Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migrazione in corso AWS Glue per Spark jobs per AWS Glue versione 5.0
Questo argomento descrive le modifiche tra AWS Glue le versioni 0.9, 1.0, 2.0, 3.0 e 4.0 per consentire la migrazione delle applicazioni Spark e dei lavori ETL alla 5.0. AWS Glue Descrive inoltre le funzionalità della AWS Glue versione 5.0 e i vantaggi del suo utilizzo.
Per utilizzare questa funzionalità con i tuoi lavori AWS Glue ETL, scegli Glue version quando 5.0 crei i tuoi lavori.
Argomenti
Nuove funzionalità
Questa sezione descrive le nuove funzionalità e i vantaggi della AWS Glue versione 5.0.
-
Aggiornamento di Apache Spark dalla versione 3.3.0 della versione AWS Glue 4.0 alla versione 3.5.4 della versione 5.0. AWS Glue Per informazioni, consulta Miglioramenti principali da Spark 3.3.0 a Spark 3.5.4.
-
Spark-native controllo degli accessi a grana fine (FGAC) utilizzando Lake Formation. Ciò include FGAC per le tabelle Iceberg, Delta e Hudi. Per ulteriori informazioni, consulta Using AWS Glue with AWS Lake Formation per un controllo granulare degli accessi.
Tenete presente le seguenti considerazioni o limitazioni per FGAC: Spark-native
Attualmente la scrittura dei dati non è supportata
Scrivere in Iceberg
GlueContexttramite Lake Formation richiede invece l'uso del controllo degli accessi IAM
Per un elenco completo delle limitazioni e delle considerazioni relative all'uso Spark-native di FGAC, vedere. Considerazioni e limitazioni
-
Supporto per Amazon S3 Access Grants come soluzione scalabile di controllo degli accessi ai tuoi dati Amazon S3 da. AWS Glue Per ulteriori informazioni, consulta Utilizzo di Amazon S3 Access Grants con AWS Glue.
-
Formati a tabella aperta (OTF) aggiornati a Hudi 0.15.0, Iceberg 1.7.1 e Delta Lake 3.3.0
-
Supporto per Amazon SageMaker Unified Studio.
-
Amazon SageMaker Lakehouse e l'integrazione dell'astrazione dei dati. Per ulteriori informazioni, consulta Interrogazione dei cataloghi di dati dei metastore da AWS Glue ETL.
-
Supporto per l'installazione di librerie Python aggiuntive utilizzando
requirements.txt. Per ulteriori informazioni, consulta Installazione di librerie Python aggiuntive in AWS Glue 5.0 o versioni successive utilizzando requirements.txt. -
AWS Glue 5.0 supporta la derivazione dei dati in Amazon DataZone. Puoi AWS Glue configurare la raccolta automatica delle informazioni sulla derivazione durante le esecuzioni dei job Spark e inviare gli eventi di derivazione da visualizzare in Amazon. DataZone Per ulteriori informazioni, consulta Data lineage in Amazon DataZone.
Per configurarlo sulla AWS Glue console, attiva Generate lineage events e inserisci il tuo ID di DataZone dominio Amazon nella scheda Job details.
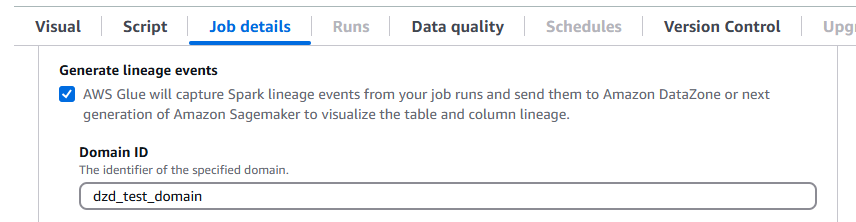
In alternativa, puoi fornire il seguente parametro di lavoro (inserisci il tuo ID di DataZone dominio):
Chiave:
--confValore:
extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener —conf spark.openlineage.transport.type=amazon_datazone_api -conf spark.openlineage.transport.domainId=<your-domain-ID>
-
Aggiornamenti del connettore e dei driver JDBC. Per ulteriori informazioni, consultare Appendice B: aggiornamenti dei driver JDBC e Appendice C: Aggiornamenti dei connettori.
-
Aggiornamento Java da 8 a 17.
-
Maggiore spazio di archiviazione AWS Glue
G.1XeG.2Xlavoro per i lavoratori con spazio su disco che è aumentato rispettivamente a 94 GB e 138 GB. Inoltre,R.8Xsono disponibili nuovi tipi diG.12Xworker e versioni ottimizzate perR.1XlaR.2Xmemoria nella versione AWS Glue 4.0 e successive.G.16XR.4XPer ulteriori informazioni, consulta Jobs Support for AWS SDK for Java, versione 2 AWS Glue - 5.0, i job possono utilizzare le versioni
Java 1.12.569 o 2.28.8 se il job supporta la versione 2. L' AWS SDK for Java 2.x è un'importante riscrittura del codice base della versione 1.x. È stata sviluppata su base Java 8+ e aggiunge diverse caratteristiche richieste frequentemente. Queste includono il supporto per la funzionalità non bloccante I/O e la possibilità di inserire un'implementazione HTTP diversa in fase di esecuzione. Per ulteriori informazioni, inclusa una Guida alla migrazione da SDK per Java v1 a v2, consultare la guida AWS SDK per Java, versione 2.
Modifiche importanti
Notare le seguenti modifiche speciali:
-
Nella AWS Glue versione 5.0, quando si utilizza il file system S3A e se sia `fs.s3a.endpoint` che `fs.s3a.endpoint.region` non sono impostati, la regione predefinita utilizzata da S3A è `us-east-2`. Ciò può causare problemi, come errori di timeout di caricamento di S3, in particolare per i processi VPC. Per mitigare i problemi causati da AWS Glue questa modifica, imposta la configurazione Spark `fs.s3a.endpoint.region` quando usi il file system S3A nella versione 5.0.
-
Lake Formation Fine-grained Access Control (FGAC)
-
AWS Glue 5.0 supporta solo il nuovo Spark-native FGAC che utilizza Spark. DataFrames Non supporta l'utilizzo di FGAC. AWS Glue DynamicFrames
-
L'uso di FGAC nella versione 5.0 richiede la migrazione da Spark AWS Glue DynamicFrames DataFrames
-
Se non hai bisogno di FGAC, non è necessario migrare a Spark DataFrame e le GlueContext funzionalità, come i segnalibri di lavoro e i predicati push down, continueranno a funzionare.
-
-
I lavori con Spark-native FGAC richiedono un minimo di 4 dipendenti: un driver utente, un driver di sistema, un esecutore di sistema e un esecutore utente in standby.
-
Per ulteriori informazioni, vedere Using with per il controllo granulare degli AWS Glue accessi AWS Lake Formation.
-
-
Accesso completo alla tabella (FTA) con Lake Formation
-
AWS Glue 5.0 supporta FTA con Spark-native DataFrames (nuove) e GlueContext DynamicFrames (versioni precedenti, con limitazioni)
-
Spark-native FTA
-
Se viene utilizzato lo script 4.0 GlueContext, esegui la migrazione all'utilizzo di Spark nativo.
-
Questa funzionalità è limitata alle tabelle hive e iceberg
-
Per ulteriori informazioni sulla configurazione di un job 5.0 per utilizzare l'FTA nativo di Spark, consulta. Native Spark FTA nella versione 5.0 AWS Glue
-
-
GlueContext DynamicFrame FTA
-
Non è necessaria alcuna modifica del codice
-
Questa funzionalità è limitata alle tabelle non OTF: non funzionerà con Iceberg, Delta Lake e Hudi.
-
-
Il lettore SIMD CSV vettorializzato non è supportato.
La registrazione continua nel gruppo di log di output non è supportata. Utilizzare invece il gruppo di log
error.Il AWS Glue job run insights
job-insights-rule-driverè stato obsoleto. Il flusso di logjob-insights-rca-driversi trova ora nel gruppo di log di errore.Athena-based custom/marketplace i connettori non sono supportati.
I connettori Adobe Marketo Engage, Facebook Ads, Google Ads, Google Analytics 4, Google Sheets, Hubspot, Instagram Ads, Intercom, Jira Cloud, Oracle, Salesforce, Salesforce Marketing Cloud NetSuite, Salesforce Marketing Cloud Account Engagement, SAP OData, Slack, Snapchat Ads, Stripe, Zendesk e Zoho CRM non sono supportati. ServiceNow
Le AWS Glue proprietà log4j personalizzate non sono supportate nella versione 5.0.
Miglioramenti principali da Spark 3.3.0 a Spark 3.5.4
Nota i seguenti miglioramenti:
-
Client Python per Spark SPARK-39375
Connect (). -
Implementa il supporto per i valori DEFAULT per le colonne nelle tabelle () SPARK-38334
. -
Supporta «Riferimenti agli alias delle colonne laterali» () SPARK-27561
. -
Rafforza l'utilizzo di SQLSTATE per le classi di errore (). SPARK-41994
-
Abilita il filtro Bloom Joins per impostazione predefinita (). SPARK-38841
-
Migliore scalabilità dell'interfaccia utente Spark e stabilità dei driver per applicazioni di grandi dimensioni (). SPARK-41053
-
Monitoraggio asincrono dei progressi in streaming strutturato (). SPARK-39591
-
Elaborazione statica arbitraria in Python in streaming strutturato (). SPARK-40434
-
Miglioramenti della copertura dell'API Pandas (SPARK-42882
) e NumPy supporto di input in (). PySpark SPARK-39405 -
Fornisci un profiler di memoria per le funzioni PySpark definite dall'utente (). SPARK-40281
-
Implementa PyTorch distributor (). SPARK-41589
-
Pubblica artefatti SBOM (). SPARK-41893
-
IPv6-only Ambiente di supporto (SPARK-39457
). -
Scheduler K8s personalizzato (Apache YuniKorn e Volcano) GA (). SPARK-42802
-
Supporto client Scala e Go in Spark Connect (SPARK-42554
) e (SPARK-43351 ). -
PyTorch-based supporto ML distribuito per Spark Connect (SPARK-42471
). -
Supporto di streaming strutturato per Spark Connect in Python e Scala SPARK-42938
(). -
Supporto dell'API Pandas per il Python Spark Connect Client (). SPARK-42497
-
Introduci le UDF di Arrow Python (). SPARK-40307
-
Supporta le funzioni di tabella definite dall'utente in Python (). SPARK-43798
-
Migra PySpark gli errori nelle classi di errore (). SPARK-42986
-
PySpark framework di test (SPARK-44042
). -
Aggiungi il supporto per Datasketches HllSketch () SPARK-16484
. -
Built-in Miglioramento della funzione SQL () SPARK-41231
. -
CLAUSOLA IDENTIFIER () SPARK-43205
. -
Aggiungi funzioni SQL in Scala, Python e R API () SPARK-43907
. -
Aggiungi il supporto per argomenti denominati per le funzioni SQL (SPARK-43922
). -
Evita la riesecuzione di attività non necessarie su un esecutore dismesso perso se i dati shuffle vengono migrati (). SPARK-41469
-
ML distribuito <> spark connect (). SPARK-42471
-
DeepSpeed distributore (). SPARK-44264
-
Implementa il checkpoint del changelog per RockSDB state store (). SPARK-43421
-
Introduci la propagazione della filigrana tra gli operatori (). SPARK-42376
-
Introduci drop DuplicatesWithinWatermark () SPARK-42931
. -
Miglioramenti alla gestione della memoria del provider di archivi di stato RockSDB (). SPARK-43311
Azioni verso cui migrare AWS Glue 5.0
Per i processi esistenti, modifica la Glue version dalla versione precedente a Glue 5.0 nella configurazione del processo.
-
In AWS Glue Studio, scegli
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3inGlue version. -
Nell'API, scegli
5.0nel parametroGlueVersionnell'operazione APIUpdateJob.
Per i nuovi processi, scegli Glue 5.0 al momento della creazione.
-
Nella console, scegli
Spark 3.5.4, Python 3 (Glue Version 5.0) or Spark 3.5.4, Scala 2 (Glue Version 5.0)inGlue version. -
In AWS Glue Studio, scegli
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3inGlue version. -
Nell'API, scegli
5.0nel parametroGlueVersionnell'operazione APICreateJob.
