Avviso di fine del supporto: il 7 ottobre 2026,AWS il supporto per.AWS IoT Greengrass Version 1 Dopo il 7 ottobre 2026, non potrai più accedere alle risorse.AWS IoT Greengrass V1 Per ulteriori informazioni, visita Migrate from.AWS IoT Greengrass Version 1
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esecuzione dell'inferenza di Machine Learning
Questa funzionalità è disponibile per AWS IoT Greengrass Core v1.6 o versioni successive.
Con AWS IoT Greengrass, puoi eseguire inferenze di machine learning (ML) all'edge su dati generati localmente utilizzando modelli addestrati sul cloud. In questo modo si beneficia della bassa latenza e dei risparmi sui costi dell'inferenza locale e si sfrutta la potenza del cloud computing per modelli di formazione ed elaborazioni complesse.
Per iniziare eseguendo un'inferenza locale, consulta Come configurare l'inferenza dell'apprendimento automatico utilizzando Console di gestione AWS.
In che modo AWS IoT Greengrass L'inferenza ML funziona
Puoi addestrare i tuoi modelli di inferenza ovunque, distribuirli localmente come risorse di machine learning in un gruppo Greengrass e quindi accedervi dalle funzioni di Greengrass Lambda. Ad esempio, puoi creare e addestrare modelli di deep learning nell'SageMaker intelligenza artificiale
Il diagramma seguente mostra il flusso di lavoro di inferenza AWS IoT Greengrass ML.
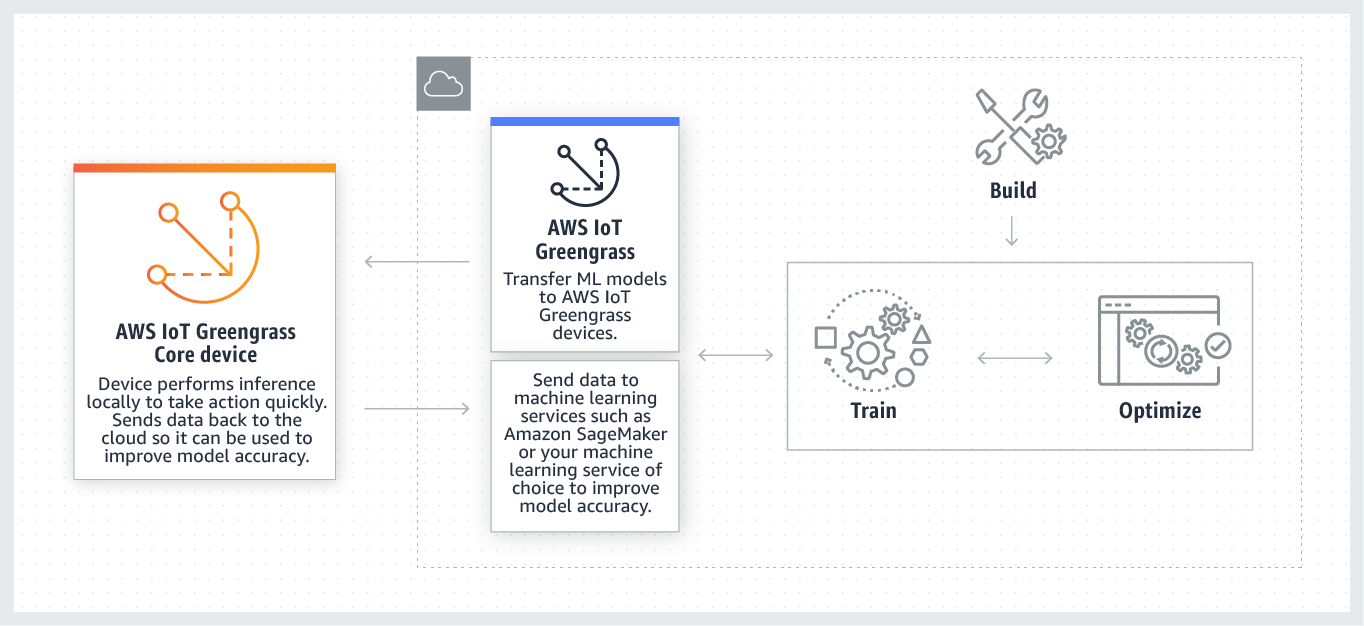
AWS IoT Greengrass L'inferenza ML semplifica ogni fase del flusso di lavoro ML, tra cui:
-
Sviluppo e distribuzione di prototipi di framework di Machine Learning.
-
Accesso a modelli qualificati per il cloud e distribuzione sui dispositivi core Greengrass.
-
Creazione di app di inferenza che possono accedere agli accelerator di hardware (come GPU e FPGA) come risorse locali.
Risorse di Machine Learning
Le risorse di machine learning rappresentano modelli di inferenza addestrati sul cloud che vengono implementati a livello centrale. AWS IoT Greengrass Per distribuire risorse di machine learning, aggiungete innanzitutto le risorse a un gruppo Greengrass, quindi definite in che modo le funzioni Lambda del gruppo possono accedervi. Durante la distribuzione di gruppo, AWS IoT Greengrass recupera i pacchetti del modello sorgente dal cloud e li estrae nelle directory all'interno dello spazio dei nomi di runtime Lambda. Quindi, le funzioni Greengrass Lambda utilizzano i modelli distribuiti localmente per eseguire l'inferenza.
Per aggiornare un modello distribuito localmente, aggiornare prima il modello di origine (nel cloud) che corrisponde alla risorsa di Machine Learning, quindi distribuire il gruppo. Durante la distribuzione, AWS IoT Greengrass controlla l'origine delle modifiche. Se vengono rilevate modifiche, AWS IoT Greengrass aggiorna il modello locale.
Origini di modello supportate
AWS IoT Greengrass supporta sorgenti di modelli SageMaker AI e Amazon S3 per risorse di apprendimento automatico.
I seguenti requisiti si applicano alle origini di modello:
-
I bucket S3 che memorizzano le sorgenti del modello SageMaker AI e Amazon S3 non devono essere crittografati utilizzando. SSE-C Per i bucket che utilizzano la crittografia lato server, l'inferenza AWS IoT Greengrass ML attualmente supporta solo le opzioni di crittografia or. SSE-S3 SSE-KMS Per ulteriori informazioni sulle opzioni di crittografia lato server, consulta Protezione dei dati utilizzando la crittografia lato server nella Guida per l'utente di Amazon Simple Storage Service.
-
I nomi dei bucket S3 che memorizzano le fonti dei modelli SageMaker AI e Amazon S3 non devono includere periodi ().
.Per ulteriori informazioni, consulta la regola sull'utilizzo di bucket in stile host virtuale con SSL nelle Regole per la denominazione dei bucket nella Amazon Simple Storage Service User Guide. -
Service-level Regione AWS il supporto deve essere disponibile sia per l'IA che per l'intelligenza artificiale. AWS IoT GreengrassSageMaker Attualmente, AWS IoT Greengrass supporta modelli di SageMaker intelligenza artificiale nelle seguenti regioni:
-
Stati Uniti orientali (Ohio)
-
Stati Uniti orientali (Virginia settentrionale)
-
Stati Uniti occidentali (Oregon)
-
Asia Pacifico (Mumbai)
-
Asia Pacifico (Seoul)
-
Asia Pacifico (Singapore)
-
Asia Pacifico (Sydney)
-
Asia Pacifico (Tokyo)
-
Europa (Francoforte)
-
Europa (Irlanda)
-
Europa (Londra)
-
-
AWS IoT Greengrass deve avere l'
readautorizzazione alla fonte del modello, come descritto nelle sezioni seguenti.
- SageMaker INTELLIGENZA ARTIFICIALE
-
AWS IoT Greengrass supporta modelli che vengono salvati come lavori di formazione sull' SageMaker intelligenza artificiale. SageMaker L'intelligenza artificiale è un servizio di machine learning completamente gestito che puoi utilizzare per creare e addestrare modelli utilizzando algoritmi integrati o personalizzati. Per ulteriori informazioni, consulta Cos'è l' SageMaker IA? nella Guida per sviluppatori di SageMaker intelligenza artificiale.
Se hai configurato il tuo ambiente di SageMaker intelligenza artificiale creando un bucket il cui nome contiene
sagemaker, allora AWS IoT Greengrass disponi delle autorizzazioni sufficienti per accedere ai tuoi lavori di formazione sull' SageMaker intelligenza artificiale. La policy gestitaAWSGreengrassResourceAccessRolePolicyconsente di accedere ai bucket il cui nome contiene la stringasagemaker. Questa policy è collegata al ruolo di servizio Greengrass.Altrimenti, devi concedere l' AWS IoT Greengrass
readautorizzazione al bucket in cui è archiviato il tuo lavoro di formazione. Per effettuare questa operazione, inserisci la seguente policy inline nel ruolo di servizio. È possibile elencare più ARN del bucket. - Amazon S3
-
AWS IoT Greengrass supporta modelli archiviati in Amazon S3 come file
tar.gzo.zip.Per consentire l'accesso AWS IoT Greengrass ai modelli archiviati nei bucket Amazon S3, devi concedere l' AWS IoT Greengrass
readautorizzazione ad accedere ai bucket effettuando una delle seguenti operazioni:-
Archivia il modello in un bucket il cui nome contiene
greengrass.La policy gestita
AWSGreengrassResourceAccessRolePolicyconsente di accedere ai bucket il cui nome contiene la stringagreengrass. Questa policy è collegata al ruolo di servizio Greengrass. -
Incorpora una policy inline nel ruolo di servizio Greengrass.
