Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: Nozioni di base su Amazon EMR
Segui un flusso di lavoro per configurare rapidamente un cluster Amazon EMR ed eseguire un'applicazione Spark.
Configurazione del cluster Amazon EMR
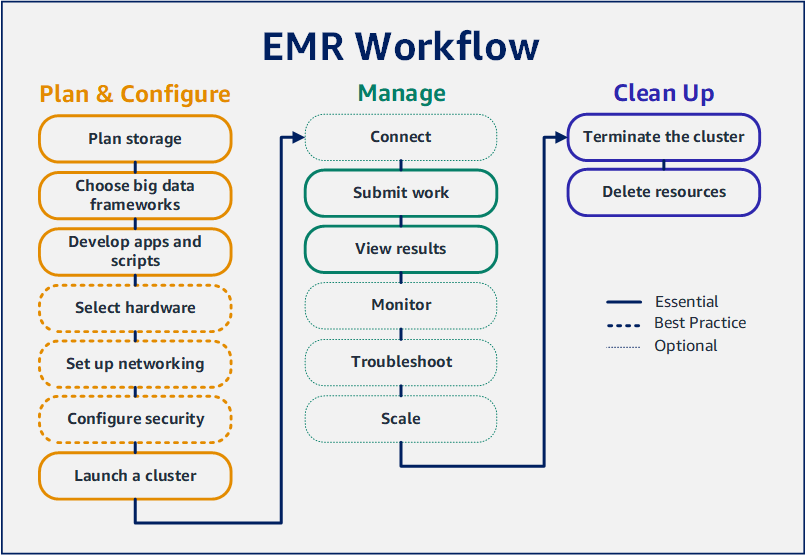
Con Amazon EMR è possibile configurare un cluster per elaborare e analizzare i dati con framework di big data in pochi minuti. Questo tutorial mostra come avviare un cluster di esempio utilizzando Spark e come eseguire un semplice PySpark script archiviato in un bucket Amazon S3. Copre le attività essenziali di Amazon EMR in tre categorie principali del flusso di lavoro: pianificazione e configurazione, gestione e pulizia.
Nel corso del tutorial sono disponibili collegamenti ad argomenti più dettagliati e idee per ulteriori fasi nella sezione Fasi successive. In caso di domande o problemi, contatta il team Amazon EMR sul nostro Forum di discussione
Prerequisiti
-
Prima di avviare un cluster Amazon EMR, assicurati di completare le attività descritte in Prima di configurare Amazon EMR.
Costo
-
Il cluster di esempio che crei viene eseguito in un ambiente reale. Il cluster accumula costi minimi. Per evitare costi aggiuntivi, assicurati di completare le processi di pulizia nell'ultima fase di questo tutorial. I costi maturano alla tariffa al secondo in base ai prezzi di Amazon EMR. I costi variano anche in base alla Regione. Per ulteriori informazioni, consulta Prezzi di Amazon EMR
. -
Potrebbero esserci degli costi minimi per i file di piccole dimensioni che archivi su Amazon S3. Alcuni o tutti i costi per Amazon S3 potrebbero non essere addebitati se rientri nei limiti di utilizzo del AWS piano gratuito. Per ulteriori informazioni, consulta Prezzi di Amazon S3
e Piano gratuito di AWS .
Fase 1: configurare le risorse di dati e avviare un cluster Amazon EMR
Preparare la archiviazione per Amazon EMR
Quando utilizzi Amazon EMR, puoi scegliere tra una varietà di file system per archiviare dati di input, dati di output e file di log. In questo tutorial, utilizzi EMRFS per archiviare i dati in un bucket S3. EMRFS è un'implementazione del file system Hadoop che permette di leggere e scrivere file standard su Amazon S3. Per ulteriori informazioni, consulta Utilizzo di sistemi di storage e file con Amazon EMR.
Per creare un bucket per questo tutorial, segui le istruzioni in Come creare un bucket S3? nella Guida per l'utente della console Amazon Simple Storage Service. Crea il bucket nella stessa AWS regione in cui prevedi di lanciare il tuo cluster Amazon EMR. Ad esempio, US West (Oregon) us-west-2 (Stati Uniti occidentali (Oregon) us-west-2).
I bucket e le cartelle utilizzati con Amazon EMR presentano le seguenti limitazioni:
-
I nomi devono includere lettere minuscole, numeri, punti (.) e trattini (-).
-
I nomi non devono terminare con numeri.
