Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ora puoi creare processi di elaborazione dati in modo più efficiente con la generazione di PySpark DataFrame codice e riconoscimento del contesto basata su query in Amazon Q Data Integration. Ad esempio, puoi utilizzare questo prompt per generare PySpark codice: «crea un lavoro per caricare i dati di vendita dalla tabella Redshift 'analytics.salesorder' utilizzando la connessione 'erp_conn', filtra order_amount al di sotto di 50 dollari e salva su Amazon S3 in formato parquet».
Amazon Q genererà lo script in base alla configurazione del flusso di lavoro di integrazione dei dati di prompt e setup con i dettagli forniti dalla domanda, come configurazioni di connessione, dettagli dello schema, nomi di database/tabelle e specifiche delle colonne per le trasformazioni. Le informazioni sensibili, come le password delle opzioni di connessione, continuano a essere oscurate.
Se le informazioni richieste non vengono fornite nel prompt, Amazon Q inserirà dei segnaposto, che dovrai aggiornare il codice generato con i valori appropriati prima di eseguire il codice.
Di seguito sono riportati alcuni esempi su come utilizzare la consapevolezza del contesto.
Esempio: interazioni
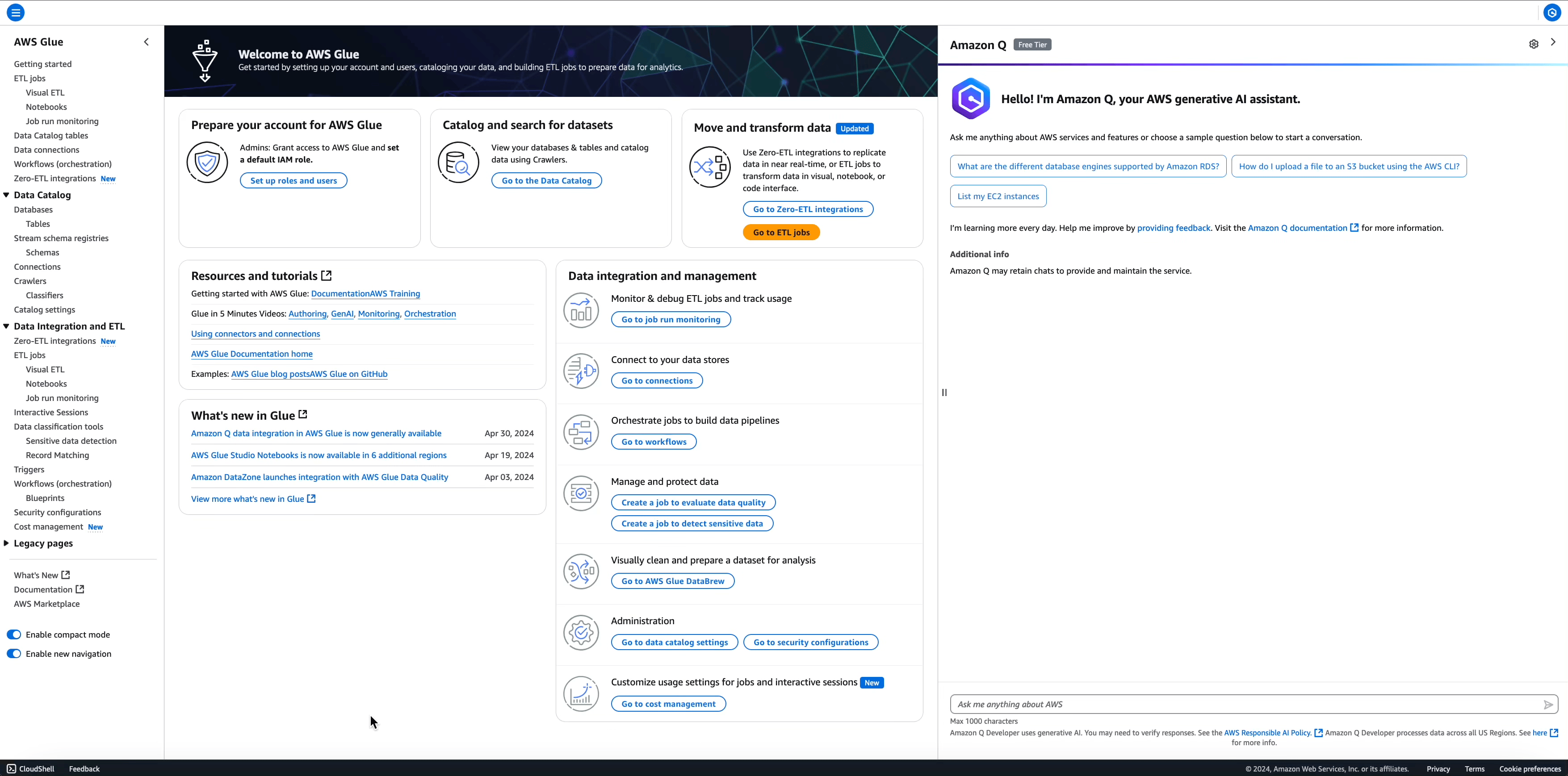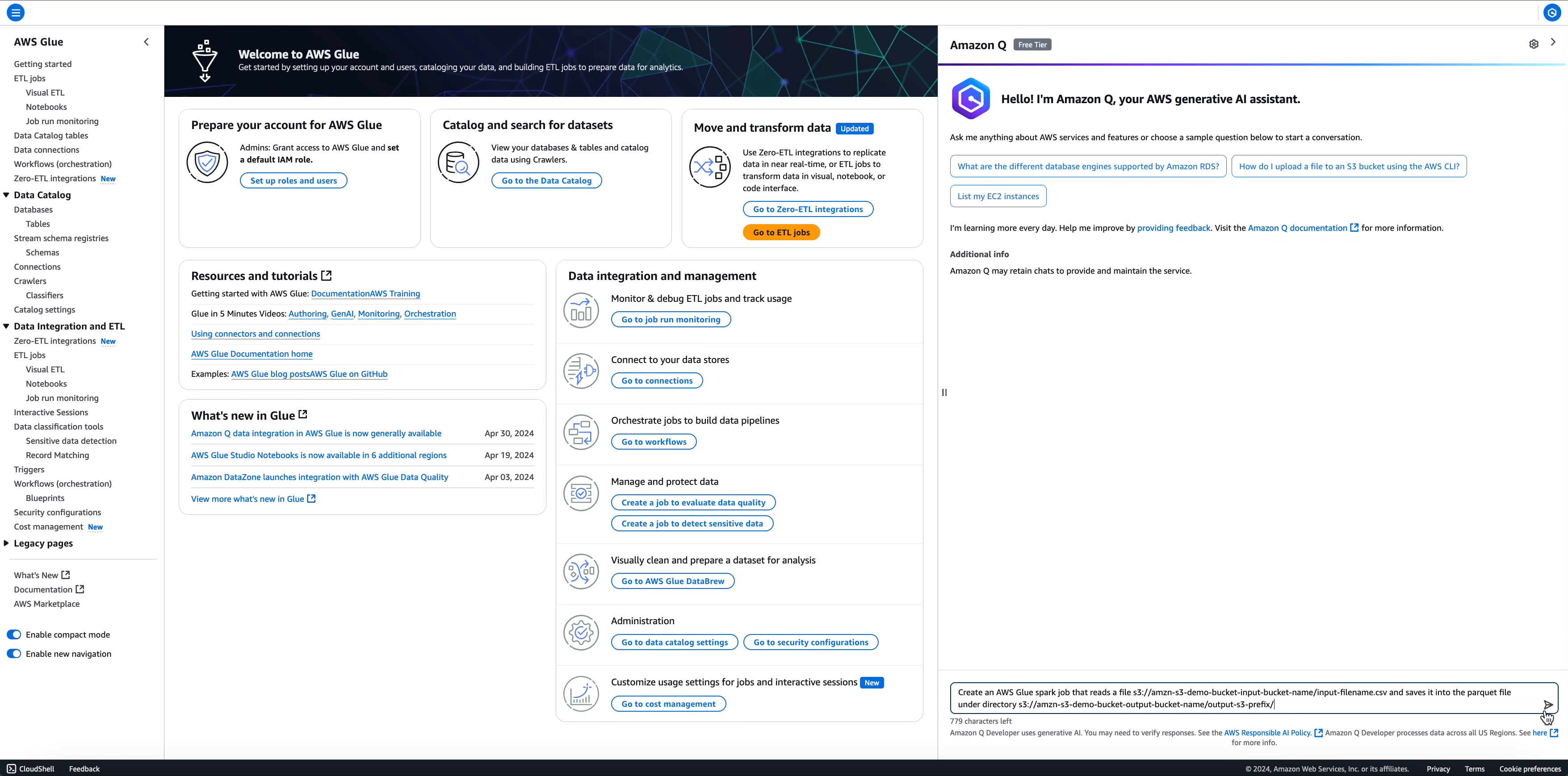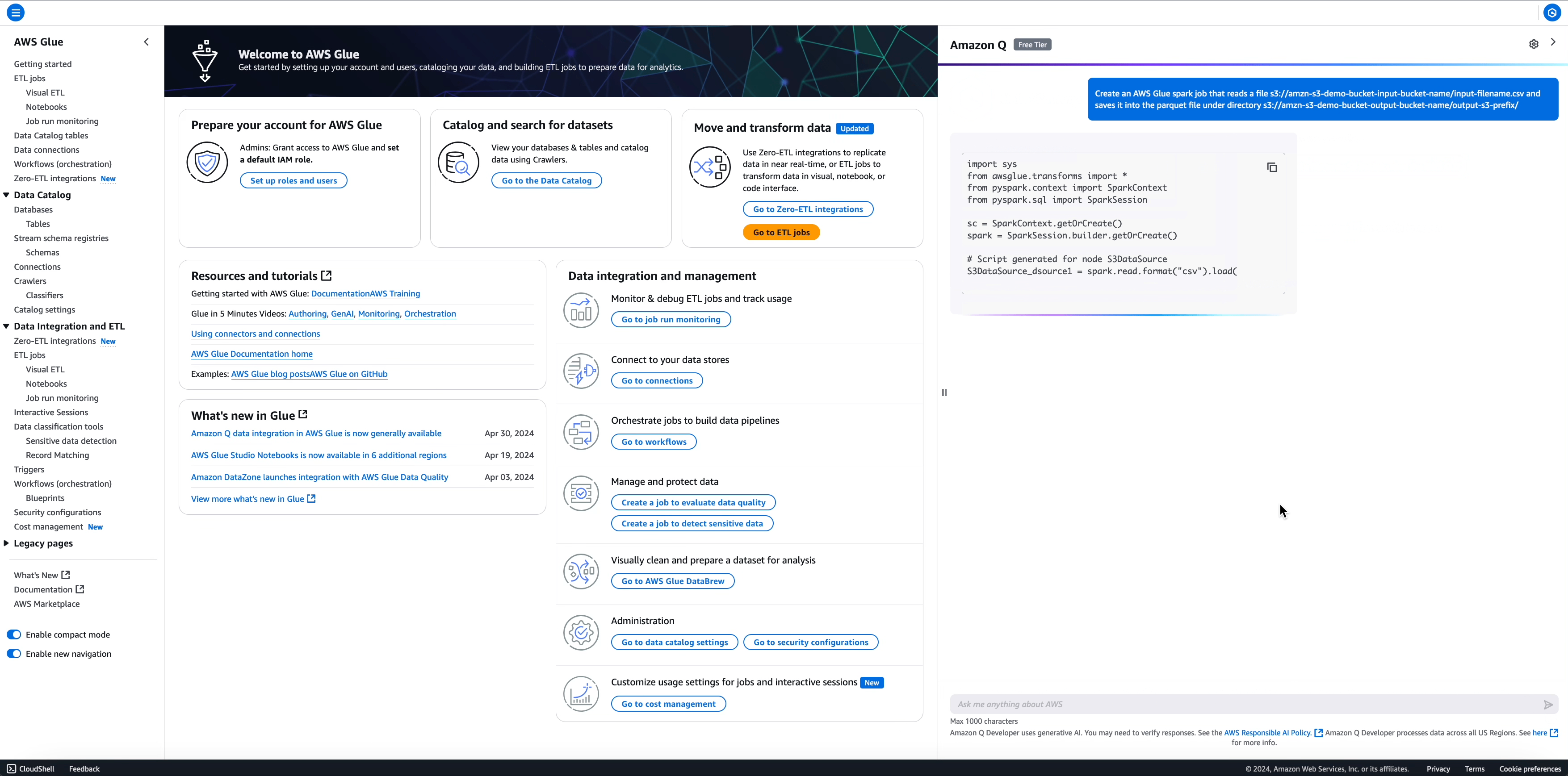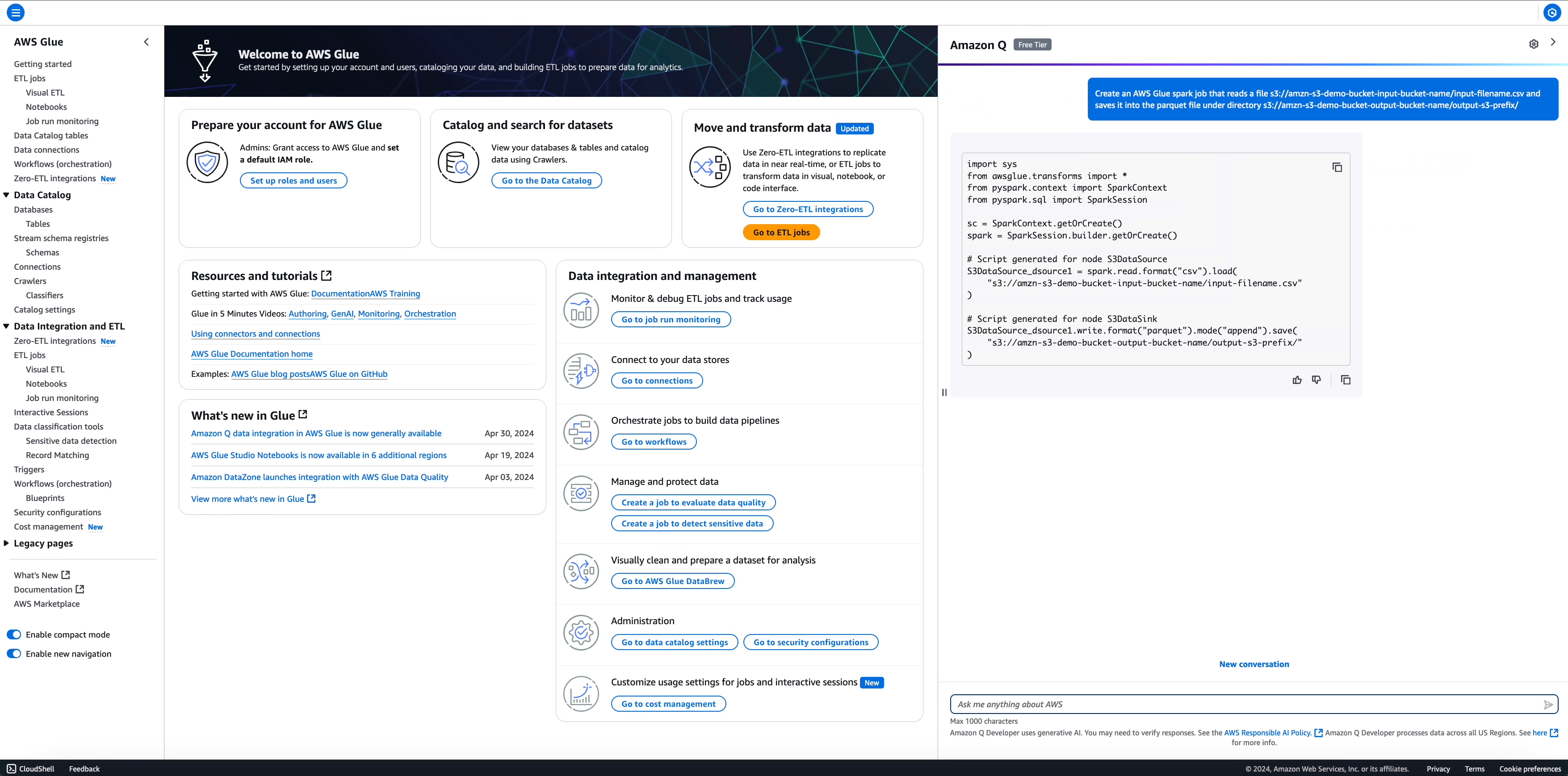
Richiesta: Create an AWS Glue spark job that reads a file s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv and
saves it into the parquet file under directory s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node S3DataSource
