Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
È possibile creare operazioni in streaming di estrazione, trasformazione e caricamento (ETL) che vengono eseguite continuamente, consumano dati da origini di streaming come Amazon Kinesis Data Streams, Apache Kafka e Amazon Managed Streaming for Apache Kafka (Amazon MSK). I processi puliscono e trasformano i dati, quindi caricano i risultati in data lake Amazon S3 o datastore JDBC.
Inoltre, è possibile produrre dati per i flussi di dati Amazon Kinesis. Questa funzionalità è disponibile solo durante la scrittura di AWS Glue script. Per ulteriori informazioni, consulta Connessioni Kinesis.
Per impostazione predefinita, AWS Glue elabora e scrive i dati in finestre di 100 secondi. Ciò consente di elaborare i dati in modo efficiente e di eseguire aggregazioni su dati che arrivano più tardi del previsto. Puoi modificare questa dimensione della finestra per aumentare la tempestività o la precisione dell'aggregazione. AWS Glue i lavori di streaming utilizzano i checkpoint anziché i segnalibri di lavoro per tenere traccia dei dati che sono stati letti.
Nota
AWS Glue fattura ogni ora per lo streaming dei lavori ETL mentre sono in esecuzione.
Questo video illustra le problematiche relative ai costi dello streaming ETL e le funzionalità di riduzione dei costi di. AWS Glue
La creazione di un processo di streaming ETL prevede i seguenti passaggi:
-
Per una sorgente di streaming Apache Kafka, crea un AWS Glue connessione alla sorgente Kafka o al cluster Amazon MSK.
-
Creare manualmente un catalogo dati per l'origine di streaming.
-
Creare un processo ETL per l'origine dati di streaming. Definire le proprietà del processo specifiche dello streaming e fornire uno script personalizzato o, facoltativamente, modificare lo script generato.
Per ulteriori informazioni, consulta Streaming di ETL in AWS Glue.
Quando si crea un processo ETL in streaming per Amazon Kinesis Data Streams, non è necessario creare un AWS Glue connessione. Tuttavia, se è presente una connessione collegata al AWS Glue è necessario eseguire lo streaming di un processo ETL con Kinesis Data Streams come origine, quindi un endpoint di cloud privato virtuale (VPC) su Kinesis. Per ulteriori informazioni, consulta Creazione di un endpoint dell'interfaccia nella Guida per l'utente di Amazon VPC. Quando si specifica un flusso Amazon Kinesis Data Streams in un altro account, è necessario impostare i ruoli e le politiche per consentire l'accesso multi-account. Per ulteriori informazioni, consulta Esempio: lettura da un flusso Kinesis in un account diverso.
AWS Glue i job ETL in streaming possono rilevare automaticamente i dati compressi, decomprimerli in modo trasparente, eseguire le consuete trasformazioni sulla sorgente di input e caricarli nell'archivio di output.
AWS Glue supporta la decompressione automatica per i seguenti tipi di compressione, in base al formato di input:
| Tipo di compressione | File Avro | Dato Avro | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | Sì | Sì | Sì | Sì | Sì |
| GZIP | No | Sì | Sì | Sì | Sì |
| SNAPPY | Sì (Snappy raw) | Sì (Snappy framed) | Sì (Snappy framed) | Sì (Snappy framed) | Sì (Snappy framed) |
| XZ | Sì | Sì | Sì | Sì | Sì |
| ZSTD | Sì | No | No | No | No |
| DEFLATE | Sì | Sì | Sì | Sì | Sì |
Argomenti
Creare un AWS Glue connessione per un flusso di dati Apache Kafka
Per leggere da uno stream di Apache Kafka, è necessario creare un AWS Glue connessione.
Per creare un AWS Glue connessione per un sorgente Kafka (Console)
Apri la AWS Glue console all'indirizzo. https://console.aws.amazon.com/glue/
-
Nel riquadro di navigazione, in Data catalog (Catalogo dati), seleziona Connections (Connessioni).
-
Scegliere Aggiungi connessione e, nella pagina Imposta proprietà della connessione, immettere un nome per la connessione.
Nota
Per ulteriori informazioni sulla specifica delle proprietà della connessione, consulta Proprietà della connessione di AWS Glue.
-
Per Tipo di connessione, scegli Kafka.
