Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Auto Scaling è disponibile per AWS Glue ETL, sessioni interattive e lavori in streaming con AWS Glue versione 3.0 o successiva.
Con Auto Scaling abilitato, otterrai i seguenti vantaggi:
-
AWS Glue aggiunge e rimuove automaticamente i lavoratori dal cluster in base al parallelismo in ogni fase o microbatch dell'esecuzione del lavoro.
-
Riduce la necessità di sperimentare e decidere il numero di lavoratori da assegnare al AWS Glue Offerte di lavoro ETL.
-
Con il numero massimo di lavoratori indicato, AWS Glue sceglierà le risorse della dimensione giusta per il carico di lavoro.
-
Puoi vedere come cambia la dimensione del cluster durante l'esecuzione del job consultando le CloudWatch metriche nella pagina dei dettagli dell'esecuzione del job in AWS Glue Studio.
Auto Scaling per AWS Glue ETL e streaming Jobs consentono la scalabilità orizzontale e orizzontale su richiesta delle risorse informatiche del AWS Glue lavori. Il dimensionamento verticale on demand consente di allocare solo le risorse di calcolo richieste inizialmente all'avvio dell'esecuzione del processo e anche di effettuare il provisioning delle risorse richieste in base alla domanda durante il processo.
Auto Scaling supporta anche la scalabilità dinamica di AWS Glue risorse di lavoro nel corso di un lavoro. Durante l'esecuzione di un processo, quando vengono richiesti più esecutori dall'applicazione Spark, verrà aggiunto al cluster un numero maggiore di dipendenti. Quando l'esecutore sarà inattivo e non avrà attività di calcolo in corso, l'esecutore e il dipendente corrispondente verranno rimossi.
Gli scenari comuni in cui Auto Scaling aiuta a ridurre i costi e l'utilizzo delle applicazioni Spark includono:
-
un driver Spark che elenca un gran numero di file in Amazon S3 o esegue un caricamento mentre gli executor sono inattivi
-
Spark inizia a funzionare con pochi esecutori a causa dell'over-provisioning
-
distorsioni dei dati o domanda di calcolo non uniforme tra le varie fasi di Spark
Requisiti
Auto Scaling è disponibile solo per AWS Glue versione 3.0 o successiva. Per utilizzare Auto Scaling, puoi seguire la guida alla migrazione per migrare i lavori esistenti su AWS Glue versione 3.0 o successiva o creare nuovi lavori con AWS Glue versione 3.0 o successiva.
Auto Scaling è disponibile per AWS Glue lavori con i tipi di lavoratore G.1X G.2XG.4X,G.8X,, o G.025X (solo per i lavori in streaming). DPUs Gli standard non sono supportati.
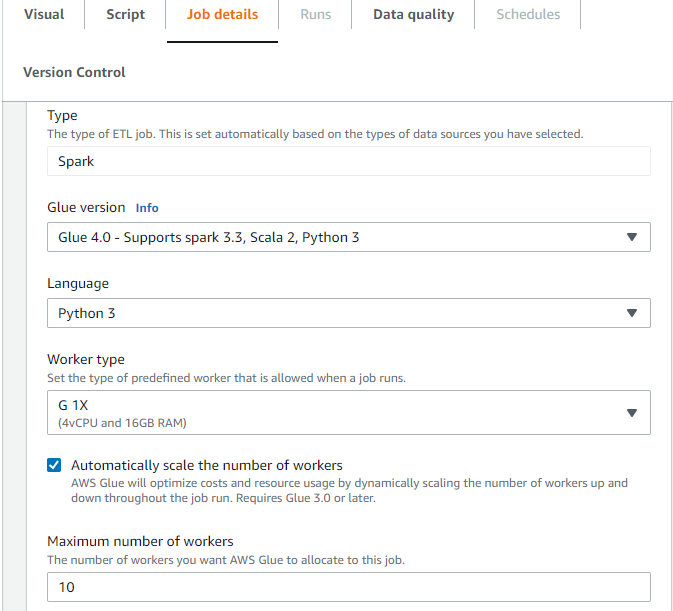
Attivazione dell'Auto Scaling in AWS Glue Studio
Nella scheda Dettagli del lavoro in AWS Glue Studio, scegli il tipo come Spark o Spark Streaming e la versione Glue uguale Glue 3.0 o successiva. Quindi, verrà visualizzata una casella di controllo sotto il tipo di lavoratore.
-
Seleziona l'opzione Dimensiona automaticamente il numero di worker.
-
Imposta la proprietà Numero massimo di dipendenti per definire il numero massimo di dipendenti che possono essere ceduti all'esecuzione del processo.
Abilitazione dell'Auto Scaling con CLI o SDK AWS
Per abilitare l'Auto Scaling dalla AWS CLI per l'esecuzione del processo, esegui start-job-run con la seguente configurazione:
{
"JobName": "<your job name>",
"Arguments": {
"--enable-auto-scaling": "true"
},
"WorkerType": "G.2X", // G.1X and G.2X are allowed for Auto Scaling Jobs
"NumberOfWorkers": 20, // represents Maximum number of workers
...other job run configurations...
}Una volta terminata l'esecuzione del processo ETL, puoi anche chiamareget-job-run per verificare l'effettivo utilizzo delle risorse del processo eseguito in secondi DPU. Nota: il nuovo campo DPUSecondsverrà visualizzato solo per i lavori in batch nella AWS Glue versione 4.0 o successiva abilitata con Auto Scaling. Questo campo non è supportato per i processi di streaming.
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1
{
"JobRun": {
...
"GlueVersion": "3.0",
"DPUSeconds": 386.0
}
}È inoltre possibile configurare le esecuzioni dei processi con Auto Scaling utilizzando l'SDK AWS Glue con la stessa configurazione.
Attivazione dell'Auto Scaling con sessioni interattive
Per abilitare l'Auto Scaling durante la creazione di AWS Glue lavori con sessioni interattive, consulta Configurazione delle AWS Glue sessioni interattive.
Suggerimenti e considerazioni
Suggerimenti e considerazioni per la messa a punto dell'Auto Scaling AWS Glue :
-
Se non hai idea del valore iniziale del numero massimo di lavoratori, puoi iniziare dal calcolo approssimativo spiegato in Estimate DPU. AWS Glue Non è necessario configurare un valore estremamente elevato nel numero massimo di lavoratori per dati di volume molto basso.
-
AWS Glue Auto Scaling si configura
spark.sql.shuffle.partitionsespark.default.parallelismsi basa sul numero massimo di DPU (calcolato con il numero massimo di lavoratori e il tipo di lavoratore) configurato sul lavoro. Nel caso in cui si preferisca il valore fisso su tali configurazioni, è possibile sovrascrivere questi parametri con i seguenti parametri di lavoro:-
Chiave:
--conf -
Value (Valore):
spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200
-
-
Per i lavori di streaming, per impostazione predefinita, AWS Glue non esegue la scalabilità automatica all'interno di microbatch e richiede diversi micro batch per avviare la scalabilità automatica. Nel caso in cui desideri abilitare la scalabilità automatica all'interno di micro batch, fornisci.
--auto-scale-within-microbatchPer ulteriori informazioni, vedere Riferimento ai parametri Job.