-
Il nome del bucket deve essere univoco per tutti gli account AWS.
-
Una cartella di output deve essere vuota.
Preparazione di un'applicazione con i dati di input per Amazon EMR
Il modo più comune per preparare un'applicazione per Amazon EMR è caricare l'applicazione e i relativi dati di input su Amazon S3. Poi, quando invii il lavoro al cluster, specificare le posizioni Amazon S3 per i vostri script e dati.
In questo passaggio, carichi uno PySpark script di esempio nel tuo bucket Amazon S3. Ti abbiamo fornito uno PySpark script da utilizzare. Lo script elabora i dati di ispezione degli stabilimenti alimentari e restituisce un file dei risultati nel bucket S3. Il file di risultati elenca i primi dieci stabilimenti alimentari con il maggior numero di violazioni di tipo "Red (Rosso)".
Inoltre, carichi dati di input di esempio su Amazon S3 per l'elaborazione dello PySpark script. I dati di input sono una versione modificata dei risultati delle ispezioni condotte dal 2006 al 2020 dal Dipartimento di sanità pubblica della Contea di King, Washington. Per ulteriori informazioni, consulta Dati pubblici della Contea di King: dati di ispezione sugli stabilimenti alimentari
name,inspection_result,inspection_closed_business,violation_type,violation_points 100 LB CLAM,Unsatisfactory,FALSE,BLUE,5 100 PERCENT NUTRICION,Unsatisfactory,FALSE,BLUE,5 7-ELEVEN #2361-39423A,Complete,FALSE,,0
Per preparare lo PySpark script di esempio per EMR
-
Copia il codice di esempio fornito di seguito in un nuovo file nell'editor che hai scelto.
import argparse from pyspark.sql import SparkSession def calculate_red_violations(data_source, output_uri): """ Processes sample food establishment inspection data and queries the data to find the top 10 establishments with the most Red violations from 2006 to 2020. :param data_source: The URI of your food establishment data CSV, such as 's3://amzn-s3-demo-bucket/food-establishment-data.csv'. :param output_uri: The URI where output is written, such as 's3://amzn-s3-demo-bucket/restaurant_violation_results'. """ with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark: # Load the restaurant violation CSV data if data_source is not None: restaurants_df = spark.read.option("header", "true").csv(data_source) # Create an in-memory DataFrame to query restaurants_df.createOrReplaceTempView("restaurant_violations") # Create a DataFrame of the top 10 restaurants with the most Red violations top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations FROM restaurant_violations WHERE violation_type = 'RED' GROUP BY name ORDER BY total_red_violations DESC LIMIT 10""") # Write the results to the specified output URI top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.") parser.add_argument( '--output_uri', help="The URI where output is saved, like an S3 bucket location.") args = parser.parse_args() calculate_red_violations(args.data_source, args.output_uri) -
Salva il file con nome
health_violations.py. -
Carica
health_violations.pysu Amazon S3 nel bucket che hai creato per questo tutorial. Per istruzioni, consulta Caricamento di un oggetto in un bucket nella Guida alle operazioni di base di Amazon Simple Storage Service.
Preparazione dei dati di input di esempio per EMR
-
Scarica il file zip food_establishment_data.zip.
-
Decomprimere e salvare
food_establishment_data.zipcomefood_establishment_data.csvsulla tua macchina. -
Carica il file CSV nel bucket S3 creato per questo tutorial. Per istruzioni, consulta Caricamento di un oggetto in un bucket nella Guida alle operazioni di base di Amazon Simple Storage Service.
Per ulteriori informazioni sulla configurazione di dati per EMR, consulta Prepara i dati di input per l'elaborazione con Amazon EMR.
Avvio di un cluster Amazon EMR
Dopo aver preparato una posizione di archiviazione e l'applicazione, è possibile avviare un cluster Amazon EMR di esempio. In questa fase, avvii un cluster Apache Spark utilizzando l'ultima versione di rilascio di Amazon EMR.
Fase 2: invia il lavoro al tuo cluster Amazon EMR
Invia il lavoro e visualizza i risultati
Dopo aver avviato un cluster, è possibile inviare il lavoro al cluster in esecuzione per elaborare e analizzare i dati. Invia lavoro a un cluster Amazon EMR come una fase. Una fase è un'unità di lavoro costituita da uno o più operazioni. Ad esempio, potresti inviare una fase per calcolare valori o per trasferire ed elaborare dati. Puoi inviare fasi quando crei un cluster o a un cluster in esecuzione. In questa parte del tutorial, invii health_violations.py come fase al cluster in esecuzione. Per ulteriori informazioni sulle fasi, consulta Invia il lavoro a un cluster Amazon EMR.