-
Per i server bootstrap Kafka URLs, inserisci l'host e il numero di porta per i broker di bootstrap per il tuo cluster Amazon MSK o il cluster Apache Kafka. Utilizza solo endpoint Transport Layer Security (TLS) per stabilire la connessione iniziale al cluster Kafka. Gli endpoint in testo normale non sono supportati.
Di seguito è riportato un elenco di esempio di coppie di nomi di host e numeri di porta per un cluster Amazon MSK.
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094Per ulteriori informazioni su come ottenere le informazioni del broker bootstrap, consulta Ottenere i broker bootstrap per un cluster Amazon MSK in Amazon Managed Streaming for Apache Kafka: Guida per gli sviluppatori.
-
Se si desidera una connessione sicura all'origine dati Kafka, seleziona Require SSL connection (Connessione SSL necessaria), e per Kafka private CA certificate location (Posizione del certificato emesso da una CA Kafka privata), inserisci un percorso Amazon S3 valido per un certificato SSL personalizzato.
Per una connessione SSL a Kafka autogestito, il certificato personalizzato è obbligatorio. P Amazon MSK è facoltativo.
Per ulteriori informazioni su come specificare un certificato personalizzato per Kafka, consulta AWS Glue proprietà della connessione SSL.
-
Usa AWS Glue Studio o la AWS CLI per specificare un metodo di autenticazione del client Kafka. Per accedere, AWS Glue Studio seleziona AWS Gluedal menu ETL nel riquadro di navigazione a sinistra.
Per ulteriori informazioni sui metodi di autenticazione client Kafka, consulta AWS Glue Proprietà di connessione Kafka per l'autenticazione del client .
-
Opzionalmente, inserisci una descrizione, quindi scegli Next (Successivo).
-
Per un cluster Amazon MSK, specifica il cloud privato virtuale (VPC), la sottorete e il gruppo di sicurezza. Le informazioni VPC sono opzionali per Kafka autogestito.
-
Scegli Next (Successivo) per esaminare tutte le proprietà della connessione, quindi scegli Finish (Termina).
Per ulteriori informazioni sull' AWS Glue connessioni, vediConnessione ai dati.
AWS Glue Proprietà di connessione Kafka per l'autenticazione del client
- Autenticazione SASL/GSSAPI (Kerberos)
-
La scelta di questo metodo di autenticazione consentirà di specificare le proprietà Kerberos.
- Keytab Kerberos
-
Scegliere la posizione del file keytab. Un keytab memorizza le chiavi a lungo termine per uno o più principali. Per ulteriori informazioni, consulta la Documentazione di MIT Kerberos: keytab
. - File Kerberos krb5.conf
-
Scegliere il file krb5.conf. Contiene l'area di autenticazione predefinita (una rete logica, simile a un dominio, che definisce un gruppo di sistemi sotto lo stesso KDC) e la posizione del server KDC. Per ulteriori informazioni, consulta la Documentazione di MIT Kerberos: krb5.conf
. - Principale Kerberos e nome del servizio Kerberos
-
Immettere il nome del principale e il nome del servizio Kerberos. Per ulteriori informazioni, consulta Documentazione MIT Kerberos: principale Kerberos
. - Autenticazione SASL/SCRAM-SHA-512
-
Scegliere questo metodo di autenticazione consentirà di specificare le credenziali di autenticazione.
- AWS Secrets Manager
-
Cercare il token nella casella Cerca digitando il nome o l'ARN.
- Nome utente e password del provider direttamente
-
Cercare il token nella casella Cerca digitando il nome o l'ARN.
- Autenticazione client SSL
-
Scegliere questo metodo di autenticazione consente di selezionare la posizione del keystore client Kafka navigando su Amazon S3. Facoltativamente, è possibile inserire la password del keystore del client Kafka e la password della chiave del client Kafka.
- Autenticazione IAM
-
Questo metodo di autenticazione non richiede specifiche aggiuntive ed è applicabile solo quando la sorgente di streaming è MSK Kafka.
- autenticazione SASL/PLAIN
-
La scelta di questo metodo di autenticazione consente di specificare le credenziali di autenticazione.
Creazione di un catalogo dati per un'origine di streaming
Una tabella del catalogo dati che specifica le proprietà del flusso dei dati di origine, incluso lo schema dei dati, può essere creata manualmente per una sorgente di streaming. Questa tabella viene utilizzata come origine dati per il processo di streaming ETL.
Se non si conosce lo schema dei dati nel flusso dei dati di origine, è possibile creare la tabella senza uno schema. Quindi, quando crei il processo ETL in streaming, puoi attivare il AWS Glue funzione di rilevamento dello schema. AWS Glue determina lo schema dai dati di streaming.