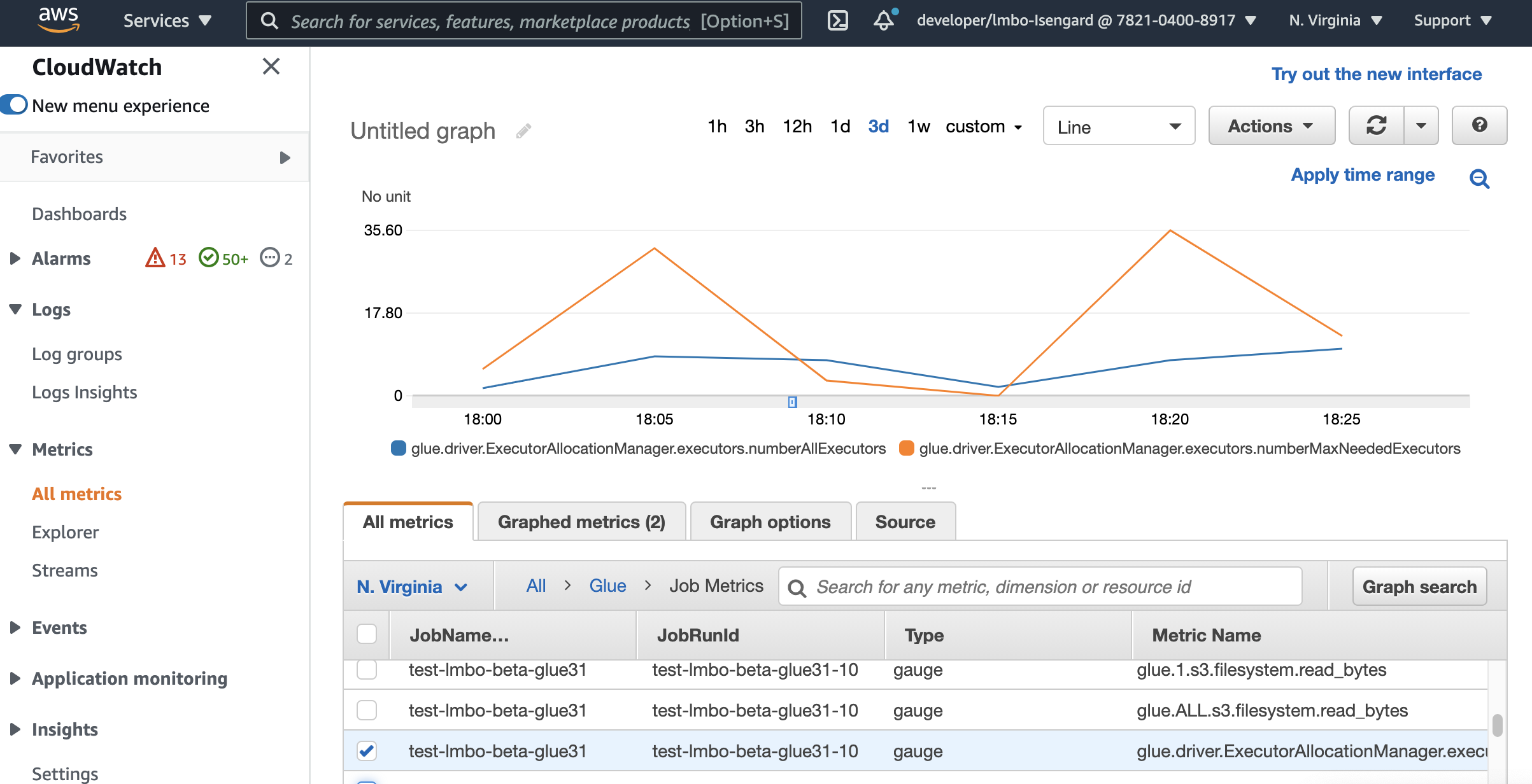
Monitoraggio dell'Auto Scaling con i parametri di Amazon CloudWatch
Le metriche degli CloudWatch esecutori sono disponibili per AWS Glue Lavori 3.0 o versioni successive se si abilita Auto Scaling. I parametri possono essere impiegati per monitorare la domanda e l'utilizzo ottimizzato degli esecutori nelle applicazioni Spark abilitate con Auto Scaling. Per ulteriori informazioni, consulta Monitoraggio AWS Glue utilizzo dei CloudWatch parametri di Amazon.
