Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Gestire i ETL lavori con AWS Glue Studio
Puoi utilizzare la semplice interfaccia grafica in AWS Glue Studio per gestire i tuoi ETL lavori. Nel pannello di navigazione, scegli Jobs (Processi) per visualizzare la pagina Jobs (Processi) In questa pagina puoi visualizzare tutti i processi creati con AWS Glue Studio o il AWS Glue console. In questa pagina puoi visualizzare, gestire ed eseguire i processi.
In questa pagina puoi anche eseguire le seguenti operazioni:
- Avviare un'esecuzione del processo
- Pianificazione delle esecuzioni dei processi
- Gestione delle pianificazioni dei processi
- Interruzione dei processi
- Visualizzazione dei processi
- Visualizzare le informazioni sulle esecuzioni dei processi recenti
- Visualizzare lo script del processo
- Modificare le proprietà del processo
- Salvare il lavoro
- Clonazione di un processo
- Eliminazione dei processi
Avviare un'esecuzione del processo
In AWS Glue Studio, puoi eseguire i processi on demand. Un processo può essere eseguito più volte e ogni volta AWS Glue raccoglie informazioni sulle attività lavorative e sulle prestazioni. Queste informazioni sono indicate come esecuzione del processo e sono identificate da un ID di esecuzione del processo.
Puoi avviare l'esecuzione di un processo nei seguenti modi: AWS Glue Studio:
-
Nella pagina Jobs (Processi), scegli il processo che vuoi avviare, quindi scegli il pulsante Run job (Esecuzione del processo).
-
Se stai visualizzando un processo nell'editor visivo e questo è stato salvato, puoi scegliere il pulsante Run (Esegui) per avviare l'esecuzione di un processo.
Per ulteriori informazioni sulle esecuzioni dei processi, consulta Utilizzo di processi on the AWS Glue Console nella Guida per AWS Glue gli sviluppatori.
Pianificazione delle esecuzioni dei processi
In AWS Glue Studio, puoi creare una pianificazione per eseguire i processi in orari specifici. Puoi specificare i vincoli, ad esempio il numero di volte in cui vengono eseguiti i processi, i giorni della settimana in cui vengono eseguiti e a che ora. Questi vincoli si basano sul comando cron e hanno le stesse limitazioni di cron. Ad esempio, se vuoi eseguire il processo il giorno 31 di ogni mese, devi ricordare che alcuni mesi non sono di 31 giorni. Per ulteriori informazioni su cron, vedi le espressioni Cron nella Guida per gli sviluppatori di AWS Glue .
Per eseguire i processi in base a una pianificazione
-
Crea una pianificazione del processo utilizzando uno dei seguenti metodi:
-
Nella pagina Jobs (Processi), scegli il processo per il quale creare una pianificazione, scegli Actions (Operazioni), quindi Schedule job (Pianifica processo).
-
Se stai visualizzando un processo nell'editor visivo e questo è stato salvato, puoi scegliere la scheda Schedules (pianificazioni). Quindi scegli Create Schedule (Crea pianificazione).
-
-
Nella pagina Schedule job run (Pianifica esecuzione del processo), inserisci le seguenti informazioni:
-
Name (Nome): inserisci un nome per il processo.
-
Frequency (Frequenza): inseriscila frequenza per la programmazione del processo. Puoi scegliere le seguenti opzioni:
-
Hourly (Orario): il processo verrà eseguito ogni ora, a partire da un minuto specifico. È possibile specificare gli attributi Minute (Minuto) dell'ora in cui il processo deve essere eseguito. Per impostazione predefinita, quando si sceglie la programmazione oraria, il processo viene eseguito all'inizio dell'ora (minuto 0).
-
Daily (Giornaliero): il processo verrà eseguito ogni giorno, a partire da un momento. È possibile specificare gli attributi Minute (Minuto) dell'ora in cui il processo deve essere eseguito e Start hour (Ora di avvio). Le ore sono specificate utilizzando un orologio di 23 ore, in cui si utilizzano i numeri da 13 a 23 per le ore pomeridiane. Il valore predefinito per i minuti e le ore è 0, il che significa che se si seleziona Daily (Giornaliero), il processo verrà eseguito per impostazione predefinita a mezzanotte.
