Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ottimizza gli shuffles
Alcune operazioni, come join() egroupByKey(), richiedono che Spark esegua uno shuffle. Lo shuffle è il meccanismo di Spark per ridistribuire i dati in modo che siano raggruppati in modo diverso tra le partizioni. RDD Lo shuffling può aiutare a rimediare ai problemi di prestazioni. Tuttavia, poiché lo shuffling in genere implica la copia dei dati tra gli esecutori Spark, lo shuffle è un'operazione complessa e costosa. Ad esempio, lo shuffle genera i seguenti costi:
-
I/O del disco:
-
Genera un gran numero di file intermedi su disco.
-
-
I/O di rete:
-
Richiede molte connessioni di rete (Numero di connessioni =
Mapper × Reducer). -
Poiché i record vengono aggregati in nuove RDD partizioni che potrebbero essere ospitate su un altro esecutore Spark, una parte sostanziale del set di dati potrebbe spostarsi tra gli esecutori Spark sulla rete.
-
-
CPUe carico di memoria:
-
Ordina i valori e unisce i set di dati. Queste operazioni sono pianificate sull'esecutore, con un carico pesante sull'esecutore.
-
Shuffle è uno dei fattori più importanti del peggioramento delle prestazioni dell'applicazione Spark. Durante la memorizzazione dei dati intermedi, può esaurire lo spazio sul disco locale dell'esecutore, causando il fallimento del job Spark.
Puoi valutare le tue prestazioni di shuffle nelle metriche e nell' CloudWatch interfaccia utente di Spark.
CloudWatch metriche
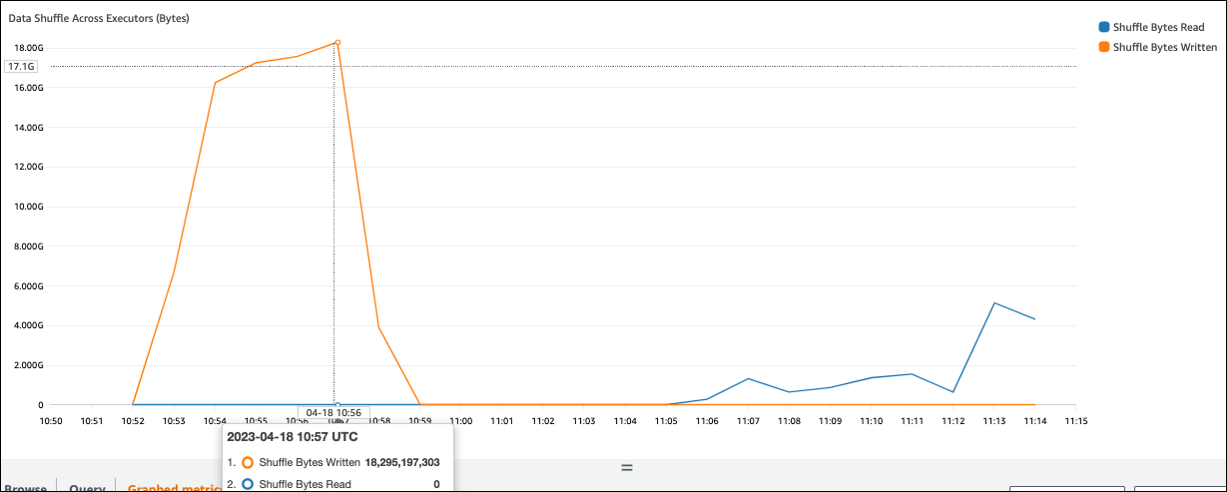
Se il valore Shuffle Bytes Written è elevato rispetto a Shuffle Bytes Read, il tuo job Spark potrebbe utilizzare operazioni di shuffle come o.join() groupByKey()
Interfaccia utente di Spark
Nella scheda Stage dell'interfaccia utente Spark, puoi controllare i valori di Shuffle Read Size/Records. Puoi vederlo anche nella scheda Executors.
