Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitoraggio dei processi tramite l'interfaccia utente Web di Apache Spark
Puoi utilizzare l'interfaccia utente Web di Apache Spark per monitorare ed eseguire il debug dei processi ETL AWS Glue in esecuzione sul sistema di processi AWS Glue e anche delle applicazioni Spark in esecuzione sugli endpoint di sviluppo AWS Glue. L'interfaccia utente di Spark consente di controllare quanto segue per ogni processo:
-
Tempistica eventi di ogni fase Spark
-
Un grafo aciclico orientato (DAG) del processo
-
Piani fisici e logici per le query SparkSQL
-
Le variabili ambientali Spark sottostanti per ogni processo
Per ulteriori informazioni sull'utilizzo dell'interfaccia utente Web di Spark, consulta l'interfaccia utente Web
Puoi vedere l'interfaccia utente di Spark nella console. AWS Glue È disponibile quando un AWS Glue job viene eseguito su versioni AWS Glue 3.0 o successive con registri generati nel formato Standard (anziché legacy), che è l'impostazione predefinita per i lavori più recenti. Se disponi di file di registro di dimensioni superiori a 0,5 GB, puoi abilitare il supporto roll-log per i job run su versioni AWS Glue 4.0 o successive per semplificare l'archiviazione, l'analisi e la risoluzione dei problemi dei log.
Puoi abilitare l'interfaccia utente di Spark utilizzando la AWS Glue console o AWS Command Line Interface ()AWS CLI. Quando abiliti l'interfaccia utente di Spark, i processi ETL AWS Glue e le applicazioni Spark su endpoint di sviluppo AWS Glue possono eseguire il backup dei log degli eventi Spark in un percorso specificato in Amazon Simple Storage Service (Amazon S3). Puoi utilizzare i log degli eventi sottoposti a backup in Amazon S3 con l'interfaccia utente di Spark sia in tempo reale, ovvero durante l'esecuzione del processo, sia al termine dello stesso. Sebbene i log rimangano in Amazon S3, l'interfaccia utente Spark nella console può AWS Glue visualizzarli.
Permissions
Per utilizzare l'interfaccia utente di Spark nella AWS Glue console, puoi utilizzare UseGlueStudio o aggiungere tutte le singole API di servizio. Tutte le API sono necessarie per utilizzare completamente l'interfaccia utente di Spark, tuttavia gli utenti possono accedere alle funzionalità di SparkUI aggiungendo le relative API di servizio nell'autorizzazione IAM per un accesso granulare.
RequestLogParsing è la più importante in quanto esegue l'analisi dei log. Le API rimanenti servono per leggere i rispettivi dati analizzati. Ad esempio, GetStages fornisce l'accesso ai dati relativi a tutte le fasi di un processo Spark.
L'elenco delle API del servizio Spark UI mappato a UseGlueStudio è riportato di seguito nella policy di esempio. La policy riportata di seguito fornisce accesso per utilizzare solo le funzionalità dell'interfaccia utente di Spark. Per aggiungere altre autorizzazioni come Amazon S3 e IAM, consulta Creazione di politiche IAM personalizzate per. AWS Glue Studio
L'elenco delle API del servizio Spark UI mappato a UseGlueStudio è riportato di seguito nella policy di esempio. Quando si utiliza un'API del servizio Spark UI, usare il seguente namespace: glue:<ServiceAPI>.
Limitazioni
-
L'interfaccia utente di Spark nella AWS Glue console non è disponibile per le esecuzioni di job avvenute prima del 20 novembre 2023 perché sono nel formato di registro legacy.
-
L'interfaccia utente di Spark nella AWS Glue console supporta i rolling log per la AWS Glue versione 4.0, come quelli generati di default nei job di streaming. La somma massima di tutti i file di eventi dei log in sequenza è di 2 GB. Per i AWS Glue lavori senza supporto per i rolllog, la dimensione massima del file degli eventi di registro supportata per SparkUI è 0,5 GB.
-
L'interfaccia utente di Spark serverless non è disponibile per i log degli eventi Spark archiviati in un bucket Amazon S3 a cui è possibile accedere solo dal proprio VPC.
Esempio: interfaccia utente Web di Apache Spark
Questo esempio illustra come utilizzare l'interfaccia utente di Spark per comprendere le prestazioni del processo. Gli screenshot mostrano l'interfaccia utente Web di Spark fornita da un server della cronologia Spark autogestito. L'interfaccia utente Spark nella AWS Glue console offre visualizzazioni simili. Per ulteriori informazioni sull'utilizzo dell'interfaccia utente Web di Spark, consulta l'interfaccia utente Web
Di seguito è riportato un esempio di un'applicazione Spark che legge da due origini dati, esegue una trasformazione join e la scrive in Amazon S3 nel formato Parquet.
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.functions import count, when, expr, col, sum, isnull from pyspark.sql.functions import countDistinct from awsglue.dynamicframe import DynamicFrame args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME']) df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json") df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json") df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter') df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/") job.commit()
La seguente visualizzazione DAG mostra le diverse fasi in questo processo Spark.
