Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: Inserimento di dati in una raccolta con Amazon Ingestion OpenSearch
Questo tutorial mostra come usare Amazon OpenSearch Ingestion per configurare una pipeline semplice e inserire dati in una raccolta Amazon Serverless. OpenSearch Una pipeline è una risorsa che Ingestion fornisce e gestisce. OpenSearch È possibile utilizzare una pipeline per filtrare, arricchire, trasformare, normalizzare e aggregare i dati per l'analisi e la visualizzazione a valle in Service. OpenSearch
Per un tutorial che dimostra come inserire dati in un dominio di servizio fornito, consulta. OpenSearch Tutorial: importazione di dati in un dominio utilizzando Amazon Ingestion OpenSearch
Completerai i seguenti passaggi in questo tutorial:.
All'interno del tutorial, creerai le seguenti risorse:
-
Una raccolta denominata su
ingestion-collectioncui la pipeline scriverà -
Una pipeline denominata
ingestion-pipeline-serverless
Autorizzazioni richieste
Per completare questo tutorial, l'utente o il ruolo deve avere una politica basata sull'identità allegata con le seguenti autorizzazioni minime. Queste autorizzazioni consentono di creare un ruolo di pipeline e allegare una policy (iam:Create*eiam:Attach*), creare o modificare una raccolta () e lavorare con aoss:* pipelines (). osis:*
Inoltre, sono necessarie diverse autorizzazioni IAM per creare automaticamente il ruolo della pipeline e passarlo a OpenSearch Ingestion in modo che possa scrivere dati nella raccolta.
Fase 1: Creare una raccolta
Innanzitutto, crea una raccolta in cui inserire i dati. Daremo un nome alla raccoltaingestion-collection.
-
Accedi alla console di Amazon OpenSearch Service all'indirizzo https://console.aws.amazon.com/aos/home
. -
Scegli Raccolte dalla barra di navigazione a sinistra e scegli Crea raccolta.
-
Nel campo Generazione serverless, scegli Passa alla versione classica.
-
Assegna un nome alla raccolta ingestion-collection.
-
Per Sicurezza, scegliete Standard create.
-
In Impostazioni di accesso alla rete, modifica il tipo di accesso in Pubblico.
-
Mantenere tutte le altre impostazioni come valori predefiniti e scegliere Successivo.
-
Ora configura una politica di accesso ai dati per la raccolta. Deseleziona Abbina automaticamente le impostazioni dei criteri di accesso.
-
Per il metodo di definizione, scegli JSON e incolla la seguente politica nell'editor. Questa politica fa due cose:
-
Consente al ruolo della pipeline di scrivere nella raccolta.
-
Consente di leggere i contenuti della raccolta. Successivamente, dopo aver inserito alcuni dati di esempio nella pipeline, interrogherete la raccolta per assicurarvi che i dati siano stati inseriti e scritti correttamente nell'indice.
[ { "Rules": [ { "Resource": [ "index/ingestion-collection/*" ], "Permission": [ "aoss:CreateIndex", "aoss:UpdateIndex", "aoss:DescribeIndex", "aoss:ReadDocument", "aoss:WriteDocument" ], "ResourceType": "index" } ], "Principal": [ "arn:aws:iam::your-account-id:role/OpenSearchIngestion-PipelineRole", "arn:aws:iam::your-account-id:role/Admin" ], "Description": "Rule 1" } ]
-
-
Modifica
Principalgli elementi per includere il tuo ID. Account AWS Per il secondo principale, specificate un utente o un ruolo che potete utilizzare per interrogare la raccolta in un secondo momento. -
Scegli Next (Successivo). Assegna un nome alla politica di accesso pipeline-collection-access e scegli nuovamente Avanti.
-
Rivedi la configurazione della raccolta e scegli Submit (Invia).
Fase 2: Creare una pipeline
Ora che hai una collezione, puoi creare una pipeline.
Come creare una pipeline
-
Nella console di Amazon OpenSearch Service, scegli Pipelines dal riquadro di navigazione a sinistra.
-
Scegliere Create pipeline (Crea pipeline).
-
Seleziona la pipeline vuota, quindi scegli Seleziona blueprint.
-
In questo tutorial, creeremo una semplice pipeline che utilizza il plug-in di origine HTTP
. Il plugin accetta i dati di registro in un formato di matrice JSON. Specificheremo una singola raccolta OpenSearch Serverless come sink e inseriremo tutti i dati nell'indice. my_logsNel menu Sorgente, scegli HTTP. Per il percorso, inserisci /logs.
-
Per semplicità, in questo tutorial, configureremo l'accesso pubblico alla pipeline. Per le opzioni di rete di origine, scegli Accesso pubblico. Per informazioni sulla configurazione dell'accesso al VPC, vedere. Configurazione dell'accesso VPC per le pipeline di Amazon Ingestion OpenSearch
-
Scegli Next (Successivo).
-
Per Processore, inserisci Data e scegli Aggiungi.
-
Abilita A partire dall'ora di ricezione. Lascia tutte le altre impostazioni come predefinite.
-
Scegli Next (Successivo).
-
Configura i dettagli del lavandino. Per il tipo di OpenSearch risorsa, scegli Collection (Serverless). Quindi scegli la raccolta OpenSearch di servizi che hai creato nella sezione precedente.
Lasciate il nome della politica di rete come predefinito. Per il nome dell'indice, inserisci my_logs. OpenSearch Ingestion crea automaticamente questo indice nella raccolta se non esiste già.
-
Scegli Next (Successivo).
-
Assegna un nome alla pipeline ingestion-pipeline-serverless. Lasciate le impostazioni di capacità come predefinite.
-
Per il ruolo Pipeline, seleziona Crea e usa un nuovo ruolo di servizio. Il ruolo pipeline fornisce le autorizzazioni necessarie affinché una pipeline possa scrivere nel sink di raccolta e leggere da fonti basate su pull. Selezionando questa opzione, OpenSearch consenti a Ingestion di creare il ruolo per te, anziché crearlo manualmente in IAM. Per ulteriori informazioni, consulta Configurazione di ruoli e utenti in Amazon OpenSearch Ingestion.
-
Per il suffisso del nome del ruolo di servizio, immettere. PipelineRole In IAM, il ruolo avrà il seguente formato
arn:aws:iam::.your-account-id:role/OpenSearchIngestion-PipelineRole -
Scegli Next (Successivo). Controlla la configurazione della pipeline e scegli Crea pipeline. La pipeline impiega 5-10 minuti per diventare attiva.
Fase 3: Inserimento di alcuni dati di esempio
Quando lo stato della pipeline è impostatoActive, puoi iniziare a importare dati al suo interno. È necessario firmare tutte le richieste HTTP alla pipeline utilizzando Signature Version 4. Utilizza uno strumento HTTP come Postman
Nota
Il principale che firma la richiesta deve disporre dell'autorizzazione IAM. osis:Ingest
Innanzitutto, ottieni l'URL di importazione dalla pagina delle impostazioni di Pipeline:
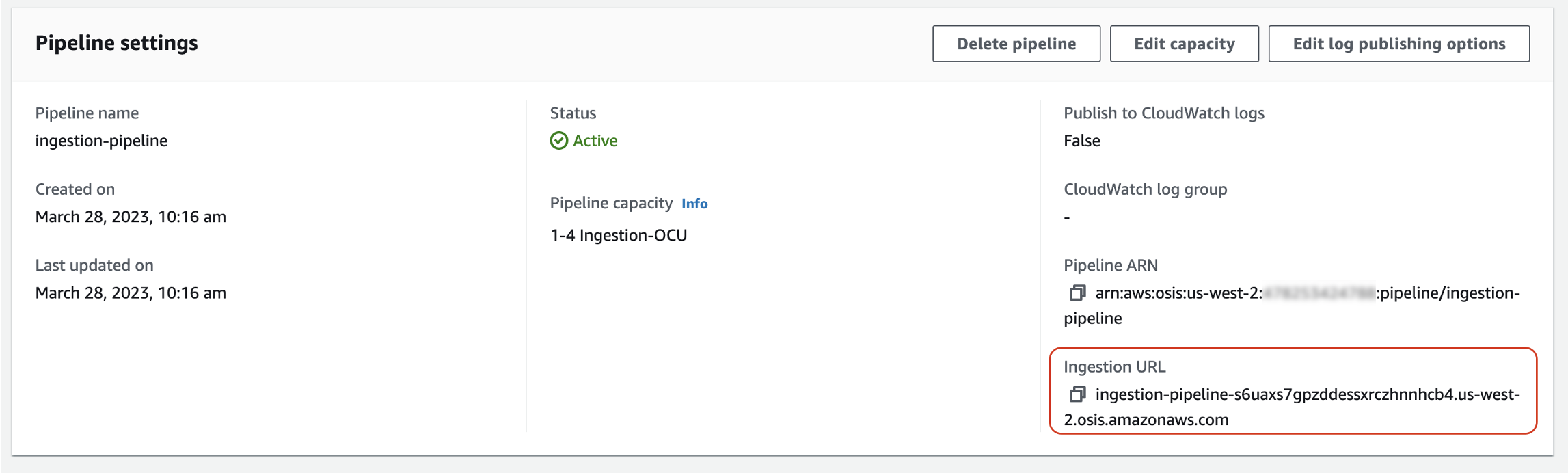
Quindi, invia alcuni dati di esempio al percorso di ingestione. La seguente richiesta di esempio utilizza awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
Dovresti vedere una risposta. 200 OK
Ora, interroga l'my_logsindice per assicurarti che la voce di registro sia stata inserita correttamente:
awscurl --service aoss --regionus-east-1\ -X GET \ https://collection-id.us-east-1.aoss.amazonaws.com/my_logs/_search | json_pp
Esempio di risposta:
{ "took":348, "timed_out":false, "_shards":{ "total":0, "successful":0, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"my_logs", "_id":"1%3A0%3ARJgDvIcBTy5m12xrKE-y", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2023-04-26T05:22:16.204Z" } } ] } }
Risorse correlate
Questo tutorial ha presentato un semplice caso d'uso di assimilazione di un singolo documento tramite HTTP. Negli scenari di produzione, configurerai le tue applicazioni client (come Fluent Bit, Kubernetes o OpenTelemetry Collector) per inviare dati a una o più pipeline. Le tue pipeline saranno probabilmente più complesse del semplice esempio di questo tutorial.
Per iniziare a configurare i client e ad acquisire dati, consulta le seguenti risorse:
