Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: crea il tuo primo carico di lavoro in streaming con Studio AWS Glue
In questo tutorial, imparerai come creare un lavoro in streaming utilizzando AWS Glue Studio. AWS Glue Studio è un'interfaccia visiva per creare AWS Glue posti di lavoro.
È possibile creare processi in streaming di estrazione, trasformazione e caricamento (ETL) che vengono eseguiti continuamente e utilizzano dati da origini di streaming in Flusso di dati Amazon Kinesis, Apache Kafka e Streaming gestito da Amazon per Apache Kafka (Amazon MSK).
Prerequisiti
Per seguire questo tutorial avrai bisogno di un utente con le autorizzazioni di utilizzo AWS della console, Amazon Kinesis AWS Glue, Amazon S3, Amazon Athena, AWS CloudFormation AWS Lambda e Amazon Cognito.
Utilizzo dei dati in streaming da Amazon Kinesis
Argomenti
Generazione di dati fittizi con Kinesis Data Generator
È possibile generare sinteticamente dati di esempio in formato JSON utilizzando Kinesis Data Generator (KDG). Puoi trovare le istruzioni complete e i dettagli nella documentazione dello strumento
Per iniziare, fai clic per eseguire un modello

nel tuo ambiente. AWS CloudFormation AWS Nota
Potresti riscontrare un errore nel CloudFormation modello perché alcune risorse, come l'utente Amazon Cognito per Kinesis Data Generator, esistono già nel tuo account. AWS Ciò potrebbe essere dovuto al fatto che l'hai già configurato in un altro tutorial o da un post di un blog. Per risolvere questo problema, puoi provare il modello in un nuovo AWS account per ricominciare da capo, oppure esplorare un'altra AWS regione. Queste opzioni consentono di eseguire il tutorial senza entrare in conflitto con le risorse esistenti.
Il modello fornisce un flusso di dati Kinesis e un account Kinesis Data Generator. Crea anche un bucket Amazon S3 per contenere i dati e un ruolo di servizio Glue con l'autorizzazione richiesta per questo tutorial.
Immetti un Nome utente e una Password che KDG utilizzerà per l'autenticazione. Prendi nota del nome utente e della password per utilizzarli in seguito.
Seleziona Avanti fino all'ultimo passaggio. Esprimi il consenso alla creazione di risorse IAM. Verifica la presenza di eventuali errori nella parte superiore dello schermo, ad esempio la password che non soddisfa i requisiti minimi, e implementa il modello.
Vai alla scheda Output dello stack. Una volta distribuito, il modello mostrerà la proprietà KinesisDataGeneratorUrlgenerata. Fai clic su quell'URL.
Inserisci il Nome utente e la Password di cui hai preso nota.
Seleziona la regione che stai utilizzando e seleziona il flusso Kinesis
GlueStreamTest-{AWS::AccountId}.Immetti il seguente modello:
{ "ventilatorid": {{random.number(100)}}, "eventtime": "{{date.now("YYYY-MM-DD HH:mm:ss")}}", "serialnumber": "{{random.uuid}}", "pressurecontrol": {{random.number( { "min":5, "max":30 } )}}, "o2stats": {{random.number( { "min":92, "max":98 } )}}, "minutevolume": {{random.number( { "min":5, "max":8 } )}}, "manufacturer": "{{random.arrayElement( ["3M", "GE","Vyaire", "Getinge"] )}}" }Ora puoi visualizzare i dati fittizi con Modello di prova e importare i dati fittizi in Kinesis con Invia dati.
Fai clic su Invia dati e genera 5-10.000 record su Kinesis.
Creazione di un lavoro AWS Glue in streaming con Studio AWS Glue
Passa alla AWS Glue console nella stessa regione.
Seleziona Processi ETL nella barra di navigazione a sinistra in Integrazione dati ed ETL.
Crea un AWS Glue Job tramite Visual con una tela bianca.

