Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Nelle odierne applicazioni basate sui dati, l'importanza dei dati diminuisce nel tempo e il loro valore predittivo si trasforma nella possibilità di reagire. Di conseguenza, i clienti vogliono elaborare i dati in tempo reale per prendere decisioni più rapide. Quando si gestiscono feed di dati in tempo reale, ad esempio dai sensori IoT, i dati possono arrivare non ordinati o subire ritardi nell'elaborazione dovuti alla latenza della rete e ad altri errori legati all'origine durante l'importazione. Come parte della AWS Glue piattaforma, AWS Glue Lo streaming si basa su queste funzionalità per fornire streaming scalabili e serverless. Inoltre, si basa sullo streaming strutturato di Apache SparkETL, che consente agli utenti di elaborare i dati in tempo reale.
In questo argomento, esploreremo i concetti e le funzionalità di streaming avanzati di AWS Glue streaming.
Considerazioni di carattere temporale relative all'elaborazione dei flussi
Esistono quattro nozioni di tempo relative all'elaborazione dei flussi:

-
Ora dell'evento: l'ora in cui si è verificato l'evento. Nella maggior parte dei casi, questo campo è incorporato nei dati degli eventi stessi all'origine.
-
E vent-time-window — L'intervallo di tempo tra due ore dell'evento. Come mostrato nel diagramma precedente, W1 è compreso tra le 17:00 e le event-time-window 17:10. Ciascuno di essi event-time-window è un raggruppamento di più eventi.
-
Tempo di attivazione: il tempo di attivazione controlla la frequenza con cui si verificano l'elaborazione dei dati e l'aggiornamento dei risultati. Si tratta dell'ora in cui è iniziata l'elaborazione del microbatch.
-
Ora di importazione: l'ora in cui i dati del flusso sono stati importati nel servizio di streaming. Se l'ora dell'evento non è incorporata nell'evento stesso, in alcuni casi può essere utilizzata per la creazione di finestre.
Raggruppamenti in finestre
Il «windowing» è una tecnica che consente di raggruppare e aggregare più eventi in base a. event-time-window Esploreremo i vantaggi del windowing e le possibilità di utilizzarlo nei seguenti esempi.
A seconda del caso d'uso aziendale, Spark supporta tre tipi di finestre temporali.
-
Finestra a cascata: è una serie di dimensioni event-time-windows fisse non sovrapposte entro le quali viene effettuata l'aggregazione.
-
Finestra scorrevole: come le finestre a cascata ha dimensioni fisse, ma a differenza di esse può sovrapporsi o scorrere, a condizione che la durata dello scorrimento sia inferiore alla durata della finestra stessa.
-
Finestra di sessione: inizia con un evento relativo ai dati di input e continua a espandersi fintantoché riceve input entro un intervallo di tempo o un periodo di inattività. Una finestra di sessione può avere una lunghezza fissa o dinamica a seconda degli input.
Finestra a cascata
La finestra a cascata è una serie di dimensioni event-time-windows fisse non sovrapposte entro le quali viene effettuata l'aggregazione. Cerchiamo di capirlo con un esempio tratto dalla realtà.
Company ABC Auto vuole lanciare una campagna di marketing per un nuovo marchio di auto sportive. Vuole scegliere la città con il maggior numero di appassionati di auto sportive. Per raggiungere questo obiettivo, pubblica sul suo sito web un breve annuncio pubblicitario di 15 secondi di presentazione dell'auto. Tutti i «clic» e la «città» corrispondente vengono registrati e trasmessi a. Amazon Kinesis Data Streams Vogliamo contare il numero di clic in una finestra di 10 minuti e raggrupparlo per città per vedere quale città registra la domanda maggiore. Di seguito è riportato l'output dell'aggregazione.
| ora_inizio_finestra | ora_fine_finestra | città | clic_totali |
|---|---|---|---|
| 2023-07-10 17:00:00 | 2023-07-10 17:10:00 | Dallas | 75 |
| 2023-07-10 17:00:00 | 2023-07-10 17:10:00 | Chicago | 10 |
| 2023 -07-10 17:20:00 | 2023 -07-10 17:30:00 | Dallas | 20 |
| 2023 -07-10 17:20:00 | 2023 -07-10 17:30:00 | Chicago | 50 |
Come spiegato sopra, questi event-time-windows sono diversi dagli intervalli del tempo di attivazione. Ad esempio, anche se l'intervallo di attivazione è ogni minuto, i risultati di output mostreranno solo finestre di aggregazione di 10 minuti non sovrapposte. A fini di ottimizzazione, è meglio allineare l'intervallo di attivazione a. event-time-window
Nella tabella precedente, nella finestra 17:00-17:10 Dallas ha registrato 75 clic mentre Chicago ha registrato 10 clic. Inoltre, per nessuna città sono presenti dati per la finestra 17:10-17:20, quindi questa finestra viene omessa.