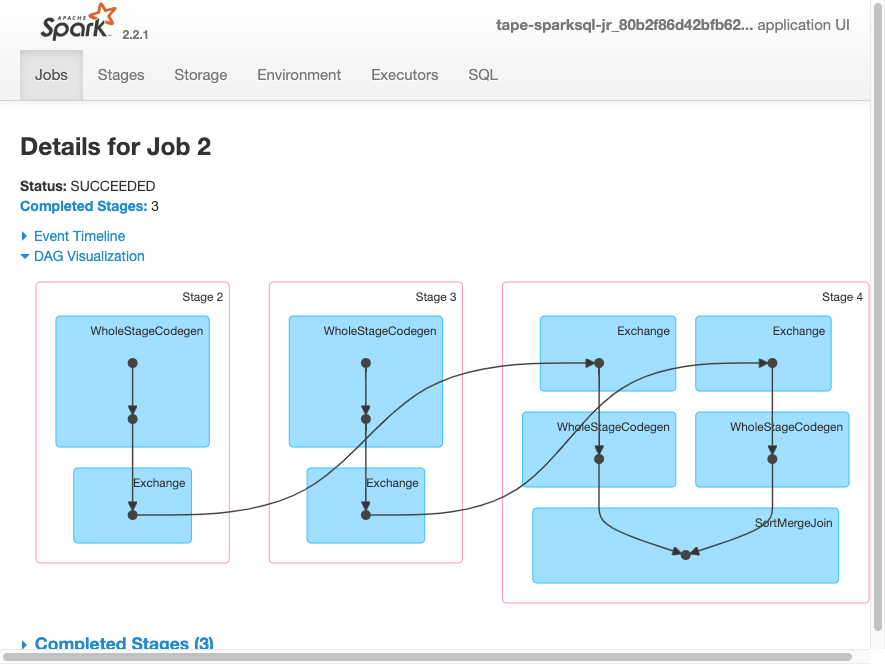
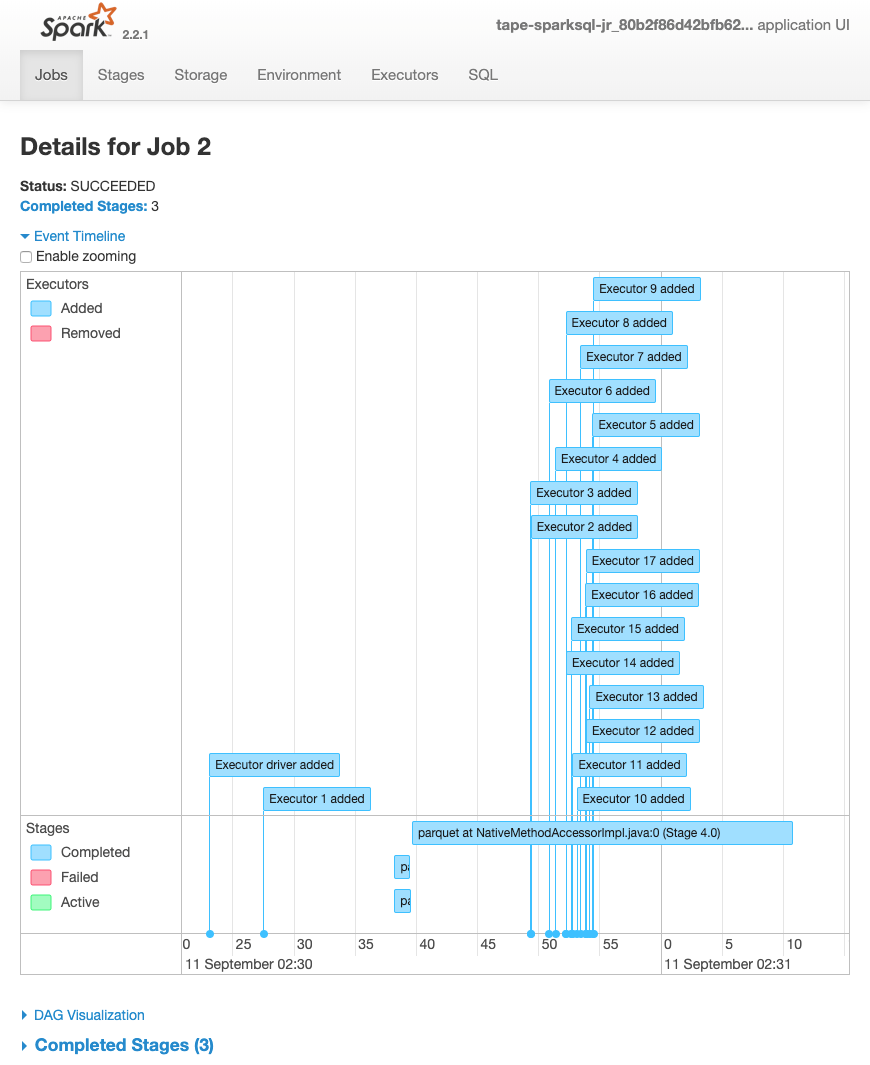
La seguente tempistica eventi per un processo mostra l'avvio, l'esecuzione e l'arresto di diversi executor Spark.
La schermata seguente mostra i dettagli dei piani di query SparkSQL:
-
Piano logico esaminato
-
Piano logico analizzato
-
Piano logico ottimizzato
-
Piano fisico per l'esecuzione

Argomenti
