Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Cos'è Amazon Managed Service per Apache Flink?
Con Amazon Managed Service for Apache Flink, puoi usare Java, Scala, Python o SQL per elaborare e analizzare i dati in streaming. Il servizio consente di creare ed eseguire codice su sorgenti di streaming e fonti statiche per eseguire analisi di serie temporali, alimentare dashboard e metriche in tempo reale.
Puoi creare applicazioni con il linguaggio che preferisci in Managed Service for Apache Flink utilizzando librerie open source basate su Apache Flink.
Il servizio gestito per Apache Flink provvede alla creazione della struttura di base per le applicazioni Apache Flink. Gestisce funzionalità di base come il provisioning delle risorse di calcolo, la resilienza del failover AZ, il calcolo parallelo, la scalabilità automatica e i backup delle applicazioni (implementati come checkpoint e snapshot). È possibile utilizzare le funzionalità di programmazione di alto livello di Flink (che includono operatori, funzioni, origini e sink) nello stesso modo in cui le si utilizza quando si ospita l'infrastruttura Flink direttamente.
Decidi se utilizzare Managed Service per Apache Flink o Managed Service per Apache Flink Studio
Hai due opzioni per eseguire i tuoi job Flink con Amazon Managed Service for Apache Flink. Con Managed Service for Apache Flink, puoi creare applicazioni Flink in Java, Scala o Python (e SQL integrato) utilizzando un IDE di tua scelta e le API Apache Flink Datastream o Table. Con Managed Service for Apache Flink Studio, puoi interrogare in modo interattivo i flussi di dati in tempo reale e creare ed eseguire facilmente applicazioni di elaborazione dei flussi utilizzando SQL, Python e Scala standard.
Puoi selezionare il metodo più adatto al tuo caso d'uso. Se non sei sicuro, questa sezione ti offrirà una guida di alto livello per aiutarti.
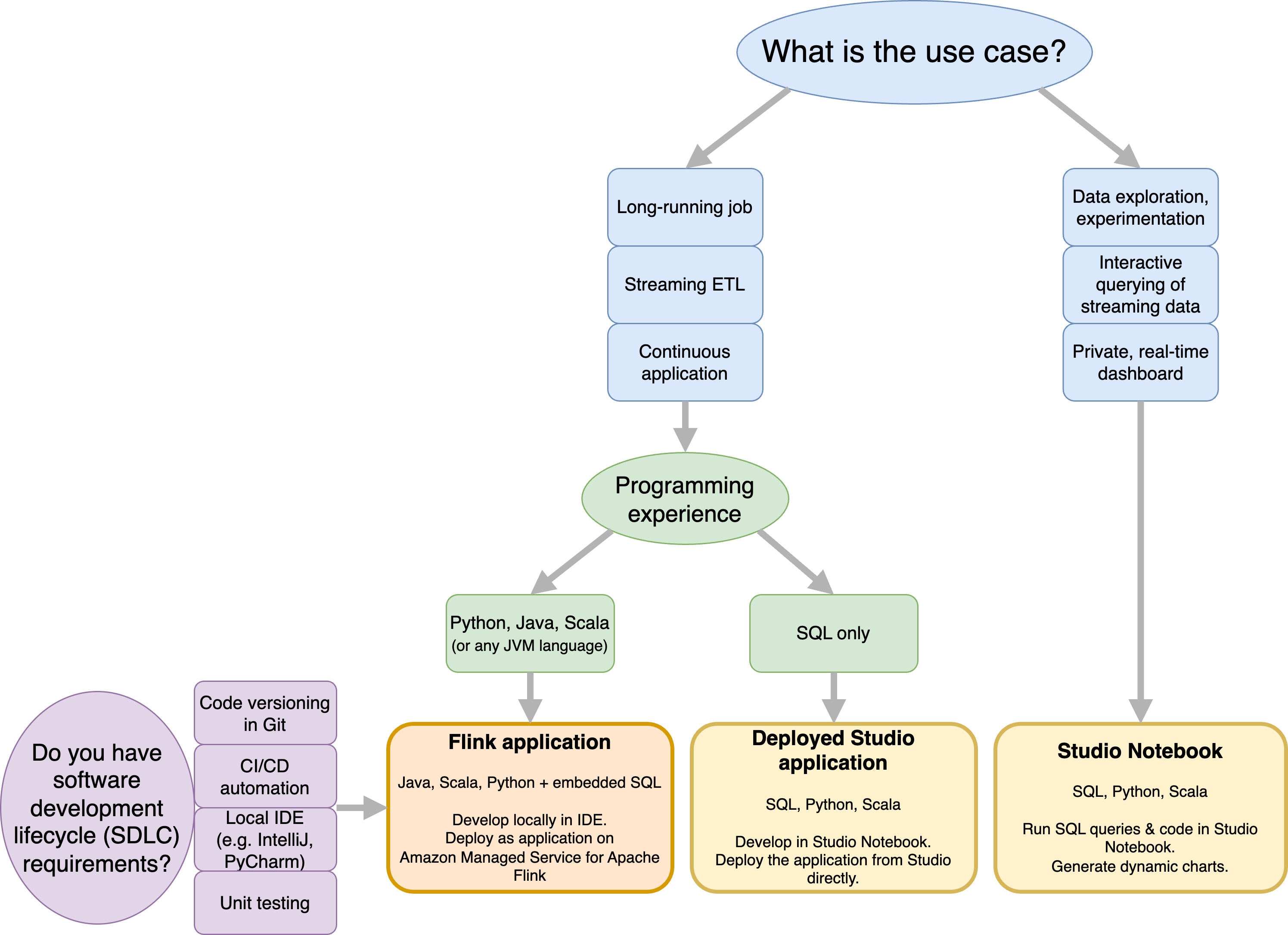
Prima di decidere se utilizzare Amazon Managed Service per Apache Flink o Amazon Managed Service per Apache Flink Studio, dovresti considerare il tuo caso d'uso.