Se il nome del bucket non contiene
greengrass, aggiungi le seguenti policy inline al ruolo di servizio. È possibile elencare più ARN del bucket.Per ulteriori informazioni, consulta Incorporare politiche in linea nella IAM User Guide.
-
Requisiti
I seguenti requisiti si applicano alla creazione e all'utilizzo di risorse di Machine Learning:
-
È necessario utilizzare AWS IoT Greengrass Core v1.6 o versione successiva.
-
User-defined Le funzioni Lambda possono eseguire
readread and writeoperazioni sulla risorsa. Le autorizzazioni per altre operazioni non sono disponibili. La modalità di containerizzazione delle funzioni Lambda affiliate determina il modo in cui si impostano le autorizzazioni di accesso. Per ulteriori informazioni, consulta Accedi alle risorse di machine learning dalle funzioni Lambda. -
È necessario fornire il percorso completo della risorsa sul sistema operativo del dispositivo core.
-
Un nome o ID di risorsa deve avere un massimo di 128 caratteri e deve utilizzare il modello
[a-zA-Z0-9:_-]+.
Runtime e librerie per inferenza ML
È possibile utilizzare i seguenti runtime e librerie ML con. AWS IoT Greengrass
-
Apache MXNet
-
TensorFlow
Questi runtime e queste librerie possono essere installati sulle piattaforme NVIDIA Jetson TX2, Intel Atom e Raspberry Pi. Per informazioni di download, consulta Runtime e librerie di Machine Learning supportati. Puoi installarli direttamente sul dispositivo principale.
Assicurati di leggere le seguenti informazioni sulla compatibilità e sulle limitazioni.
SageMaker Runtime di deep learning AI Neo
Puoi utilizzare il runtime di deep learning SageMaker AI Neo per eseguire inferenze con modelli di machine learning ottimizzati sui tuoi AWS IoT Greengrass dispositivi. Questi modelli sono ottimizzati utilizzando il compilatore di deep learning SageMaker AI Neo per migliorare la velocità di previsione dell'inferenza dell'apprendimento automatico. Per ulteriori informazioni sull'ottimizzazione dei modelli nell' SageMaker intelligenza artificiale, consulta la documentazione di SageMaker AI Neo.
Nota
Attualmente, puoi ottimizzare i modelli di machine learning utilizzando il compilatore di deep learning Neo solo in specifiche regioni di Amazon Web Services. Tuttavia, puoi utilizzare il runtime di deep learning Neo con modelli ottimizzati in ognuna delle Regione AWS quali è supportato il AWS IoT Greengrass core. Per informazioni, consulta Come configurare l'inferenza Machine Learning ottimizzata.
Funzione Versioni multiple MXNet
Apache MXNet non garantisce attualmente la compatibilità con le versioni successive, quindi i modelli che si addestrano utilizzando versioni successive del framework potrebbero non funzionare correttamente nelle versioni precedenti del framework. Per evitare conflitti tra le fasi di model-training e model-serving e per fornire un'esperienza end-to-end coerente, utilizza la stessa versione del framework MXNet in entrambe le fasi.
MXNet su Raspberry Pi
Le funzioni Greengrass Lambda che accedono ai modelli MXNet locali devono impostare la seguente variabile di ambiente:
MXNET_ENGINE_TYPE=NativeEngine
È possibile impostare la variabile d'ambiente nel codice funzione o aggiungerla alla configurazione specifica del gruppo della funzione. Per un esempio in cui viene aggiunta come impostazione di configurazione, vedi questa fase.
Nota
Per un uso generale del framework MXNet, come l'esecuzione di un esempio di codice di terze parti, la variabile di ambiente deve essere configurata sul Raspberry Pi.
TensorFlow limitazioni relative al servizio dei modelli su Raspberry Pi
I seguenti consigli per migliorare i risultati di inferenza si basano sui nostri test con le librerie Arm TensorFlow a 32 bit sulla piattaforma Raspberry Pi. Queste raccomandazioni sono destinate a utenti esperti solo per riferimento, senza garanzie di alcun tipo.
-
Modelli che sono addestrati utilizzando il formato Checkpoint
devono essere "congelati" nel formato del buffer di protocollo prima di essere messi a disposizione. Per un esempio, consulta la libreria dei modelli di classificazione delle TensorFlow-Slim immagini . -
Non utilizzate le TF-Slim librerie TF-Estimator and né nel codice di addestramento né in quello di inferenza. Utilizzare invece il pattern di caricamento del modello di file
.pbche viene mostrato nell'esempio seguente.graph = tf.Graph() graph_def = tf.GraphDef() graph_def.ParseFromString(pb_file.read()) with graph.as_default(): tf.import_graph_def(graph_def)
Nota
Per ulteriori informazioni sulle piattaforme supportate per TensorFlow, consultate Installazione TensorFlow
