Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Scalare la capacità del cluster
Se il tuo lavoro richiede troppo tempo, ma gli esecutori consumano risorse sufficienti e Spark sta creando un grande volume di attività relative ai core disponibili, prendi in considerazione la possibilità di scalare la capacità del cluster. Per valutare se ciò è appropriato, utilizza le seguenti metriche.
CloudWatch metriche
-
Controllate CPUil carico e l'utilizzo della memoria per determinare se gli esecutori stanno consumando risorse sufficienti.
-
Controllate la durata del processo per valutare se il tempo di elaborazione è troppo lungo per soddisfare gli obiettivi prestazionali.
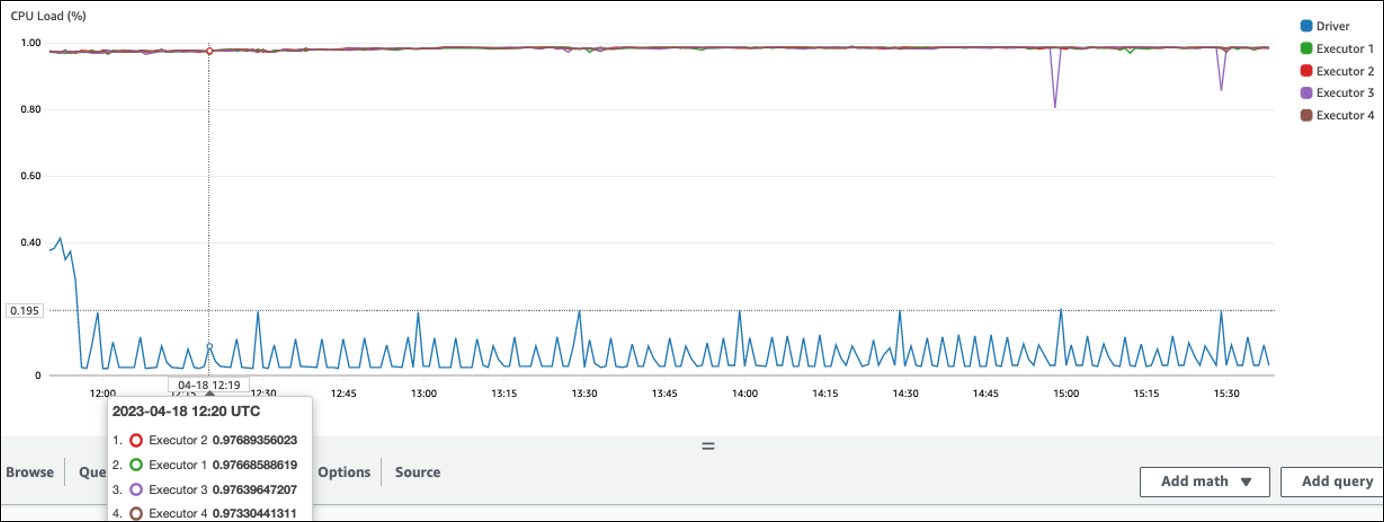
Nell'esempio seguente, quattro executor sono in esecuzione con un CPU carico superiore al 97%, ma l'elaborazione non è stata completata dopo circa tre ore.
Nota
Se CPU il carico è basso, probabilmente non trarrete alcun vantaggio dalla scalabilità della capacità del cluster.
Interfaccia utente di Spark
Nella scheda Job o Stage, puoi vedere il numero di attività per ogni lavoro o fase. Nell'esempio seguente, Spark ha creato 58100 delle attività.

Nella scheda Esecutore, puoi vedere il numero totale di esecutori e attività. Nella schermata seguente, ogni esecutore Spark ha quattro core e può eseguire quattro attività contemporaneamente.
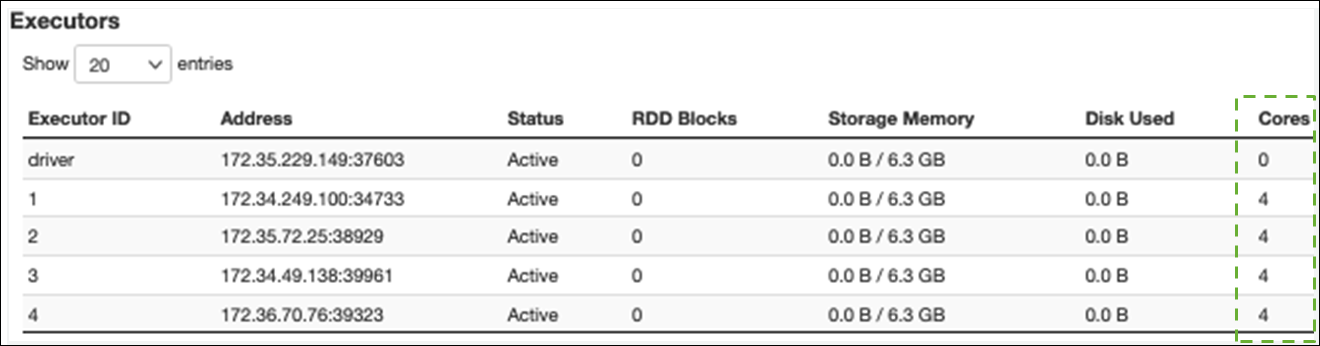
In questo esempio, il numero di attività Spark () 58100) è molto maggiore delle 16 attività che gli esecutori possono elaborare contemporaneamente (4 esecutori × 4 core).
Se osservi questi sintomi, valuta la possibilità di ridimensionare il cluster. È possibile scalare la capacità del cluster utilizzando le seguenti opzioni:
-
Abilita AWS Glue Auto Scaling: Auto Scaling è disponibile per AWS Glue i processi di estrazione, trasformazione e caricamento ETL () e streaming AWS Glue nella versione 3.0 o successiva. AWS Glue aggiunge e rimuove automaticamente i worker dal cluster in base al numero di partizioni in ogni fase o alla velocità con cui vengono generati i microbatch durante l'esecuzione del lavoro.
Se osservate una situazione in cui il numero di lavoratori non aumenta anche se l'Auto Scaling è abilitato, prendete in considerazione l'aggiunta manuale dei lavoratori. Tuttavia, tieni presente che il ridimensionamento manuale per una fase potrebbe far sì che molti lavoratori rimangano inattivi nelle fasi successive, con costi maggiori senza alcun miglioramento delle prestazioni.
Dopo aver abilitato Auto Scaling, puoi vedere il numero di executor nelle metriche degli executor. CloudWatch Utilizza le seguenti metriche per monitorare la richiesta di esecutori nelle applicazioni Spark:
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
Per ulteriori informazioni sui parametri, consulta Monitoraggio AWS Glue tramite i CloudWatch parametri Amazon.
-
-
Scalabilità orizzontale: aumenta il numero di AWS Glue lavoratori: puoi aumentare manualmente il numero di AWS Glue lavoratori. Aggiungi lavoratori solo finché non osservi i lavoratori inattivi. A quel punto, l'aggiunta di più lavoratori aumenterà i costi senza migliorare i risultati. Per ulteriori informazioni, consulta Parallelizzare le attività.
-
Scalabilità verticale: utilizza un tipo di worker più grande: puoi modificare manualmente il tipo di istanza dei tuoi AWS Glue lavoratori per utilizzare lavoratori con più core, memoria e storage. I tipi di worker più grandi consentono di scalare verticalmente ed eseguire lavori intensivi di integrazione dei dati, come trasformazioni di dati che richiedono molta memoria, aggregazioni asimmetriche e controlli di rilevamento delle entità che coinvolgono petabyte di dati.
La scalabilità è utile anche nei casi in cui il driver Spark necessiti di una maggiore capacità, ad esempio perché il piano di richieste di lavoro è piuttosto ampio. Per ulteriori informazioni sui tipi di worker e sulle prestazioni, consulta il post del AWS Big Data Blog Scale your AWS Glue for Apache Spark jobs with
new large worker type G.4X e G.8X. L'utilizzo di lavoratori di grandi dimensioni può anche ridurre il numero totale di lavoratori necessari, il che aumenta le prestazioni grazie alla riduzione degli spostamenti in operazioni intensive come la partecipazione.