Utilizzo dell'AWS Glue console
Nota
Non è possibile utilizzare la AWS Lake Formation console per creare la tabella; è necessario utilizzare AWS Glue console.
Considera inoltre le seguenti informazioni per le origini di streaming in formato Avro o per i dati di log a cui è possibile applicare i pattern Grok.
Origine dati Kinesis
Durante la creazione della tabella, impostare le seguenti proprietà di streaming ETL (console).
- Tipo di origine
-
Kinesis
- Per una fonte Kinesis nello stesso account:
-
- Regione
-
La AWS regione in cui risiede il servizio Amazon Kinesis Data Streams. Il nome della regione e del flusso Kinesis sono tradotti insieme in un flusso ARN.
Esempio: https://kinesis.us-east-1.amazonaws.com
- Nome del flusso Kinesis
-
Nome del flusso come descritto in Creazione di un flusso nella Guida per gli sviluppatori Amazon Kinesis Data Streams.
- Per un'origine Kinesis in un altro account, fai riferimento a questo esempio per configurare i ruoli e i criteri per consentire l'accesso a più account. Configura queste impostazioni:
-
- Flusso ARN
-
L'ARN del flusso dei dati Kinesis con il quale il consumatore è registrato. Per ulteriori informazioni, consulta Amazon Resource Names (ARNs) e AWS Service Namespaces nel. Riferimenti generali di AWS
- ARN del ruolo assunto
-
L'Amazon Resource Name (ARN) del ruolo assegnato al ruolo da assumere.
- Nome sessione (facoltativo)
-
Un identificatore della sessione del ruolo assunto.
Utilizza il nome della sessione del ruolo per identificare in modo univoco una sessione quando lo stesso ruolo viene assunto da diverse entità principali o per motivi diversi. In scenari multi-account, l'account proprietario del ruolo può vedere il nome della sessione del ruolo e può registrarlo. Il nome della sessione del ruolo viene utilizzato anche nell'ARN dell'entità ruolo assunto. Ciò significa che le successive richieste API tra più account che utilizzano le credenziali di sicurezza temporanee esporranno il nome della sessione del ruolo all'account esterno nei relativi log. AWS CloudTrail
Per impostare le proprietà ETL di streaming per Amazon Kinesis Data Streams (AWS Glue API o) AWS CLI
-
Per impostare le proprietà di streaming ETL per un'origine Kinesis nello stesso account, specifica i parametri
streamNameeendpointUrlnella strutturaStorageDescriptordell'operazione APICreateTableo del comando CLIcreate_table."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }In alternativa, specifica il
streamARN."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
Per impostare le proprietà di streaming ETL per un'origine Kinesis nello stesso account, specifica i parametri
streamARN,awsSTSRoleARNeawsSTSSessionName(facoltativo) nella strutturaStorageDescriptordell'operazione APICreateTableo del comando CLIcreate_table."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Origine dati Kafka
Durante la creazione della tabella, impostare le seguenti proprietà di streaming ETL (console).
- Tipo di origine
-
Kafka
- Per una fonte Kafka:
-
- Nome argomento
-
Nome argomento specificato in Kafka.
- Connessione
-
Un record AWS Glue connessione che fa riferimento a una fonte Kafka, come descritto in. Creare un AWS Glue connessione per un flusso di dati Apache Kafka
AWS Glue Fonte della tabella Schema Registry
Per utilizzare AWS Glue Registro degli schemi per i lavori di streaming, segui le istruzioni riportate Caso d'uso: AWS Glue Data Catalog per creare o aggiornare una tabella del registro degli schemi.
Attualmente, AWS Glue Lo streaming supporta solo il formato Glue Schema Registry Avro con inferenza dello schema impostata su. false
Note e restrizioni per le origini di streaming Avro
Le seguenti note e restrizioni si applicano alle origini di streaming nel formato Avro:
-
Quando il rilevamento dello schema è attivato, lo schema Avro deve essere incluso nel payload. Quando disattivato, il payload deve contenere solo dati.
-
Alcuni tipi di dati Avro non sono supportati nei frame dinamici. Non è possibile specificare questi tipi di dati quando si definisce lo schema con la pagina Definisci uno schema nella procedura guidata di creazione della tabella in AWS Glue console. Durante il rilevamento dello schema, i tipi non supportati nello schema Avro vengono convertiti in tipi supportati come segue:
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
Se si definisce lo schema della tabella utilizzando la pagina Define a schema (Definire uno schema) nella console, il tipo di elemento root implicito per lo schema è
record. Se si desidera un tipo di elemento root diverso darecord, ad esempioarrayomap, non è possibile specificare lo schema utilizzando la pagina Define a schema (Definire uno schema). È invece necessario saltare quella pagina e specificare lo schema come proprietà di tabella o all'interno dello script ETL.-
Per specificare lo schema nelle proprietà della tabella, completa la procedura guidata per la creazione della tabella, modifica i dettagli della tabella e aggiungi una nuova coppia chiave-valore in Table properties (Proprietà della tabella). Utilizza la chiave
avroSchema, e inserisci un oggetto JSON dello schema per il valore, come mostrato nello screenshot seguente.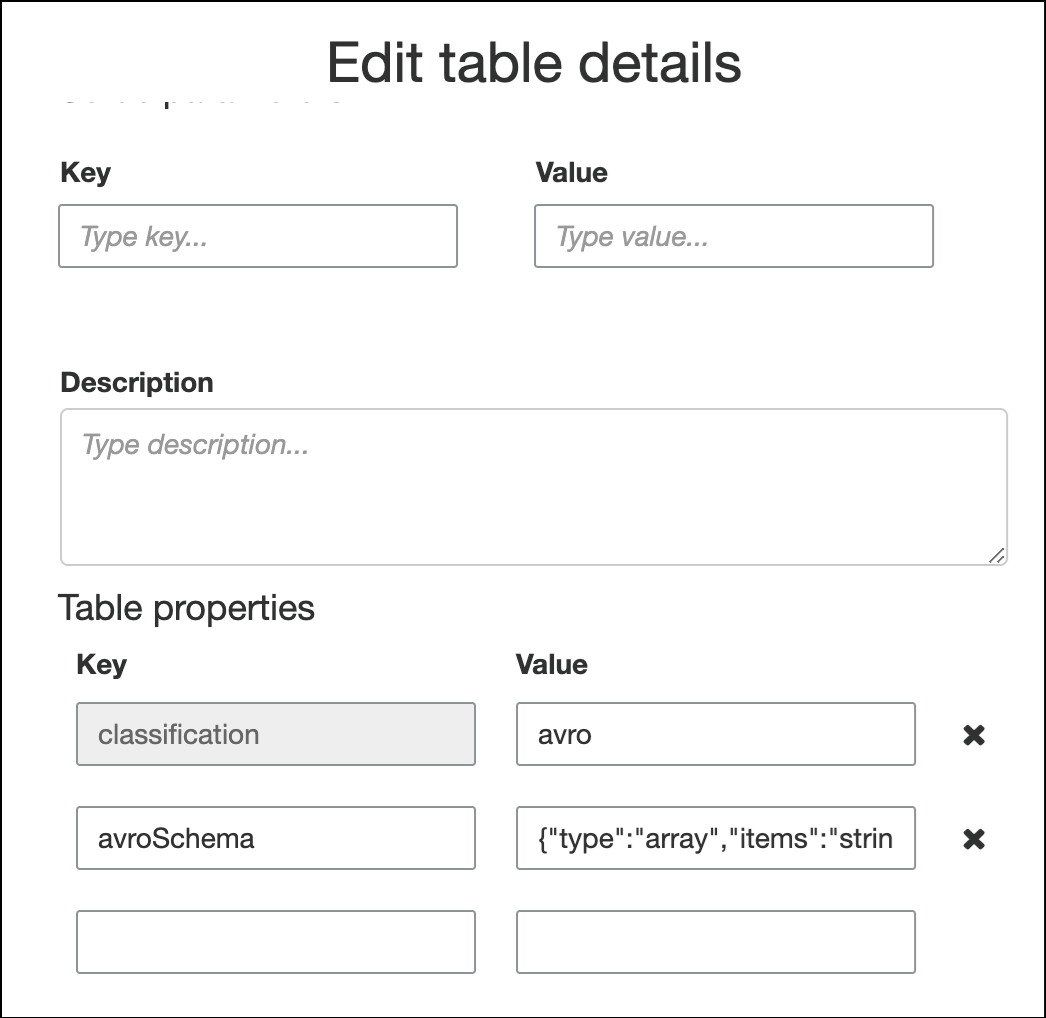
-
Per specificare lo schema nello script ETL, modifica l'istruzione di assegnazione
datasource0e aggiungi la chiaveavroSchemaall'argomentoadditional_options, come mostrato nei seguenti esempi Python e Scala.SCHEMA_STRING = ‘{"type":"array","items":"string"}’ datasource0 = glueContext.create_data_frame.from_catalog(database = "database", table_name = "table_name", transformation_ctx = "datasource0", additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "false", "avroSchema": SCHEMA_STRING})
-
Applicazione di pattern Grok alle origini di streaming
È possibile creare un processo di streaming ETL per un'origine dati dei log e utilizzare i pattern Grok per convertire i registri in dati strutturati. Il processo ETL elabora quindi i dati come origine dati strutturata. È possibile specificare i pattern Grok da applicare quando si crea la tabella Catalogo dati per l'origine di streaming.