Per visualizzare i log degli eventi di Spark della AWS Glue versione 5.0 della versione AWS Glue 2.0 o precedente, avvia un server di cronologia Spark aggiornato per la AWS Glue versione 5.0 utilizzando o Docker. CloudFormation
Elenco di controllo della migrazione
Rivedi questo elenco di controllo per la migrazione:
-
Aggiornamenti di Java 17
-
[Scala] Aggiorna le chiamate AWS SDK dalla v1 alla v2
-
Migrazione da Python 3.10 a 3.11
-
[Python] Aggiornare i riferimenti di avvio da 1.26 a 1.34
AWS Glue Funzionalità 5.0
Questa sezione descrive AWS Glue le funzionalità in modo più dettagliato.
Interrogazione dei cataloghi di dati dei metastore da AWS Glue ETL
Puoi registrare il tuo AWS Glue lavoro per accedere a AWS Glue Data Catalog, che rende disponibili tabelle e altre risorse di metastore per diversi consumatori. Il Data Catalog supporta una gerarchia multicatalogo, che unifica tutti i dati nei data lake Amazon S3. Fornisce inoltre sia un'API del metastore Hive che un'API Apache Iceberg open source per l'accesso ai dati. Queste funzionalità sono disponibili per altri servizi orientati ai dati come Amazon EMR, Amazon Athena AWS Glue e Amazon Redshift.
Quando crei risorse nel Data Catalog, puoi accedervi da qualsiasi motore SQL che supporti l'API REST di Apache Iceberg. AWS Lake Formation gestisce le autorizzazioni. Dopo la configurazione, è possibile sfruttare le funzionalità AWS Glue di interrogazione di dati diversi interrogando queste risorse di metastore con applicazioni familiari. Queste includono Apache Spark e Trino.
Come sono organizzate le risorse dei metadati
I dati sono organizzati in una gerarchia logica di cataloghi, database e tabelle, utilizzando: AWS Glue Data Catalog
Catalogo: un contenitore logico che contiene oggetti provenienti da un archivio dati, come schemi o tabelle.
Database: organizza oggetti di dati come tabelle e viste in un catalogo.
Tabelle e viste: oggetti di dati in un database che forniscono un livello di astrazione con uno schema comprensibile. Semplificano l'accesso ai dati sottostanti, che possono essere in vari formati e in varie posizioni.
Migrazione da AWS Glue da 4,0 a AWS Glue 5.0
Tutti i parametri di lavoro e le funzionalità principali esistenti in AWS Glue 4.0 esisteranno nella AWS Glue versione 5.0, ad eccezione delle trasformazioni dell'apprendimento automatico.
Sono stati aggiunti i nuovi parametri seguenti:
-
--enable-lakeformation-fine-grained-access: abilita la funzionalità di controllo degli accessi a grana fine (FGAC) nelle tabelle di Lake Formation. AWS
Consulta la documentazione relativa alla migrazione di Spark:
Migrazione da AWS Glue da 3.0 a AWS Glue 5.0
Nota
Per le fasi di migrazione relative alla AWS Glue versione 4.0, vedereMigrazione dalla 3.0 alla 4.0 AWS Glue AWS Glue.
Tutti i parametri di lavoro e le funzionalità principali esistenti nella AWS Glue versione 3.0 esisteranno nella AWS Glue versione 5.0, ad eccezione delle trasformazioni di apprendimento automatico.
Migrazione da AWS Glue da 2.0 a AWS Glue 5.0
Nota
Per le fasi di migrazione relative alla AWS Glue 4.0 e un elenco delle differenze di migrazione tra AWS Glue la versione 3.0 e 4.0, vedereMigrazione dalla 3.0 alla 4.0 AWS Glue AWS Glue.
Tieni inoltre presente le seguenti differenze di migrazione tra AWS Glue le versioni 3.0 e 2.0:
Tutti i parametri di lavoro e le funzionalità principali esistenti nella AWS Glue versione 2.0 esisteranno nella AWS Glue versione 5.0, ad eccezione delle trasformazioni di apprendimento automatico.
