Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Quando crei o modifichi un processo, AWS Glue Studio aggiunge automaticamente le librerie Hudi corrispondenti a seconda della versione di AWS Glue che stai utilizzando. Per ulteriori informazioni, consulta Utilizzo del framework di Hudi in AWS Glue.
Utilizzo del framework di Apache Hudi nelle origini dati del catalogo dati
Per aggiungere un formato di origine dati di Hudi a un processo:
-
Dal menu Origine, scegli Catalogo dati AWS Glue Studio.
-
Nella scheda Proprietà dell'origine dati, scegli un database e una tabella.
-
AWS Glue Studio mostra il tipo di formato come Apache Hudi e l'URL di Amazon S3.

Utilizzo del framework di Hudi nelle origini dati di Amazon S3
-
Dal menu Origine, scegli Amazon S3.
-
Se scegli la tabella del catalogo dati come tipo di origine di Amazon S3, scegli un database e una tabella.
-
AWS Glue Studio mostra il formato come Apache Hudi e l'URL di Amazon S3.
-
Se scegli la posizione Amazon S3 come tipo di origine Amazon S3, scegli l'URL di Amazon S3 facendo clic su Sfoglia Amazon S3.
-
In Formato dati, seleziona Apache Hudi.
Nota
Se AWS Glue Studio non riesce a inferire lo schema dalla cartella o dal file Amazon S3 che hai selezionato, scegli Opzioni aggiuntive per selezionare una nuova cartella o un nuovo file.
In Opzioni aggiuntive, scegli tra le seguenti opzioni in Inferenza dello schema:
-
Lascia che AWS Glue Studio scelga automaticamente un file di esempio: AWS Glue Studio sceglierà un file di esempio nella posizione di Amazon S3 in modo da poter inferire lo schema. Nel campo File con campionatura automatica, puoi visualizzare il file che è stato selezionato automaticamente.
-
Scegli un file di esempio da Amazon S3: scegli il file Amazon S3 da utilizzare facendo clic su Sfoglia Amazon S3.
-
-
Fai clic su Inferisci schema. A questo punto potrai visualizzare lo schema di output facendo clic sulla scheda Schema di output.
-
Scegli Opzioni aggiuntive per inserire una coppia chiave-valore.

Utilizzo del framework di Apache Hudi nelle destinazioni dei dati
Utilizzo del framework di Apache Hudi nelle destinazioni dei dati del catalogo dati
-
Dal menu Destinazione, scegli Catalogo dati AWS Glue Studio.
-
Nella scheda Proprietà dell'origine dati, scegli un database e una tabella.
-
AWS Glue Studio mostra il tipo di formato come Apache Hudi e l'URL di Amazon S3.
Utilizzo del framework di Apache Hudi nelle destinazioni dei dati di Amazon S3
Inserisci valori o scegli tra le opzioni disponibili per configurare il formato di Apache Hudi. Per ulteriori informazioni su Apache Hudi, consulta la documentazione di Apache Hudi
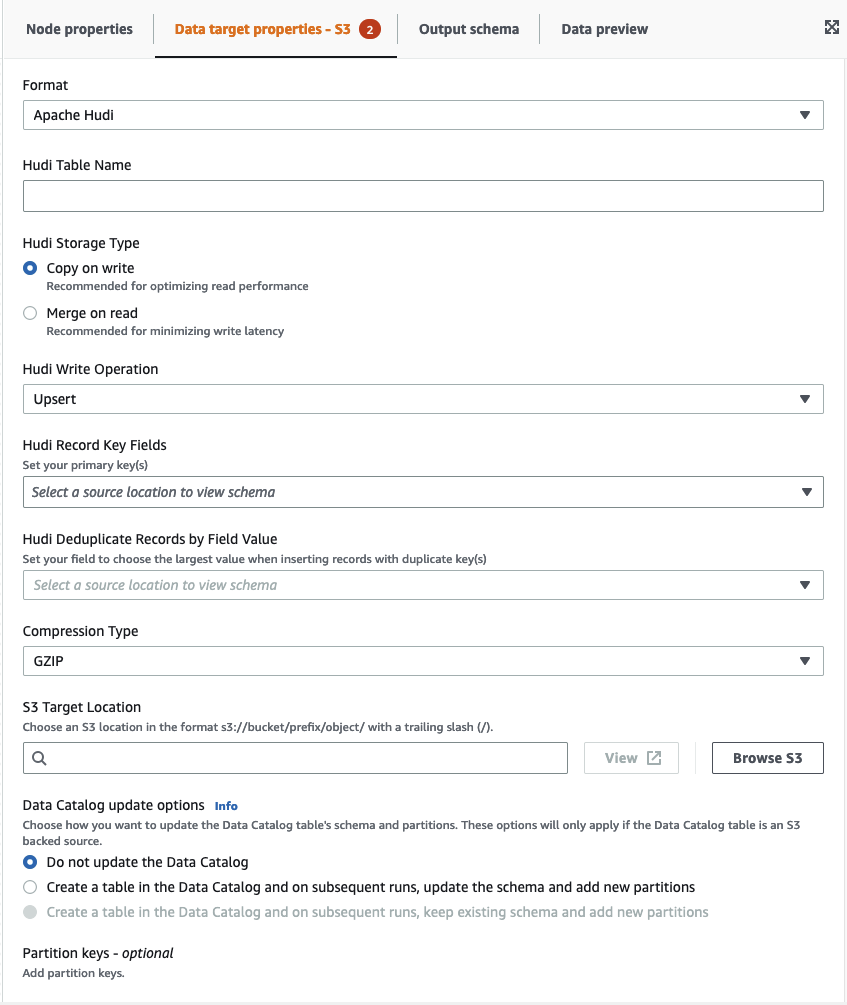
-
Nome tabella Hudi: questo è il nome della tua tabella Hudi.