Per informazioni sui pattern Grok e sui valori delle stringhe di pattern personalizzati, consulta Scrittura di classificatori personalizzati grok.
Aggiungere pattern Grok alla tabella Catalogo dati (console)
-
Utilizza la procedura guidata per la creazione della tabella e crea la tabella con i parametri specificati in Creazione di un catalogo dati per un'origine di streaming. Specifica il formato dei dati come Grok, compila il pattern Grok e, facoltativamente, aggiungi pattern personalizzati in Custom patterns (optional) (Modelli personalizzati [facoltativo]).
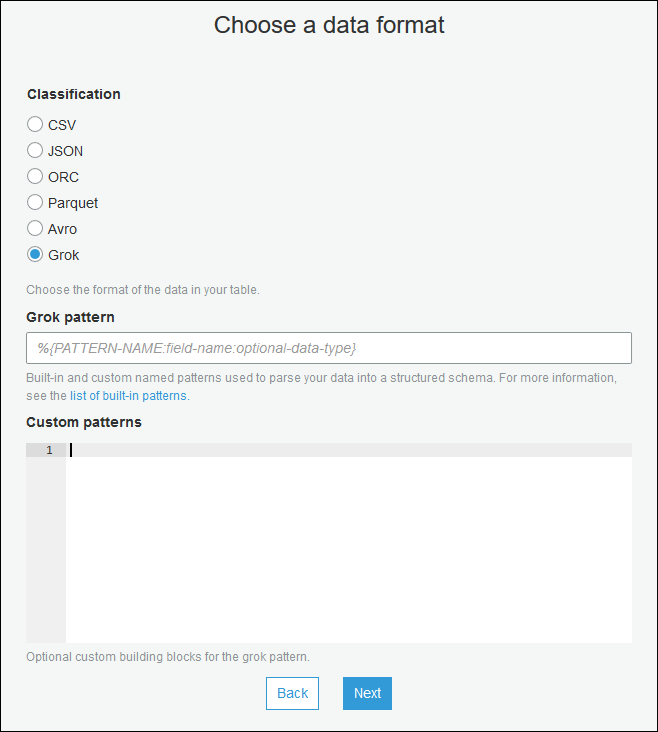
Premi Invio dopo ogni pattern personalizzato.
Per aggiungere modelli grok alla tabella Data Catalog (AWS Glue API o AWS CLI)
-
Aggiungi il parametro
GrokPatterne, facoltativamente, il parametroCustomPatternsal processo APICreateTableo al comando CLIcreate_table."Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },Esprimi
grokCustomPatternscome stringa e usa "\n" come separatore tra i pattern.Di seguito è riportato un esempio di specifica di questi parametri.
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
Definizione delle proprietà di processo per un processo di streaming ETL
Quando si definisce un processo ETL in streaming in AWS Glue console, fornisci le seguenti proprietà specifiche per i flussi. Per le descrizioni di proprietà aggiuntive, consulta Definire le proprietà di processo per i processi Spark.
- Ruolo IAM
-
Specificate il ruolo AWS Identity and Access Management (IAM) utilizzato per l'autorizzazione alle risorse utilizzate per eseguire il job, accedere alle sorgenti di streaming e accedere agli archivi dati di destinazione.
Per accedere ad Amazon Kinesis Data Streams,
AmazonKinesisFullAccessAWS collega la policy gestita al ruolo o allega una policy IAM simile che consenta un accesso più dettagliato. Per i criteri di esempio, consulta Controllo dell'accesso alle risorse Amazon Kinesis Data Streams tramite IAM.Per ulteriori informazioni sulle autorizzazioni per l'esecuzione di lavori in AWS Glue, consulta Gestione delle identità e degli accessi per AWS Glue.