Diverse modifiche di Spark da sole potrebbero richiedere la revisione degli script per garantire che non si faccia riferimento alle caratteristiche rimosse. Ad esempio, Spark 3.1.1 e versioni successive non abilitano le Scala-untyped UDF, ma Spark 2.4 le consente.
Python 2.7 non è supportato.
Eventuali jar aggiuntivi forniti nei job AWS Glue 2.0 esistenti possono creare dipendenze in conflitto poiché sono stati effettuati aggiornamenti in diverse dipendenze. È possibile evitare conflitti di dipendenze con il parametro
--user-jars-firstdel processo.Modifiche al comportamento dei file in parquet con timestamp. loading/saving from/to Per ulteriori dettagli, consultare Aggiornamento da Spark SQL 3.0 a 3.1.
Diverso parallelismo delle attività Spark per la configurazione. driver/executor È possibile regolare il parallelismo delle attività passando l'argomento del processo
--executor-cores.
Modifiche al comportamento di registrazione in AWS Glue 5.0
Di seguito sono riportate le modifiche al comportamento di registrazione nella AWS Glue versione 5.0. Per ulteriori informazioni, vedere Logging for AWS Glue jobs.
-
Tutti i log (log di sistema, log dei daemon Spark, log degli utenti e log di Glue Logger) vengono ora scritti nel gruppo di log
/aws-glue/jobs/errorper impostazione predefinita. -
Il gruppo di log
/aws-glue/jobs/logs-v2utilizzato per la registrazione continua nelle versioni precedenti non viene più utilizzato. -
Non è più possibile rinominare o personalizzare i nomi dei gruppi di log o dei flussi di log utilizzando gli argomenti di registrazione continua rimossi. Consultate invece i nuovi argomenti relativi al lavoro nella AWS Glue versione 5.0.
Vengono introdotti due nuovi argomenti relativi al lavoro in AWS Glue 5.0
-
––custom-logGroup-prefix: consente di specificare un prefisso personalizzato per i gruppi di log/aws-glue/jobs/errore/aws-glue/jobs/output. -
––custom-logStream-prefix: consente di specificare un prefisso personalizzato per i nomi dei flussi di log all'interno dei gruppi di log.Le regole e le limitazioni di convalida per i prefissi personalizzati includono:
-
L'intero nome del flusso di log deve contenere da 1 a 512 caratteri.
-
Il prefisso personalizzato per i nomi dei flussi di log è limitato a 400 caratteri.
-
I caratteri consentiti nei prefissi includono caratteri alfanumerici, caratteri di sottolineatura (`_`), trattini (`-`) e barre (`/`).
-
Argomenti di registrazione continua obsoleti AWS Glue 5.0
I seguenti argomenti di lavoro per la registrazione continua sono obsoleti nella versione 5.0 AWS Glue
-
––enable-continuous-cloudwatch-log -
––continuous-log-logGroup -
––continuous-log-logStreamPrefix -
––continuous-log-conversionPattern -
––enable-continuous-log-filter
Migrazione di connettori e driver JDBC per AWS Glue 5.0
Per le versioni dei connettori JDBC e data lake che sono state aggiornate, consulta:
Le seguenti modifiche si applicano alle versioni dei connettori o dei driver identificate nelle appendici di Glue 5.0.
Amazon Redshift
Nota le seguenti modifiche:
Aggiunge il supporto per i nomi di tabella in tre parti per consentire al connettore di interrogare le tabelle di condivisione dei dati di Redshift.
Corregge la mappatura di Spark
ShortTypeper utilizzare RedshiftSMALLINTanzichéINTEGERper adattarla meglio alla dimensione prevista dei dati.È stato aggiunto il supporto per Custom Cluster Names (CNAME) per Amazon Redshift serverless.
Apache Hudi
Nota le seguenti modifiche:
Supporta l'indice di livello record.
Supporta la generazione automatica di chiavi di registrazione. Ora non è necessario specificare il campo della chiave di registrazione.
Apache Iceberg
Nota le seguenti modifiche:
Supporta il controllo granulare degli accessi con. AWS Lake Formation
Supporta la ramificazione e il tagging, che sono riferimenti denominati a snapshot con cicli di vita indipendenti.
