Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Parallelizza le attività
Per ottimizzare le prestazioni, è importante parallelizzare le attività per i caricamenti e le trasformazioni dei dati. Come abbiamo discusso in Argomenti chiave di Apache Spark, il numero di partizioni resilienti di set di dati distribuiti (RDD) è importante, perché determina il grado di parallelismo. Ogni attività creata da Spark corrisponde a una partizione su base 1:1. RDD Per ottenere le migliori prestazioni, devi capire come viene determinato il numero di RDD partizioni e come tale numero viene ottimizzato.
Se il parallelismo non è sufficiente, i seguenti sintomi verranno registrati nelle CloudWatchmetriche e nell'interfaccia utente di Spark.
CloudWatch metriche
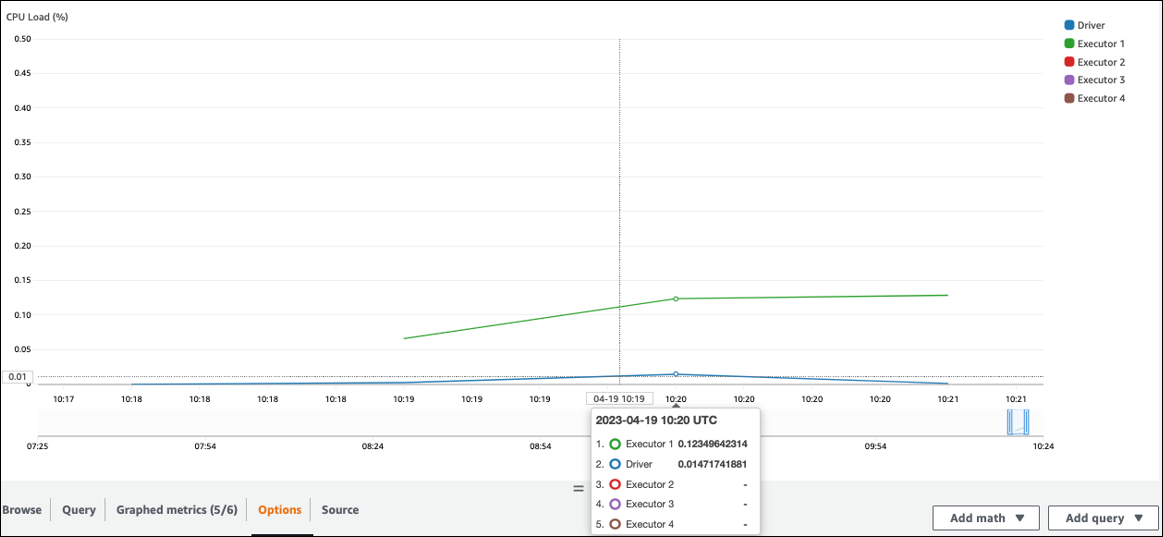
Controlla il CPUcarico e l'utilizzo della memoria. Se alcuni esecutori non eseguono l'elaborazione durante una fase del lavoro, è opportuno migliorare il parallelismo. In questo caso, durante il periodo di tempo visualizzato, l'Executor 1 stava eseguendo un'operazione, ma gli esecutori rimanenti (2, 3 e 4) no. Si può dedurre che a quegli esecutori non sono stati assegnati compiti dal driver Spark.
Interfaccia utente di Spark
Nella scheda Stage dell'interfaccia utente di Spark, puoi vedere il numero di attività in una fase. In questo caso, Spark ha eseguito una sola operazione.

Inoltre, la cronologia degli eventi mostra l'Executor 1 che elabora un'operazione. Ciò significa che il lavoro in questa fase è stato eseguito interamente su un esecutore, mentre gli altri erano inattivi.

Se osservi questi sintomi, prova le seguenti soluzioni per ogni fonte di dati.
Parallelizza il caricamento dei dati da Amazon S3
Per parallelizzare i caricamenti di dati da Amazon S3, controlla innanzitutto il numero predefinito di partizioni. Puoi quindi determinare manualmente il numero di partizioni di destinazione, ma assicurati di evitare di avere troppe partizioni.
Determina il numero predefinito di partizioni
Per Amazon S3, il numero iniziale di RDD partizioni Spark (ognuna delle quali corrisponde a un'attività Spark) è determinato dalle caratteristiche del set di dati Amazon S3 (ad esempio, formato, compressione e dimensione). Quando crei uno AWS Glue DynamicFrame o uno Spark DataFrame da CSV oggetti archiviati in Amazon S3, il numero iniziale RDD di partizioni NumPartitions () può essere calcolato approssimativamente come segue:
-
Dimensione dell'oggetto <= 64 MB:
NumPartitions = Number of Objects -
Dimensione dell'oggetto > 64 MB:
NumPartitions = Total Object Size / 64 MB -
Indivisibile (gzip):
NumPartitions = Number of Objects
Come discusso nella sezione Ridurre la quantità di scansione dei dati, Spark divide oggetti S3 di grandi dimensioni in suddivisioni che possono essere elaborate in parallelo. Quando l'oggetto è più grande della dimensione divisa, Spark lo divide e crea una RDD partizione (e un'attività) per ogni divisione. La dimensione suddivisa di Spark si basa sul formato dei dati e sull'ambiente di runtime, ma questa è un'approssimazione iniziale ragionevole. Alcuni oggetti vengono compressi utilizzando formati di compressione non divisibili come gzip, quindi Spark non può dividerli.