S3DataSource_dsource1 = spark.read.format("csv").load(
"s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv"
)
# Script generated for node S3DataSink
S3DataSource_dsource1.write.format("parquet").mode("append").save(
"s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/"
)
Richiesta: Create an AWS Glue spark job that reads a file s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv and
saves it into the parquet file under directory s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node S3DataSource
S3DataSource_dsource1 = spark.read.format("csv").load(
"s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv"
)
# Script generated for node S3DataSink
S3DataSource_dsource1.write.format("parquet").mode("append").save(
"s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/"
) Richiesta: write an ETL script to read from a Lakehouse table my-table in database my-database and write it to a RDS MySQL table
my-target-table
Per i campi in cui non hai fornito informazioni (ad esempio, quello connectionName obbligatorio è My SQL data sink e l'impostazione predefinita è con un segnaposto <connection-name>nel codice generato), viene mantenuto un segnaposto per inserire le informazioni richieste prima di eseguire lo script.
Script generato:
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
from connectivity.adapter import CatalogConnectionHelper
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node S3DataSource
S3DataSource_dsource1 = spark.read.format("parquet").load(
"s3://amzn-lakehouse-demo-bucket/my-database/my-table"
)
# Script generated for node ConnectionV2DataSink
ConnectionV2DataSink_dsink1_additional_options = {"dbtable": "my-target-table"}
CatalogConnectionHelper(spark).write(
S3DataSource_dsource1,
"mysql",
"<connection-name>",
ConnectionV2DataSink_dsink1_additional_options,
)
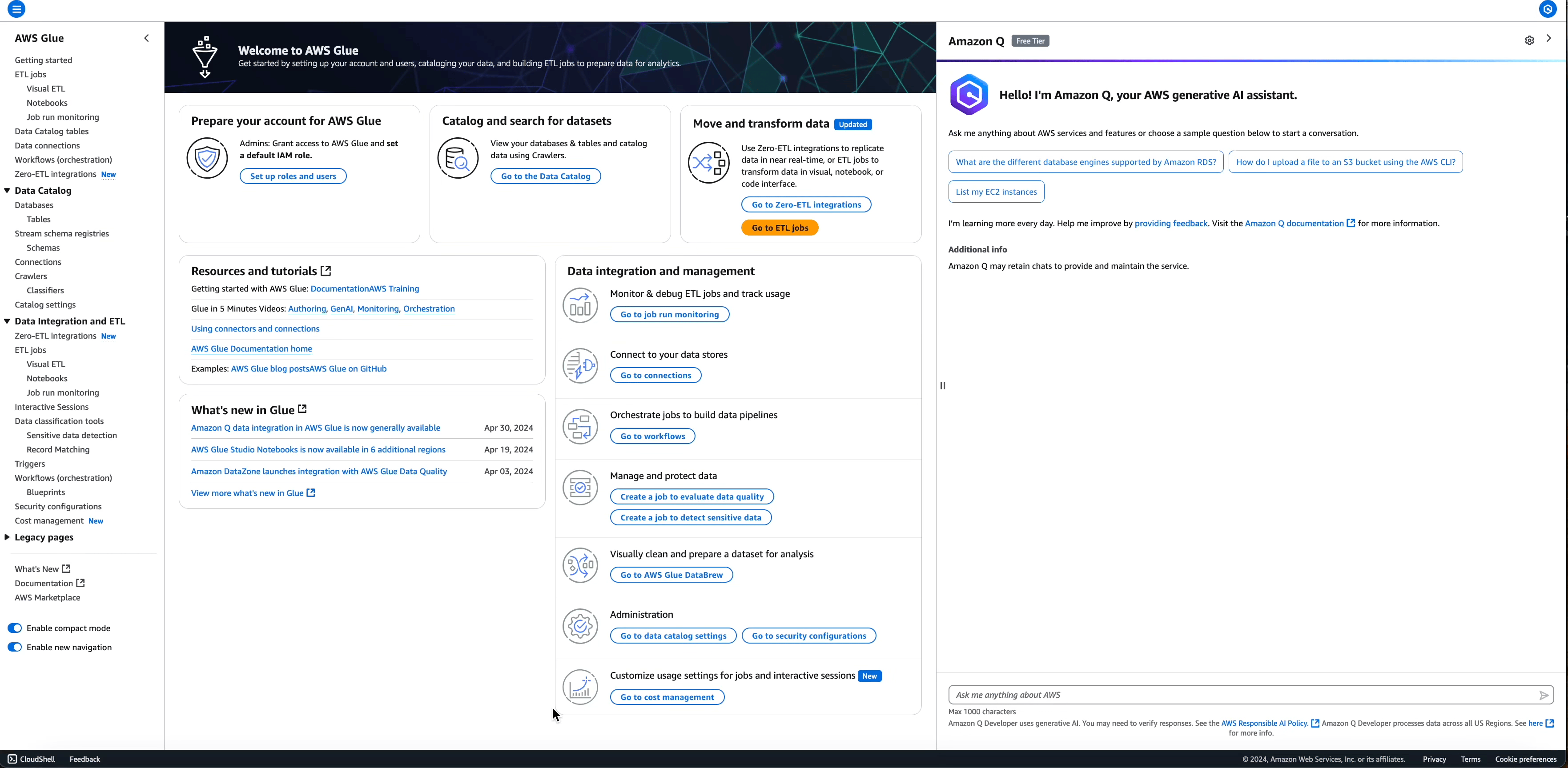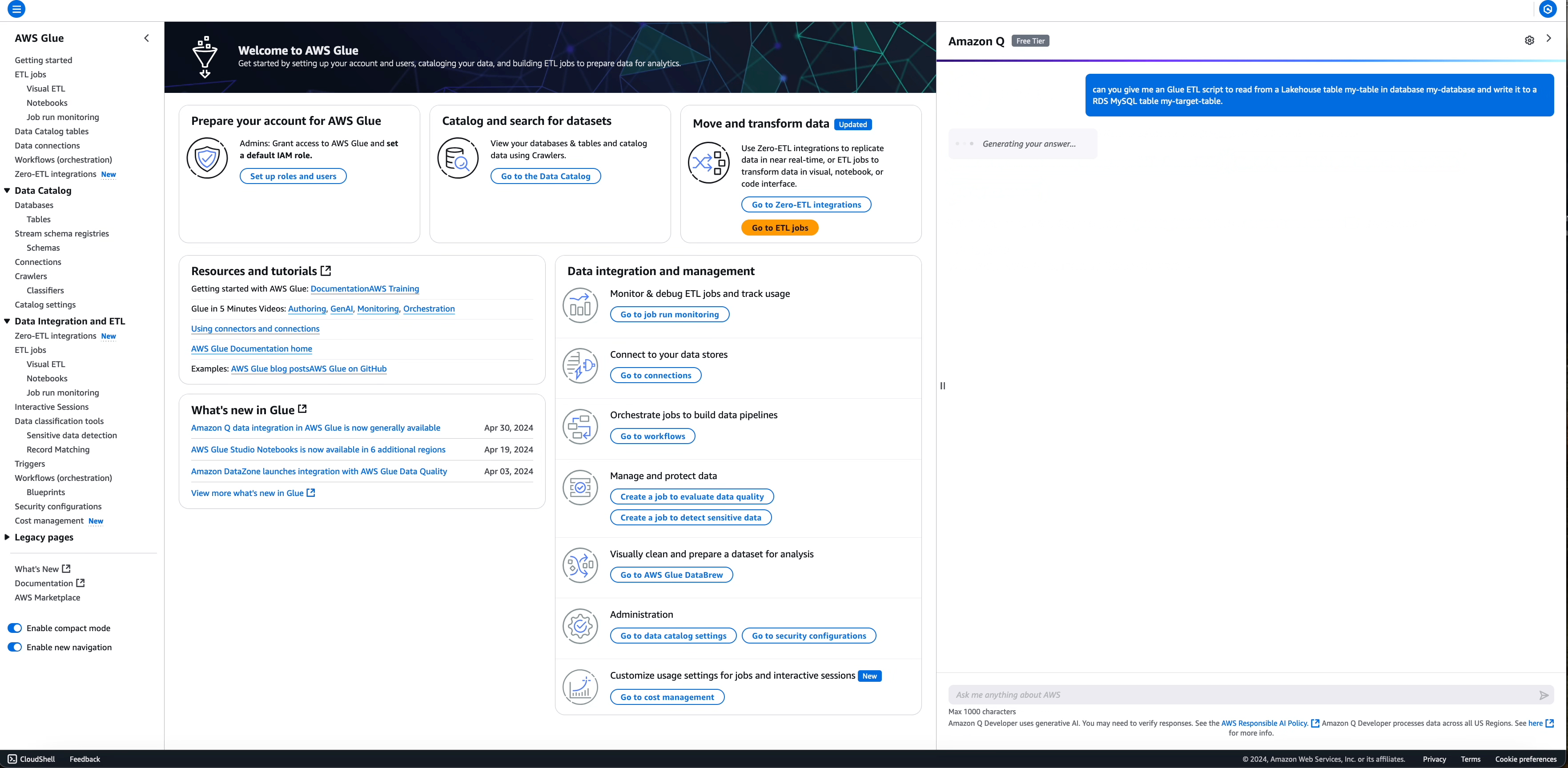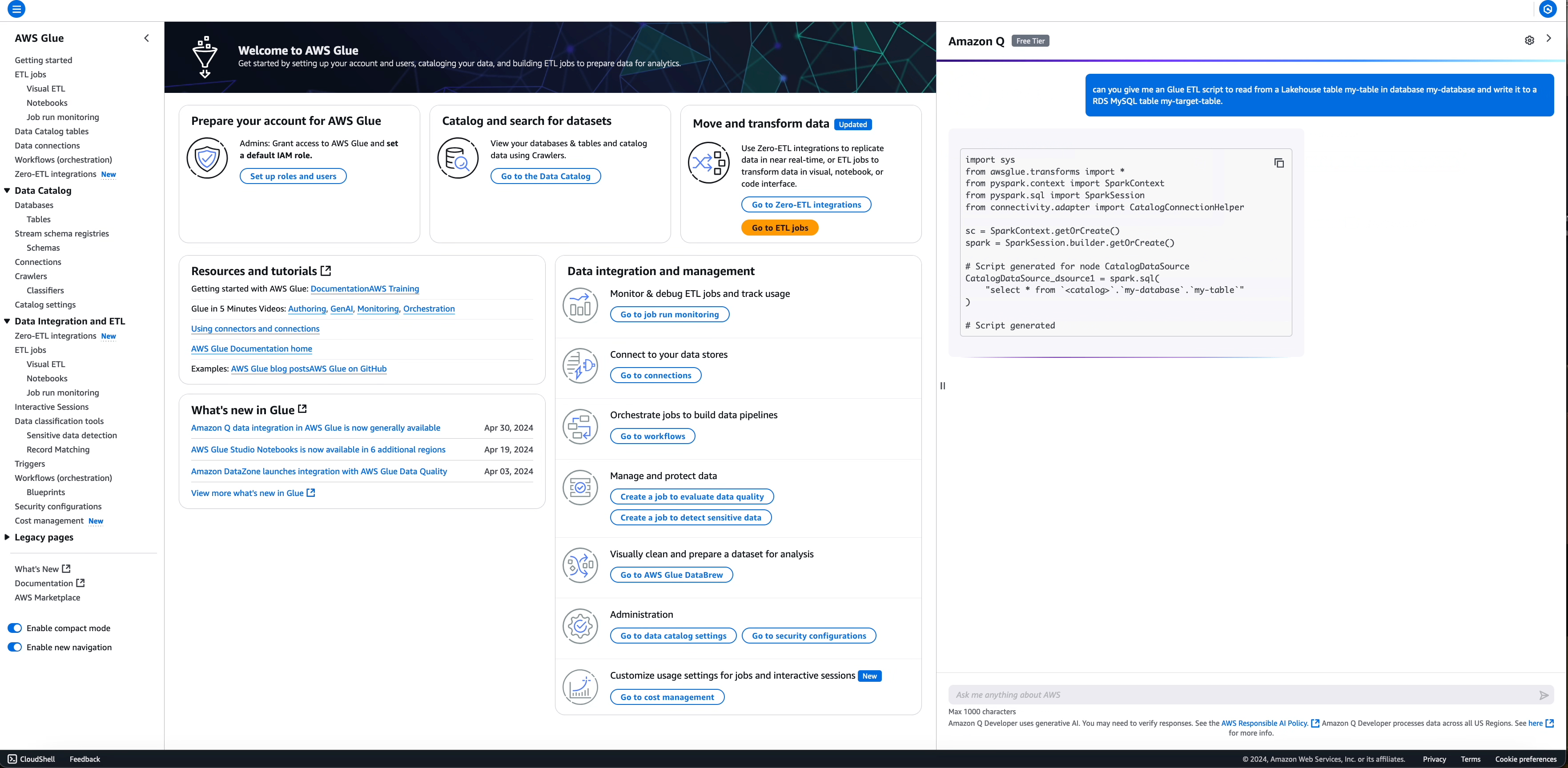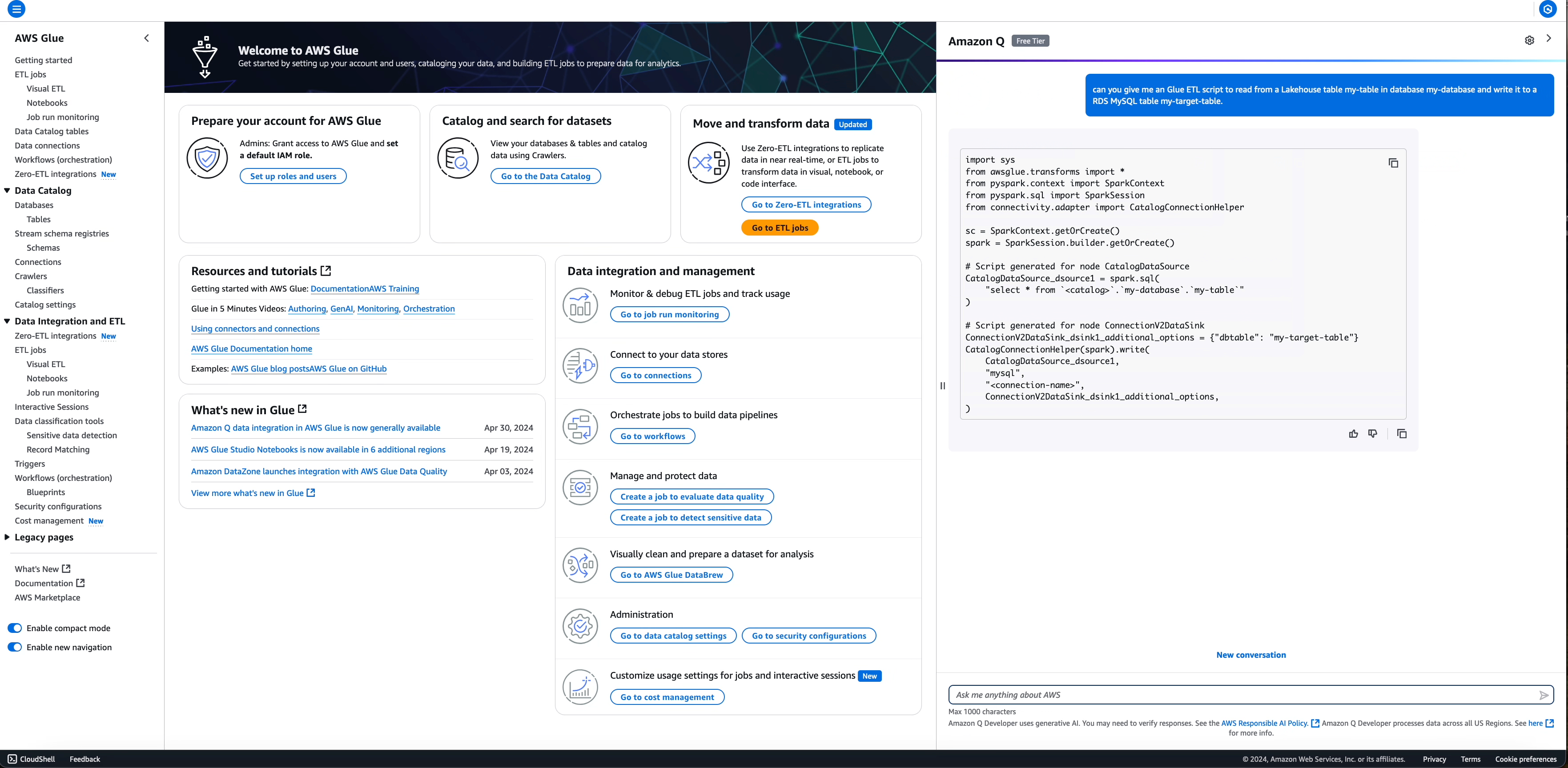
Richiesta: write an ETL script to read from a Lakehouse table my-table in database my-database and write it to a RDS MySQL table
my-target-table
Per i campi in cui non hai fornito informazioni (ad esempio, quello connectionName obbligatorio è My SQL data sink e l'impostazione predefinita è con un segnaposto <connection-name>nel codice generato), viene mantenuto un segnaposto per inserire le informazioni richieste prima di eseguire lo script.
Script generato:
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
from connectivity.adapter import CatalogConnectionHelper
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node S3DataSource
S3DataSource_dsource1 = spark.read.format("parquet").load(
"s3://amzn-lakehouse-demo-bucket/my-database/my-table"
)
# Script generated for node ConnectionV2DataSink
ConnectionV2DataSink_dsink1_additional_options = {"dbtable": "my-target-table"}
CatalogConnectionHelper(spark).write(
S3DataSource_dsource1,
"mysql",
"<connection-name>",
ConnectionV2DataSink_dsink1_additional_options,
)
L'esempio seguente dimostra come è possibile chiedere a AWS Glue di creare uno script AWS Glue per completare un ETL flusso di lavoro completo con il seguente prompt:. Create a AWS Glue ETL Script read from two AWS Glue Data Catalog tables venue and event in my database
glue_db_4fthqih3vvk1if, join the results on the field venueid, filter on venue state with condition as venuestate=='DC'
after joining the results and write output to an Amazon S3 S3 location s3://amz-s3-demo-bucket/output/ in CSV format
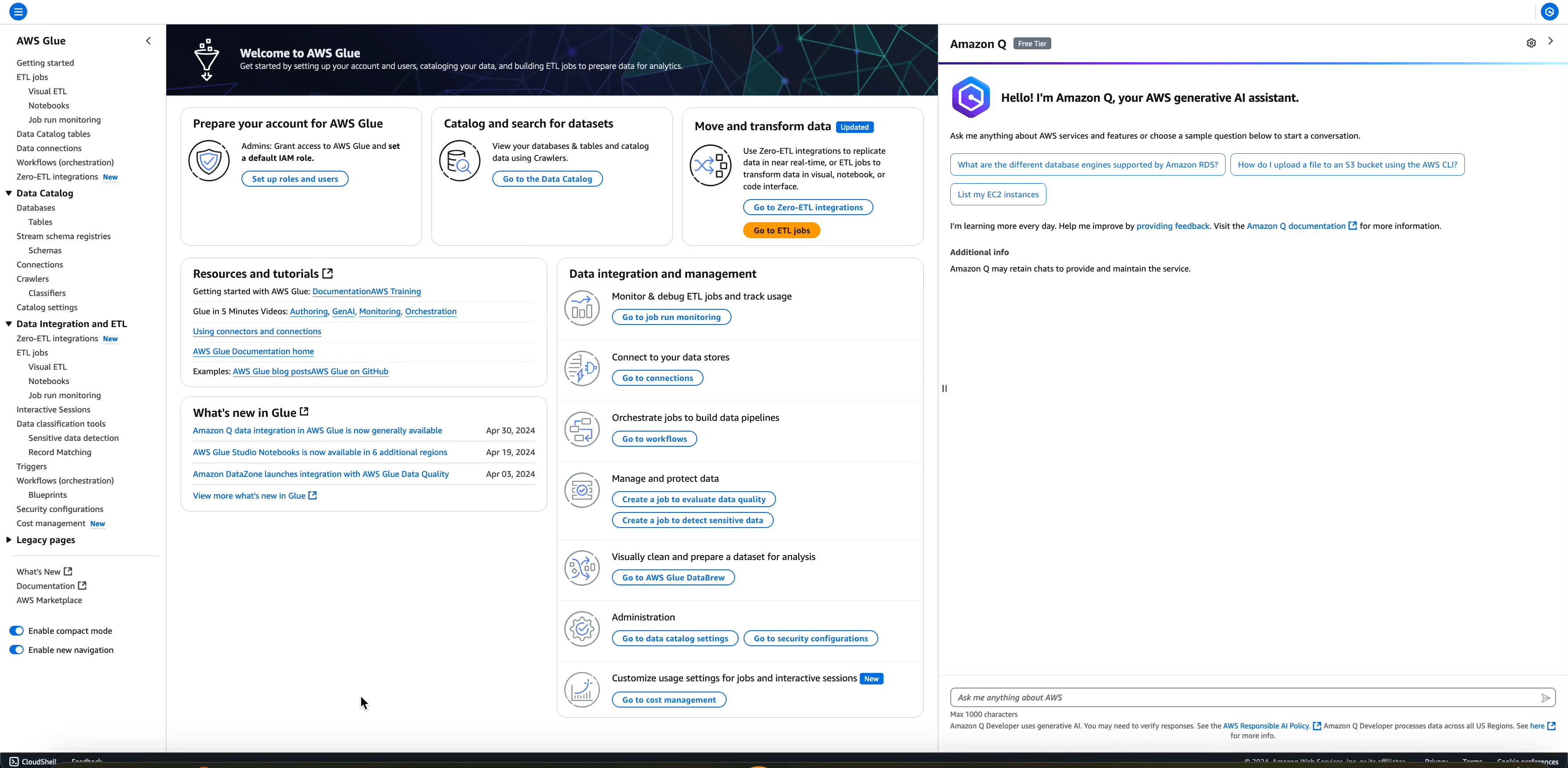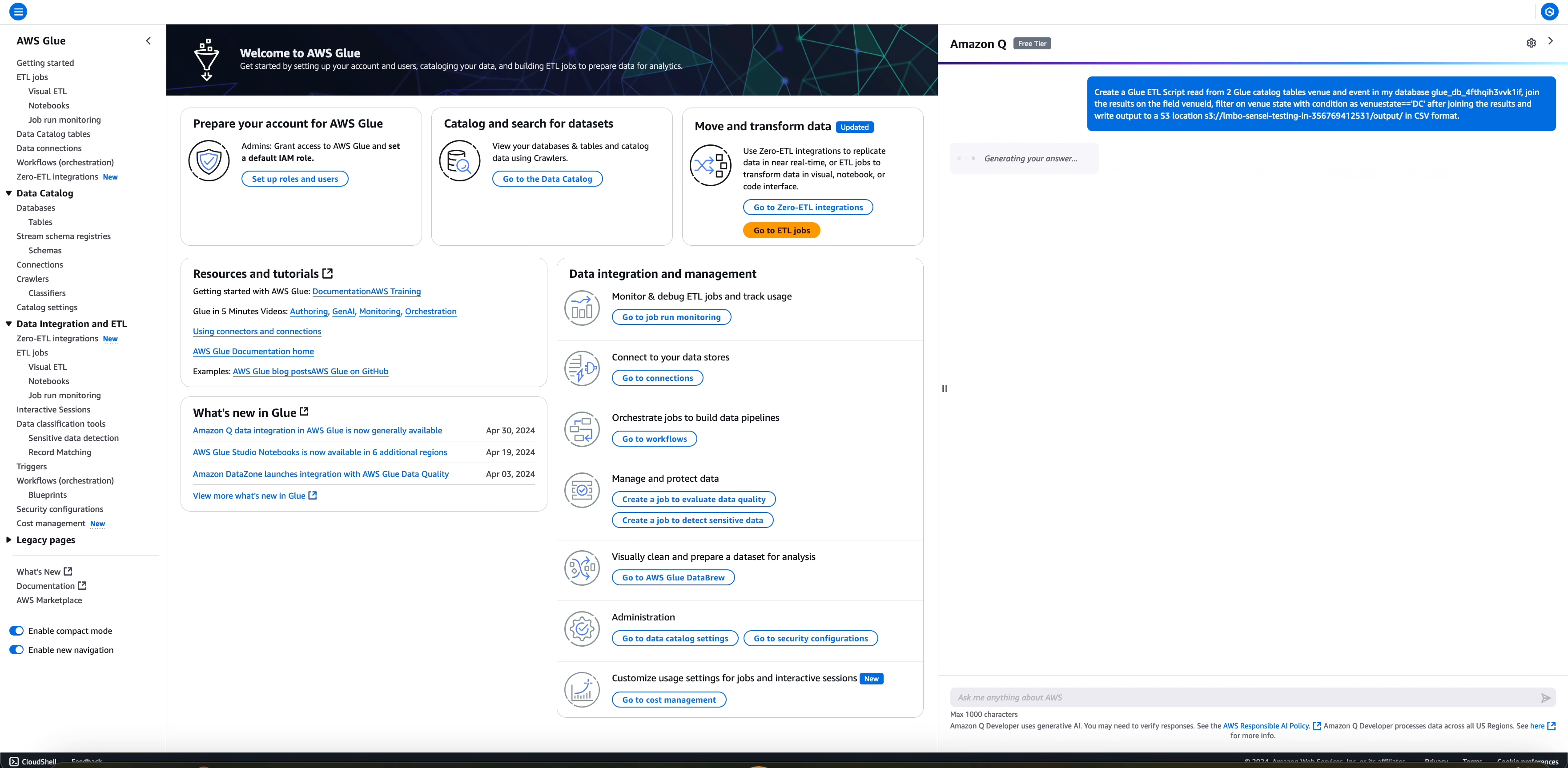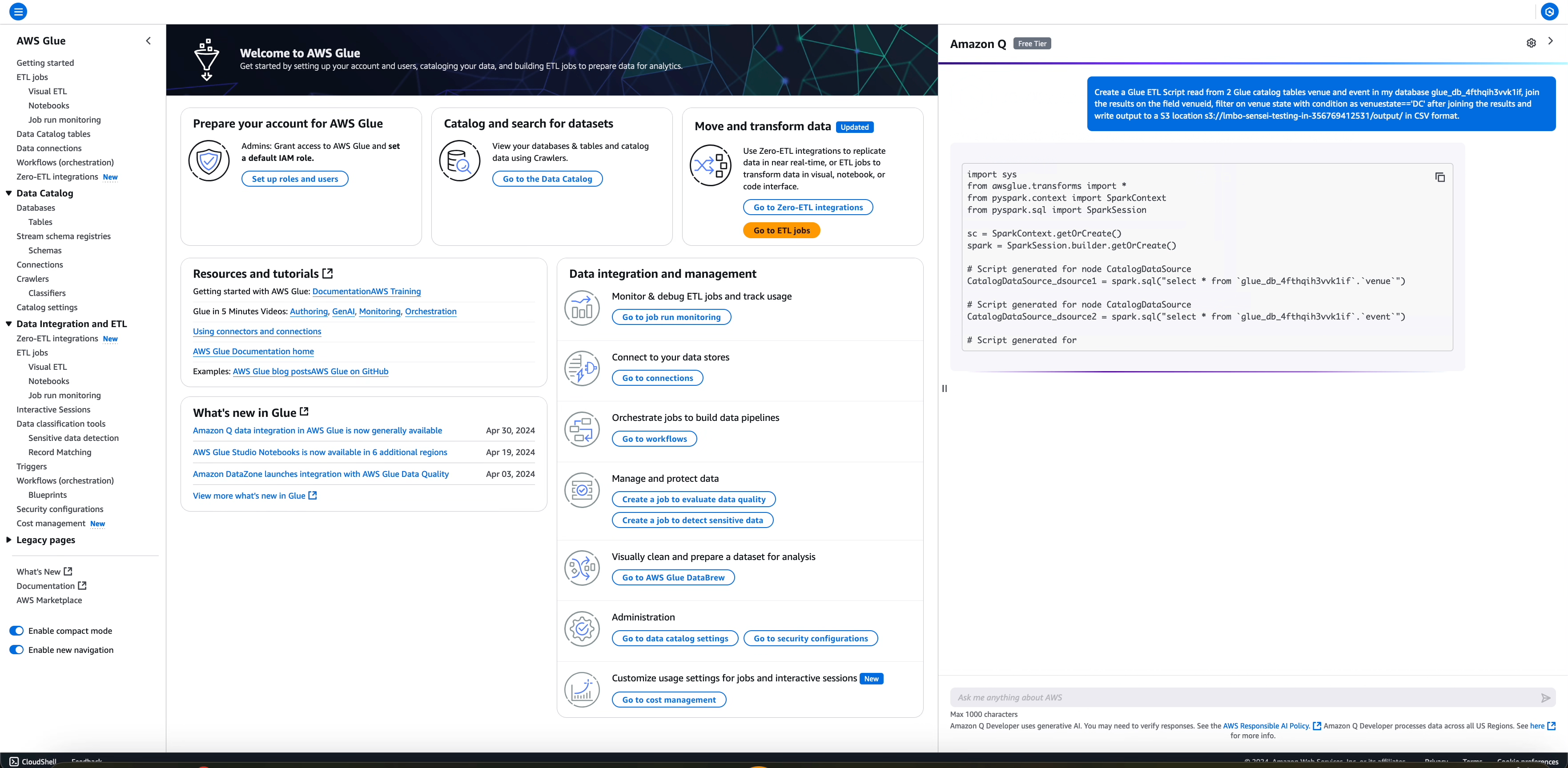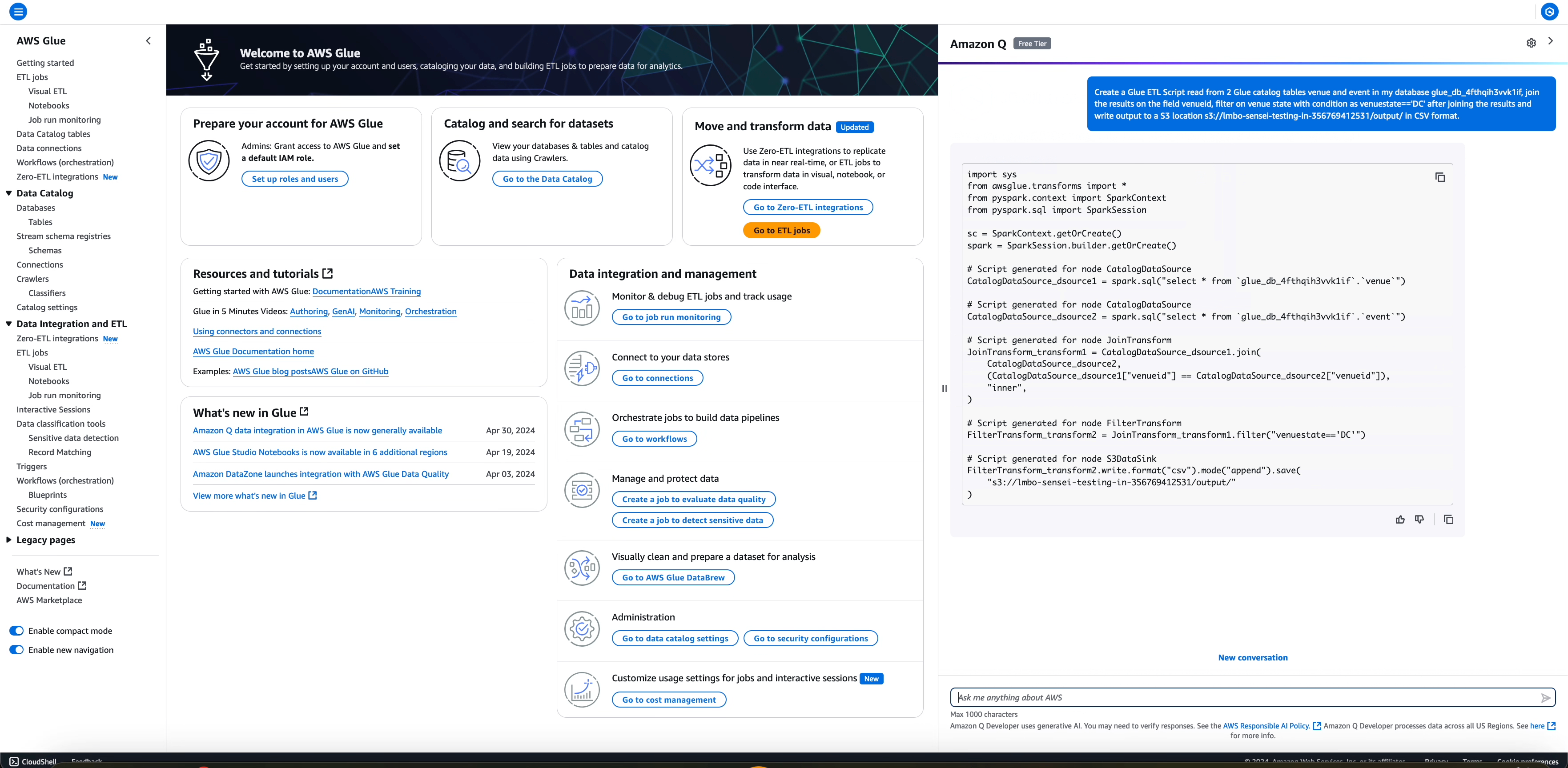
Il flusso di lavoro contiene la lettura da diverse fonti di dati (due tabelle AWS Glue Data Catalog) e un paio di trasformazioni dopo la lettura unendo il risultato di due letture, filtrando in base a determinate condizioni e scrivendo l'output trasformato in una destinazione Amazon S3 in formato. CSV
Il job generato inserirà le informazioni dettagliate relative all'origine dei dati, alla trasformazione e al funzionamento del sink con le informazioni corrispondenti estratte dalla domanda dell'utente, come di seguito.
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node CatalogDataSource
CatalogDataSource_dsource1 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`venue`")
# Script generated for node CatalogDataSource
CatalogDataSource_dsource2 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`event`")
# Script generated for node JoinTransform
JoinTransform_transform1 = CatalogDataSource_dsource1.join(
CatalogDataSource_dsource2,
(CatalogDataSource_dsource1["venueid"] == CatalogDataSource_dsource2["venueid"]),
"inner",
)
# Script generated for node FilterTransform
FilterTransform_transform2 = JoinTransform_transform1.filter("venuestate=='DC'")
# Script generated for node S3DataSink
FilterTransform_transform2.write.format("csv").mode("append").save(
"s3://amz-s3-demo-bucket/output//output/"
)
L'esempio seguente dimostra come è possibile chiedere a AWS Glue di creare uno script AWS Glue per completare un ETL flusso di lavoro completo con il seguente prompt:. Create a AWS Glue ETL Script read from two AWS Glue Data Catalog tables venue and event in my database
glue_db_4fthqih3vvk1if, join the results on the field venueid, filter on venue state with condition as venuestate=='DC'
after joining the results and write output to an Amazon S3 S3 location s3://amz-s3-demo-bucket/output/ in CSV format
Il flusso di lavoro contiene la lettura da diverse fonti di dati (due tabelle AWS Glue Data Catalog) e un paio di trasformazioni dopo la lettura unendo il risultato di due letture, filtrando in base a determinate condizioni e scrivendo l'output trasformato in una destinazione Amazon S3 in formato. CSV