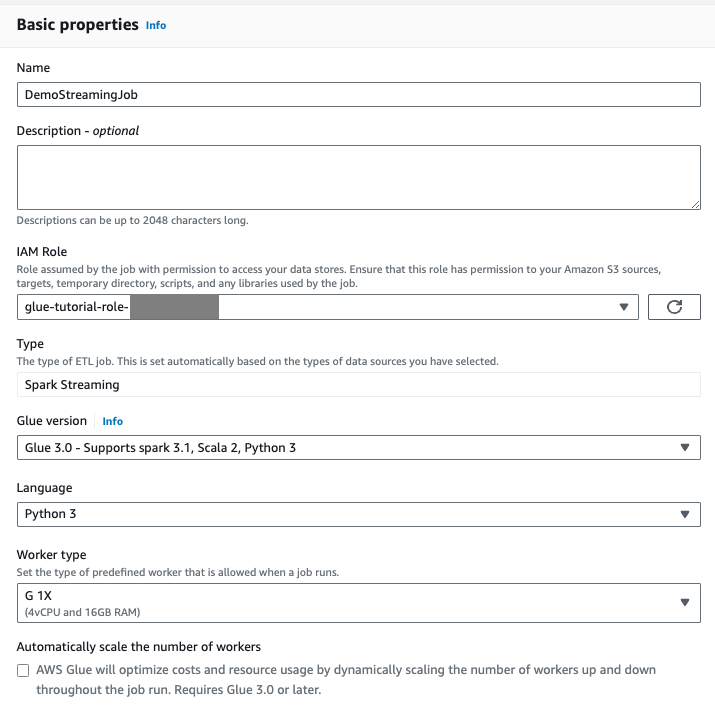
Passa alla scheda Dettagli del processo.
Per il nome del AWS Glue lavoro, immettere
DemoStreamingJob.Per IAM Role, seleziona il ruolo assegnato dal CloudFormation modello,
glue-tutorial-role-${AWS::AccountId}.Per Versione Glue, seleziona Glue 3.0. Mantieni tutte le altre opzioni predefinite.
Vai alla scheda Visivo.
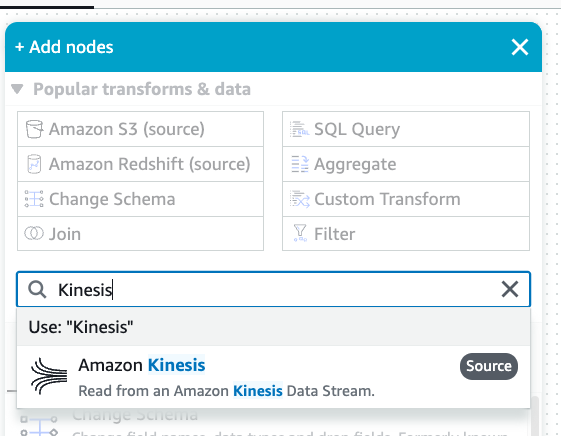
Fai clic sull'icona del segno più. Immetti Kinesis nella barra di ricerca. Seleziona l'origine dati Amazon Kinesis.