Per ulteriori informazioni sul ciclo di vita delle fasi, consulta Esecuzione di fasi per elaborare i dati.
Visualizzazione dei risultati
Se l'esecuzione della fase è stata riuscita, puoi visualizzarne i risultati nella cartella output di Amazon S3.
Per visualizzare i risultati di health_violations.py
Apri la console Amazon S3 all'indirizzo. https://console.aws.amazon.com/s3/
-
Scegli il Bucket name (Nome bucket) e la cartella di output che hai specificato all'invio della fase. Ad esempio,
amzn-s3-demo-buckete poimyOutputFolder. -
Verifica che nella cartella di output siano presenti i seguenti elementi:
-
Un oggetto di piccole dimensioni denominato
_SUCCESS. -
Un file CSV che inizia con il prefisso
part-che contiene i risultati.
-
-
Scegli l'oggetto con i risultati, quindi scegli Download per salvare i risultati nel file system locale.
-
Apri i risultati nell'editor che preferisci. Il file di output elenca i primi dieci stabilimenti alimentari con il maggior numero di violazioni di tipo "red (rosso)". Il file di output mostra anche il numero totale di violazioni di tipo "red (rosso)" per ogni stabilimento.
Di seguito è riportato un esempio di risultati
health_violations.py.name, total_red_violations SUBWAY, 322 T-MOBILE PARK, 315 WHOLE FOODS MARKET, 299 PCC COMMUNITY MARKETS, 251 TACO TIME, 240 MCDONALD'S, 177 THAI GINGER, 153 SAFEWAY INC #1508, 143 TAQUERIA EL RINCONSITO, 134 HIMITSU TERIYAKI, 128
Per ulteriori informazioni sull'output dei cluster Amazon EMR, consulta Configurare una posizione per l'output del cluster Amazon EMR.
Quando utilizzi Amazon EMR, potresti voler connetterti a un cluster in esecuzione per leggere i file di log, eseguire il debug del cluster o utilizzare strumenti CLI come la shell Spark. Amazon EMR consente di connetterti a un cluster utilizzando il protocollo Secure Shell (SSH). Questa sezione illustra come configurare SSH, connettersi al cluster e visualizzare i file di log per Spark. Per ulteriori informazioni sulla connessione a un cluster, consulta Autenticazione nei nodi cluster Amazon EMR.
Autorizza le connessioni SSH al cluster
Prima di connetterti al cluster, devi modificare i gruppi di sicurezza del cluster per autorizzare le connessioni SSH in entrata. I gruppi di sicurezza Amazon EC2 agiscono come firewall virtuali per controllare il traffico in entrata e uscita del cluster. Quando hai creato il cluster per questo tutorial, Amazon EMR ha creato i seguenti gruppi di sicurezza per tuo conto:
- ElasticMapReduce-master
-
Il gruppo di sicurezza gestito da Amazon EMR predefinito associato al nodo primario. In un cluster Amazon EMR, il nodo primario è un'istanza Amazon EC2 che gestisce il cluster.
- ElasticMapReduce-slave
-
Il gruppo di sicurezza predefinito associato ai nodi principali e attività.
Connect al cluster utilizzando ilAWS CLI
A prescindere dal sistema operativo, è possibile creare una connessione SSH al cluster utilizzando la AWS CLI.
Per connettersi al cluster e visualizzare i file di registro utilizzando ilAWS CLI
-
Utilizza il comando seguente per aprire una connessione SSH al cluster. Sostituisci
<mykeypair.key>con il percorso completo e il nome del file della coppia di chiavi. Ad esempio,C:\Users\<username>\.ssh\mykeypair.pem.aws emr ssh --cluster-id<j-2AL4XXXXXX5T9>--key-pair-file<~/mykeypair.key> -
Navigare a
/mnt/var/log/sparkper accedere ai registri Spark sul nodo principale del cluster. Quindi visualizza i file in quella posizione. Per un elenco di file di log aggiuntivi sul nodo principale, consulta Visualizzazione di file di log sul nodo primario.cd /mnt/var/log/spark ls
Amazon EMR su EC2 è anche un tipo di elaborazione supportato per Unified Studio. Amazon SageMaker AI Per informazioni su come utilizzare e gestire EMR sulle risorse EC2 in Unified Studio, consulta Managing Amazon EMR on EC2. Amazon SageMaker AI
Fase 3: pulizia delle risorse Amazon EMR
Terminazione di un cluster
Ora che hai inviato il lavoro al cluster e visualizzato i risultati della tua PySpark applicazione, puoi terminare il cluster. La terminazione di un cluster interrompe tutti i costi Amazon EMR e le istanze Amazon EC2 associati.