Il job generato inserirà le informazioni dettagliate relative all'origine dei dati, alla trasformazione e al funzionamento del sink con le informazioni corrispondenti estratte dalla domanda dell'utente, come di seguito.
import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession.builder.getOrCreate()
# Script generated for node CatalogDataSource
CatalogDataSource_dsource1 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`venue`")
# Script generated for node CatalogDataSource
CatalogDataSource_dsource2 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`event`")
# Script generated for node JoinTransform
JoinTransform_transform1 = CatalogDataSource_dsource1.join(
CatalogDataSource_dsource2,
(CatalogDataSource_dsource1["venueid"] == CatalogDataSource_dsource2["venueid"]),
"inner",
)
# Script generated for node FilterTransform
FilterTransform_transform2 = JoinTransform_transform1.filter("venuestate=='DC'")
# Script generated for node S3DataSink
FilterTransform_transform2.write.format("csv").mode("append").save(
"s3://amz-s3-demo-bucket/output//output/"
) Limitazioni
-
Riporto contestuale:
-
La funzionalità di riconoscimento del contesto riprende solo il contesto della precedente query dell'utente all'interno della stessa conversazione. Non mantiene il contesto oltre l'interrogazione immediatamente precedente.
-
-
Support per le configurazioni dei nodi:
-
Attualmente, la consapevolezza del contesto supporta solo un sottoinsieme delle configurazioni richieste per vari nodi.
-
Il supporto per i campi opzionali è previsto nelle prossime versioni.
-
-
Disponibilità:
-
La consapevolezza del contesto e DataFrame il supporto sono disponibili nei notebook Q Chat e SageMaker Unified Studio. Tuttavia, queste funzionalità non sono ancora disponibili nei notebook AWS Glue Studio.
-