È stata aggiunta una procedura di visualizzazione del registro delle modifiche che genera una vista che contiene le modifiche apportate a una tabella in un periodo specificato o tra snapshot specifici.
Delta Lake
Nota le seguenti modifiche:
Supporta Delta Universal Format (UniForm) che consente un accesso senza interruzioni tramite Apache Iceberg e Apache Hudi.
Supporta i vettori di cancellazione che implementano un Merge-on-Read paradigma.
AzureCosmos
Nota le seguenti modifiche:
È stato aggiunto il supporto per chiavi di partizione gerarchiche.
È stata aggiunta l'opzione per utilizzare lo schema personalizzato con StringType (raw json) per una proprietà annidata.
È stata aggiunta l'opzione di configurazione
spark.cosmos.auth.aad.clientCertPemBase64per consentire l'utilizzo dell'autenticazione SPN (ServicePrincipal nome) con certificato anziché il segreto del client.
Per ulteriori informazioni, consulta il registro delle modifiche del connettore Azure Cosmos DB Spark
Microsoft SQL Server
Nota le seguenti modifiche:
La crittografia TLS è abilita per impostazione predefinita.
Quando encrypt = false ma il server richiede la crittografia, il certificato viene convalidato in base all'impostazione della connessione
trustServerCertificate.aadSecurePrincipalIdeaadSecurePrincipalSecretresi obsoleti.getAADSecretPrincipalIdAPI rimossa.È stata aggiunta la risoluzione CNAME quando viene specificato il realm.
MongoDB
Nota le seguenti modifiche:
Supporto per la modalità micro-batch con Spark Structured Streaming.
Supporto per i tipi di dati BSON.
È stato aggiunto il supporto per la lettura di più raccolte quando si utilizzano modalità di streaming micro-batch o continuo.
Se il nome di una raccolta utilizzata nell'opzione di configurazione
collectioncontiene una virgola, Spark Connector la considera come due raccolte diverse. Per risolvere questo problema, è necessario evitare la virgola facendola precedere da una barra rovesciata (\).Se il nome di una raccolta utilizzata nell'opzione di
collectionconfigurazione è “*”, Spark Connector la interpreta come una specifica per la scansione di tutte le raccolte. Per risolvere questo problema, è necessario evitare l'asterisco facendolo precedere da una barra rovesciata (\).Se il nome di una raccolta utilizzata nell'opzione di configurazione
collectioncontiene una barra rovesciata (\), Spark Connector considera la barra rovesciata come un carattere di escape, il che potrebbe cambiare il modo in cui interpreta il valore. Per risolvere questo problema, è necessario evitare la barra rovesciata facendola precedere da un'altra barra rovesciata.
Per ulteriori informazioni, consultare il connettore MongoDB per le note di rilascio di Spark
Snowflake
Nota le seguenti modifiche:
È stato introdotto un nuovo parametro
trim_spaceche è possibile utilizzare per rifinire automaticamente i valori delle colonneStringTypedurante il salvataggio in una tabella Snowflake. Default:false.Per impostazione predefinita, il parametro
abort_detached_queryè stato disabilitato a livello di sessione.È stato rimosso il requisito del parametro
SFUSERquando si utilizza OAUTH.È stata rimossa la funzionalità Advanced Query Pushdown. Sono disponibili alternative alla funzionalità. Ad esempio, anziché caricare i dati dalle tabelle Snowflake, gli utenti possono caricare direttamente i dati dalle query SQL di Snowflake.