-
Tipo di archiviazione Hudi - scegli tra due opzioni:
-
Copia in scrittura: consigliata per ottimizzare le prestazioni di lettura. È il tipo di archiviazione di Hudi predefinito. Ogni aggiornamento crea una nuova versione dei file durante una scrittura.
-
Unisci in lettura: consigliata per ridurre al minimo la latenza di scrittura. Gli aggiornamenti vengono registrati nei file delta basati su righe e vengono compattati come necessario per creare nuove versioni dei file colonnari.
-
-
Operazione di scrittura di Hudi - scegli una delle seguenti opzioni:
-
Upsert: questa è l'operazione predefinita in cui i record di input vengono prima contrassegnati come inserimenti o aggiornamenti cercando l'indice. Consigliata laddove stai aggiornando dati esistenti.
-
Inserimento: inserisce i record ma non verifica i record esistenti e può generare duplicati.
-
Inserimento in blocco: consente di inserire record ed è consigliato per grandi quantità di dati.
-
-
Campi chiave record Hudi: utilizza la barra di ricerca per cercare e scegliere le chiavi record primarie. I record in Hudi sono identificati da una chiave primaria che è una coppia composta da chiave di record e percorso di partizione a cui appartiene il record.
-
Campo di precombinazione Hudi: questo è il campo utilizzato in "preCombining" prima della scrittura effettiva. Quando due record hanno lo stesso valore chiave, AWS Glue Studio seleziona quello con il valore più grande per il campo di precombinazione. Imposta un campo con valore incrementale (ad esempio updated_at) a cui appartiene.
-
Tipo di compressione: scegli una delle opzioni per il tipo di compressione: Uncompressed, GZIP, LZO o Snappy.
-
Posizione di destinazione di Amazon S3: scegli la posizione di destinazione di Amazon S3 facendo clic su Sfoglia S3.
-
Opzioni di aggiornamento del catalogo dati - scegli una delle seguenti opzioni:
-
Do not update the Data Catalog (Non aggiornare il catalogo dati): (impostazione predefinita) scegli questa opzione se non vuoi che il processo aggiorni il catalogo dati, anche se lo schema viene modificato o sono aggiunte nuove partizioni.
-
Crea una tabella nel catalogo dati e, nelle esecuzioni successive, aggiorna lo schema e aggiungi nuove partizioni: se scegli questa opzione, il processo crea la tabella nel catalogo dati alla prima esecuzione. Nelle successive esecuzioni del processo, questo aggiorna la tabella del catalogo dati se lo schema viene modificato o sono aggiunte nuove partizioni.
Devi inoltre selezionare un database dal catalogo dati e inserire un nome di tabella.
-
Create a table in the Data Catalog and on subsequent runs, keep existing schema and add new partitions (Crea una tabella nel catalogo dati e, nelle esecuzioni successive, mantieni lo schema esistente e aggiungi nuove partizioni): se scegli questa opzione, il processo crea la tabella nel catalogo dati alla prima esecuzione. Nelle successive esecuzioni del processo, questo aggiorna la tabella del catalogo dati solo per aggiungere nuove partizioni.
Devi inoltre selezionare un database dal catalogo dati e inserire un nome di tabella.
-
-
Partition keys (Chiavi di partizione): scegli quali colonne utilizzare come chiavi di partizionamento nell'output. Per aggiungere altre chiavi di partizione, scegli Add a partition key (Aggiungi una chiave di partizione).
-
Opzioni aggiuntive: inserisci una coppia chiave-valore, se necessario.
Generazione di codice tramite AWS Glue Studio
Quando il processo viene salvato, i seguenti parametri di processo vengono aggiunti al processo se viene rilevata un'origine o una destinazione Hudi:
-
--datalake-formats: un elenco distinto di formati di data lake rilevati nel processo visivo (direttamente scegliendo un "Formato" o indirettamente selezionando una tabella di catalogo supportata da un data lake). -
--conf: generato in base al valore di--datalake-formats. Ad esempio, se il valore per--datalake-formatsè "hudi", AWS Glue genera un valore dispark.serializer=org.apache.spark.serializer.KryoSerializer —conf spark.sql.hive.convertMetastoreParquet=falseper questo parametro.
Sostituzione delle librerie fornite da AWS Glue
Per utilizzare una versione di Hudi che AWS Glue non supporta, puoi specificare i tuoi file JAR della libreria di Hudi. Per usare il tuo file JAR:
-
utilizza il parametro del processo
--extra-jars. Ad esempio,'--extra-jars': 's3pathtojarfile.jar'. Per ulteriori informazioni, consulta i parametri del processo AWS Glue. -
Non includere
hudicome valore per il parametro del processo--datalake-formats. L'immissione di una stringa vuota come valore garantisce che nessuna libreria di data lake venga fornita automaticamente da AWS Glue. Per ulteriori informazioni, consulta Utilizzo del framework di Hudi in AWS Glue.
