Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Argomenti chiave di Apache Spark
Questa sezione spiega i concetti di base di Apache Spark e gli argomenti chiave per l'ottimizzazione delle prestazioni di Apache AWS Glue Spark. È importante comprendere questi concetti e argomenti prima di discutere delle strategie di ottimizzazione del mondo reale.
Architettura
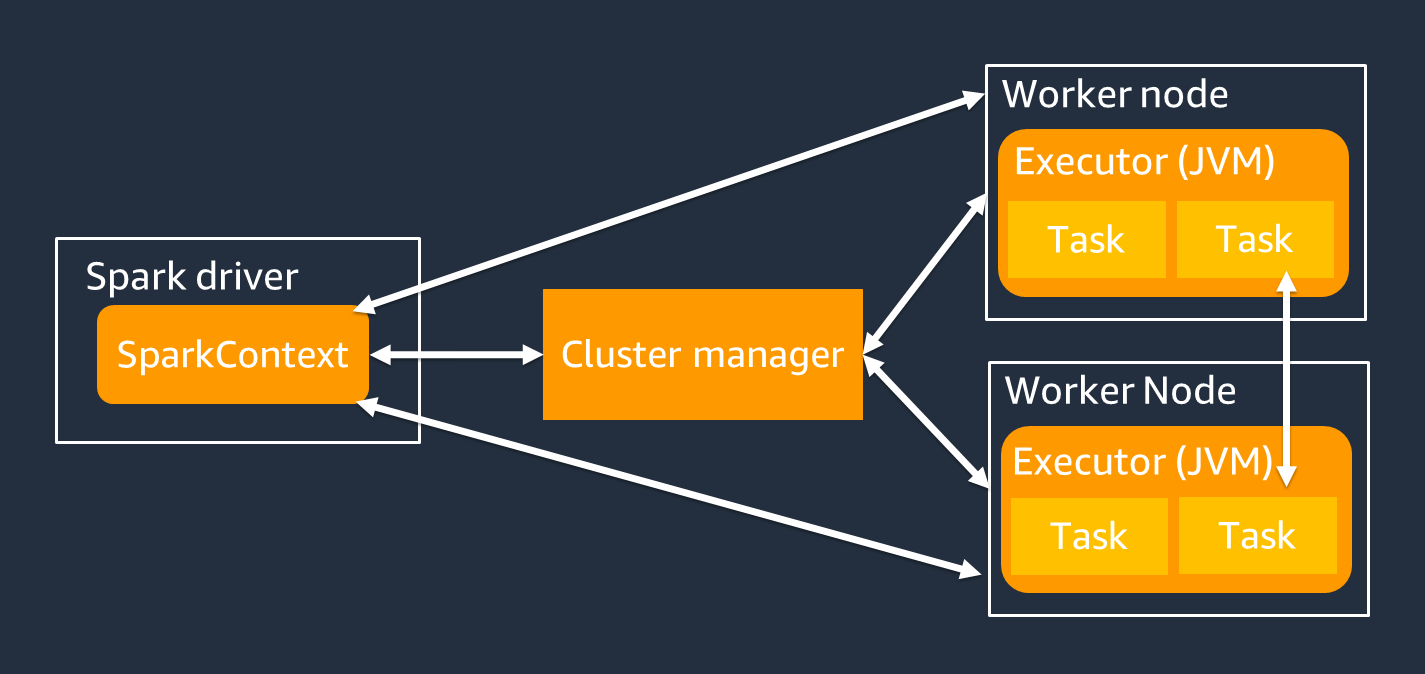
Il driver Spark è principalmente responsabile della suddivisione dell'applicazione Spark in attività che possono essere eseguite su singoli lavoratori. Il driver Spark ha le seguenti responsabilità:
-
È in esecuzione
main()nel tuo codice -
Generazione di piani di esecuzione
-
Fornitura degli esecutori Spark in collaborazione con il gestore del cluster, che gestisce le risorse del cluster
-
Pianificazione delle attività e richiesta di attività per gli esecutori Spark
-
Gestione dell'avanzamento e del ripristino delle attività
Si utilizza un SparkContext oggetto per interagire con il driver Spark durante l'esecuzione del lavoro.
Un esecutore Spark è un lavoratore che conserva dati ed esegue attività che vengono trasmesse dal driver Spark. Il numero di esecutori Spark aumenterà e diminuirà in base alle dimensioni del cluster.
Nota
Un esecutore Spark ha più slot in modo che più attività vengano elaborate in parallelo. Per impostazione predefinita, Spark supporta un'attività per ogni core della CPU virtuale (vCPU). Ad esempio, se un executor ha quattro core CPU, può eseguire quattro attività simultanee.
Set di dati distribuito resiliente
Spark svolge il complesso lavoro di archiviazione e tracciamento di set di dati di grandi dimensioni tra gli esecutori Spark. Quando scrivi codice per i job Spark, non devi pensare ai dettagli dello storage. Spark fornisce l'astrazione resiliente del set di dati distribuito (RDD), che è una raccolta di elementi su cui è possibile operare in parallelo e che possono essere partizionati tra gli esecutori Spark del cluster.
La figura seguente mostra la differenza nel modo in cui archiviare i dati in memoria quando uno script Python viene eseguito nel suo ambiente tipico e quando viene eseguito nel framework Spark (). PySpark
![Python val [1,2,3N], Apache Spark rdd = sc.parallelize [1,2,3N].](images/store-data-memory.png)
-
Python: la scrittura
val = [1,2,3...N]in uno script Python mantiene i dati in memoria sulla singola macchina su cui è in esecuzione il codice. -
PySpark— Spark fornisce la struttura dati RDD per caricare ed elaborare i dati distribuiti nella memoria su più esecutori Spark. Puoi generare un RDD con codice come
rdd = sc.parallelize[1,2,3...N], e Spark può distribuire e conservare automaticamente i dati in memoria su più esecutori Spark.In molti AWS Glue lavori, usi RDD tramite e Spark. AWS Glue DynamicFramesDataFrames Si tratta di astrazioni che consentono di definire lo schema dei dati in un RDD ed eseguire attività di livello superiore con tali informazioni aggiuntive. Poiché utilizzano RDD internamente, i dati vengono distribuiti in modo trasparente e caricati su più nodi nel seguente codice:
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
Un RDD presenta le seguenti funzionalità:
-
Gli RDD sono costituiti da dati suddivisi in più parti chiamate partizioni. Ogni esecutore Spark archivia una o più partizioni in memoria e i dati vengono distribuiti su più esecutori.
-
Gli RDD sono immutabili, il che significa che non possono essere modificati dopo essere stati creati. Per modificare un DataFrame, puoi usare le trasformazioni, che sono definite nella sezione seguente.
-
Gli RDD replicano i dati tra i nodi disponibili, in modo da poter eseguire automaticamente il ripristino in caso di errori dei nodi.
Valutazione pigra
Gli RDD supportano due tipi di operazioni: le trasformazioni, che creano un nuovo set di dati da uno esistente, e le azioni, che restituiscono un valore al programma driver dopo aver eseguito un calcolo sul set di dati.
-
Trasformazioni: poiché gli RDD sono immutabili, è possibile modificarli solo utilizzando una trasformazione.
Ad esempio,
mapè una trasformazione che passa ogni elemento del set di dati attraverso una funzione e restituisce un nuovo RDD che rappresenta i risultati. Notate che ilmapmetodo non restituisce un output. Spark memorizza la trasformazione astratta per il futuro, invece di lasciarti interagire con il risultato. Spark non agirà sulle trasformazioni finché non richiederai un'azione. -
Azioni: utilizzando le trasformazioni, costruisci il tuo piano di trasformazione logica. Per avviare il calcolo, si esegue un'azione come
write,count,showo.collectTutte le trasformazioni in Spark sono lente, in quanto non calcolano immediatamente i risultati. Spark ricorda invece una serie di trasformazioni applicate ad alcuni set di dati di base, come gli oggetti Amazon Simple Storage Service (Amazon S3). Le trasformazioni vengono calcolate solo quando un'azione richiede la restituzione di un risultato al driver. Questo design consente a Spark di funzionare in modo più efficiente. Ad esempio, si consideri la situazione in cui un set di dati creato tramite la
maptrasformazione viene utilizzato solo da una trasformazione che riduce sostanzialmente il numero di righe, ad esempio.reduceÈ quindi possibile passare al driver il set di dati più piccolo che ha subito entrambe le trasformazioni, invece di passare il set di dati mappato più grande.
Terminologia delle applicazioni Spark
Questa sezione tratta la terminologia delle applicazioni Spark. Il driver Spark crea un piano di esecuzione e controlla il comportamento delle applicazioni in diverse astrazioni. I seguenti termini sono importanti per lo sviluppo, il debug e l'ottimizzazione delle prestazioni con l'interfaccia utente Spark.
-
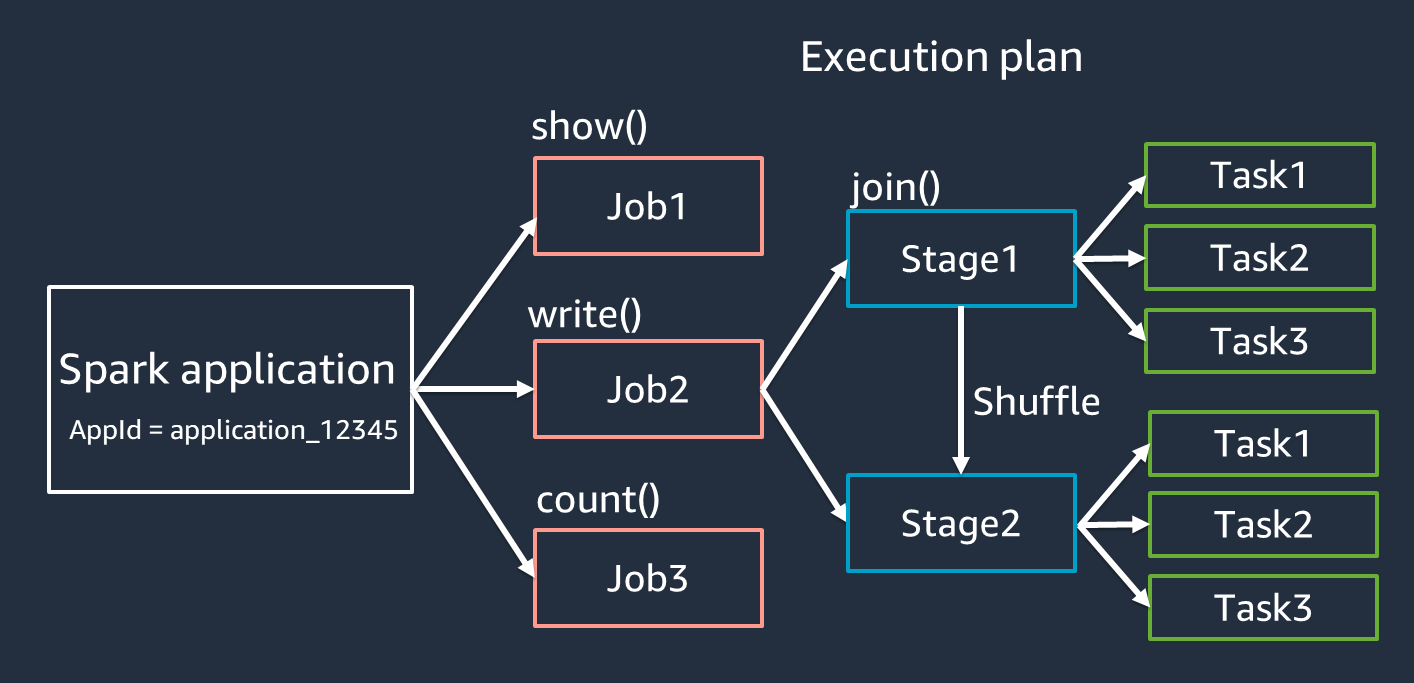
Applicazione: basata su una sessione Spark (contesto Spark). Identificato da un ID univoco come.
<application_XXX> -
Offerte di lavoro: in base alle azioni create per un RDD. Un lavoro è costituito da una o più fasi.
-
Fasi: basato sugli shuffle creati per un RDD. Una fase è costituita da una o più attività. Lo shuffle è il meccanismo di Spark per ridistribuire i dati in modo che siano raggruppati in modo diverso tra le partizioni RDD. Alcune trasformazioni, ad esempio, richiedono un shuffle.
join()Lo shuffle viene discusso più dettagliatamente nella pratica di ottimizzazione di Optimize shuffles. -
Attività: un'attività è l'unità minima di elaborazione pianificata da Spark. Le attività vengono create per ogni partizione RDD e il numero di attività è il numero massimo di esecuzioni simultanee nella fase.
Nota
Le attività sono la cosa più importante da considerare quando si ottimizza il parallelismo. Il numero di attività varia in base al numero di RDD
Parallelism
Spark parallelizza le attività per il caricamento e la trasformazione dei dati.
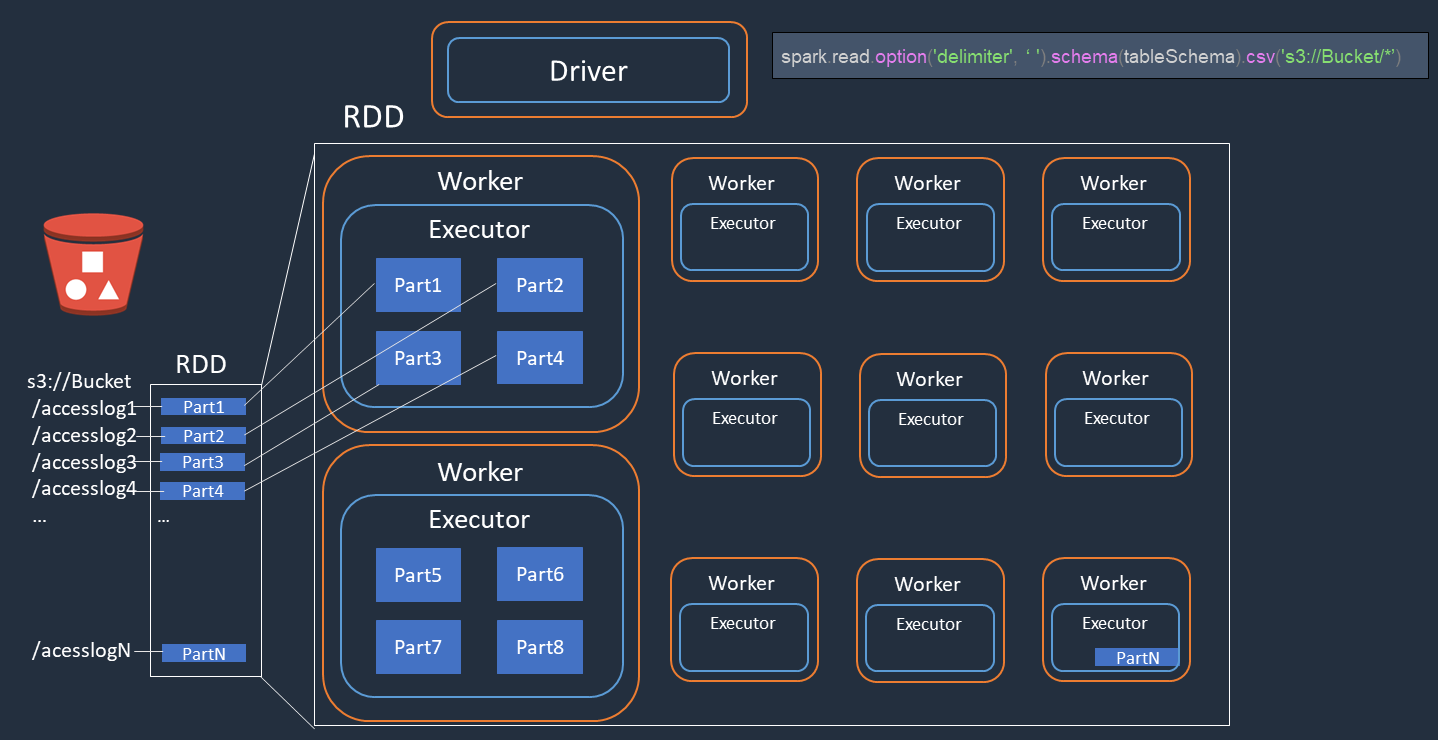
Prendi in considerazione un esempio in cui esegui l'elaborazione distribuita dei file di log di accesso (denominatiaccesslog1 ... accesslogN) su Amazon S3. Il diagramma seguente mostra il flusso di elaborazione distribuito.
-
Il driver Spark crea un piano di esecuzione per l'elaborazione distribuita su molti esecutori Spark.
-
Il driver Spark assegna le attività a ciascun esecutore in base al piano di esecuzione. Per impostazione predefinita, il driver Spark crea partizioni RDD (ciascuna corrispondente a un'attività Spark) per ogni oggetto S3 ().
Part1 ... NQuindi il driver Spark assegna le attività a ciascun esecutore. -
Ogni task Spark scarica l'oggetto S3 assegnato e lo archivia in memoria nella partizione RDD. In questo modo, più esecutori Spark scaricano ed elaborano l'attività assegnata in parallelo.
Per maggiori dettagli sul numero iniziale di partizioni e sull'ottimizzazione, consulta la sezione Parallelizza le attività.
Ottimizzatore Catalyst
Internamente, Spark utilizza un motore chiamato Catalyst
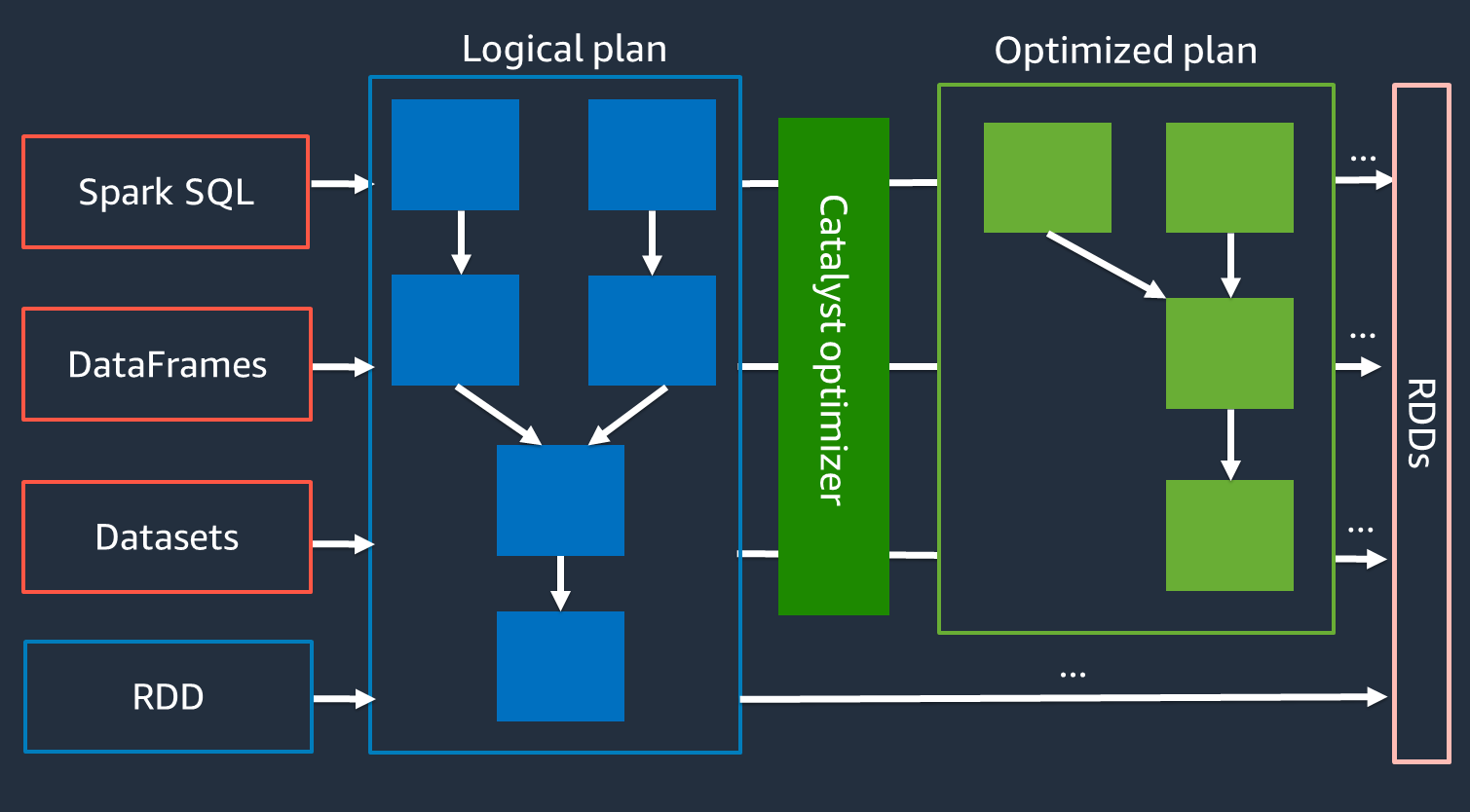
Poiché l'ottimizzatore Catalyst non funziona direttamente con l'API RDD, le API di alto livello sono generalmente più veloci delle API RDD di basso livello. Per i join complessi, l'ottimizzatore Catalyst può migliorare significativamente le prestazioni ottimizzando il piano di esecuzione dei job. Puoi vedere il piano ottimizzato del tuo job Spark nella scheda SQL dell'interfaccia utente di Spark.
Esecuzione adattiva delle interrogazioni
L'ottimizzatore Catalyst esegue l'ottimizzazione del runtime tramite un processo chiamato Adaptive Query Execution. Adaptive Query Execution utilizza le statistiche di runtime per ottimizzare nuovamente il piano di esecuzione delle query durante l'esecuzione del lavoro. Adaptive Query Execution offre diverse soluzioni ai problemi di prestazioni, tra cui la coalescenza delle partizioni post-shuffle, la conversione dello sort-merge join in broadcast join e l'ottimizzazione dello skew join, come descritto nelle sezioni seguenti.
Adaptive Query Execution è disponibile nella versione 3.0 e successive ed è abilitata per AWS Glue impostazione predefinita nella versione 4.0 (Spark 3.3.0) e versioni successive. AWS Glue Adaptive Query Execution può essere attivata e disattivata utilizzando spark.conf.set("spark.sql.adaptive.enabled",
"true") il codice.
Partizioni unificate dopo lo shuffle
Questa funzione riduce le partizioni RDD (coalescenza) dopo ogni mescolamento in base alle statistiche di output. map Semplifica l'ottimizzazione del numero di partizione shuffle durante l'esecuzione di query. Non è necessario impostare un numero di partizione shuffle per adattarlo al set di dati. Spark può scegliere il numero di partizione shuffle corretto in fase di esecuzione dopo aver ottenuto un numero iniziale sufficientemente grande di partizioni shuffle.
La coalescenza delle partizioni post-shuffle è abilitata quando entrambe le partizioni sono impostate su true. spark.sql.adaptive.enabled spark.sql.adaptive.coalescePartitions.enabled Per ulteriori informazioni, consulta la documentazione di Apache Spark.
Conversione da sort-merge join a broadcast join
Questa funzione riconosce quando si uniscono due set di dati di dimensioni sostanzialmente diverse e adotta un algoritmo di join più efficiente basato su tali informazioni. Per maggiori dettagli, consulta la documentazione di Apache Spark.
Ottimizzazione delle giunzioni asimmetriche
La distorsione dei dati è uno degli ostacoli più comuni per i lavori Spark. Descrive una situazione in cui i dati vengono distorti su partizioni RDD specifiche (e di conseguenza, attività specifiche), il che ritarda il tempo di elaborazione complessivo dell'applicazione. Ciò può spesso ridurre le prestazioni delle operazioni di join. La funzionalità di ottimizzazione dello skew join gestisce dinamicamente l'inclinazione nei join ordin-merge suddividendo (e replicando se necessario) le attività asimmetriche in attività di dimensioni approssimativamente uguali.
Questa spark.sql.adaptive.skewJoin.enabled funzionalità è abilitata quando è impostata su true. Per maggiori dettagli, consulta la documentazione di Apache Spark