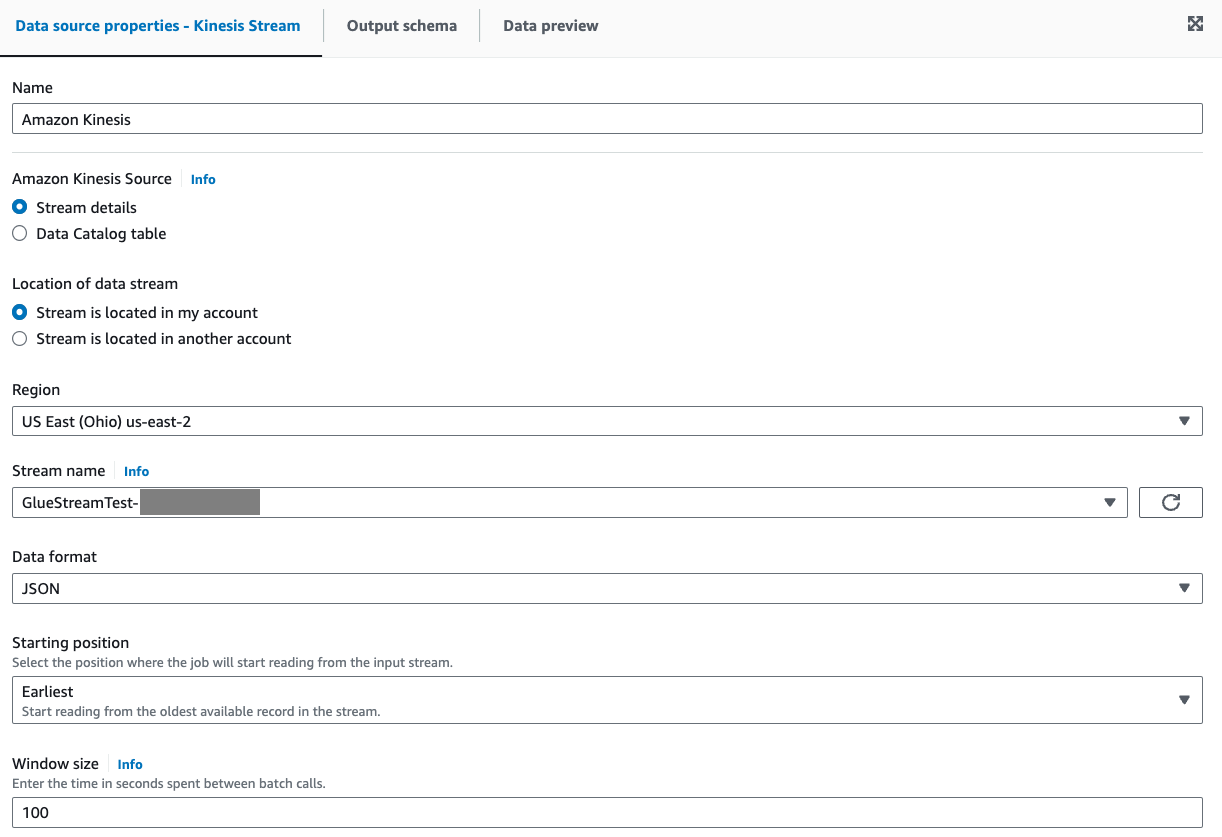
Seleziona Dettagli del flusso per Origine Amazon Kinesis nella scheda Proprietà dell'origine dati - Flusso Kinesis.
Seleziona Il flusso si trova nel mio account per Posizione del flusso di dati.
Seleziona la regione che stai utilizzando.
Seleziona il flusso
GlueStreamTest-{AWS::AccountId}.Mantieni tutte le altre impostazioni predefinite.
Vai alla scheda Anteprima dei dati.
Fai clic su Avvia sessione di anteprima dei dati, che visualizza in anteprima i dati fittizi generati da KDG. Scegli il ruolo del servizio Glue che hai creato in precedenza per il lavoro AWS Glue Streaming.
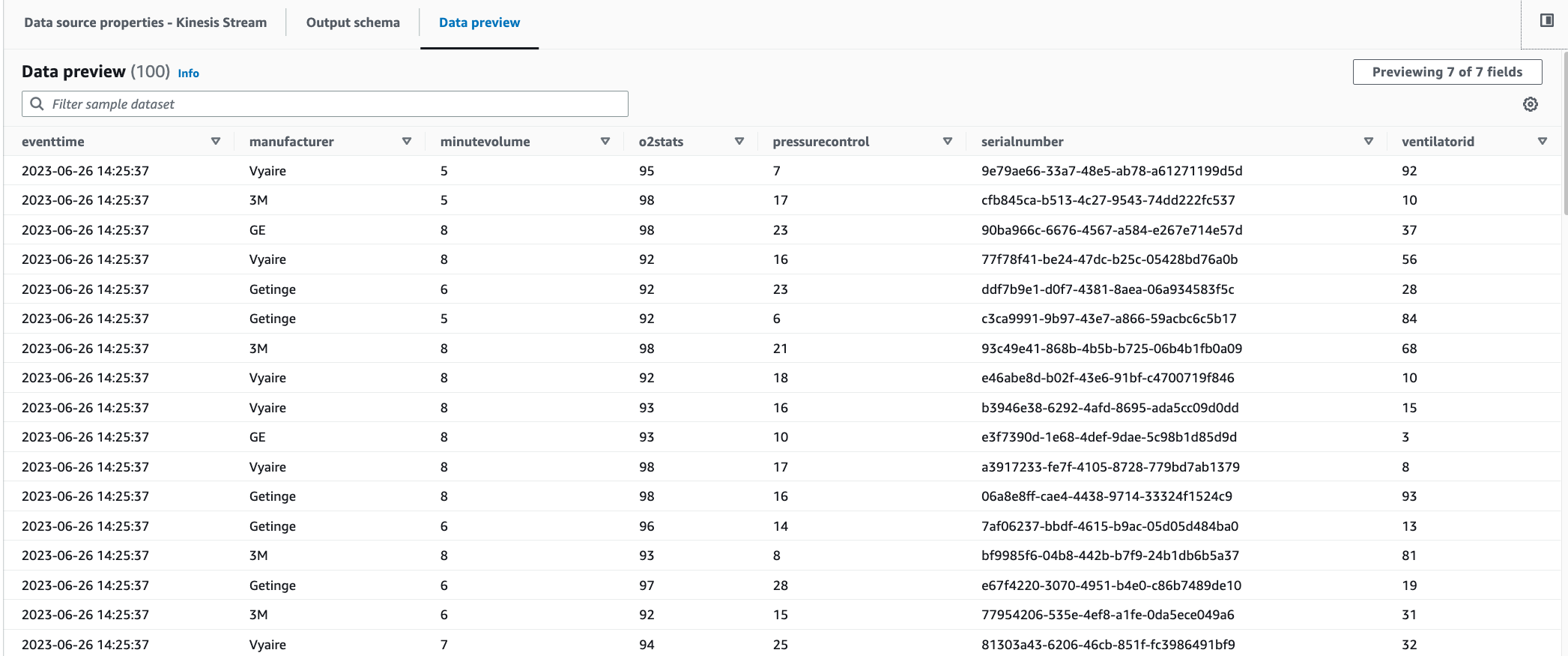
Occorrono 30-60 secondi prima che i dati di anteprima vengano visualizzati. Se compare Nessun dato da visualizzare, fai clic sull'icona a forma di ingranaggio e imposta il Numero di righe in base al quale campionare su
100.Puoi visualizzare i dati di esempio come segue:
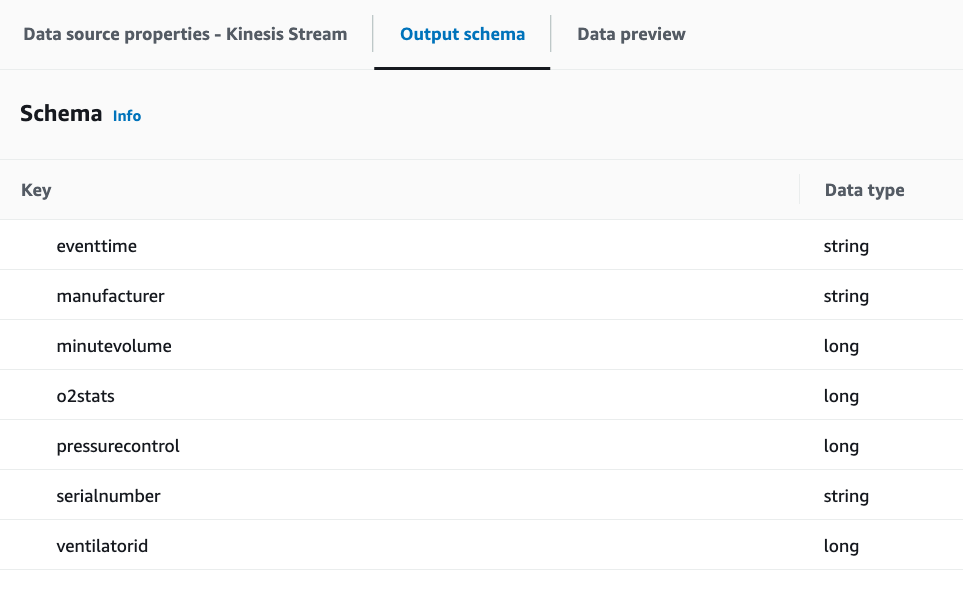
È inoltre possibile visualizzare lo schema dedotto nella scheda Schema di output.