Per ulteriori informazioni, consultare il connettore Snowflake per le note di rilascio di Spark
Appendice A: Aggiornamenti importanti delle dipendenze
Di seguito sono riportati gli aggiornamenti delle dipendenze:
| Dipendenza | Versione 5.0 AWS Glue | Versione in AWS Glue 4.0 | Versione in AWS Glue 3.0 | Versione in AWS Glue 2.0 | Versione in AWS Glue 1.0 |
|---|---|---|---|---|---|
| Java | 17 | 8 | 8 | 8 | 8 |
| Spark | 3.5.4 | 3.3.0-amzn-1 | 3.1.1-amzn-0 | 2.4.3 | 2.4.3 |
| Hadoop | 3.4.1 | 3.3.3-amzn-0 | 3.2.1-amzn-3 | 2.8.5-amzn-5 | 2.8.5-amzn-1 |
| Scala | 2,12,18 | 2,12 | 2,12 | 2.11 | 2.11 |
| Jackson | 2,15,2 | 2,12 | 2,12 | 2.11 | 2.11 |
| Hive | 2.3.9-amzn-4 | 2.3.9-amzn-2 | 2.3.7-amzn-4 | 1.2 | 1.2 |
| EMRFS | 2,69,0 | 2,54,0 | 2,46,0 | 2.38.0 | 2.30.0 |
| Json4s | 3.7.0-M11 | 3.7.0-M11 | 36.6 | 3.5.x | 3.5.x |
| Arrow | 12,0,1 | 7,0,0 | 2.0.0 | 0.10.0 | 0.10.0 |
| AWS Glue Client Data Catalog | 4.5.0 | 3.7.0 | 3.0.0 | 1.10.0 | N/A |
| AWS SDK per Java | 2.29.52 | 1.12 | 1.12 | ||
| Python | 3,11 | 3,10 | 3.7 | 2.7 e 3.6 | 2.7 e 3.6 |
| Boto | 1,34,131 | 1,26 | 1,18 | 1.12 | N/A |
| Connettore EMR DynamoDB | 5.6.0 | 4,16,0 |
Appendice B: aggiornamenti dei driver JDBC
Di seguito sono riportati gli aggiornamenti dei driver JDBC:
| Driver | Versione del driver JDBC nella versione 5.0 AWS Glue | Versione del driver JDBC nella versione 4.0 AWS Glue | Versione del driver JDBC nella versione 3.0 AWS Glue | Versione del driver JDBC nelle versioni precedenti AWS Glue |
|---|---|---|---|---|
| MySQL | 8.0.33 | 8.0.23 | 8.0.23 | 5.1 |
| Microsoft SQL Server | 10,2,0 | 9,40 | 7,0,0 | 6.1.0 |
| Database Oracle | 23,3,023,09 | 21,7 | 21,1 | 11.2 |
| PostgreSQL | 42,7,3 | 42,36 | 4,2,18 | 42,1,0 |
| Amazon Redshift |
redshift-jdbc42-2.1.0.29 |
redshift-jdbc42-2.1.0.16 |
redshift-jdbc41-1.2.12.1017 |
redshift-jdbc41-1.2.12.1017 |
| SAP Hana | 2,20,17 | 2,17,12 | ||
| Teradata | 20,00,00,33 | 20,00,00,06 |
Appendice C: Aggiornamenti dei connettori
Di seguito sono riportati gli aggiornamenti dei connettori:
| Driver | Versione del connettore in 5.0 AWS Glue | Versione del connettore in AWS Glue 4.0 | Versione del connettore in AWS Glue 3.0 |
|---|---|---|---|
| Connettore EMR DynamoDB | 5.6.0 | 4.16.0 | |
| Amazon Redshift | 64,0 | 6.1.3 | |
| OpenSearch | 1.2.0 | 1.0.1 | |
| MongoDB | 10.3,0 | 10.0.4 | 3.0.0 |
| Snowflake | 3.0.0 | 2.12.0 | |
| Google BigQuery | 0.32.2 | 0,32,2 | |
| AzureCosmos | 4,33,0 | 42,0 | |
| AzureSQL | 1.3.0 | 1.3.0 | |
| Vertica | 33,5 | 3.3.5 |
Appendice D: Aggiornamenti di formato a tabella aperta
Di seguito sono riportati gli aggiornamenti di formato a tabella aperta:
| OTF | Versione del connettore in 5.0 AWS Glue | Versione del connettore in AWS Glue 4.0 | Versione del connettore in AWS Glue 3.0 |
|---|---|---|---|
| Hudi | 0.15.0 | 0.12.1 | 0,10,1 |
| Delta Lake | 3.3.0 | 2.1.0 | 1.0.0 |
| Iceberg | 1.7.1 | 1.0.0 | 0.13.1 |