-
Weekly (Settimanale): il processo verrà eseguito uno o più giorni della ogni settimana. Oltre alle stesse impostazioni descritte in precedenza per Daily (Giornaliero), è possibile scegliere i giorni della settimana in cui verrà eseguito il processo. È possibile scegliere uno o più giorni.
-
Monthly (Mensile): il processo verrà eseguito ogni mese in un giorno specifico. Oltre alle stesse impostazioni descritte in precedenza per Daily (Giornaliero), è possibile scegliere i giorni del mese in cui verrà eseguito il processo. Specifica il giorno come un valore numerico compreso tra 1 e 31. Se si seleziona un giorno che in un mese non esiste, ad esempio il 30 febbraio, il processo in quel mese non viene eseguito.
-
Custom (Personalizzato): inserisci un'espressione per la pianificazione del processo utilizzando la sintassi
cron. Le espressioni cron permettono di creare pianificazioni più complicate, ad esempio l'ultimo giorno del mese (invece di un giorno specifico del mese) o ogni terzo mese dai giorni 7 al 21.Consulta le espressioni cron nella Guida per gli sviluppatori di AWS Glue
-
-
Description (Descrizione): è possibile inserire una descrizione per la programmazione dei processi. Se prevedi di utilizzare la stessa pianificazione per più processi, una descrizione può rendere più facile determinare il relativo funzionamento.
-
-
Scegli Create schedule (Crea pianificazione) per salvare la pianificazione del processo.
-
Dopo aver creato la pianificazione, nella parte superiore della pagina della console viene visualizzato un messaggio di operazione riuscita. Puoi selezionare Job details (Dettagli del processo) in questo banner per visualizzare i dettagli. Si apre la pagina dell'editor visivo dei processi, con la scheda Schedules (Piani) selezionata.
Gestione delle pianificazioni dei processi
Dopo aver creato le pianificazioni per un processo, puoi aprirlo nell'editor visivo e scegliere la casella di controllo Schedules (Piani) per gestire le pianificazioni.
Nella scheda Schedules (Pianificazioni) dell'editor visivo, puoi eseguire le seguenti attività:
-
Creare una nuova pianificazione.
Scegli Create schedule (Crea pianificazione), quindi inserisci le informazioni per la pianificazione come descritto in Pianificazione delle esecuzioni dei processi.
-
Modificare una pianificazione esistente.
Seleziona la pianificazione da modificare, quindi Action (Operazioni) e poi Edit schedule (Modifica pianificazione). Quando scegli di modificare una pianificazione esistente, la frequenza è personalizzata e la pianificazione viene visualizzata come espressione
cron. Puoi modificare l'espressionecronoppure specificare una nuova pianificazione utilizzando l'opzione Frequency (Frequenza). Una volta terminate le modifiche, seleziona Update schedule (Aggiorna pianificazione). -
Sospendere una pianificazione attiva.
Seleziona una pianificazione attiva, quindi Action (Operazioni) e Pause schedule (Sospendi pianificazione). La pianificazione viene disattivata immediatamente. Seleziona il pulsante di aggiornamento (ricarica) per visualizzare lo stato aggiornato della pianificazione.
-
Riprendere una pianificazione sospesa.
Seleziona una pianificazione attiva, quindi Action (Operazioni) e Resume schedule (Riprendi pianificazione). La pianificazione viene attivata immediatamente. Seleziona il pulsante di aggiornamento (ricarica) per visualizzare lo stato aggiornato della pianificazione.
-
Eliminare una pianificazione.
Seleziona la pianificazione da rimuovere, quindi Action (Operazioni) e poi Delete schedule (Elimina pianificazione). La pianificazione viene eliminata immediatamente. Seleziona il pulsante di aggiornamento (ricarica) per visualizzare l'elenco delle pianificazioni aggiornato. La pianificazione mostrerà lo stato Deleting (Eliminazione in corso) fino a quando non è completamente rimossa.
Interruzione dei processi
Puoi interrompere un processo prima che abbia completato l'esecuzione. Puoi scegliere questa opzione se sai che il processo non è configurato correttamente o se richiede troppo tempo per essere completato.
Nella pagina Monitoring (Monitoraggio), nell'elenco Job runs (Esecuzioni di processo), scegli il processo da interrompere, quindi seleziona Actions (Operazioni) e poi Stop run (Interrompi esecuzione).
Visualizzazione dei processi
Puoi visualizzare tutti i processi nella pagina Jobs (Processi). Per accedere a questa pagina, seleziona Jobs (Processi) nel pannello di navigazione.
Nella pagina Jobs (Processi) puoi visualizzare tutti i processi creati nell'account. L'elenco Your jobs (I tuoi processi) mostra il nome del processo, il tipo, lo stato dell'ultima esecuzione del processo e le date in cui è stato creato e modificato per l'ultima volta. Puoi selezionare il nome di un processo per visualizzare le relative informazioni dettagliate.
Puoi anche utilizzare il pannello di controllo Your jobs (Monitoraggio) per visualizzare tutti i processi. Puoi accedere al pannello di controllo selezionando Monitoring (Monitoraggio) nel pannello di navigazione.
Personalizzazione della visualizzazione del processo
Puoi personalizzare la modalità di visualizzazione dei processi nella sezione Your jobs (I tuoi processi) della pagina Jobs (Processi). Puoi inoltre inserire del testo nel campo di ricerca per visualizzare solo i lavori con un nome che contiene tale testo.
Se scegli l'icona delle impostazioni
![]() nella sezione I tuoi lavori, puoi personalizzare la modalità AWS Glue Studio visualizza le informazioni nella tabella. Puoi scegliere di inserire a capo le righe di testo nella visualizzazione, modificare il numero di processi visualizzati nella pagina e specificare le colonne da visualizzare.
nella sezione I tuoi lavori, puoi personalizzare la modalità AWS Glue Studio visualizza le informazioni nella tabella. Puoi scegliere di inserire a capo le righe di testo nella visualizzazione, modificare il numero di processi visualizzati nella pagina e specificare le colonne da visualizzare.
Visualizzare le informazioni sulle esecuzioni dei processi recenti
Un processo può essere eseguito più volte man mano che nuovi dati vengono aggiunti nella posizione di origine. Ogni volta che un processo viene eseguito, all'esecuzione viene assegnato un ID univoco e vengono raccolte informazioni su tale esecuzione. Puoi visualizzare queste informazioni utilizzando i seguenti metodi.
-
Seleziona la scheda Runs (Esecuzioni) dell'editor visivo per visualizzare le informazioni sull'esecuzione per il processo attualmente mostrato.
Nella scheda Runs(Esecuzioni) (la pagina Recent job runs [Esecuzioni dei processi recenti]), è presente una scheda per ogni esecuzione del processo. Le informazioni visualizzate nella scheda Runs (Esecuzioni) includono:
-
ID dell'esecuzione del processo
-
Numero di tentativi di esecuzione del processo
-
Stato dell'esecuzione del processo
-
Ora di inizio e fine dell'esecuzione del processo
-
Il runtime per l'esecuzione del processo
-
Un collegamento ai file di log del processo
-
Un collegamento ai file di log degli errori del processo
-
L'errore restituito per i processi non riusciti
-
Puoi selezionare l'esecuzione di un processo per visualizzarne le informazioni aggiuntive, tra cui:
Inserimento di argomenti
Log continui
Parametri: puoi visualizzare le visualizzazioni dei parametri di base. Per ulteriori informazioni sui parametri inclusi, consulta Visualizzazione delle Amazon CloudWatch metriche relative all'esecuzione di un job Spark.
Interfaccia utente Spark: puoi visualizzare i log di Spark relativi al processo nell'interfaccia utente di Spark. Per ulteriori informazioni sull'utilizzo dell'interfaccia utente di Spark, consulta Monitoraggio dei processi tramite l'interfaccia utente Web di Apache Spark. Abilita questa funzionalità seguendo la procedura in Abilitazione dell'interfaccia utente Web di Apache Spark per processi AWS Glue.
È possibile selezionare Visualizza dettagli per visualizzare informazioni simili nella pagina dei dettagli dell'esecuzione del processo. In alternativa, è possibile accedere alla pagina dei dettagli dell'esecuzione del processo tramite la pagina Monitoraggio. Nel riquadro di navigazione, scegli Monitoring (Monitoraggio). Scorri in basso fino all'elenco Job runs (Esecuzioni processo). Scegli il processo e poi scegli View run details (Visualizza i dettagli dell'esecuzione). I contenuti sono descritti in Visualizzazione dei dettagli di un'esecuzione di un processo.
Per ulteriori informazioni sui log del processo, consulta Visualizzazione dei log di esecuzione del processo.
Visualizzare lo script del processo
Dopo aver fornito le informazioni per tutti i nodi del job, AWS Glue Studio genera uno script utilizzato dal processo per leggere i dati dall'origine, trasformarli e scriverli nella posizione di destinazione. Salvando il processo, puoi visualizzare questo script in qualsiasi momento.
Per visualizzare lo script generato per il processo
-
Nel riquadro di navigazione seleziona Jobs (Processi).
-
Nella pagina Jobs (Processi), nell'elenco Your Jobs (I tuoi processi), scegli il nome del processo da esaminare. In alternativa, puoi selezionare un processo nell'elenco, selezionare il menu Actions (Operazioni), quindi scegliere Edit job (Modifica il processo).
-
Nella pagina dell'editor visivo, scegliere la scheda Script nella parte superiore per visualizzare lo script del processo.
Se desideri modificare lo script del processo, consulta AWS Glue guida alla programmazione.
Modificare le proprietà del processo
I nodi nel diagramma processo definiscono le azioni eseguite dal processo, ma sono disponibili anche diverse proprietà che è possibile configurare per il processo. Queste proprietà determinano l'ambiente in cui viene eseguito il processo, le risorse utilizzate, le impostazioni di soglia, le impostazioni di sicurezza e altro ancora.
Per personalizzare l'ambiente di esecuzione dei processi
-
Nel riquadro di navigazione seleziona Jobs (Processi).
-
Nella pagina Jobs (Processi), nell'elenco Your Jobs (I tuoi processi), scegli il nome del processo da esaminare.
-
Nella pagina dell'editor visivo, scegliere la scheda Job details (Dettagli del processo) nella parte superiore del pannello di modifica del processo.
-
Modifica le proprietà del processo secondo le necessità.
Per ulteriori informazioni sulle proprietà del processo, consulta Definizione delle proprietà del processo nella Guida per gli sviluppatori di AWS Glue .
-
Espandi la sezione Advanced properties (Proprietà avanzate) se devi specificare queste proprietà aggiuntive del processo:
-
Script filename (Nome del file di script): il nome del file che memorizza lo script del processo in Amazon S3.
-
Script path (Percorso dello script): la posizione di Amazon S3 in cui è memorizzato lo script del processo.
-
Job metrics (Parametri del processo): (non disponibile per i lavori di shell Python) attiva la creazione Amazon CloudWatch di parametri durante l'esecuzione del processo.
-
Continuous logging (Registrazione continua): (non disponibile per i lavori di shell Python) attiva la registrazione continua CloudWatch a, in modo che i log siano disponibili per la visualizzazione prima del completamento del processo.
-
Spark UI (Interfaccia utente di Spark) e Spark UI logs path (Percorso dei log dell'interfaccia utente Spark): (non disponibile per i processi di shell Python) attiva l'uso dell'interfaccia utente Spark per il monitoraggio del processo e specifica la posizione per i log dell'interfaccia utente di Spark.
-
Maximum concurrency (Simultaneità massima): imposta il numero massimo di esecuzioni simultanee consentite per il processo.
-
Temporary path (Percorso temporaneo): il percorso di una directory di lavoro in Amazon S3, in cui vengono scritti i risultati intermedi temporanei quando AWS Glue esegue lo script del processo.
-
Delay notification threshold (minutes) (Soglia notifica di ritardo [minuti]): specifica una soglia di ritardo per il processo. Se il processo viene eseguito per un tempo più lungo di quello specificato dalla soglia, AWS Glue invia una notifica di ritardo per il lavoro a CloudWatch.
-
Security configuration (Configurazione di sicurezza) e Server-side encryption (Crittografia lato server): usa questi campi per scegliere le opzioni di crittografia per il processo.
-
Use Glue Data Catalog as the Hive metastore (Usa il catalogo dati di Glue come metastore Hive): scegli questa opzione per utilizzare il AWS Glue Data Catalog in alternativa ad Apache Hive Metastore.