Esecuzione di una trasformazione e archiviazione del risultato della trasformazione in Amazon S3
Con il nodo di origine selezionato, fai clic sull'icona del segno più in alto a sinistra per aggiungere un passaggio Trasformazioni.
Seleziona il passaggio Modifica schema.
In questo passaggio è possibile rinominare i campi e convertire il tipo di dati dei campi. Rinomina la colonna
o2statsinOxygenSaturatione converti tutti i tipi di datilonginint.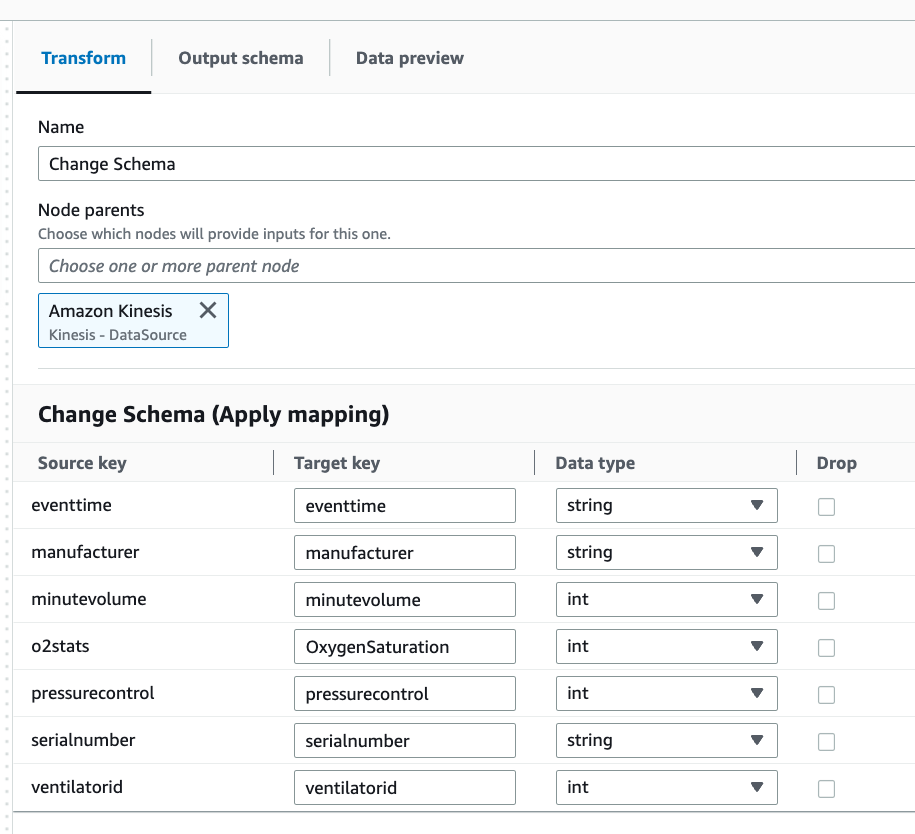
Fai clic sull'icona del segno più per aggiungere una destinazione Amazon S3. Immetti S3 nella casella di ricerca e seleziona la fase di trasformazione di Amazon S3 - Destinazione.
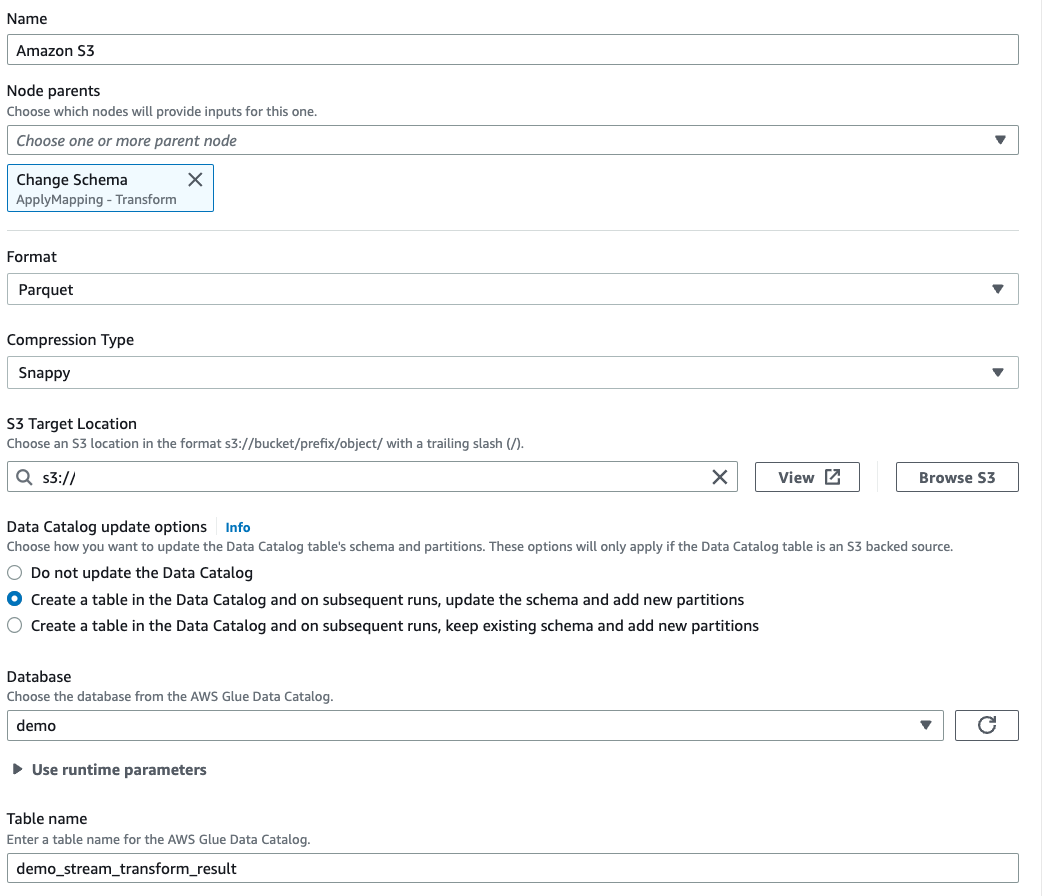
Seleziona Parquet come formato del file di destinazione.
Seleziona Snappy come tipo di compressione.
Inserisci una posizione di destinazione S3 creata dal CloudFormation modello,
streaming-tutorial-s3-target-{AWS::AccountId}.Seleziona Crea una tabella nel Catalogo dati e, nelle esecuzioni successive, aggiorna lo schema e aggiungi nuove partizioni.
Inserisci il nome del Database e della Tabella di destinazione per archiviare lo schema della tabella di destinazione Amazon S3.
Fai clic sulla scheda Script per visualizzare il codice generato.
Fai clic su Salva in alto a destra per salvare il codice ETL, quindi fai clic su Esegui per avviare il processo di streaming. AWS Glue
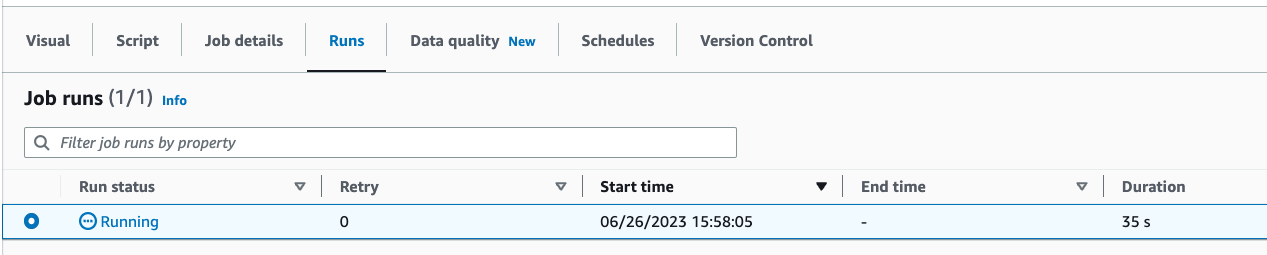
Puoi trovare lo Stato di esecuzione nella scheda Esecuzioni. Lascia che il processo venga eseguito per 3-5 minuti, quindi interrompilo.
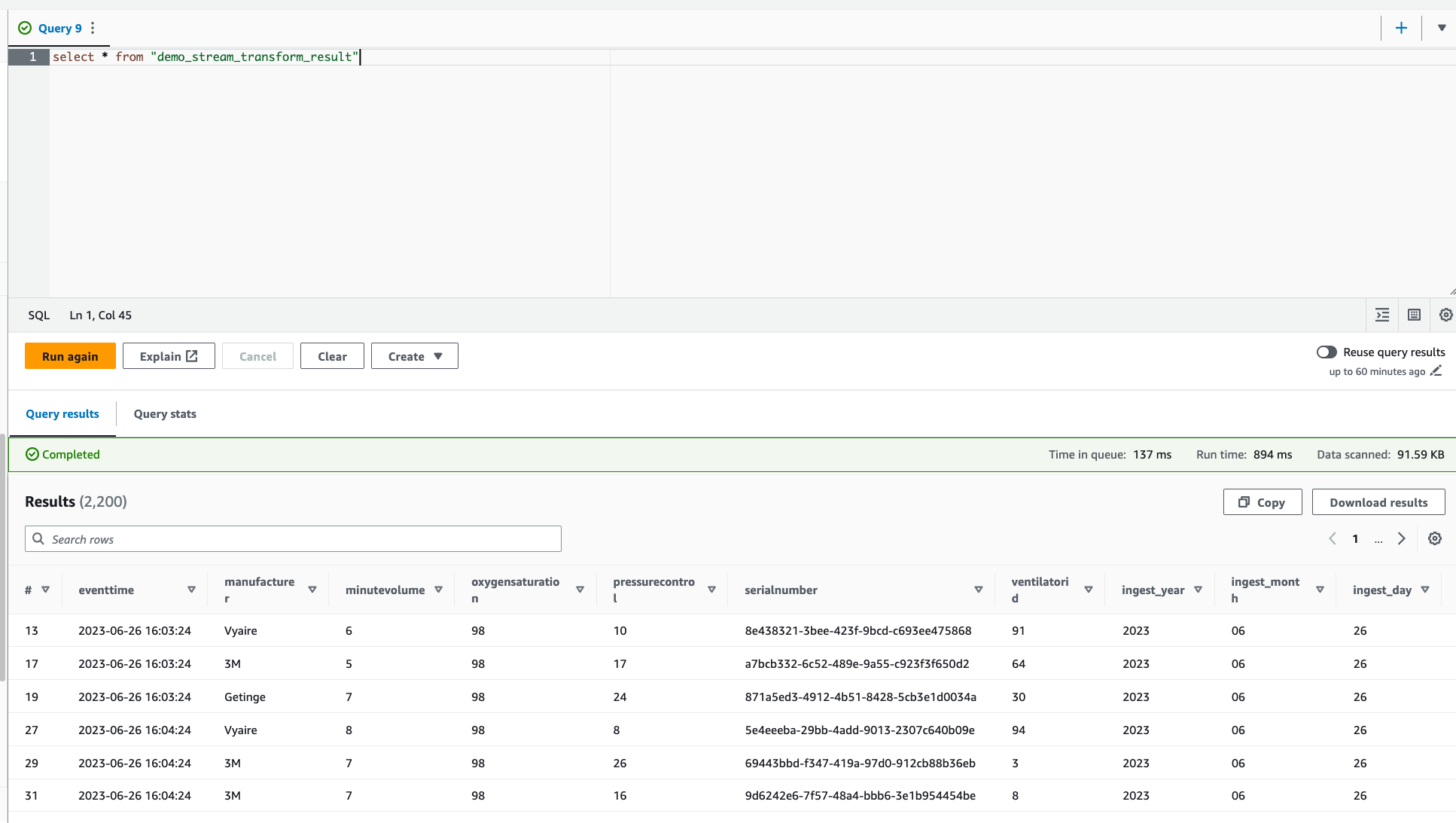
Verifica la nuova tabella creata in Amazon Athena.