- Tipo
-
Scegli Spark streaming.
- AWS Glue version
-
Il AWS Glue version determina le versioni di Apache Spark e Python o Scala disponibili per il lavoro. Scegliete una selezione che specifichi la versione di Python o Scala disponibile per il lavoro. AWS Glue La versione 2.0 con supporto Python 3 è la versione predefinita per lo streaming delle operazioni ETL.
- Maintenance window (Finestra di manutenzione)
-
Speciifica una finestra in cui è possibile riavviare un processo di streaming. Per informazioni, consulta Finestre di manutenzione per AWS Glue lo streaming.
- Timeout dei processi
-
È possibile inserire una durata in minuti. Il valore predefinito è vuoto.
I lavori di streaming devono avere un valore di timeout inferiore a 7 giorni o 10080 minuti.
Se il valore viene lasciato vuoto, il processo verrà riavviato dopo 7 giorni, se non è stata impostata una finestra di manutenzione. Se hai impostato una finestra di manutenzione, il lavoro verrà riavviato durante la finestra di manutenzione dopo 7 giorni.
- Origine dati
-
Rimuovi la tabella creata in Creazione di un catalogo dati per un'origine di streaming.
- Destinazione dati
-
Esegui una di queste operazioni:
-
Scegliere Crea tabelle nell'oggetto dati e specificare le seguenti proprietà dell'oggetto dati.
- Datastore
-
Seleziona Amazon S3 o JDBC.
- Formato
-
Scegli un formato qualsiasi. Tutti sono supportati per lo streaming.
-
Scegli Use tables in the data catalog and update your data target (Usa tabelle nel catalogo dati e aggiorna la destinazione dati) e scegli una tabella per un data store JDBC.
-
- Definizione dello schema di output
-
Esegui una di queste operazioni:
-
Scegli Rileva automaticamente lo schema di ogni record per attivare il rilevamento dello schema. AWS Glue determina lo schema dai dati di streaming.
-
Scegli Specify output schema for all records (Specificare lo schema di output per tutti i record) per utilizzare la trasformazione Apply Mapping (Applica mapping) per definire lo schema di output.
-
- Script
-
È possibile fornire uno script personalizzato o modificare lo script generato per eseguire le operazioni supportate dal motore di Apache Spark Structured Streaming. Per informazioni sulle operazioni disponibili, vedere Operazioni sullo streaming DataFrames /Datasets.
Streaming di note e restrizioni ETL
Tieni presente le seguenti note e restrizioni:
-
Decompressione automatica per AWS Glue lo streaming dei lavori ETL è disponibile solo per i tipi di compressione supportati. Tieni presente quanto segue:
Snappy framed si riferisce al formato di framing
ufficiale di Snappy. Deflate è supportato in Glue versione 3.0, non Glue versione 2.0.
-
Quando si utilizza il rilevamento dello schema, non è possibile eseguire join dei dati di streaming.
-
AWS Glue i lavori ETL in streaming non supportano il tipo di dati Union per AWS Glue Registro degli schemi con formato Avro.
-
Il tuo script ETL può usare AWS Gluee le trasformazioni native di Apache Spark Structured Streaming. Per ulteriori informazioni, consulta Operazioni sullo streaming DataFrames /Datasets sul sito Web
di Apache Spark o. AWS Glue PySpark trasforma il riferimento -
AWS Glue i processi ETL in streaming utilizzano i checkpoint per tenere traccia dei dati che sono stati letti. Pertanto, un processo arrestato e riavviato riprende da dove era stato interrotto nello stream. Se si desidera rielaborare i dati, è possibile eliminare la cartella di checkpoint a cui si fa riferimento nello script.
-
I segnalibri delle operazioni non sono supportati.
-
Per utilizzare la funzionalità di fan-out avanzato di Flusso di dati Kinesis, consulta la pagina Utilizzo del fan-out avanzato nei processi di flussi di dati Kinesis.
-
Se utilizzi una tabella Data Catalog creata da AWS Glue Schema Registry, quando diventa disponibile una nuova versione dello schema, per riflettere il nuovo schema, devi fare quanto segue:
-
Arrestare i processi associati alla tabella.
-
Aggiornare lo schema per la tabella catalogo dati.
-
Riavviare i processi associati alla tabella.
-