Ora puoi eseguire ulteriori analisi su questi dati nell'applicazione di analisi a valle per determinare la città più indicata per la conduzione della campagna di marketing.
Utilizzo delle finestre a cascata in AWS Glue
-
Crea un file Amazon Kinesis Data Streams DataFrame e leggi da esso. Esempio:
parsed_df = kinesis_raw_df \ .selectExpr('CAST(data AS STRING)') \ .select(from_json("data", ticker_schema).alias("data")) \ .select('data.event_time','data.ticker','data.trade','data.volume', 'data.price') -
Elabora i dati in una finestra a cascata. Nell'esempio seguente, i dati vengono raggruppati in base al campo di input "ora_evento" in finestre a cascata di 10 minuti e l'output viene scritto in un data lake Amazon S3.
grouped_df = parsed_df \ .groupBy(window("event_time", "10 minutes"), "city") \ .agg(sum("clicks").alias("total_clicks")) summary_df = grouped_df \ .withColumn("window_start_time", col("window.start")) \ .withColumn("window_end_time", col("window.end")) \ .withColumn("year", year("window_start_time")) \ .withColumn("month", month("window_start_time")) \ .withColumn("day", dayofmonth("window_start_time")) \ .withColumn("hour", hour("window_start_time")) \ .withColumn("minute", minute("window_start_time")) \ .drop("window") write_result = summary_df \ .writeStream \ .format("parquet") \ .trigger(processingTime="10 seconds") \ .option("checkpointLocation", "s3a://bucket-stock-stream/stock-stream-catalog-job/checkpoint/") \ .option("path", "s3a://bucket-stock-stream/stock-stream-catalog-job/summary_output/") \ .partitionBy("year", "month", "day") \ .start()
Finestra scorrevole
Come le finestre a cascata, le finestre scorrevoli hanno dimensioni fisse, ma a differenza di esse possono sovrapporsi o scorrere, a condizione che la durata dello scorrimento sia inferiore alla durata della finestra stessa. In virtù della natura dello scorrimento, uno stesso input può essere associato a più finestre.
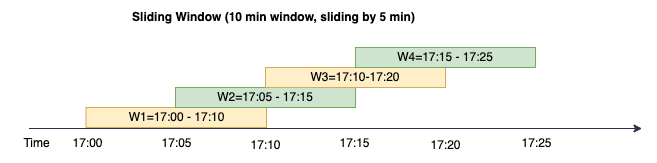
Per comprendere meglio, prendiamo in considerazione l'esempio di una banca che desidera rilevare potenziali frodi relative alle carte di credito. Un'applicazione di streaming potrebbe monitorare un flusso continuo delle transazioni con carta di credito. Queste transazioni potrebbero essere aggregate in finestre della durata di 10 minuti e ogni 5 minuti la finestra scorrerebbe in avanti, eliminando i 5 minuti di dati più vecchi e aggiungendo gli ultimi 5 minuti di dati più recenti. All'interno di ciascuna finestra, le transazioni potrebbero essere raggruppate per paese, verificando la presenza di schemi sospetti, ad esempio una transazione negli Stati Uniti seguita immediatamente da un'altra in Australia. Per semplicità, tali transazioni vengono classificate come frodi quando l'importo totale delle transazioni è superiore a 100 USD. Se viene rilevato uno schema di questo tipo, viene segnalata una frode potenziale e la carta potrebbe essere bloccata.
Il sistema di elaborazione delle carte di credito sta inviando a Kinesis una serie di transazioni con i dati relativi agli ID delle carte di credito e al paese. Un AWS Glue processo di esegue l'analisi e produce il seguente output aggregato.
| ora_inizio_finestra | ora_fine_finestra | ultime_quattro_cifre_carta | country | importo_totale |
|---|---|---|---|---|
| 2023-07-10 17:00:00 | 2023-07-10 17:10:00 | 6544 | US | 85 |
| 2023-07-10 17:00:00 | 2023-07-10 17:10:00 | 6544 | Australia | 10 |
| 2023 -07-10 17:05:05:45 | 2023 -07-10 17:15:15:45 | 6544 | US | 50 |
| 2023-07-10 17:10:45 | 2023 -07-10 17:20:20:45 | 6544 | US | 50 |
| 2023-07-10 17:10:45 | 2023 -07-10 17:20:20:45 | 6544 | Australia | 150 |
In base all'aggregazione di cui sopra, si può osservare come la finestra di 10 minuti scorra ogni 5 minuti, sommata per importo della transazione. L'anomalia viene rilevata nella finestra 17:10-17:20 dove compare un valore anomalo, ossia una transazione del valore di 150 USD in Australia. AWS Glue è in grado di rilevare questa anomalia e inviare un evento di allarme con la chiave offensiva a un argomento utilizzando boto3. SNS Inoltre, una funzione Lambda può iscriversi a questo argomento e agire di conseguenza.
Elaborazione dei dati in una finestra scorrevole
Per implementare la finestra scorrevole vengono utilizzate la clausola group-by e la funzione finestra, come mostrato di seguito.
grouped_df = parsed_df \
.groupBy(window(col("event_time"), "10 minute", "5 min"), "country", "card_last_four") \
.agg(sum("tx_amount").alias("total_amount"))
Finestra di sessione
A differenza delle due finestre precedenti, che hanno una dimensione fissa, la finestra di sessione può avere una lunghezza fissa o dinamica a seconda degli input. Una finestra di sessione inizia con un evento di dati di input e continua a espandersi finché riceve input entro un intervallo di tempo o un periodo di inattività.

Facciamo un esempio. ABCL'hotel aziendale vuole scoprire qual è il periodo più trafficato della settimana e proporre agli ospiti offerte più allettanti. Non appena un ospite effettua il check-in, viene avviata una finestra di sessione e Spark mantiene uno stato con aggregazione a tale scopo. event-time-window Ogni volta che un ospite effettua il check-in, un evento viene generato e inviato ad Amazon Kinesis Data Streams. L'hotel decide che se non vengono effettuati check-in per un periodo di 15 minuti, event-time-window può essere chiuso. Il successivo event-time-window comincerà quando verrà effettuato un nuovo check-in. L'output è simile al seguente.
| ora_inizio_finestra | ora_fine_finestra | città | checkin_totali |
|---|---|---|---|
| 2023 -07-10 17:02:00 | 2023 -07-10 17:30:00 | Dallas | 50 |
| 2023 -07-10 17:02:00 | 2023 -07-10 17:30:00 | Chicago | 25 |
| 2023 -07-10 17:40:00 | 2023 -07-10 18:20:00 | Dallas | 75 |
| 2023 -07-10 18:50:45 | 2023 -07-10 19:15:45 | Dallas | 20 |
Il primo check-in è avvenuto all'ora_evento=17:02. L'aggregazione inizia event-time-window alle 17:02. L'aggregazione continuerà fintantoché verranno ricevuti eventi nell'arco di 15 minuti. Nell'esempio precedente, l'ultimo evento è stato ricevuto alle 17:15, poi per i successivi 15 minuti non si sono verificati eventi. Di conseguenza, Spark l'ha chiuso alle event-time-window 17:15 +15 minuti = 17:30 e l'ha impostato come 17:02-17:30. È iniziato un nuovo evento alle event-time-window 17:47, quando ha ricevuto un nuovo evento di dati relativo a un check-in.
Elaborazione dei dati in una finestra di sessione
Per implementare la finestra scorrevole vengono utilizzate la clausola group-by e la funzione finestra.
grouped_df = parsed_df \
.groupBy(session_window(col("event_time"), "10 minute"), "city") \
.agg(count("check_in").alias("total_checkins"))
Modalità di output
La modalità di output è la modalità in cui i risultati della tabella illimitata vengono scritti nel sink esterno. Sono disponibili tre modalità. Nell'esempio seguente si contano le occorrenze di una parola mentre le righe di dati vengono trasmesse ed elaborate in ogni microbatch.
-
Modalità completa: l'intera tabella dei risultati viene scritta nel sink dopo ogni elaborazione di microbatch, anche se il conteggio delle parole non è stato aggiornato nella versione corrente event-time-window.
