Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: crea il tuo primo carico di lavoro in streaming utilizzando i notebook AWS Glue Studio
In questo tutorial, scoprirai come sfruttare i notebook AWS Glue Studio per creare e perfezionare in modo interattivo i tuoi job ETL per un'elaborazione dei dati quasi in tempo reale. Che siate alle prime armi AWS Glue o che vogliate migliorare le vostre competenze, questa guida vi guiderà attraverso il processo, consentendovi di sfruttare tutto il potenziale dei taccuini interattivi con sessioni. AWS Glue
Con AWS Glue Streaming, puoi creare processi di estrazione, trasformazione e caricamento (ETL) in streaming che vengono eseguiti in modo continuo e utilizzano dati da fonti di streaming come Amazon Kinesis Data Streams, Apache Kafka e Amazon Managed Streaming for Apache Kafka (Amazon MSK).
Prerequisiti
Per seguire questo tutorial avrai bisogno di un utente con le autorizzazioni di utilizzo AWS della console, Amazon Kinesis AWS Glue, Amazon S3, Amazon Athena, AWS CloudFormation AWS Lambda e Amazon Cognito.
Utilizzo dei dati in streaming da Amazon Kinesis
Argomenti
Generazione di dati fittizi con Kinesis Data Generator
Nota
Se hai già completato i passaggi del precedente Tutorial: crea il tuo primo carico di lavoro in streaming con Studio AWS Glue e hai già installato Kinesis Data Generator sull'account, puoi saltare i passaggi da 1 a 8 riportati di seguito e andare direttamente alla sezione Creazione di un lavoro AWS Glue in streaming con Studio AWS Glue.
È possibile generare sinteticamente dati di esempio in formato JSON utilizzando Kinesis Data Generator (KDG). Puoi trovare le istruzioni complete e i dettagli nella documentazione dello strumento
Per iniziare, fai clic per eseguire un modello

nel tuo ambiente. AWS CloudFormation AWS Nota
Potresti riscontrare un errore nel CloudFormation modello perché alcune risorse, come l'utente Amazon Cognito per Kinesis Data Generator, esistono già nel tuo account. AWS Ciò potrebbe essere dovuto al fatto che l'hai già configurato in un altro tutorial o da un post di un blog. Per risolvere questo problema, puoi provare il modello in un nuovo AWS account per ricominciare da capo, oppure esplorare un'altra AWS regione. Queste opzioni consentono di eseguire il tutorial senza entrare in conflitto con le risorse esistenti.
Il modello fornisce un flusso di dati Kinesis e un account Kinesis Data Generator.
Immetti un Nome utente e una Password che KDG utilizzerà per l'autenticazione. Prendi nota del nome utente e della password per utilizzarli in seguito.
Seleziona Avanti fino all'ultimo passaggio. Esprimi il consenso alla creazione di risorse IAM. Verifica la presenza di eventuali errori nella parte superiore dello schermo, ad esempio la password che non soddisfa i requisiti minimi, e implementa il modello.
Vai alla scheda Output dello stack. Una volta distribuito, il modello mostrerà la proprietà KinesisDataGeneratorUrlgenerata. Fai clic su quell'URL.
Inserisci il Nome utente e la Password di cui hai preso nota.
Seleziona la regione che stai utilizzando e seleziona il flusso Kinesis
GlueStreamTest-{AWS::AccountId}.Immetti il seguente modello:
{ "ventilatorid": {{random.number(100)}}, "eventtime": "{{date.now("YYYY-MM-DD HH:mm:ss")}}", "serialnumber": "{{random.uuid}}", "pressurecontrol": {{random.number( { "min":5, "max":30 } )}}, "o2stats": {{random.number( { "min":92, "max":98 } )}}, "minutevolume": {{random.number( { "min":5, "max":8 } )}}, "manufacturer": "{{random.arrayElement( ["3M", "GE","Vyaire", "Getinge"] )}}" }Ora puoi visualizzare i dati fittizi con Modello di prova e importare i dati fittizi in Kinesis con Invia dati.
Fai clic su Invia dati e genera 5-10.000 record su Kinesis.
Creazione di un lavoro AWS Glue in streaming con Studio AWS Glue
AWS Glue Studio è un'interfaccia visiva che semplifica il processo di progettazione, orchestrazione e monitoraggio delle pipeline di integrazione dei dati. Consente agli utenti di creare pipeline di trasformazione dei dati senza scrivere codice esteso. Oltre all'esperienza di creazione visiva dei lavori, AWS Glue Studio include anche un notebook Jupyter supportato da sessioni AWS Glue interattive, che utilizzerai nel resto di questo tutorial.
Configura il processo di streaming delle sessioni interattive AWS Glue
Scarica il file del notebook
fornito e salvalo in una directory locale Apri la AWS Glue console e nel riquadro sinistro fai clic su Notebooks > Jupyter Notebook > Carica e modifica un taccuino esistente. Carica il notebook dal passaggio precedente e fai clic su Crea.
Fornisci un nome e un ruolo per il processo e seleziona il kernel Spark predefinito. Quindi fai clic su Avvia notebook. Per il ruolo IAM, seleziona il ruolo assegnato dal modello. CloudFormation Puoi vederlo nella scheda Output di. CloudFormation
Il notebook contiene tutte le istruzioni necessarie per continuare il tutorial. Puoi eseguire le istruzioni sul notebook o seguire questo tutorial per continuare con lo sviluppo del processo.
Esecuzione delle celle del notebook
(Facoltativo) La prima cella di codice,
%help, elenca tutte le funzioni magic disponibili per il notebook. Per ora puoi saltare questa cella, ma se desideri puoi esplorarla.Inizia con il blocco di codice successivo,
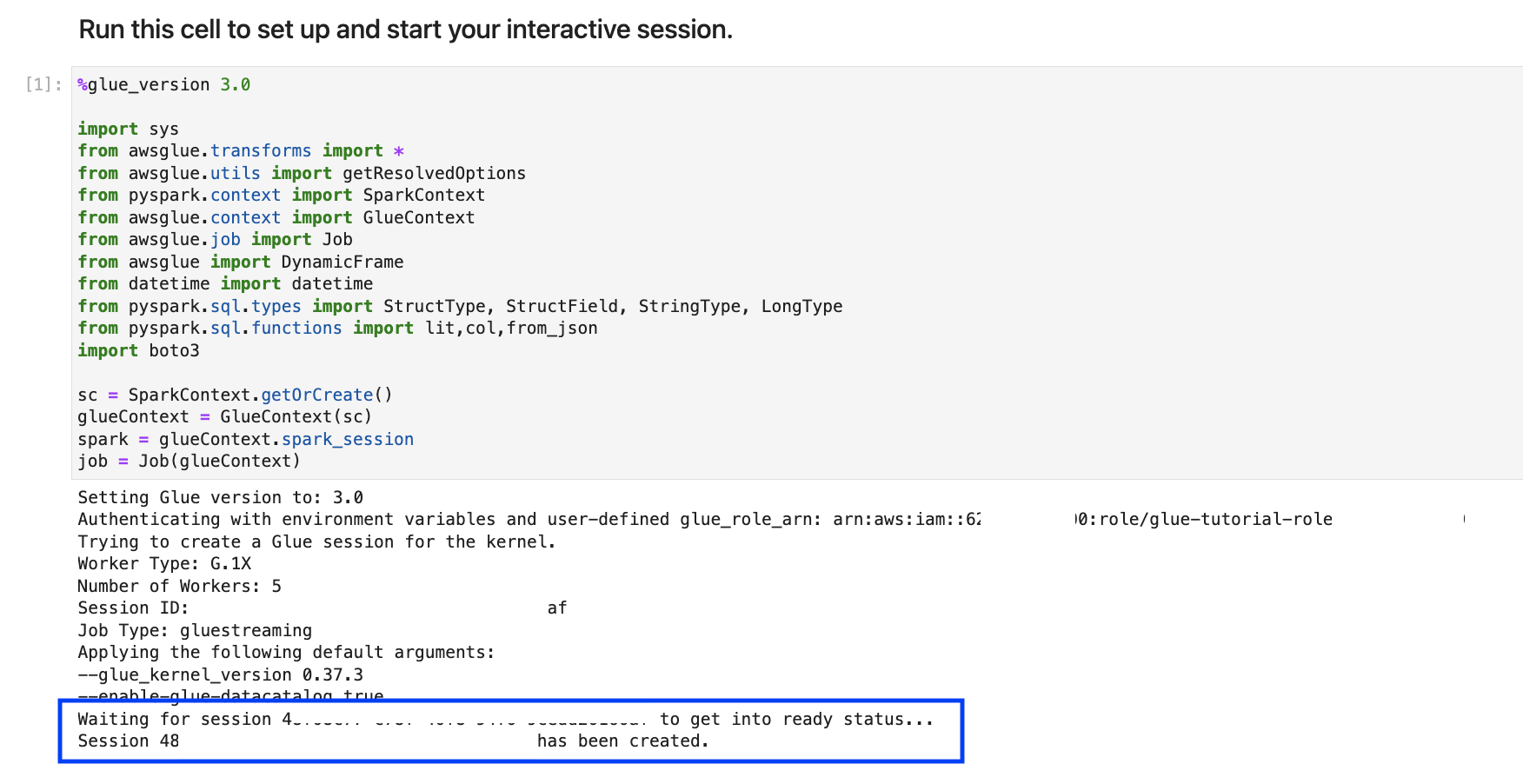
%streaming. Questa magia imposta il tipo di lavoro sullo streaming, che consente di sviluppare, eseguire il debug e distribuire un lavoro ETL AWS Glue in streaming.Esegui la cella successiva per creare una AWS Glue sessione interattiva. La cella di output contiene un messaggio che conferma la creazione della sessione.
La cella successiva definisce le variabili. Sostituisci i valori con quelli appropriati per il tuo processo ed esegui la cella. Esempio:

Poiché i dati vengono già trasmessi in streaming a Flussi di dati Kinesis, la cella successiva utilizzerà i risultati del flusso. Esegui la cella successiva. Poiché non ci sono istruzioni di stampa, non è previsto alcun output per questa cella.
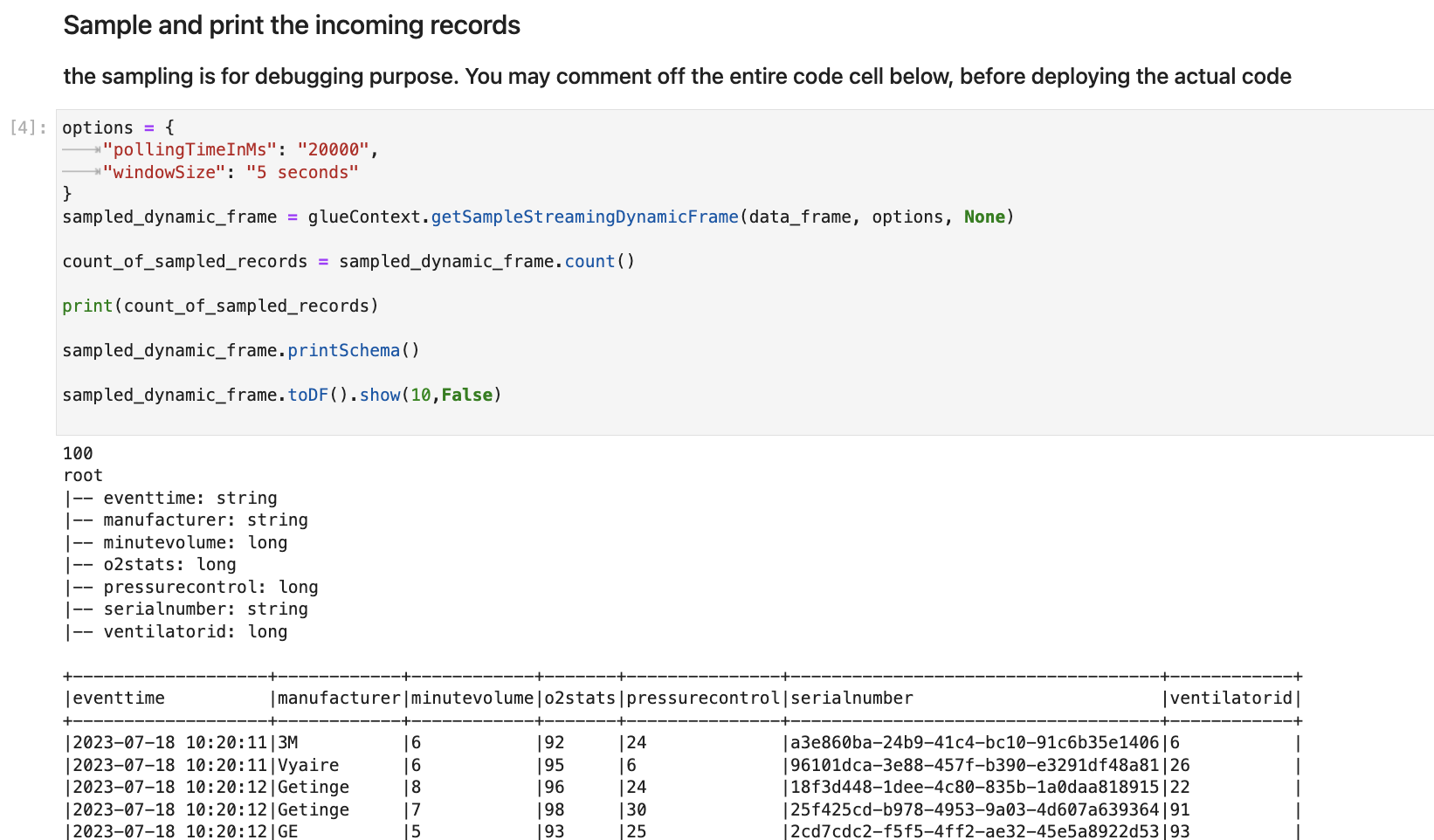
Nella cella seguente, esplori il flusso in entrata prelevando un set di esempio e stampandone lo schema e i dati effettivi. Esempio:
Successivamente, definisci la logica di trasformazione dei dati effettiva. La cella è costituita dal metodo
processBatchche viene attivato durante ogni microbatch. Esegui la cella. Ad alto livello, eseguiamo le operazioni seguenti per il flusso in entrata:Seleziona un sottoinsieme delle colonne di input.
Rinomina una colonna (o2stats in oxygen_stats).
Ricava nuove colonne (serial_identifier, ingest_year, ingest_month e ingest_day).
Archivia i risultati in un bucket Amazon S3 e crea anche una tabella di catalogo partizionata AWS Glue
Nell'ultima cella, il batch di processo si attiva ogni 10 secondi. Esegui la cella e attendi circa 30 secondi affinché compili il bucket Amazon S3 e AWS Glue la tabella del catalogo.
Infine, esplora i dati archiviati utilizzando l'editor di query di Amazon Athena. Puoi visualizzare la colonna rinominata e le nuove partizioni.
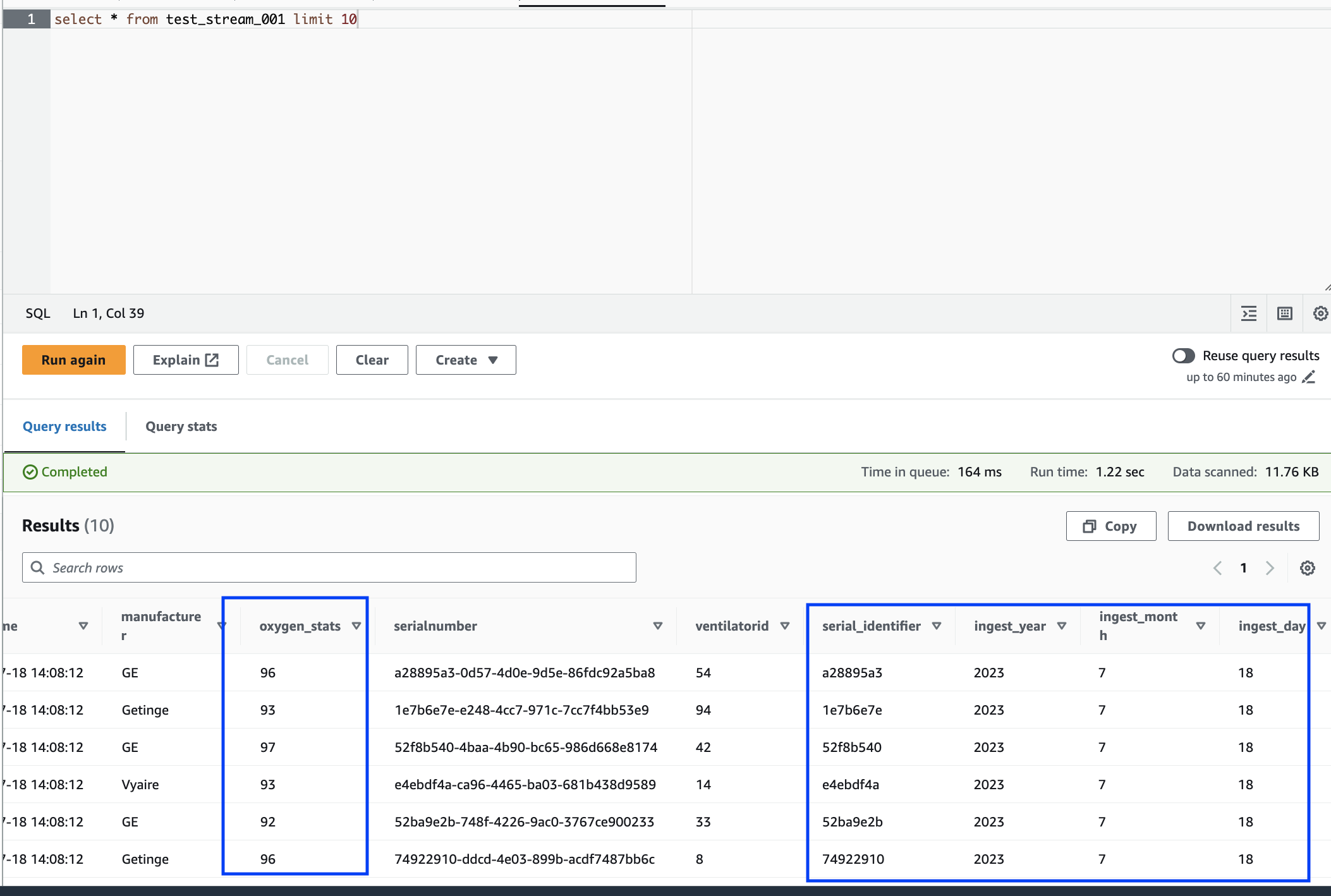
Il notebook contiene tutte le istruzioni necessarie per continuare il tutorial. Puoi eseguire le istruzioni sul notebook o seguire questo tutorial per continuare con lo sviluppo del processo.
Salva ed esegui il lavoro AWS Glue
Una volta completato lo sviluppo e il test dell'applicazione utilizzando il notebook delle sessioni interattive, fai clic su Salva nella parte superiore dell'interfaccia del notebook. Una volta salvata l'applicazione, puoi anche eseguirla come processo.

Eliminazione
Per evitare addebiti aggiuntivi sul tuo account, interrompi il processo di streaming che hai avviato seguendo le istruzioni. Puoi farlo arrestando il notebook, operazione che termina la sessione. Svuota il bucket Amazon S3 ed elimina lo AWS CloudFormation stack che hai fornito in precedenza.
Conclusioni
In questo tutorial, abbiamo dimostrato come eseguire le seguenti operazioni utilizzando il notebook Studio AWS Glue
Creazione di un processo di ETL in streaming utilizzando i notebook
Visualizzazione in anteprima dei flussi di dati in entrata
Codifica e risolvi i problemi senza dover pubblicare AWS Glue lavori
Esamina il codice end-to-end funzionante, rimuovi eventuali errori di debug e stampa le istruzioni o le celle dal taccuino
Pubblica il codice come lavoro AWS Glue
L'obiettivo di questo tutorial è darti un'esperienza pratica di lavoro con AWS Glue lo streaming e le sessioni interattive. Ti invitiamo a utilizzarlo come riferimento per i tuoi casi d'uso individuali di AWS Glue Streaming. Per ulteriori informazioni, consulta Nozioni di base sulle sessioni interattive AWS Glue.