Amazon EMR mantiene gratuitamente i metadati relativi al cluster per due mesi dopo la terminazione del cluster. I metadati archiviati ti aiutano clonare il cluster per un nuovo lavoro o rivedere la configurazione del cluster a scopo di riferimento. I metadati non includono i dati che il cluster scrive in S3 o che sono archiviati in HDFS sul cluster.
Nota
La console di Amazon EMR non consente di eliminare un cluster dalla visualizzazione elenco in seguito alla terminazione del cluster. Un cluster terminato scompare dalla console quando Amazon EMR ne cancella i metadati.
Eliminazione di risorse S3
Per evitare costi aggiuntivi, devi eliminare il bucket Amazon S3. L'eliminazione del bucket rimuove tutte le risorse di Amazon S3 per questo tutorial. Il bucket deve contenere:
-
La PySpark sceneggiatura
-
Il set di dati di input
-
La cartella dei risultati di output
-
La cartella dei file di log
Potrebbe essere necessario eseguire ulteriori passaggi per eliminare i file archiviati se PySpark lo script o l'output sono stati salvati in una posizione diversa.
Nota
Il cluster deve essere terminato prima di eliminare il bucket. In caso contrario, potrebbe non essere consentito svuotare il bucket.
Per eliminare il bucket, segui le istruzioni in Come eliminare un bucket S3? nella Guida per l'utente di Amazon Simple Storage Service.
Fasi successive
Ora hai avviato il tuo primo cluster Amazon EMR dall'inizio alla fine. Hai inoltre completato processi EMR essenziali come la preparazione e l'invio di applicazioni di Big Data, la visualizzazione dei risultati e la terminazione di un cluster.
Utilizza gli argomenti seguenti per ulteriori informazioni su come personalizzare il flusso di lavoro Amazon EMR.
Valutazione delle applicazioni di big data per Amazon EMR
Scopri e confronta le applicazioni di big data che si possono installare in un cluster nella Guida ai rilasci di Amazon EMR. La Guida ai rilasci descrive in dettaglio ogni versione di EMR e include suggerimenti per l'utilizzo di framework come Spark e Hadoop su Amazon EMR.
Pianificazione dell'hardware, della rete e della sicurezza del cluster
In questo tutorial hai creato un cluster EMR semplice senza configurare opzioni avanzate. Le opzioni avanzate consentono di specificare i tipi di istanza Amazon EC2, la rete cluster e la sicurezza del cluster. Per ulteriori informazioni sulla pianificazione e sull'avvio di un cluster che soddisfi i tuoi requisiti, consulta Pianifica, configura e avvia i cluster Amazon EMR e Sicurezza in Amazon EMR.
Gestione di cluster
Immergiti nel lavoro con i cluster in esecuzione Gestione dei cluster Amazon EMR. Per gestire un cluster, è possibile connettersi al cluster, eseguire il debug delle fasi e tenere traccia delle processi e l'integrità del cluster. Inoltre, puoi regolare le risorse del cluster in risposta alle richieste dei carichi di lavoro con Dimensionamento gestito da EMR.
Uso di un'interfaccia diversa
Oltre alla console Amazon EMR, puoi gestire Amazon EMR utilizzando l'API del AWS Command Line Interface servizio Web o uno dei tanti SDK supportati. AWS Per ulteriori informazioni, consulta Interfacce di gestione.
Inoltre, puoi interagire in molti modi con le applicazioni installate nei cluster Amazon EMR. Alcune applicazioni come Apache Hadoop pubblicano interfacce Web visualizzabili. Per ulteriori informazioni, consulta Visualizzazione di interfacce Web ospitate su cluster Amazon EMR.
Consultazione del blog tecnico su EMR
Per esempi dettagliati e discussioni tecniche approfondite sulle nuove caratteristiche di Amazon EMR, consulta il Blog sui Big Data AWS