-
Modalità di aggiunta: questa è la modalità predefinita, in cui solo le nuove parole e/o righe aggiunte alla tabella dei risultati dall'ultima attivazione vengono scritte nel sink. Questa modalità è utile per lo streaming stateless per query come mapflatMap, filter, ecc.
-
Modalità di aggiornamento: nel sink vengono scritte solo le parole e/o le righe che sono state aggiornate o aggiunte nella tabella dei risultati dall'ultima attivazione.
Nota
La modalità di output "aggiornamento" non è supportata per le finestre di sessione.
Gestione di dati in ritardo e filigrane
Quando si lavora con dati in tempo reale, i dati potrebbero pervenire in ritardo a causa della latenza della rete e di guasti a monte; pertanto, occorre un meccanismo per eseguire nuovamente l'aggregazione dei dati mancati. event-time-window Tuttavia, a tale scopo, è necessario mantenere lo stato. Allo stesso tempo, per limitare le dimensioni dello stato, è necessario rimuovere i dati più vecchi. La versione 2.1 di Spark ha aggiunto il supporto per una funzionalità chiamata "watermarking", ossia "applicazione della filigrana", che mantiene lo stato e consente all'utente di specificare la soglia per i dati in ritardo.
Facendo riferimento all'esempio sul simbolo azionario riportato sopra, poniamo che i dati in ritardo non possano superare la soglia dei 10 minuti. Per semplificare, supponiamo di utilizzare le finestre a cascataAMZ, il simbolo come. BUY
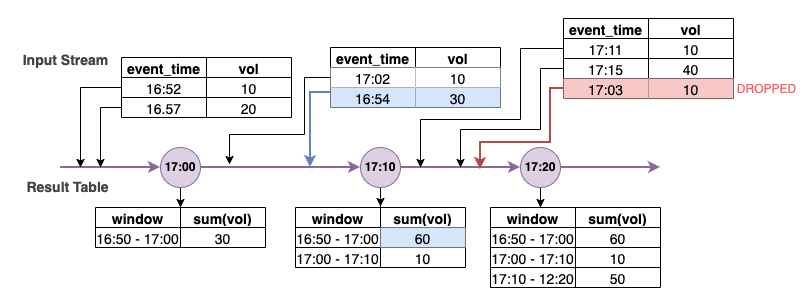
Nel diagramma precedente, calcoliamo il volume totale su una finestra a cascata di 10 minuti. L'attivazione è impostata alle ore 17:00, 17:10 e 17:20. Sopra la freccia della linea temporale si trova il flusso di dati di input, mentre sotto si trova la tabella dei risultati illimitata.
Nella prima finestra a cascata di 10 minuti i dati sono stati aggregati in base a ora_evento e il volume_totale calcolato è stato 30. Nel secondo event-time-window, Spark ha ricevuto il primo evento di dati con ora_evento= 17:02. Poiché questo è il valore massimo di ora_evento visto finora da Spark, la soglia della filigrana viene riportata indietro di 10 minuti (ossia, ora_evento_filigrana=16:52). Qualsiasi evento di dati con un valore di ora_evento successivo alle 16:52 verrà preso in considerazione per l'aggregazione entro i limiti temporali, mentre gli eventi di dati precedenti verranno eliminati. Ciò consente a Spark di mantenere uno stato intermedio per altri 10 minuti per accogliere i dati in ritardo. Intorno alle 17:08, Spark ha ricevuto un evento con un valore di ora_evento=16:54 che rientrava nella soglia. Pertanto, Spark ha ricalcolato le "16:50-17:00" event-time-window e il volume totale è stato modificato da 30 a 60.
Tuttavia, all'ora di attivazione 17:20, quando Spark ha ricevuto un evento con ora_evento=17:15, ha impostato ora_evento_filigrana=17:05. Pertanto, l'evento di dati in ritardo con il valore di ora_evento=17:03 è stato considerato successivo alla soglia di tolleranza e quindi ignorato.
Watermark Boundary = Max(Event Time) - Watermark ThresholdUtilizzo delle filigrane in AWS Glue
Spark non emette né scrive i dati nel sink esterno finché non viene superato il limite della filigrana. Per implementare una filigrana in AWS Glue, consulta l'esempio di seguito.
grouped_df = parsed_df \
.withWatermark("event_time", "10 minutes") \
.groupBy(window("event_time", "5 minutes"), "ticker") \
.agg(sum("volume").alias("total_volume"))