Puoi anche utilizzare metriche di AWS Glue osservabilità per ottenere informazioni sull'utilizzo delle risorse. Ad esempio, tramite il monitoraggioglue.driver.workerUtilization, è possibile monitorare la quantità di risorse effettivamente utilizzate con e senza la scalabilità automatica. Un altro esempio, monitorando glue.driver.skewness.job eglue.driver.skewness.stage, è possibile vedere come i dati sono distorti. Queste informazioni ti aiuteranno a decidere di abilitare la scalabilità automatica e ottimizzare le configurazioni. Per ulteriori informazioni, consulta Monitoraggio con. Monitoraggio con AWS Glue Parametri di osservabilità
-
glue.driver. ExecutorAllocationManager.esecutori. numberAllExecutors
-
colla.driver. ExecutorAllocationManager.esecutori. numberMaxNeededEsecutori
Per ulteriori dettagli su questi parametri, consulta Monitoraggio per la pianificazione della capacità DPU.
Nota
CloudWatch le metriche degli esecutori non sono disponibili per le sessioni interattive.
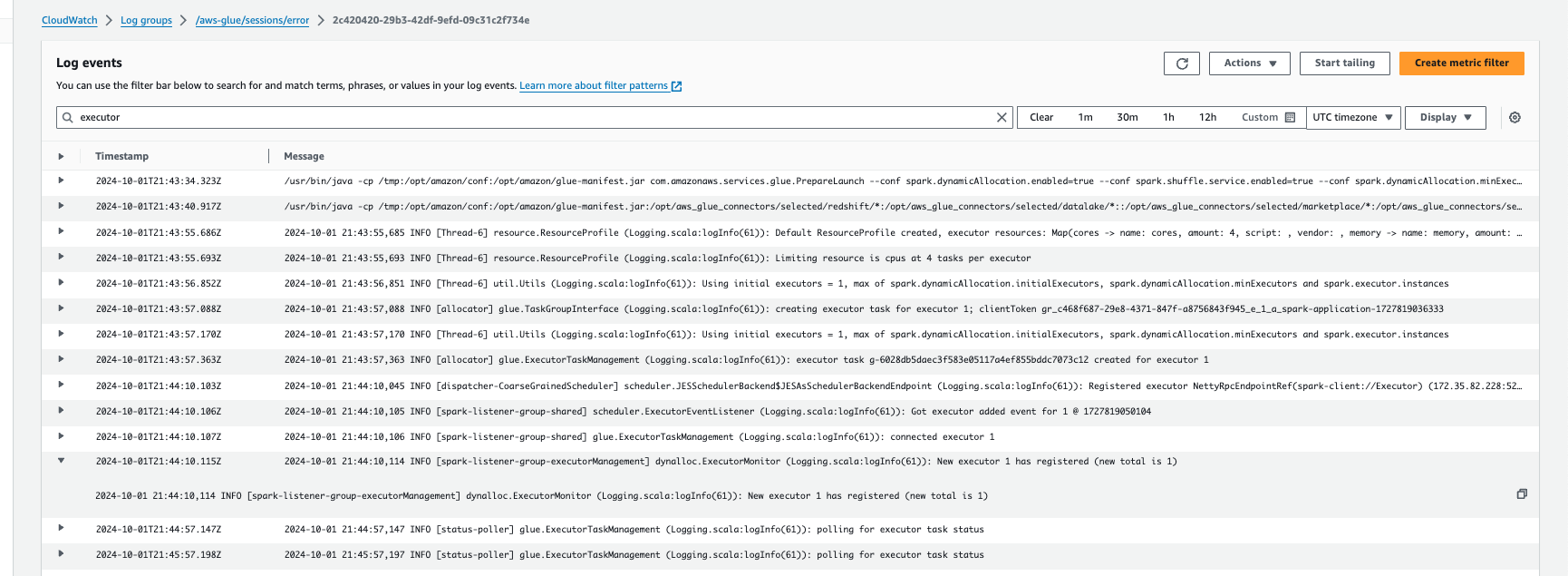
Monitoraggio dell'Auto Scaling con Amazon Logs CloudWatch
Se utilizzi sessioni interattive, puoi monitorare il numero di executor abilitando Amazon CloudWatch Logs continui e cercando «executor» nei log o utilizzando l'interfaccia utente Spark. Per fare ciò, usa la %%configure magia di abilitare la registrazione continua insieme a. enable auto scaling
%%configure{
"--enable-continuous-cloudwatch-log": "true",
"--enable-auto-scaling": "true"
}Negli CloudWatch eventi di Amazon Logs, cerca «executor» nei log:
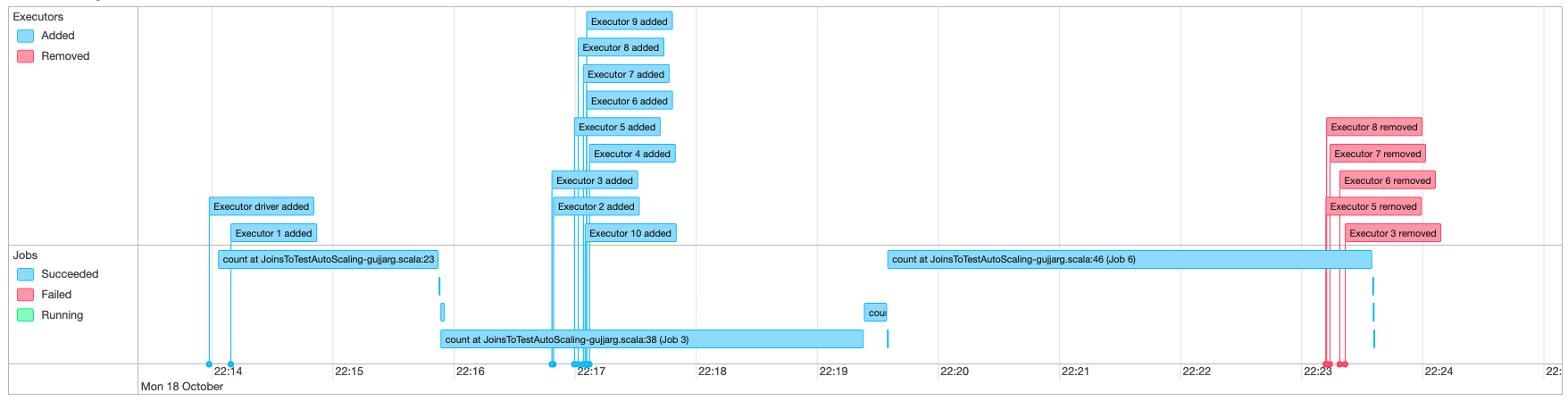
Monitoraggio di Auto Scaling con interfaccia utente di Spark
Con Auto Scaling abilitato, puoi anche monitorare gli esecutori aggiunti e rimossi con scalabilità dinamica verso l'alto e verso il basso in base alla domanda del tuo AWS Glue lavori che utilizzano l'interfaccia utente di Glue Spark. Per ulteriori informazioni, consulta Abilitazione dell'interfaccia utente web di Apache Spark per AWS Glue jobs.
Quando utilizzi sessioni interattive dal notebook Jupyter, puoi eseguire la seguente magia per abilitare la scalabilità automatica insieme all'interfaccia utente Spark:
%%configure{
"--enable-auto-scaling": "true",
"--enable-continuous-cloudwatch-log": "true"
}
Monitoraggio dell'utilizzo della DPU di esecuzione del processo Auto Scaling
È possibile utilizzare la Vista esecuzione dei processi AWS Glue Studio per controllare l'utilizzo della DPU da parte dei processi di dimensionamento automatico.
-
Scegli Monitoraggio dal pannello di navigazione. AWS Glue Studio Viene visualizzata la pagina Monitoraggio.
-
Scorri in basso fino all'elenco Job runs (Esecuzioni processo).
-
Passa all'esecuzione del processo che ti interessa e scorri fino alla colonna ore DPU per verificare l'utilizzo per l'esecuzione specifica del processo.
Limitazioni
AWS Glue Lo streaming Auto Scaling attualmente non supporta un DataFrame join in streaming con un elemento statico DataFrame creato all'esterno di. ForEachBatch Una statica DataFrame creata all'interno di ForEachBatch funzionerà come previsto.
