Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Integrazione delle pipeline OpenSearch di Amazon Ingestion con altri servizi e applicazioni
Per inserire correttamente i dati in una pipeline di Amazon OpenSearch Ingestion, devi configurare l'applicazione client (la fonte) per inviare dati all'endpoint della pipeline. La tua fonte potrebbe essere client come Fluent Bit logs, Collector o un semplice bucket S3. OpenTelemetry La configurazione esatta è diversa per ogni client.
Le differenze importanti durante la configurazione dell'origine (rispetto all'invio di dati direttamente a un dominio di OpenSearch servizio o a una raccolta OpenSearch Serverless) sono il nome del AWS servizio (osis) e l'endpoint host, che deve essere l'endpoint della pipeline.
Costruzione dell'endpoint di ingestione
Per importare dati in una pipeline, inviateli all'endpoint di ingestione. Per individuare l'URL di importazione, accedete alla pagina delle impostazioni della pipeline e copiate l'URL di ingestione.
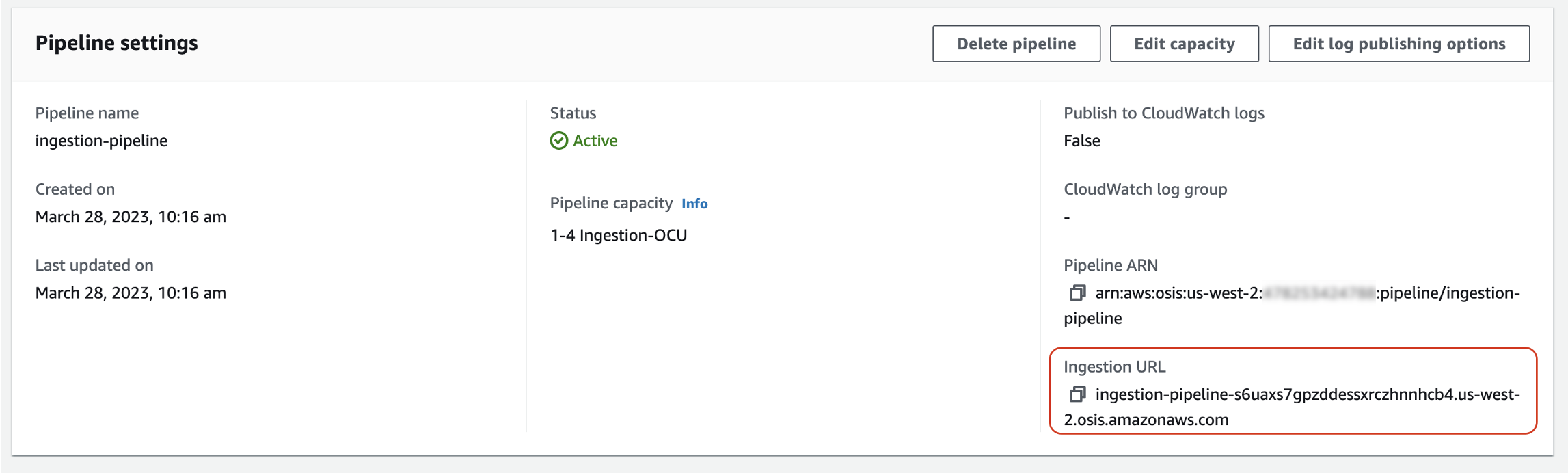
Per creare l'endpoint di ingestione completo per sorgenti basate su pull come Otel trace e Otel
Ad esempio, supponiamo che la configurazione della pipeline abbia il seguente percorso di inserimento:

L'endpoint di ingestione completo, specificato nella configurazione del client, assumerà il seguente formato:. https://ingestion-pipeline-abcdefg.us-east-1.osis.amazonaws.com/my/test_path
Creazione di un ruolo di importazione
Tutte le richieste di OpenSearch Ingestion devono essere firmate con Signature Version 4. Al ruolo che firma la richiesta deve essere almeno concessa l'autorizzazione per l'osis:Ingestazione, che gli consente di inviare dati a una pipeline di OpenSearch Ingestion.
Ad esempio, la seguente policy AWS Identity and Access Management (IAM) consente al ruolo corrispondente di inviare dati a una singola pipeline:
Nota
Per utilizzare il ruolo per tutte le pipeline, sostituite l'ARN Resource nell'elemento con un carattere jolly (*).
Fornire l'accesso all'importazione su più account
Nota
Puoi fornire l'accesso all'ingestione tra account solo per le pipeline pubbliche, non per le pipeline VPC.
Potrebbe essere necessario importare dati in una pipeline da un altro Account AWS, ad esempio un account che ospita l'applicazione di origine. Se il principale che sta scrivendo su una pipeline si trova in un account diverso rispetto alla pipeline stessa, devi configurarlo in modo che si fidi di un altro ruolo IAM per l'inserimento dei dati nella pipeline.
Per configurare le autorizzazioni di importazione tra più account
-
Crea il ruolo di ingestione con
osis:Ingestautorizzazione (descritto nella sezione precedente) all'interno della stessa pipeline. Account AWS Per istruzioni, consulta Creazione di ruoli IAM. -
Allega una politica di fiducia al ruolo di inserimento che consenta a un responsabile di un altro account di assumerlo:
-
Nell'altro account, configura l'applicazione client (ad esempio, Fluent Bit) per assumere il ruolo di importazione. Affinché ciò funzioni, l'account dell'applicazione deve concedere le autorizzazioni all'utente o al ruolo dell'applicazione per assumere il ruolo di ingestione.
L'esempio seguente di politica basata sull'identità consente al principale allegato di assumere dall'account della pipeline:
ingestion-role
L'applicazione client può quindi utilizzare l'AssumeRoleoperazione per assumere ingestion-role e importare dati nella pipeline associata.
Fasi successive
Dopo aver esportato i dati in una pipeline, puoi interrogarli dal dominio di OpenSearch servizio configurato come sink per la pipeline. Le seguenti risorse possono aiutarti a iniziare:
