Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Per consentire al crawler di accedere a un datastore in un account diverso utilizzando le credenziali di Lake Formation, è necessario prima registrare la posizione dei dati di Amazon S3 con Lake Formation. Quindi, concedi le autorizzazioni per la posizione dei dati all'account del crawler eseguendo la procedura seguente.
È possibile completare i seguenti passaggi utilizzando AWS Management Console o AWS CLI.
Nell'account in cui è registrata la posizione Amazon S3 (account B):
-
Registra un percorso Amazon S3 con Lake Formation. Per ulteriori informazioni, consulta la pagina Registrazione della posizione Amazon S3.
-
Concedi le autorizzazioni per la posizione dei dati all'account (A) in cui verrà eseguito il crawler. Per ulteriori informazioni, consulta la pagina Concessione delle autorizzazioni per la posizione dei dati.
-
Crea un database vuoto in Lake Formation con la posizione sottostante come posizione Amazon S3 di destinazione. Per ulteriori informazioni, consulta la pagina Creazione di un database.
-
Concedi l'accesso al database all'account A (l'account in cui verrà eseguito il crawler) creato nel passaggio precedente. Per ulteriori informazioni, consulta la pagina Concessione delle autorizzazioni al database.
-
-
Nell'account in cui è stato creato e verrà eseguito il crawler (account A):
-
Utilizzando la AWS RAM console, accetta il database che è stato condiviso dall'account esterno (account B). Per ulteriori informazioni, consulta Accettazione di un invito alla condivisione di risorse da AWS Resource Access Manager.
-
Crea un ruolo IAM per il crawler. Aggiungi la policy
lakeformation:GetDataAccessal ruolo. -
Nella console di Lake Formation (https://console.aws.amazon.com/lakeformation/
), concedi le autorizzazioni di Data Location (Posizione dei dati) nella posizione Amazon S3 di destinazione al ruolo IAM utilizzato per l'esecuzione del crawler, in modo che quest'ultimo possa leggere i dati dalla destinazione in Lake Formation. Per ulteriori informazioni, consulta la pagina Concessione delle autorizzazioni per la posizione dei dati. -
Crea un collegamento alla risorsa nel database condiviso. Per ulteriori informazioni, consulta la pagina Creare un collegamento alla risorsa.
-
Concessione al ruolo crawler delle autorizzazioni di accesso (
Create) sul database condiviso e (Describe) sul collegamento alla risorsa. Il collegamento alla risorsa è specificato nell'output del crawler. -
Nella AWS Glue console (https://console.aws.amazon.com/glue/
), durante la configurazione del crawler, seleziona l'opzione Usa le credenziali di Lake Formation per la scansione dell'origine dati Amazon S3. Per la scansione tra più account, specifica l' Account AWS ID in cui è registrata la sede Amazon S3 di destinazione con Lake Formation. Per il crawling all'interno dell'account, il campo accountId è facoltativo.
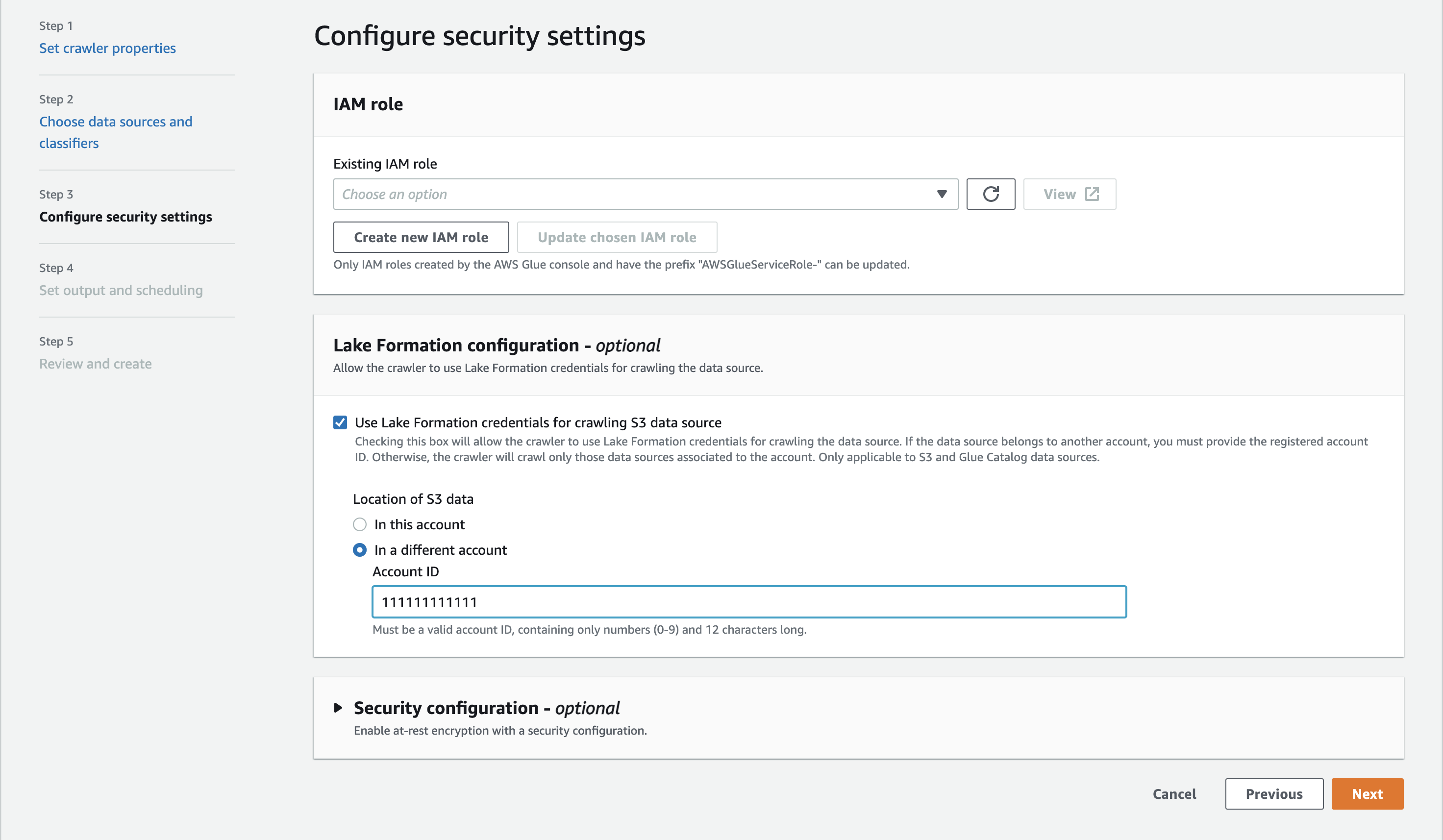
-
Nota
Un crawler che utilizza le credenziali Lake Formation è supportato solo per le destinazioni Amazon S3 e Catalogo dati.
Per le destinazioni che utilizzano la distribuzione delle credenziali Lake Formation, le posizioni Amazon S3 sottostanti devono appartenere allo stesso bucket. Ad esempio, gli utenti possono utilizzare più destinazioni (s3://bucket1/folder1, s3://bucket1/folder2) purché tutte le posizioni di destinazione si trovino nello stesso bucket (bucket1). Non è consentito specificare bucket diversi (s3://bucket1/folder1, s3://bucket2/folder2).
Per i crawler di destinazione del catalogo dati è attualmente consentita solo una singola destinazione del catalogo per una singola tabella.