Se prevedi di utilizzare un'applicazione a lunga durata che eseguirà carichi di lavoro come Streaming ETL o Continuous Applications, dovresti prendere in considerazione l'utilizzo di Managed Service for Apache Flink. Questo perché potete creare la vostra applicazione Flink utilizzando le API Flink direttamente nell'IDE di vostra scelta. Lo sviluppo locale con il tuo IDE ti consente inoltre di sfruttare processi e strumenti comuni del ciclo di vita dello sviluppo del software (SDLC), come il controllo delle versioni del codice in Git, CI/CD l'automazione o il test delle unità.
Se sei interessato all'esplorazione dei dati ad hoc, desideri interrogare i dati di streaming in modo interattivo o creare dashboard private in tempo reale, Managed Service for Apache Flink Studio ti aiuterà a raggiungere questi obiettivi in pochi clic. Gli utenti che hanno familiarità con SQL possono prendere in considerazione la distribuzione di un'applicazione a lunga durata direttamente da Studio.
Nota
Puoi promuovere il tuo notebook Studio a un'applicazione a lunga durata. Tuttavia, se desideri integrarti con i tuoi strumenti SDLC come il controllo delle versioni del codice su Git e CI/CD l'automazione, o tecniche come il test delle unità, ti consigliamo Managed Service for Apache Flink utilizzando l'IDE di tua scelta.
Scegliete quali API Apache Flink utilizzare in Managed Service for Apache Flink
Puoi creare applicazioni utilizzando Java, Python e Scala in Managed Service for Apache Flink utilizzando le API Apache Flink in un IDE di tua scelta. Puoi trovare indicazioni su come creare applicazioni utilizzando le API Flink Datastream e Table nella documentazione. È possibile selezionare la lingua in cui creare l'applicazione Flink e le API da utilizzare per soddisfare al meglio le esigenze dell'applicazione e delle operazioni. Se non siete sicuri, questa sezione fornisce una guida di alto livello per aiutarvi.
Scegli un'API Flink
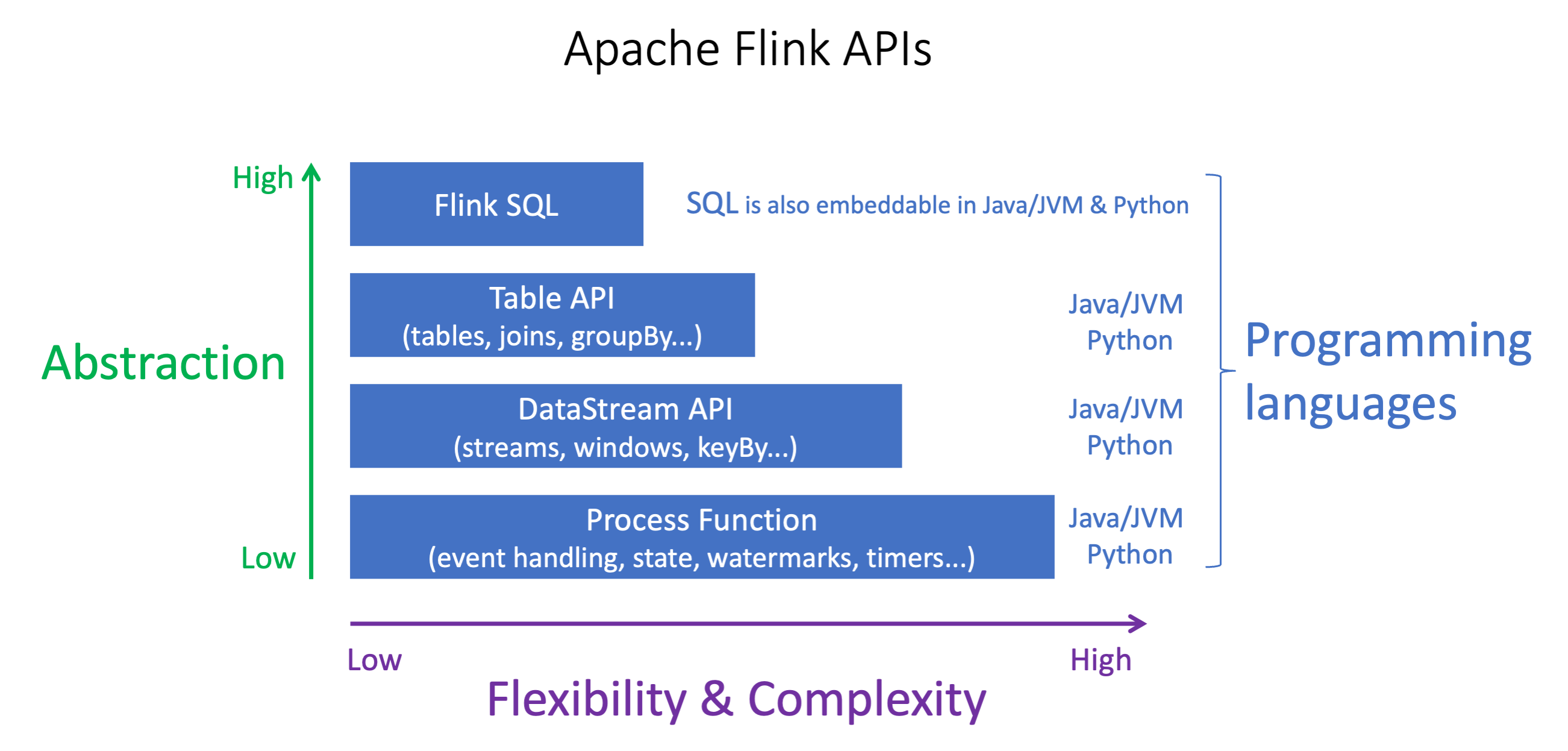
Le API Apache Flink hanno diversi livelli di astrazione che possono influire sul modo in cui decidi di creare la tua applicazione. Sono espressive e flessibili e possono essere utilizzate insieme per creare un'applicazione. Non è necessario utilizzare una sola API Flink. Puoi saperne di più sulle API Flink nella documentazione di Apache Flink.