Nella schermata seguente, ogni executor scambia circa 18,6 GB/4020.000 record con il processo shuffle, per una dimensione totale di lettura shuffle di circa 75 GB).
La colonna Shuffle Spill (Disk) mostra che una grande quantità di dati trasferisce memoria su disco, il che potrebbe causare un disco pieno o un problema di prestazioni.

Se osservate questi sintomi e la fase richiede troppo tempo rispetto agli obiettivi prestazionali prefissati, oppure fallisce con Out Of Memory No space
left on device errori, prendete in considerazione le seguenti soluzioni.
Ottimizza l'unione
L'join()operazione, che unisce le tabelle, è l'operazione di shuffle più comunemente utilizzata, ma è spesso un ostacolo alle prestazioni. Poiché l'unione è un'operazione costosa, si consiglia di non utilizzarla a meno che non sia essenziale per i requisiti aziendali. Ricontrolla che stai facendo un uso efficiente della tua pipeline di dati ponendoti le seguenti domande:
-
Stai ricalcolando un join che viene eseguito anche in altri lavori che puoi riutilizzare?
-
Vi state unendo per risolvere chiavi esterne relative a valori che non vengono utilizzati dai consumatori del vostro output?
Dopo aver verificato che le operazioni di join sono essenziali per i requisiti aziendali, consulta le seguenti opzioni per ottimizzare l'iscrizione in modo da soddisfare i requisiti.
Usa il pushdown prima di partecipare
Filtra le righe e le colonne non necessarie DataFrame prima di eseguire un join. Ciò presenta i seguenti vantaggi:
-
Riduce la quantità di dati trasferiti durante lo shuffle
-
Riduce la quantità di elaborazione nell'esecutore Spark
-
Riduce la quantità di dati da scansionare
# Default df_joined = df1.join(df2, ["product_id"]) # Use Pushdown df1_select = df1.select("product_id","product_title","star_rating").filter(col("star_rating")>=4.0) df2_select = df2.select("product_id","category_id") df_joined = df1_select.join(df2_select, ["product_id"])
Usa DataFrame Join
Prova a usare uno Spark di alto livello APIdyf.toDF() Come discusso nella sezione Argomenti chiave di Apache Spark, queste operazioni di unione sfruttano internamente l'ottimizzazione delle query mediante l'ottimizzatore Catalyst.
Mescola e trasmetti hash, join e suggerimenti
Spark supporta due tipi di join: shuffle join e broadcast hash join. Un broadcast hash join non richiede lo shuffling e può richiedere meno elaborazione rispetto a uno shuffle join. Tuttavia, è applicabile solo quando si unisce un tavolo piccolo a uno grande. Quando ti unisci a una tabella che può stare nella memoria di un singolo esecutore Spark, prendi in considerazione l'utilizzo di un broadcast hash join.
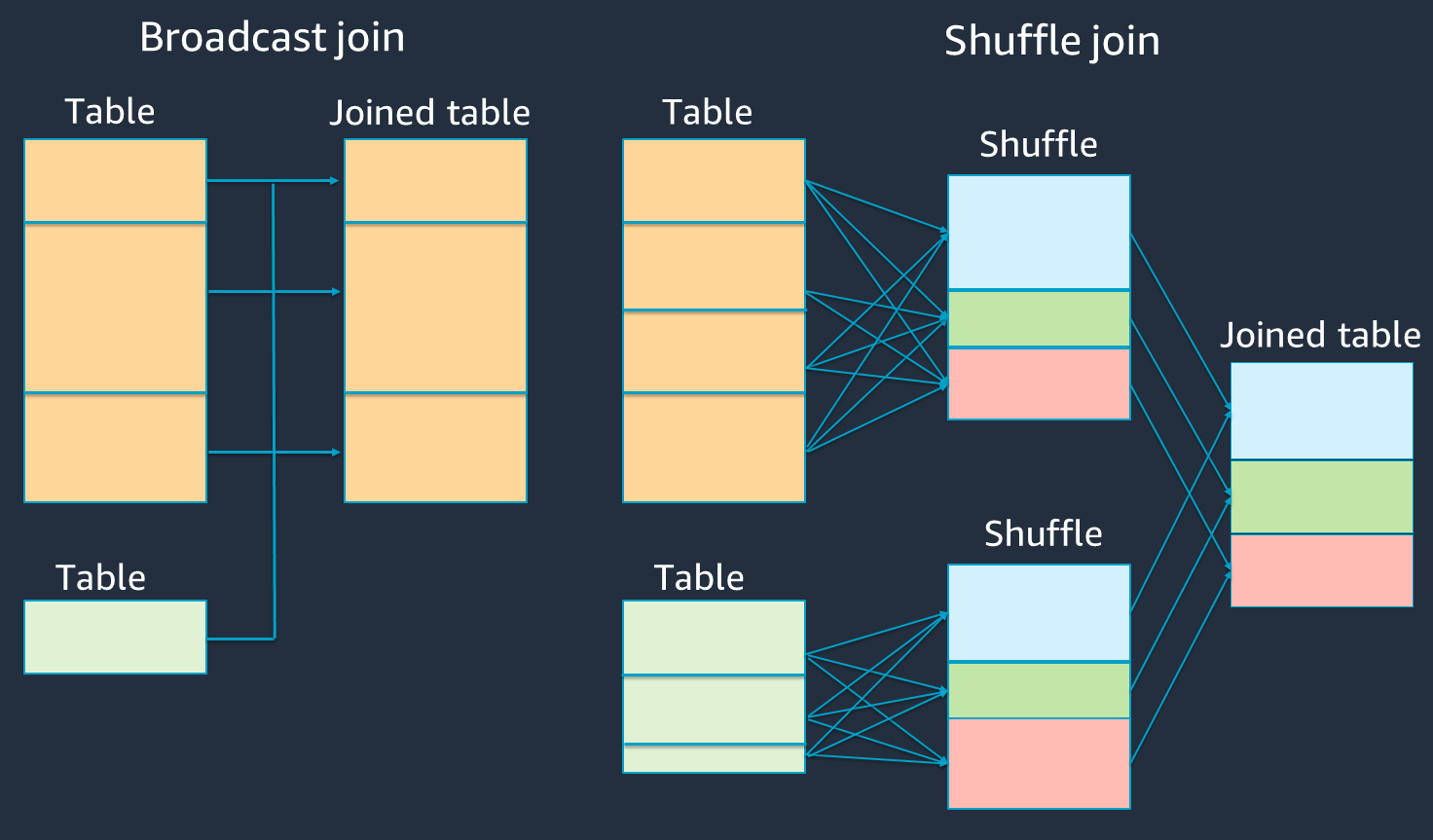
Il diagramma seguente mostra la struttura e le fasi di alto livello di un broadcast hash join e di uno shuffle join.
I dettagli di ogni join sono i seguenti:
-
Shuffle join:
-
Lo shuffle hash join unisce due tabelle senza ordinamento e distribuisce il join tra le due tabelle. È adatto per unire piccole tabelle che possono essere archiviate nella memoria dell'esecutore Spark.
-
Lo sort-merge join distribuisce le due tabelle da unire tramite chiave e le ordina prima di unirle. È adatto per unire tavoli di grandi dimensioni.
-
-
Broadcast hash join:
-
Un broadcast hash join invia il file più piccolo RDD o la tabella a ciascuno dei nodi di lavoro. Quindi esegue una combinazione sul lato della mappa con ogni partizione del più grande o della tabella. RDD
È adatto per i join quando uno dei tuoi tavoli può stare in memoria RDDs o può essere adattato per adattarsi alla memoria. È utile eseguire un hash join di trasmissione quando possibile, perché non richiede un shuffle. Puoi usare un hint di iscrizione per richiedere un join alla trasmissione da Spark come segue.
# DataFrame from pySpark.sql.functions import broadcast df_joined= df_big.join(broadcast(df_small), right_df[key] == left_df[key], how='inner') -- SparkSQL SELECT /*+ BROADCAST(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;Per maggiori informazioni sui suggerimenti per partecipare, vedi Join hints.
-
Nella AWS Glue versione 3.0 e successive, puoi sfruttare automaticamente i broadcast hash join abilitando Adaptive Query
Nella AWS Glue 3.0, è possibile abilitare Adaptive Query Execution impostando. spark.sql.adaptive.enabled=true L'esecuzione adattiva delle query è abilitata per impostazione predefinita in AWS Glue 4.0.
È possibile impostare parametri aggiuntivi relativi agli shuffle e agli hash join di trasmissione:
-
spark.sql.adaptive.localShuffleReader.enabled -
spark.sql.adaptive.autoBroadcastJoinThreshold
Per ulteriori informazioni sui parametri correlati, vedere Conversione di sort-merge
Nella AWS Glue versione 3.0 e versioni successive, puoi usare altri suggerimenti di join for shuffle per ottimizzare il tuo comportamento.
-- Join Hints for shuffle sort merge join SELECT /*+ SHUFFLE_MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGEJOIN(t2) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle hash join SELECT /*+ SHUFFLE_HASH(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle-and-replicate nested loop join SELECT /*+ SHUFFLE_REPLICATE_NL(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;
Usa il bucketing
Il sort-merge join richiede due fasi, shuffle e sort, quindi merge. Queste due fasi possono sovraccaricare l'esecutore Spark e causare problemi di prestazioni quando alcuni esecutori si uniscono OOM e altri si ordinano contemporaneamente. In questi casi, potrebbe essere possibile unirsi in modo efficiente utilizzando il bucketing.
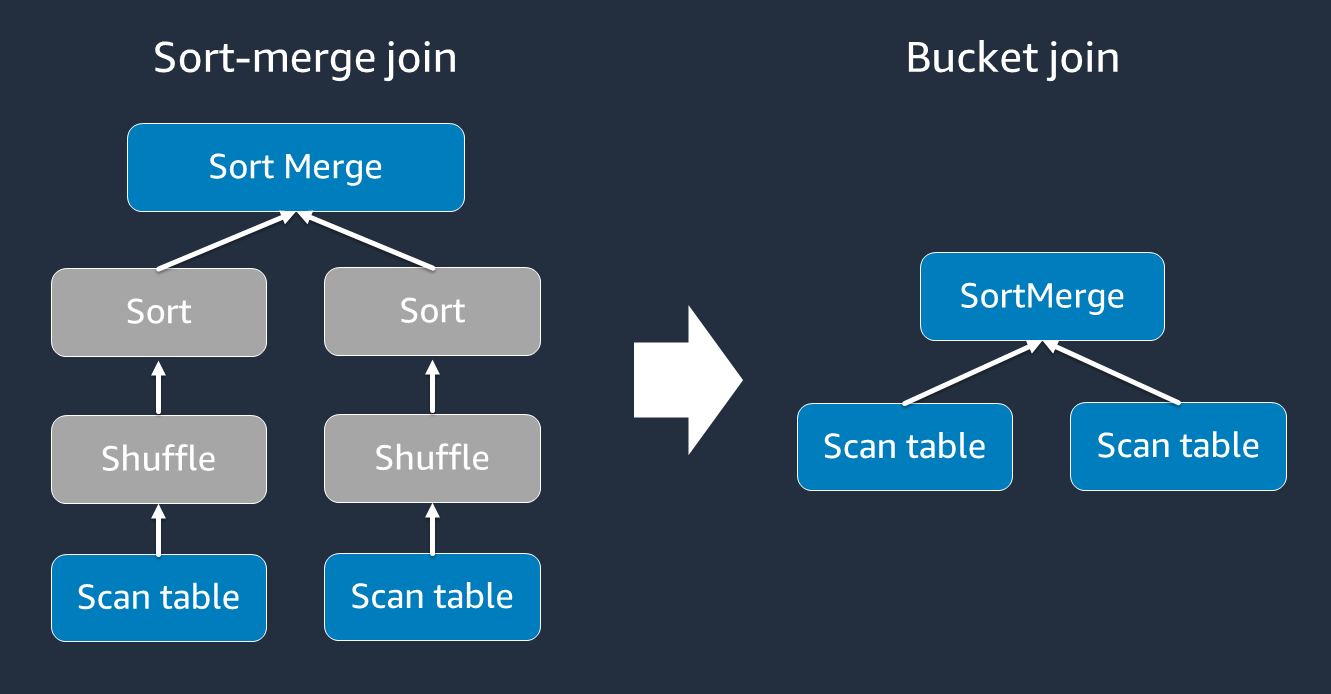
Le tabelle bucketed sono utili per quanto segue:
-
I dati vengono uniti frequentemente sulla stessa chiave, ad esempio
account_id -
Caricamento di tabelle cumulative giornaliere, ad esempio tabelle base e delta, che potrebbero essere inserite in una colonna comune
È possibile creare una tabella a blocchi utilizzando il codice seguente.
df.write.bucketBy(50, "account_id").sortBy("age").saveAsTable("bucketed_table")
Ripartizione delle DataFrames chiavi di unione prima dell'unione
Per ripartizionare le due chiavi DataFrames sulle chiavi di join prima del join, utilizzate le seguenti istruzioni.
df1_repartitioned = df1.repartition(N,"join_key") df2_repartitioned = df2.repartition(N,"join_key") df_joined = df1_repartitioned.join(df2_repartitioned,"product_id")
Questo ne partizionerà due (ancora separate) RDDs sulla chiave di unione prima di iniziare l'unione. Se i due record RDDs sono partizionati sulla stessa chiave e con lo stesso codice di partizionamento, è molto probabile che i RDD record che si intende unire vengano collocati insieme sullo stesso worker prima di procedere all'unione. Ciò potrebbe migliorare le prestazioni riducendo l'attività di rete e la distorsione dei dati durante l'unione.
Supera la distorsione dei dati
La distorsione dei dati è una delle cause più comuni di difficoltà per i lavori Spark. Si verifica quando i dati non sono distribuiti uniformemente tra le partizioni. RDD Ciò fa sì che le attività relative a quella partizione richiedano molto più tempo rispetto ad altre, ritardando il tempo di elaborazione complessivo dell'applicazione.
Per identificare la distorsione dei dati, valuta le seguenti metriche nell'interfaccia utente di Spark:
-
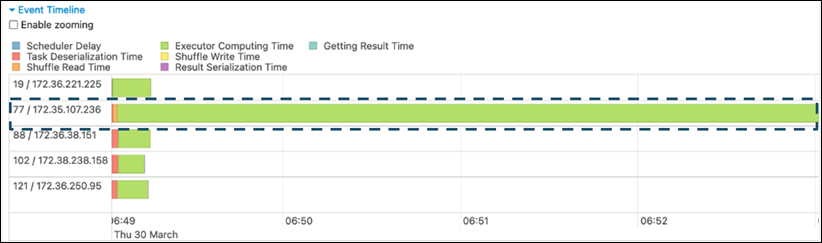
Nella scheda Stage dell'interfaccia utente Spark, esamina la pagina Cronologia degli eventi. Puoi vedere una distribuzione non uniforme delle attività nella schermata seguente. Le attività distribuite in modo non uniforme o che richiedono troppo tempo per essere eseguite possono indicare una distorsione dei dati.
-
Un'altra pagina importante è Summary Metrics, che mostra le statistiche per le attività di Spark. La schermata seguente mostra le metriche con percentili per Duration, GC Time, Spill (memoria), Spill (disco) e così via.

Quando le attività sono distribuite uniformemente, vedrai numeri simili in tutti i percentili. In caso di distorsione dei dati, in ogni percentile verranno visualizzati valori molto distorti. Nell'esempio, la durata dell'attività è inferiore a 13 secondi in Min, 25° percentile, Mediano e 75° percentile. Sebbene l'attività Max abbia elaborato 100 volte più dati rispetto al 75° percentile, la sua durata di 6,4 minuti è circa 30 volte maggiore. Significa che almeno un'attività (o fino al 25 percento delle attività) ha richiesto molto più tempo rispetto al resto delle attività.
Se i dati sono distorti, prova quanto segue:
-
Se usi la AWS Glue versione 3.0, abilita Adaptive Query Execution impostando.
spark.sql.adaptive.enabled=trueAdaptive Query Execution è abilitato per impostazione predefinita nella AWS Glue versione 4.0.È inoltre possibile utilizzare Adaptive Query Execution per la distorsione dei dati introdotta dai join impostando i seguenti parametri correlati:
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor -
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes -
spark.sql.adaptive.advisoryPartitionSizeInBytes=128m (128 mebibytes or larger should be good) -
spark.sql.adaptive.coalescePartitions.enabled=true (when you want to coalesce partitions)
Per ulteriori informazioni, consulta la documentazione di Apache
Spark. -
-
Usa chiavi con un ampio intervallo di valori per le chiavi di unione. In uno shuffle join, le partizioni vengono determinate per ogni valore hash di una chiave. Se la cardinalità di una chiave di join è troppo bassa, è più probabile che la funzione hash faccia un cattivo lavoro di distribuzione dei dati tra le partizioni. Pertanto, se la tua applicazione e la tua logica aziendale la supportano, prendi in considerazione l'utilizzo di una chiave di cardinalità più elevata o di una chiave composita.
# Use Single Primary Key df_joined = df1_select.join(df2_select, ["primary_key"]) # Use Composite Key df_joined = df1_select.join(df2_select, ["primary_key","secondary_key"])
Usa la cache
Quando usi metodi ripetitivi DataFrames, evita ulteriori operazioni di shuffle o calcoli utilizzando df.cache() o df.persist() memorizzando nella cache i risultati del calcolo nella memoria e su disco di ogni esecutore Spark. Spark supporta anche la persistenza RDDs su disco o la replica su più nodi (livello di storage).
Ad esempio, puoi rendere persistente aggiungendo. DataFrames df.persist() Quando la cache non è più necessaria, è possibile utilizzarla unpersist per eliminare i dati memorizzati nella cache.
df = spark.read.parquet("s3://<Bucket>/parquet/product_category=Books/") df_high_rate = df.filter(col("star_rating")>=4.0) df_high_rate.persist() df_joined1 = df_high_rate.join(<Table1>, ["key"]) df_joined2 = df_high_rate.join(<Table2>, ["key"]) df_joined3 = df_high_rate.join(<Table3>, ["key"]) ... df_high_rate.unpersist()
Rimuovi le azioni Spark non necessarie
Evita di eseguire azioni non necessarie come countshow, o. collect Come discusso nella sezione Argomenti chiave di Apache Spark, Spark è pigro. Ogni trasformazione RDD può essere ricalcolata ogni volta che si esegue un'azione su di essa. Quando usi molte azioni Spark, per ogni azione vengono richiamati accessi a più sorgenti, calcoli di attività ed esecuzioni casuali.
Se non hai bisogno collect() di altre azioni nel tuo ambiente commerciale, valuta la possibilità di rimuoverle.
Nota
Evita il più possibile di usare Spark collect() in ambienti commerciali. L'collect()azione restituisce tutti i risultati di un calcolo nell'esecutore Spark al driver Spark, il che potrebbe causare la restituzione di un errore da parte del driver Spark. OOM Per evitare un OOM errore, Spark imposta di spark.driver.maxResultSize = 1GB default, che limita la dimensione massima dei dati restituiti al driver Spark a 1 GB.