Il NumPartitions valore può variare in base al formato dei dati, alla compressione, alla AWS Glue versione, al numero di worker e alla configurazione di AWS Glue Spark.
Ad esempio, quando carichi un singolo csv.gz oggetto da 10 GB usando Spark DataFrame, il driver Spark creerà solo una RDD partizione (NumPartitions=1) perché gzip non è divisibile. Ciò comporta un carico pesante su un particolare esecutore Spark e nessun compito viene assegnato agli esecutori rimanenti, come descritto nella figura seguente.
Controlla il numero effettivo di attività (NumPartitions) per lo stage nella scheda Spark Web UI Stage oppure esegui il codice per verificare il df.rdd.getNumPartitions() parallelismo.
Quando trovi un file gzip da 10 GB, esamina se il sistema che lo genera è in grado di generarlo in un formato divisibile. Se questa non è un'opzione, potrebbe essere necessario scalare la capacità del cluster per elaborare il file. Per eseguire le trasformazioni in modo efficiente sui dati caricati, sarà necessario ribilanciare le trasformazioni RDD tra i worker del cluster utilizzando la ripartizione.
Determinare manualmente il numero di partizioni desiderato
A seconda delle proprietà dei dati e dell'implementazione di alcune funzionalità da parte di Spark, potresti ritrovarti con un NumPartitions valore basso anche se il lavoro sottostante può ancora essere parallelizzato. Se NumPartitions è troppo piccolo, esegui df.repartition(N) per aumentare il numero di partizioni in modo che l'elaborazione possa essere distribuita su più esecutori Spark.
In questo caso, l'esecuzione df.repartition(100) passerà NumPartitions da 1 a 100, creando 100 partizioni di dati, ognuna con un'attività che può essere assegnata agli altri esecutori.
L'operazione repartition(N) divide equamente tutti i dati (10 GB/100 partizioni = 100 MB/partizione), evitando la distorsione dei dati su determinate partizioni.
Nota
Quando si esegue un'operazione di shuffle come quella eseguita, il numero di partizioni join viene aumentato o diminuito dinamicamente in base al valore di o. spark.sql.shuffle.partitions spark.default.parallelism Ciò facilita uno scambio di dati più efficiente tra gli esecutori Spark. Per ulteriori informazioni, consulta la documentazione di Spark.
Il vostro obiettivo nel determinare il numero di partizioni previsto è quello di massimizzare l'uso dei lavoratori assegnati. AWS Glue Il numero di AWS Glue lavoratori e il numero di attività Spark sono correlati dal numero di. vCPUs Spark supporta un task per ogni v CPU core. Nella AWS Glue versione 3.0 o successiva, puoi calcolare un numero target di partizioni utilizzando la seguente formula.
# Calculate NumPartitions by WorkerType numExecutors = (NumberOfWorkers - 1) numSlotsPerExecutor = 4 if WorkerType is G.1X 8 if WorkerType is G.2X 16 if WorkerType is G.4X 32 if WorkerType is G.8X NumPartitions = numSlotsPerExecutor * numExecutors # Example: Glue 4.0 / G.1X / 10 Workers numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later ) NumPartitions = 9 * 4 = 36
In questo esempio, ogni worker G.1X fornisce quattro v CPU core a un executor Spark (). spark.executor.cores = 4 Spark supporta un task per ogni v CPU Core, quindi gli executor G.1X Spark possono eseguire quattro attività contemporaneamente (). numSlotPerExecutor Questo numero di partizioni sfrutta appieno il cluster se le attività richiedono lo stesso periodo di tempo. Tuttavia, alcune attività richiederanno più tempo di altre, creando core inattivi. In tal caso, valuta la possibilità di moltiplicare numPartitions per 2 o 3 per suddividere e pianificare in modo efficiente le attività più difficili.
Troppe partizioni
Un numero eccessivo di partizioni crea un numero eccessivo di attività. Ciò causa un carico pesante sul driver Spark a causa del sovraccarico legato all'elaborazione distribuita, come le attività di gestione e lo scambio di dati tra gli esecutori Spark.
Se il numero di partizioni del lavoro è notevolmente superiore al numero di partizioni previsto, valuta la possibilità di ridurre il numero di partizioni. È possibile ridurre le partizioni utilizzando le seguenti opzioni:
-
Se le dimensioni dei file sono molto piccole, usa AWS Glue groupFiles. È possibile ridurre l'eccessivo parallelismo derivante dall'avvio di un'attività di Apache Spark per elaborare ogni file.
-
Si usa per unire le
coalesce(N)partizioni. Si tratta di un processo a basso costo. Quando si riduce il numero di partizioni,coalesce(N)è preferibile rispetto a primarepartition(N), perchérepartition(N)esegue lo shuffle per distribuire equamente la quantità di record in ogni partizione. Ciò aumenta i costi e il sovraccarico di gestione. -
Usa Spark 3.x Adaptive Query Execution. Come discusso nella sezione Argomenti chiave di Apache Spark, Adaptive Query Execution fornisce una funzione per unire automaticamente il numero di partizioni. È possibile utilizzare questo approccio quando non è possibile conoscere il numero di partizioni finché non si esegue l'esecuzione.
Parallelizza il caricamento dei dati da JDBC
Il numero di RDD partizioni Spark è determinato dalla configurazione. Nota che per impostazione predefinita viene eseguita una sola operazione per scansionare un intero set di dati di origine tramite una query. SELECT
AWS Glue DynamicFrames Sia Spark che Spark DataFrames supportano il caricamento parallelizzato JDBC dei dati su più attività. Questa operazione viene eseguita utilizzando where i predicati per suddividere una SELECT query in più query. Per parallelizzare le letture daJDBC, configura le seguenti opzioni:
-
Per AWS Glue DynamicFrame, set
hashfield(o and.hashexpression)hashpartitionPer ulteriori informazioni, consulta Leggere da JDBC tabelle in parallelo.connection_mysql8_options = { "url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test", "dbtable": "medicare_tb", "user": "test", "password": "XXXXXXXXX", "hashexpression":"id", "hashpartitions":"10" } datasource0 = glueContext.create_dynamic_frame.from_options( 'mysql', connection_options=connection_mysql8_options, transformation_ctx= "datasource0" ) -
Per Spark DataFrame, set
numPartitions,partitionColumnlowerBound, eupperBound. Per saperne di più, consulta JDBC To Other Databases. df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \ .option("dbtable", "medicare_tb") \ .option("user", "test") \ .option("password", "XXXXXXXXXX") \ .option("partitionColumn", "id") \ .option("numPartitions", "10") \ .option("lowerBound", "0") \ .option("upperBound", "1141455") \ .load() df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
Parallelizza il caricamento dei dati da DynamoDB quando usi il connettore ETL
Il numero di RDD partizioni Spark è determinato dal parametro. dynamodb.splits Per parallelizzare le letture da Amazon DynamoDB, configura le seguenti opzioni:
-
Aumenta il valore di.
dynamodb.splits -
Ottimizza il parametro seguendo la formula spiegata in Tipi di connessione e opzioni per ETL in AWS Glue for Spark.
Parallelizza il caricamento dei dati da Kinesis Data Streams
Il numero di RDD partizioni Spark è determinato dal numero di shard nel flusso di dati Amazon Kinesis Data Streams di origine. Se hai solo pochi shard nel tuo flusso di dati, ci saranno solo alcune attività Spark. Ciò può comportare un basso parallelismo nei processi a valle. Per parallelizzare le letture da Kinesis Data Streams, configura le seguenti opzioni:
-
Aumenta il numero di shard per ottenere un maggiore parallelismo durante il caricamento dei dati da Kinesis Data Streams.
-
Se la logica del microbatch è abbastanza complessa, valuta la possibilità di ripartizionare i dati all'inizio del batch, dopo aver eliminato le colonne non necessarie.
Per ulteriori informazioni, consulta Best practice per ottimizzare costi e prestazioni per i lavori di streaming
Parallelizza le attività dopo il caricamento dei dati
Per parallelizzare le attività dopo il caricamento dei dati, aumenta il numero di RDD partizioni utilizzando le seguenti opzioni:
-
Ripartiziona i dati per generare un numero maggiore di partizioni, soprattutto subito dopo il caricamento iniziale se non è possibile parallelizzare il carico stesso.
Chiama su
repartition()DynamicFrame o DataFrame, specificando il numero di partizioni. Una buona regola empirica è due o tre volte il numero di core disponibili.Tuttavia, quando si scrive una tabella partizionata, ciò può portare a un'esplosione di file (ogni partizione può potenzialmente generare un file in ogni partizione della tabella). Per evitare ciò, puoi ripartizionare il file per colonna. DataFrame Questo utilizza le colonne di partizione della tabella in modo che i dati siano organizzati prima della scrittura. È possibile specificare un numero maggiore di partizioni senza inserire file di piccole dimensioni nelle partizioni della tabella. Tuttavia, fate attenzione a evitare la distorsione dei dati, in cui alcuni valori di partizione finiscono con la maggior parte dei dati e ritardano il completamento dell'operazione.
-
In caso di mescolamenti, aumentate il valore.
spark.sql.shuffle.partitionsQuesto può anche aiutare a risolvere eventuali problemi di memoria durante lo shuffling.Quando hai più di 2.001 partizioni shuffle, Spark utilizza un formato di memoria compressa. Se hai un numero vicino a quello, potresti voler impostare il
spark.sql.shuffle.paritionsvalore oltre tale limite per ottenere una rappresentazione più efficiente.