Flink offre quattro livelli di astrazione delle API: Flink SQL, Table API, DataStream API e Process Function, che viene utilizzata insieme all'API. DataStream Sono tutte supportate in Amazon Managed Service for Apache Flink. È consigliabile iniziare con un livello di astrazione più elevato ove possibile, tuttavia alcune funzionalità di Flink sono disponibili solo con l'API Datastream in cui è possibile creare l'applicazione in Java, Python o Scala. Dovresti prendere in considerazione l'utilizzo dell'API Datastream se:
È necessario un controllo granulare sullo stato
Desiderate sfruttare la possibilità di chiamare un database o un endpoint esterno in modo asincrono (ad esempio per l'inferenza)
Desiderate utilizzare timer personalizzati (ad esempio per implementare finestre personalizzate o la gestione degli eventi tardivi)
-
Vuoi essere in grado di modificare il flusso della tua applicazione senza reimpostare lo stato
Nota
Scelta di una lingua con l'API: DataStream
SQL può essere incorporato in qualsiasi applicazione Flink, indipendentemente dal linguaggio di programmazione scelto.
Se hai intenzione di utilizzare l' DataStream API, non tutti i connettori sono supportati in Python.
Se hai bisogno di un latency/high throughput basso, dovresti prendere in considerazione Java/Scala indipendentemente dall'API.
Se prevedi di utilizzare Async IO nell'API Process Functions, dovrai usare Java.
La scelta dell'API può influire anche sulla capacità di far evolvere la logica dell'applicazione senza dover reimpostare lo stato. Ciò dipende da una funzionalità specifica, la possibilità di impostare l'UID sugli operatori, disponibile solo nell'DataStreamAPI per Java e Python. Per ulteriori informazioni, consulta Impostare gli UUID per tutti gli operatori
Inizia con le applicazioni di streaming di dati
Innanzitutto, è consigliabile creare un'applicazione del servizio gestito per Apache Flink che legga ed elabori in maniera continua i dati in streaming. In seguito, consigliamo di scrivere il codice utilizzando l'ambiente di sviluppo integrato (IDE) prescelto ed effettuare test con i dati di streaming live. È inoltre possibile configurare le destinazioni a cui si desidera che il servizio gestito per Apache Flink invii i risultati.
Per iniziare, consigliamo di consultare le sezioni seguenti:
In alternativa, puoi iniziare creando un notebook Managed Service for Apache Flink Studio che ti permetta di interrogare interattivamente i flussi di dati in tempo reale e di creare ed eseguire facilmente applicazioni di elaborazione dei flussi utilizzando SQL, Python e Scala standard. Con pochi clic Console di gestione AWS, puoi avviare un notebook serverless per interrogare i flussi di dati e ottenere risultati in pochi secondi. Per iniziare, consigliamo di consultare le sezioni seguenti:
