Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo dei crawler per compilare il Catalogo dati
È possibile utilizzare an Crawler di AWS Glue per popolarli AWS Glue Data Catalog con database e tabelle. Questo è il metodo principale utilizzato dalla maggior parte AWS Glue degli utenti. Un crawler è in grado di eseguire il crawling di archivi dati con una sola esecuzione. Al termine dell'operazione, il crawler crea o aggiorna una o più tabelle nel catalogo dati. I processi di estrazione, trasformazione e caricamento (ETL) definiti in AWS Glue usano queste tabelle del catalogo dati come origini e destinazioni. Il processo ETL legge e scrive negli archivi dati specificati nelle tabelle del catalogo dati di origine e di destinazione.
Flusso di lavoro
Il diagramma del flusso di lavoro seguente mostra in che modo i crawler AWS Glue interagiscono con i datastore e altri elementi per popolare il catalogo dati.
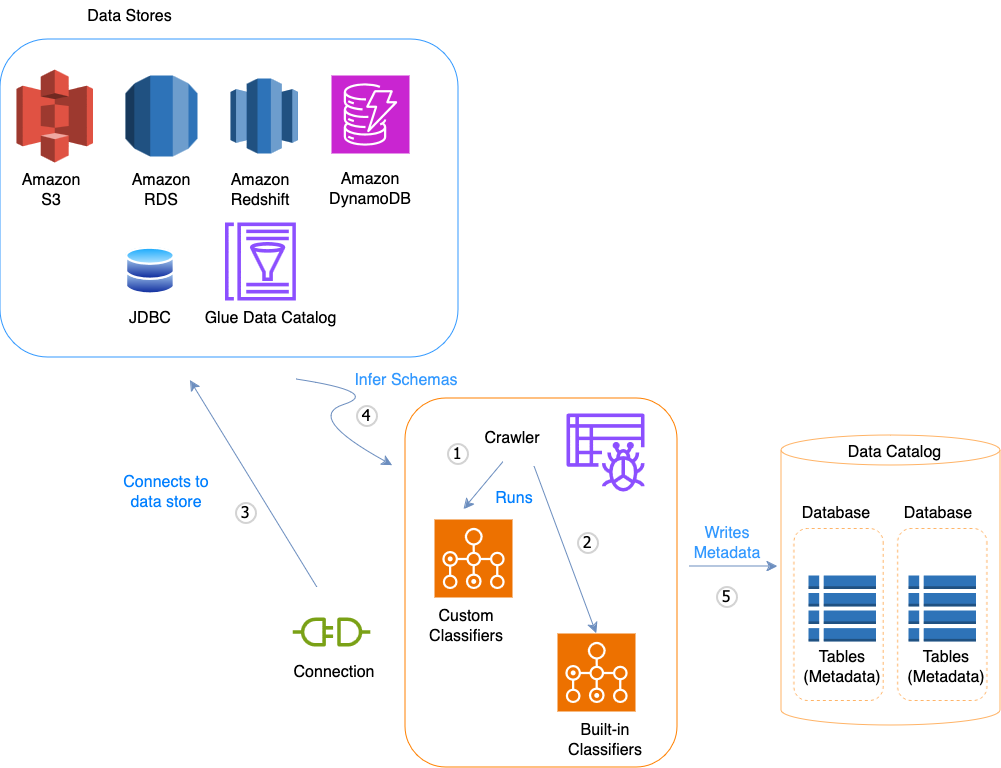
Di seguito è riportato il flusso di lavoro generale che descrive il modo in cui il crawler popola il AWS Glue Data Catalog:
-
Un crawler esegue qualsiasi classificatore personalizzato da te selezionato per dedurre il formato e lo schema dei dati. É possibile fornire il codice per i classificatori personalizzati, i quali vengono eseguiti nell'ordine specificato.