-
Additional network connection (Connessione di rete aggiuntiva): per un'origine dati in aVPC, puoi specificare un tipo di connessione
Networkper assicurarti che il processo acceda ai tuoi dati tramite. VPC -
Python library path (Percorso libreria Python), Dependent jars path (Percorso file .jar dipendenti) (non disponibili per i processi di shell Python) o Referenced files path (Percorso file di riferimento): utilizza questi campi per specificare la posizione dei file aggiuntivi utilizzati dal processo durante l'esecuzione dello script.
-
Job Parameters (Parametri del processo): puoi aggiungere un insieme di coppie chiave-valore che vengono passate come parametri denominati allo script del processo. Quando in Python si chiamano le, è preferibile passare AWS Glue API i parametri in modo esplicito usando il nome. Per ulteriori informazioni sull'utilizzo dei parametri in uno script di processo, consulta Passaggio e accesso ai parametri Python in AWS Glue nella Guida per gli sviluppatori di AWS Glue .
-
Tag: puoi aggiungere tag al processo per facilitarne l'organizzazione e l'individuazione.
-
-
Dopo aver modificato le proprietà del processo, salvalo.
Memorizza i file Spark shuffle su Amazon S3
Alcuni ETL processi richiedono la lettura e la combinazione di informazioni da più partizioni, ad esempio quando si utilizza una trasformazione di join. Questa operazione è indicata come shuffle. Durante uno shuffle, i dati vengono scritti su disco e trasferiti attraverso la rete. con AWS Glue versione 3.0, puoi configurare Amazon S3 come posizione di storage per questi file. AWS Glue fornisce un gestore shuffle che scrive e legge file shuffle da e verso Amazon S3. La scrittura e la lettura di file shuffle da Amazon S3 è più lenta (del 5-20%) rispetto al disco locale (o Amazon EBS che è estremamente ottimizzato per Amazon). EC2 Tuttavia, Amazon S3 offre una capacità di archiviazione illimitata, pertanto non è necessario preoccuparsi errori "No space left on device" durante l'esecuzione del lavoro.
Per configurare il processo per l'utilizzo di Amazon S3 per i file shuffle
-
Nella pagina Jobs (Processi), nell'elenco Your Jobs (I tuoi processi), scegli il nome del processo da modificare.
-
Nella pagina dell'editor visivo, scegliere la scheda Job details (Dettagli del processo) nella parte superiore del pannello di modifica del processo.
Scorri verso il basso fino alla sezione Job parameters (Parametri del processo).
-
Specifica le seguenti coppie chiave-valore.
-
--write-shuffle-files-to-s3—trueQuesto è il parametro principale che configura il gestore shuffle in AWS Glue per utilizzare i bucket Amazon S3 per la scrittura e la lettura di dati shuffle. Per impostazione predefinita, questo parametro ha un valore di
false. -
(Facoltativo)
--write-shuffle-spills-to-s3—trueQuesto parametro consente di scaricare i file di riversamento nei bucket Amazon S3, che fornisce ulteriore resilienza al processo Spark in AWS Glue. Questo è necessario solo per carichi di lavoro di grandi dimensioni che riversano molti dati sul disco. Per impostazione predefinita, questo parametro ha un valore di
false. -
(Facoltativo)
--conf spark.shuffle.glue.s3ShuffleBucket—S3://<shuffle-bucket>Questo parametro specifica il bucket Amazon S3 da utilizzare durante la scrittura dei file shuffle. Se non viene impostato, la posizione è la cartella
shuffle-datanella posizione specificata per Temporary path (Percorso temporaneo) (--TempDir).Nota
Verifica che la posizione del bucket di shuffle si trovi nella stessa Regione AWS in cui viene eseguito il processo.
Inoltre, il servizio shuffle non pulisce i file al termine dell'esecuzione del processo, pertanto è necessario configurare le policy del ciclo di vita dello storage Amazon S3 nella posizione del bucket shuffle. Per ulteriori informazioni, consulta Gestione del ciclo di vita dello storage nella Guida per l'utente di Amazon S3.
-
Salvare il lavoro
Finché non si salva il processo, a sinistra della finestra Save (Salva) viene visualizzato un messaggio in rosso che indica che il processo non è stato salvato.

Per salvare il processo
-
Fornisci tutte le informazioni richieste nelle schede Visual (Visivo) e Job details (Dettagli del processo).
-
Seleziona il pulsante Save (Salva).
Dopo aver salvato il processo, il messaggio 'non salvato' si modifica per mostrare l'ora e la data dell'ultimo salvataggio.
