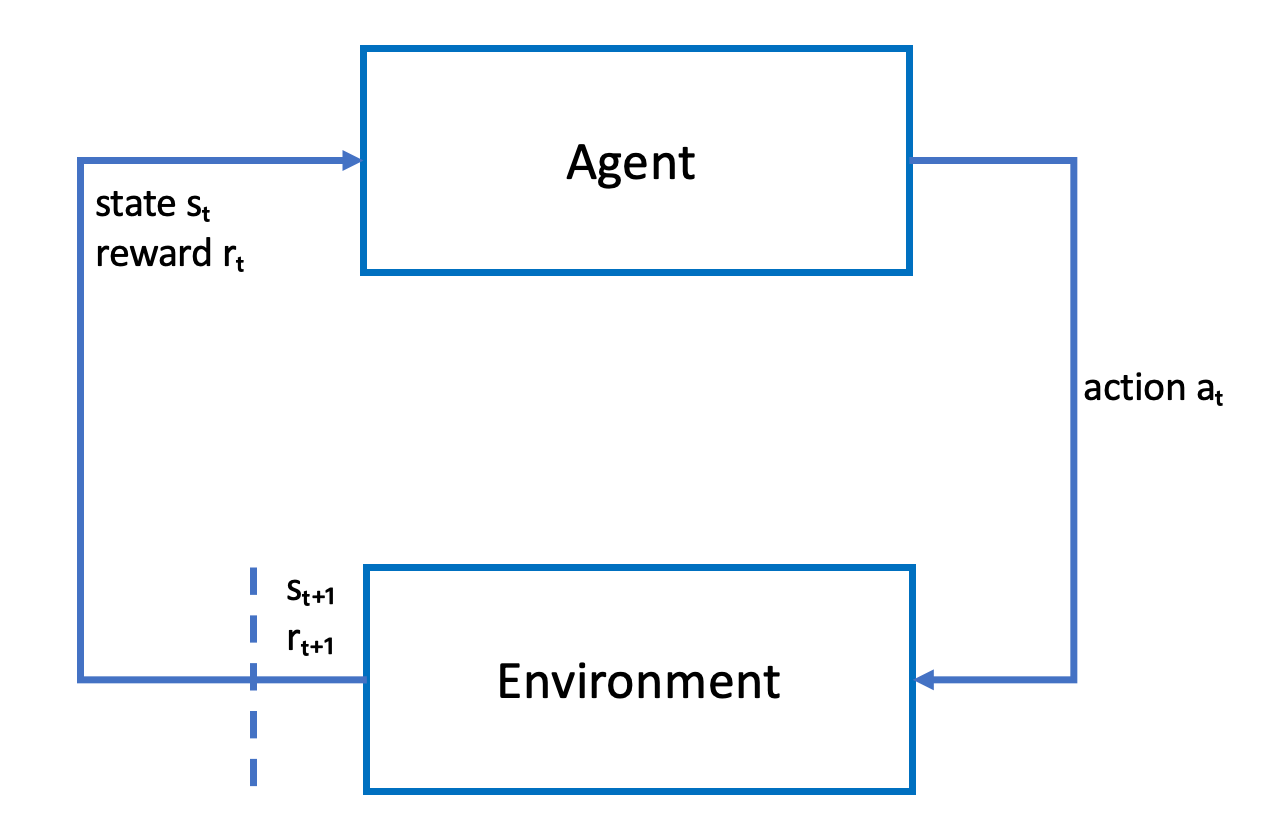
L'agente incarna una rete neurale che rappresenta una funzione per l'approssimazione alla policy dell'agente. L'immagine dalla fotocamera frontale del veicolo è lo stato dell'ambiente e l'azione dell'agente viene definita dalla sua velocità e dai suoi angoli di sterzata.
L'agente riceve ricompense positive se rimane in pista per completare la corsa e ricompense negative in caso di uscita dal tracciato. Un episodio inizia con l'agente in un punto della pista e termina quando esce di pista o completa un giro.
Nota
A rigor di termini, lo stato dell'ambiente fa riferimento a tutti gli elementi significativi per il problema. Ad esempio, la posizione del veicolo in pista e la forma di quest'ultima. L'immagine trasmessa dalla telecamera montata sulla parte anteriore del veicolo non cattura l'intero stato dell'ambiente. Per questo motivo, l'ambiente è considerato parzialmente osservato e l'input fornito all'agente viene definito osservazione anziché stato. Per semplicità, utilizzeremo i termini stato e osservazione in modo intercambiabile in tutta la documentazione.
L'addestramento dell'agente in un ambiente simulato presenta i seguenti vantaggi:
-
La simulazione può stimare l'avanzamento dell'agente e identificare il momento di uscita dal circuito per calcolare una ricompensa.
-
La simulazione solleva il trainer dal compito noioso di reimpostare il veicolo ogni volta che esce di pista, come avviene in un ambiente fisico.
-
La simulazione può accelerare l'addestramento.
-
La simulazione consente di controllare meglio le condizioni ambientali, ad esempio selezionando diversi percorsi, sfondi e condizioni del veicolo.
L'alternativa all'apprendimento per rinforzo è l'apprendimento supervisionato, anche definito apprendimento per imitazione. Di seguito viene utilizzato un set di dati noto (di tuple [immagine, azione]) raccolto da un determinato ambiente per addestrare l'agente. I modelli addestrati tramite apprendimento per imitazione possono essere applicati alla guida autonoma. Funzionano al meglio solo quando le immagini dalla fotocamera appaiono simili alle immagini nel set di dati di apprendimento. Per una guida eccellente, il set di dati di apprendimento deve essere completo. Al contrario, l'apprendimento per rinforzo non richiede tali sforzi profusi di etichettatura e può essere addestrato interamente nella simulazione. Poiché l'apprendimento per rinforzo inizia con azioni casuali, l'agente apprende una serie di condizioni dell'ambiente e della pista. Questo rende il modello addestrato robusto.