Il primo classificatore personalizzato che riconosce in modo corretto la struttura dei dati viene utilizzato per creare uno schema. I classificatori personalizzati in basso nell'elenco vengono ignorati.
-
Se nessun classificatore personalizzato è in grado di abbinar lo schema dei dati, i classificatori integrati ne tenteranno il riconoscimento. Un esempio di un classificatore incorporato è quello che riconosce JSON.
-
Il crawler si collega al datastore. Alcuni datastore richiedono proprietà di connessione per l'accesso al crawler.
-
Lo schema dedotto dei dati viene creato.
-
Il crawler scrive metadati nel catalogo dati. Una definizione di tabella contiene i metadati sui dati presenti nel datastore. La tabella viene scritta in un database, che è un container di tabelle nel catalogo dati. Gli attributi di una tabella includono la classificazione, ovvero un'etichetta creata dal classificatore che ha dedotto lo schema della tabella.
Come funzionano i crawler
Quando un crawler viene eseguito, è necessario effettuare le seguenti operazioni per interrogare un archivio dati:
-
Classifica dei dati per determinare il formato, lo schema e le relative proprietà dei dati grezzi : è possibile configurare i risultati di classificazione creando un classificatore personalizzato.
-
Raggruppamento di dati in tabelle o partizioni : i dati vengono raggruppati in base a processi euristici del crawler.
-
Scrittura dei metadati nel catalogo dati: è possibile configurare il modo in cui il crawler aggiunge, aggiorna ed elimina tabelle e partizioni.
Quando si definisce un crawler, si scelgono uno o più classificatori che valutano il formato dei dati per dedurre uno schema. Quando il crawler viene eseguito, il primo classificatore nella lista per riconoscere con successo gli archivi dati è utilizzato per creare uno schema per la tabella. È possibile utilizzare classificatori incorporati o definirne uno proprio. Definisci i classificatori predefiniti in un'operazione separata prima di definire i crawler. AWS Glue fornisce classificatori predefiniti per dedurre gli schemi da file comuni con formati che includono JSON, CSV e Apache Avro. Per l'elenco aggiornato dei classificatori integrati nel AWS Glue, consulta Classificatori integrati.
Le tabelle di metadati create dal crawler sono contenute in un database nel momento in cui si definisce il crawler. Se il crawler non specifica un database, le tabelle sono posizionate in un database di default. Inoltre, ogni tabella ha una colonna di classificazione che viene compilata dal classificatore che per primo ha riconosciuto con successo l'archivio dati.
Se il file sottoposto a crawling è compresso, il crawler deve scaricarlo per elaborarlo. Quando viene eseguito, un crawler interroga i file per determinarne il formato e il tipo di compressione e scrive queste proprietà nel catalogo dati. Alcuni formati di file, ad esempio Apache Parquet, permettono di comprimere parti del file non appena vengono scritte. Per questi file, i dati compressi sono un componente interno del file e AWS Glue non popola la proprietà compressionType quando scrive tabelle nel catalogo dati. Al contrario, se un intero file viene compresso tramite un algoritmo di compressione, ad esempio gzip, la proprietà compressionType viene popolata quando vengono scritte tabelle nel catalogo dati.
Il crawler genera i nomi per le tabelle che crea. I nomi delle tabelle archiviate in base alle seguenti AWS Glue Data Catalog regole:
-
Sono ammessi solo caratteri alfanumerici e caratteri di sottolineatura (
_). -
Qualsiasi prefisso personalizzato non può essere più lungo di 64 caratteri.
-
La lunghezza massima del nome non può essere superiore a 128 caratteri. Il crawler tronca i nomi generati per rientrare nel limite.
-
Se vengono rilevati nomi di tabelle duplicati, il crawler aggiunge al nome un suffisso stringa hash.
Se il crawler viene eseguito più di una volta, su pianificazione, cerca file nuovi o modificati o tabelle nel tuo archivio dati. L'output del crawler include nuove tabelle e partizioni trovate nel corso di un'esecuzione precedente.