Se esci AWS Glue Studio prima di salvare il lavoro, la prossima volta che accedi AWS Glue Studio, viene visualizzata una notifica. La notifica indica che esiste un processo non salvato e chiede se si desidera ripristinarlo. Se si sceglie di ripristinare il processo, è possibile continuare a modificarlo.
Risoluzione dei problemi relativi al salvataggio di un processo
Se scegli l'opzione Save (Salva), ma nel tuo lavoro mancano alcune informazioni richieste, nella scheda in cui mancano le informazioni viene visualizzato un messaggio in rosso. Il numero nel messaggio indica quanti campi mancanti sono stati rilevati.
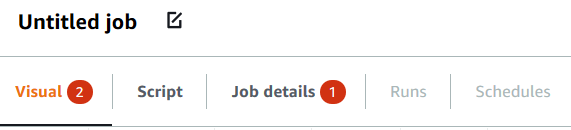
-
Se un nodo nell'editor visivo non è configurato correttamente, la scheda Visual (Visivo) mostra un messaggio in rosso e il nodo con l'errore mostra un simbolo di avvertenza
 .
.-
Seleziona il nodo. Nel pannello dei dettagli del nodo, nella scheda in cui si trovano le informazioni mancanti o errate viene visualizzato un messaggio in rosso.
-
Scegli la scheda nel pannello dei dettagli del nodo che mostra un messaggio in rosso, quindi individua i campi interessati dal problema, che sono evidenziati. Un messaggio di errore sotto i campi fornisce ulteriori informazioni sul problema.
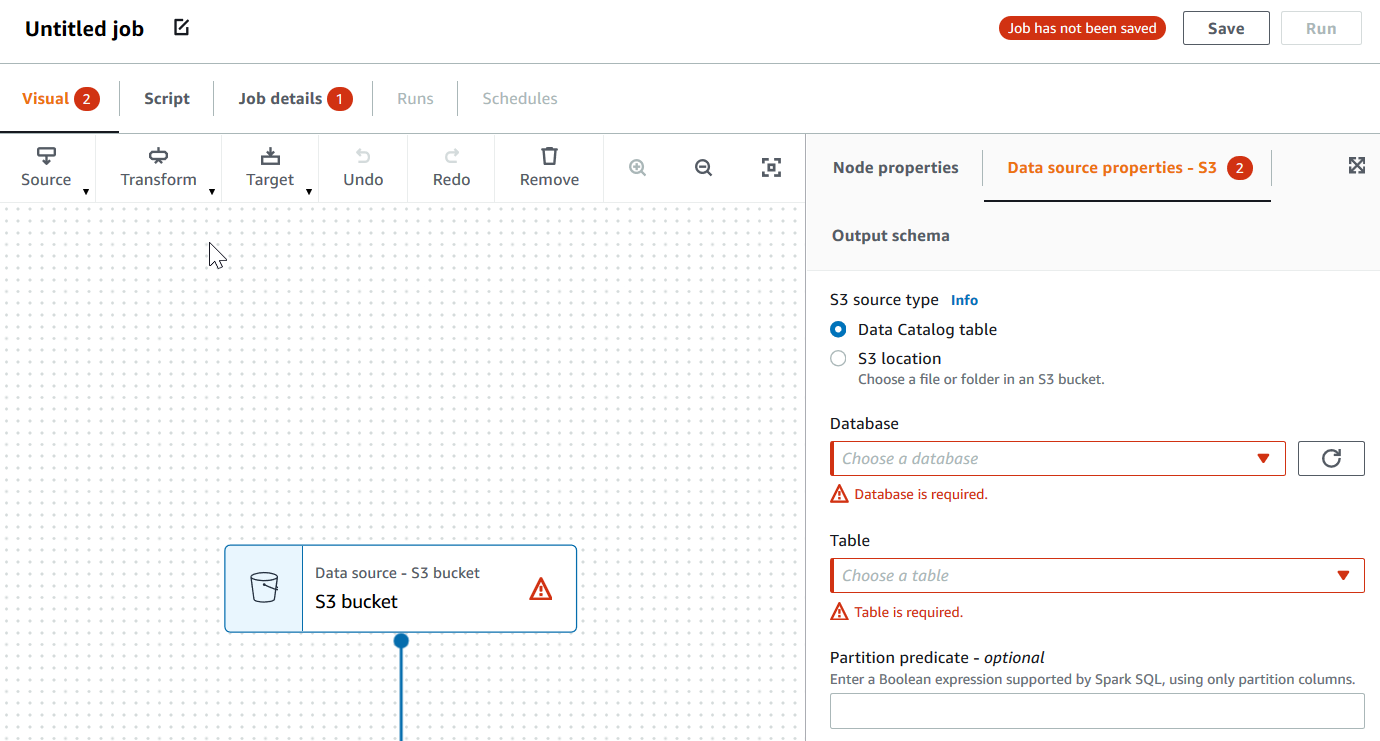
-
-
Se si verifica un problema con le proprietà del processo, la scheda Job details (Dettagli del processo) mostra un messaggio in rosso. Scegli quella scheda e individua i campi interessati dal problema, che sono evidenziati. Il messaggio di errore sotto i campi fornisce ulteriori informazioni sul problema.
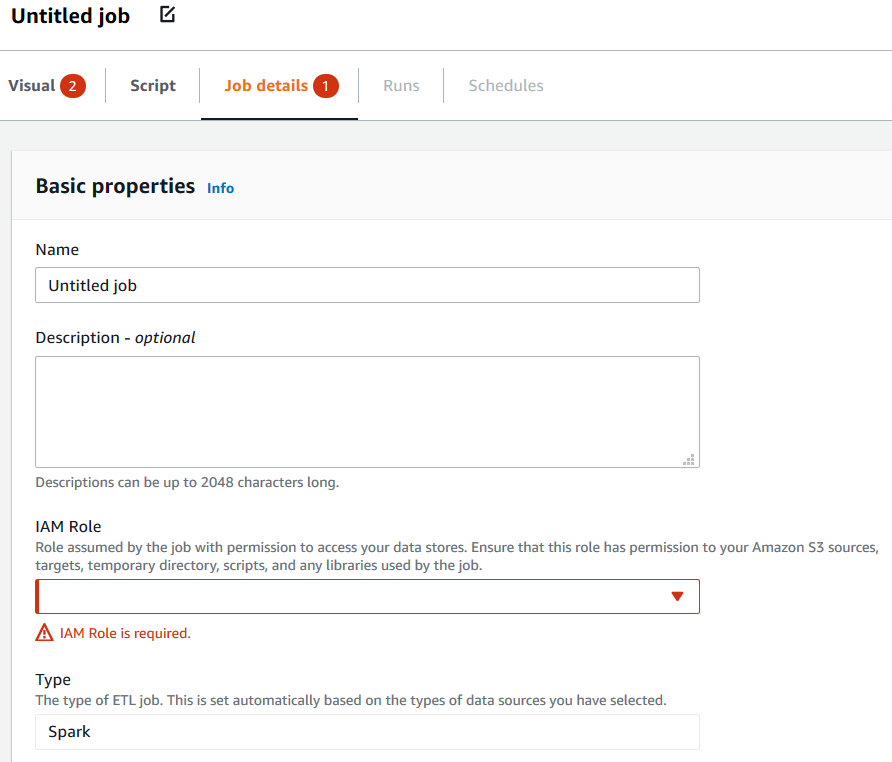
Clonazione di un processo
Puoi utilizzare l'operazione Clone job (Clona processo) per copiare un processo esistente in un nuovo processo.
Per creare un nuovo processo copiando un processo esistente
-
Nella pagina Jobs (Processi), nell'elenco Your Jobs (I tuoi processi), scegli il processo da duplicare.
-
Nel menu Actions (Operazioni) scegli Clone job (Clona processo).
-
Inserisci un nome per il processo. Puoi quindi salvare o modificare il processo.
Eliminazione dei processi
È possibile rimuovere i processi che non sono più necessari. È possibile eliminare uno o più processi in un'unica operazione.
Per rimuovere processi da AWS Glue Studio
-
Nella pagina Jobs (Processi), nell'elenco Your Jobs (I tuoi processi), scegli il processo da eliminare.
Nel menu Actions (Operazioni) seleziona Delete job (Elimina processo).
Conferma di voler eliminare il processo inserendo
delete.
È inoltre possibile eliminare un processo salvato durante la visualizzazione della scheda Job details (Dettagli del processo) per quel lavoro nell'editor visivo.