In che modo un crawler determina quando creare le partizioni?
Quando un AWS Glue crawler esegue la scansione del data store Amazon S3 e rileva più cartelle in un bucket, determina la radice di una tabella nella struttura delle cartelle e quali cartelle sono partizioni di una tabella. Il nome della tabella si basa sul prefisso Amazon S3 o sul nome della cartella. Si deve specificare un Include path (Percorso di inclusione) che indichi il livello della cartella su cui eseguire il crawling. Quando la maggior parte degli schemi a un livello della cartella sono simili, il crawler crea partizioni di una tabella invece di tabelle separate. Per fare in modo che il crawler crei tabelle separate, aggiungere ogni cartella radice della tabella come archivio dati separato quando si definisce il crawler.
Considera, ad esempio, la seguente struttura di cartelle Amazon S3.
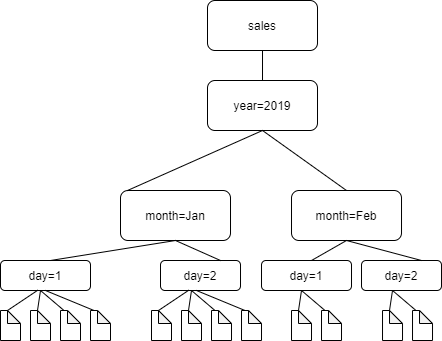
I percorsi alle quattro cartelle più in basso sono i seguenti:
S3://sales/year=2019/month=Jan/day=1 S3://sales/year=2019/month=Jan/day=2 S3://sales/year=2019/month=Feb/day=1 S3://sales/year=2019/month=Feb/day=2
Supponiamo che la destinazione del crawler sia impostata su Sales e che tutti i file nelle cartelle day=n siano nello stesso formato (ad esempio, JSON, non crittografato) e abbiano schemi uguali o molto simili. Il crawler creerà una singola tabella con quattro partizioni, con chiavi di partizione year, month, e day.
Nel prossimo esempio consideriamo la seguente struttura di cartelle Amazon S3:
s3://bucket01/folder1/table1/partition1/file.txt s3://bucket01/folder1/table1/partition2/file.txt s3://bucket01/folder1/table1/partition3/file.txt s3://bucket01/folder1/table2/partition4/file.txt s3://bucket01/folder1/table2/partition5/file.txt
Se gli schemi per i file sotto table1 e table2 sono simili e nel crawler viene definito un unico archivio dati con Include path (Percorso di inclusione) s3://bucket01/folder1/, il crawler crea un'unica tabella con due colonne delle chiavi di partizione. La prima colonna delle chiavi di partizione contiene table1 e table2 e la seconda colonna delle chiavi di partizione contiene da partition1 a partition3 per la partizione table1 e partition4 e partition5 per la partizione table2. Per creare due tabelle separate, definire il crawler con due archivi dati. In questo esempio, definire il primo Include path (Percorso di inclusione) come s3://bucket01/folder1/table1/ e il secondo come s3://bucket01/folder1/table2.
Nota
In Amazon Athena, ogni tabella corrisponde a un prefisso Amazon S3 con tutti gli oggetti contenuti. Se gli oggetti hanno schemi diversi, Athena non riconosce gli oggetti diversi all'interno dello stesso prefisso come tabelle separate. Questo può verificarsi se un crawler crea più tabelle dallo stesso prefisso Amazon S3. In questo caso, alcune query in Athena possono restituire zero risultati. Perché Athena riconosca correttamente le tabelle ed esegua query sulle tabelle, crea il crawler con un Include path (Percorso di inclusione) separato per ogni schema di tabella diverso nella struttura di cartelle Amazon S3. Per ulteriori informazioni, consulta Best practice durante l'utilizzo di Athena con AWS Glue e questo articolo del Portale del sapere AWS
